sparkstreaming并不是一个真正的实时流处理框架,而是一个mini batch的框架
storm和flink是真正的实时流处理框架
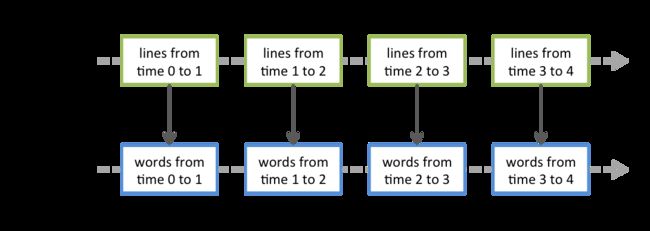
SparkStreaming编程模型:DStream(discretized stream),represents a continuous stream of data,Internally, a DStream is represented as a sequence of RDDs
SparkCore的编程模型: RDD
SparkSQL的编程模型: DF/DS
SparkStreaming入口:StreamingContext
SparkCore入口: SparkContext
SparkSQL入口:SparkSession
[hadoop@hadoop000 bin]$ ./spark-shell --master local[2]
scala> import org.apache.spark._
import org.apache.spark._
scala> import org.apache.spark.streaming._
import org.apache.spark.streaming._
scala> val ssc = new StreamingContext(sc.getConf, Seconds(1))
org.apache.spark.SparkException: Only one SparkContext may be running in this JVM (see SPARK-2243). To ignore this error, set spark.driver.allowMultipleContexts = true. The currently running SparkContext was created at:
org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:924)
org.apache.spark.repl.Main$.createSparkSession(Main.scala:103)
(:15)
(:43)
(:45)
.(:49)
.()
.$print$lzycompute(:7)
.$print(:6)
$print()
sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
java.lang.reflect.Method.invoke(Method.java:497)
scala.tools.nsc.interpreter.IMain$ReadEvalPrint.call(IMain.scala:786)
scala.tools.nsc.interpreter.IMain$Request.loadAndRun(IMain.scala:1047)
scala.tools.nsc.interpreter.IMain$WrappedRequest$$anonfun$loadAndRunReq$1.apply(IMain.scala:638)
scala.tools.nsc.interpreter.IMain$WrappedRequest$$anonfun$loadAndRunReq$1.apply(IMain.scala:637)
scala.reflect.internal.util.ScalaClassLoader$class.asContext(ScalaClassLoader.scala:31)
scala.reflect.internal.util.AbstractFileClassLoader.asContext(AbstractFileClassLoader.scala:19)
at org.apache.spark.SparkContext$$anonfun$assertNoOtherContextIsRunning$2.apply(SparkContext.scala:2456)
at org.apache.spark.SparkContext$$anonfun$assertNoOtherContextIsRunning$2.apply(SparkContext.scala:2452)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.SparkContext$.assertNoOtherContextIsRunning(SparkContext.scala:2452)
at org.apache.spark.SparkContext$.markPartiallyConstructed(SparkContext.scala:2541)
at org.apache.spark.SparkContext.(SparkContext.scala:84)
at org.apache.spark.streaming.StreamingContext$.createNewSparkContext(StreamingContext.scala:838)
at org.apache.spark.streaming.StreamingContext.(StreamingContext.scala:85)
... 53 elided
spark报错:Only one SparkContext may be running in this JVM
原因通过以下StreamingContext的源码可以看出:
/**
* Create a StreamingContext by providing the configuration necessary for a new SparkContext.
* @param conf a org.apache.spark.SparkConf object specifying Spark parameters
* @param batchDuration the time interval at which streaming data will be divided into batches
*/
def this(conf: SparkConf, batchDuration: Duration) = {
this(StreamingContext.createNewSparkContext(conf), null, batchDuration)
}
------------------------------------------------------------------------------------
private[streaming] def createNewSparkContext(conf: SparkConf): SparkContext = {
new SparkContext(conf)
}
private[streaming] def createNewSparkContext(
master: String,
appName: String,
sparkHome: String,
jars: Seq[String],
environment: Map[String, String]
): SparkContext = {
val conf = SparkContext.updatedConf(
new SparkConf(), master, appName, sparkHome, jars, environment)
new SparkContext(conf)
}
sc.getConf相当于传进去了一个conf调用的就是上边这个方法,这个方法里的def createNewSparkContext(conf: SparkConf): SparkContext = {
new SparkContext(conf)
}又new了一个sparkcontext,所以会报错
应该调用下面这个方法:
/**
* Create a StreamingContext using an existing SparkContext.
* @param sparkContext existing SparkContext
* @param batchDuration the time interval at which streaming data will be divided into batches
*/
def this(sparkContext: SparkContext, batchDuration: Duration) = {
this(sparkContext, null, batchDuration)
}
也就是直接传进去一个sparkcontext,再次启动就没问题了:
[hadoop@hadoop000 bin]$ ./spark-shell --master local[2]
scala> import org.apache.spark._
import org.apache.spark._
scala> import org.apache.spark.streaming._
import org.apache.spark.streaming._
scala> val ssc = new StreamingContext(sc, Seconds(5))
ssc: org.apache.spark.streaming.StreamingContext = org.apache.spark.streaming.StreamingContext@7f64bd7
scala> val lines = ssc.socketTextStream("localhost",9999)
lines: org.apache.spark.streaming.dstream.ReceiverInputDStream[String] = org.apache.spark.streaming.dstream.SocketInputDStream@546c30c2
scala> val words = lines.flatMap(_.split(" "))
words: org.apache.spark.streaming.dstream.DStream[String] = org.apache.spark.streaming.dstream.FlatMappedDStream@1e75af65
scala> val pairs = words.map(x=>(x,1))
pairs: org.apache.spark.streaming.dstream.DStream[(String, Int)] = org.apache.spark.streaming.dstream.MappedDStream@1aebe759
scala> val wordcounts = pairs.reduceByKey(_+_)
wordcounts: org.apache.spark.streaming.dstream.DStream[(String, Int)] = org.apache.spark.streaming.dstream.ShuffledDStream@1bd6bfb0
scala> wordcounts.print()
scala> ssc.start()
-------------------------------------------
Time: 1537941150000 ms
-------------------------------------------
-------------------------------------------
Time: 1537941155000 ms
-------------------------------------------
-------------------------------------------
Time: 1537941160000 ms
-------------------------------------------
-------------------------------------------
Time: 1537941165000 ms
-------------------------------------------
[Stage 0:> (0 + 1) / 1]
[hadoop@hadoop000 ~]$ nc -lk 9999
huluwa huluwa yi gen teng shang qi ge wa
18/09/26 13:53:25 WARN storage.RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.
18/09/26 13:53:25 WARN storage.BlockManager: Block input-0-1537941205200 replicated to only 0 peer(s) instead of 1 peers
-------------------------------------------
Time: 1537941210000 ms
-------------------------------------------
(gen,1)
(teng,1)
(huluwa,2)
(wa,1)
(yi,1)
(ge,1)
(qi,1)
(shang,1)
-------------------------------------------
Time: 1537941215000 ms
-------------------------------------------
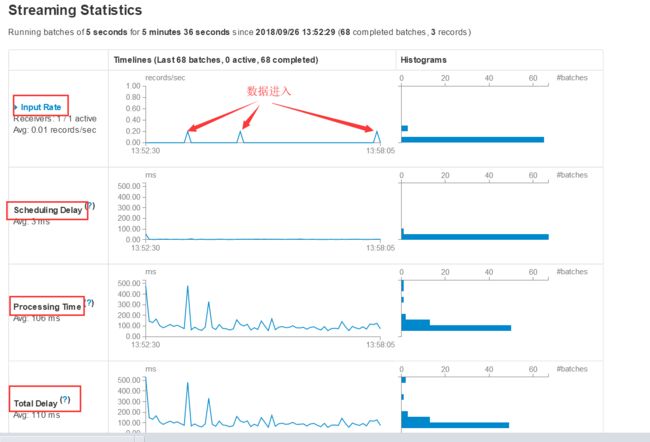
IDEA测试代码如下:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamingApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("SparkStreamingApp")
val ssc = new StreamingContext(conf,Seconds(5))
val lines = ssc.socketTextStream("hadoop000",9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(x=>(x,1))
val wordcounts = pairs.reduceByKey(_+_)
wordcounts.print()
ssc.start()
ssc.awaitTermination()
}
}
如果把上方代码中local[2]改为local[1],运行信息如下:
......
18/09/27 16:37:52 WARN StreamingContext: spark.master should be set as local[n], n > 1 in local mode if you have receivers to get data, otherwise Spark jobs will not get resources to process the received data.
....
18/09/27 16:38:30 INFO JobScheduler: Added jobs for time 1538037510000 ms
18/09/27 16:38:35 INFO JobScheduler: Added jobs for time 1538037515000 ms
18/09/27 16:38:40 INFO JobScheduler: Added jobs for time 1538037520000 ms
18/09/27 16:38:45 INFO JobScheduler: Added jobs for time 1538037525000 ms
18/09/27 16:38:50 INFO JobScheduler: Added jobs for time 1538037530000 ms
18/09/27 16:38:55 INFO JobScheduler: Added jobs for time 1538037535000 ms
18/09/27 16:39:00 INFO JobScheduler: Added jobs for time 1538037540000 ms
18/09/27 16:39:05 INFO JobScheduler: Added jobs for time 1538037545000 ms
18/09/27 16:39:10 INFO JobScheduler: Added jobs for time 1538037550000 ms
18/09/27 16:39:15 INFO JobScheduler: Added jobs for time 1538037555000 ms
18/09/27 16:39:20 INFO JobScheduler: Added jobs for time 1538037560000 ms
18/09/27 16:39:25 INFO JobScheduler: Added jobs for time 1538037565000 ms
.....
关于这个问题,官网的说明如下:
1)When running a Spark Streaming program locally, do not use “local” or “local[1]” as the master URL. Either of these means that only one thread will be used for running tasks locally. If you are using an input DStream based on a receiver (e.g. sockets, Kafka, Flume, etc.), then the single thread will be used to run the receiver, leaving no thread for processing the received data. Hence, when running locally, always use “local[n]” as the master URL, where n > number of receivers to run (see Spark Properties for information on how to set the master).
2)Extending the logic to running on a cluster, the number of cores allocated to the Spark Streaming application must be more than the number of receivers. Otherwise the system will receive data, but not be able to process it.
receiver会占用一个core,如果只有一个core,那么只能接收数据而不能处理数据,因为没有core可用于处理数据了
注意:File streams do not require running a receiver so there is no need to allocate any cores for receiving file data.
读文件系统的文件(file stream)不需要receiver,数据都存在HDFS上,假设挂掉了重新读一次就行了,不需要一个专门的receiver接收数据
查看源码可以知道原因:
/**
* Creates an input stream from TCP source hostname:port. Data is received using
* a TCP socket and the receive bytes is interpreted as UTF8 encoded `\n` delimited
* lines.
* @param hostname Hostname to connect to for receiving data
* @param port Port to connect to for receiving data
* @param storageLevel Storage level to use for storing the received objects
* (default: StorageLevel.MEMORY_AND_DISK_SER_2)
* @see [[socketStream]]
*/
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String] = withNamedScope("socket text stream") {
socketStream[String](hostname, port, SocketReceiver.bytesToLines, storageLevel)
}
------------------------------------------------------------------------------------------------------------------
/**
* Gets the receiver object that will be sent to the worker nodes
* to receive data. This method needs to defined by any specific implementation
* of a ReceiverInputDStream.
*/
def getReceiver(): Receiver[T]
socketTextStream返回值是个抽象类ReceiverInputDStream,该类下有个getReceiver方法
/**
* Create an input stream that monitors a Hadoop-compatible filesystem
* for new files and reads them as text files (using key as LongWritable, value
* as Text and input format as TextInputFormat). Files must be written to the
* monitored directory by "moving" them from another location within the same
* file system. File names starting with . are ignored.
* @param directory HDFS directory to monitor for new file
*/
def textFileStream(directory: String): DStream[String] = withNamedScope("text file stream") {
fileStream[LongWritable, Text, TextInputFormat](directory).map(_._2.toString)
}
textFileStream的返回值直接就是个DStream
需要注意的几点:
- Once a context has been started, no new streaming computations can be set up or added to it.
- Once a context has been stopped, it cannot be restarted.
- Only one StreamingContext can be active in a JVM at the same time.
- stop() on StreamingContext also stops the SparkContext. To stop only the StreamingContext, set the optional parameter of stop() called stopSparkContext to false.
- A SparkContext can be re-used to create multiple StreamingContexts, as long as the previous StreamingContext is stopped (without stopping the SparkContext) before the next StreamingContext is created.