《姜子牙》《哪吒》连连看
《姜子牙》《哪吒》连连看
- 前言
- 一、票房对比分析
-
- 1.获取票房数据
- 2.票房走势分析
- 二、评价对比分析
-
- 1.爬取影评
-
- 1.1获取评论页面
- 1.2 解析页面中的评论
- 1.3 定义爬取函数
- 1.4 完整代码
- 2.词云分析
-
- 2.1 完整代码
- 2.2 结果展示
- 写在最后
前言

随着国内疫情得到有效控制,每个地区的电影院都陆陆续续的开放了,而很多本应该在春节档上映的电影因为疫情撤档,现在也重新上映了。
想必和不少小伙伴一样,我一直对《姜子牙》满怀期待。于是,国庆第2天我便杀入影院。而关于《姜子牙》的评价呈现了两极分化,而它也经常被拿来和去年上映的《哪吒》对比。关于电影本身,我不做过多评价,主要是从数据的角度出发,把《姜子牙》和《哪吒》进行一个对比分析。
一、票房对比分析
两部电影的基本情况如下:
| 姜子牙 | 哪吒 |
|---|---|
| 2020年10月1日(上映10天) | 2019年7月26日(上映443天) |
1.获取票房数据
为了使得数据统一,我选取上映的前9日的票房数据(将持续更新):
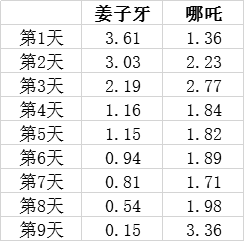
注:票房数据来源于网络,不保证完全准确
将其存于本地excel表格中,命名为“票房数据.xlsx”
2.票房走势分析
利用pandas库对票房数据进行分析,并绘制折线图:
import pandas as pd
import matplotlib.pyplot as plt
# 票房分析
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
data = pd.read_excel('票房数据.xlsx',index_col=0)
data.plot(style='.-.')
plt.title('票房数据')
plt.ylabel('票房(亿元)')
plt.xlabel('上映时间')
plt.savefig('票房数据.png')
其中,index_col=0表示将第一列作为索引。运行结果如下:

从图可以看出(仅代表个人观点):
- 首映当日《姜子牙》票房明显高于《哪吒》。这大概是源于观众的期待,这也说明前期的宣传工作做到位了;
- 从走势来看,《姜子牙》呈现出明显下滑。这大概是因为上映后口碑上出现了两级分化,电影本身没有到达观众原本的期待;
- 从走势来看,《哪吒》后续走势强劲有力。这大概是因为上映后《哪吒》作为国产动漫的代表口口相传,吸引了越来越多的观众。
二、评价对比分析
这一部分主要是对观众的影评进行分析,评价数据来源于某瓣。
Tip:本文仅供学习与交流,切勿用于非法用途!!!
1.爬取影评
在网站简单搜索之后可以发现一个电影短评的接口:
https://movie.douban.com/subject/26794435/comments?start=20&limit=20&status=P&sort=new_score
其中,26794435表示电影的编号l;start参数表示评论起始位置;limit表示每次请求的评论数。
1.1获取评论页面
def get_comment(mid,page):
'''
获得评论页面的HTML
'''
start = (page-1)*20
url = 'https://movie.douban.com/subject/%s/comments?start=%d&limit=20&status=P&sort=new_score'%(mid,start)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:81.0) Gecko/20100101 Firefox/81.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'}
cookies = {
}
res = requests.get(url,headers=headers,cookies=cookies)
html = res.text
return html
注:请求需要带上登陆后的cookies,否则将只能获取10页的评论。
1.2 解析页面中的评论
def parse_comment(html):
'''
解析HTML中的评论
'''
comment = re.findall('(.*?)',html)
return comment
这里就是一个简单的正则匹配,就不过多解释了。
1.3 定义爬取函数
def crawl_comment(mid,N,name):
'''
爬取指定页数的评论,并保存在本地
'''
comments = []
for p in range(1,N+1):
html = get_comment(mid,p)
comment = parse_comment(html)
comments.extend(comment)
print('《%s》第%d页评论爬取完成(%d条)'%(name,p,len(comment)))
time.sleep(random.uniform(3,5))
with open('%s.txt'%name,'w') as f:
f.write(json.dumps(comments))
注:time.sleep()很重要,否则请求过于频繁将触发安全机制,导致403
1.4 完整代码
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 10 12:01:35 2020
@author: kimol_love
"""
import re
import time
import json
import random
import requests
# 定义相关函数
def get_comment(mid,page):
'''
获得评论页面的HTML
'''
start = (page-1)*20
url = 'https://movie.douban.com/subject/%s/comments?start=%d&limit=20&status=P&sort=new_score'%(mid,start)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:81.0) Gecko/20100101 Firefox/81.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'}
cookies = {
}
res = requests.get(url,headers=headers,cookies=cookies)
html = res.text
return html
def parse_comment(html):
'''
解析HTML中的评论
'''
comment = re.findall('(.*?)',html)
return comment
def crawl_comment(mid,N,name):
'''
爬取指定页数的评论,并保存在本地
'''
comments = []
for p in range(1,N+1):
html = get_comment(mid,p)
comment = parse_comment(html)
comments.extend(comment)
print('《%s》第%d页评论爬取完成(%d条)'%(name,p,len(comment)))
time.sleep(random.uniform(3,5))
with open('%s.txt'%name,'w') as f:
f.write(json.dumps(comments))
# 爬取姜子牙评论
crawl_comment('25907124',25,'姜子牙')
# 爬取哪吒评论
crawl_comment('26794435',25,'哪吒')
2.词云分析
利用python的jieba库和wordcloud库对评论进行分析,绘制出词云。其中相应库的安装如下:
pip install jieba
pip install wordcloud
2.1 完整代码
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 10 12:22:53 2020
@author: kimol_love
"""
import json
import jieba
from wordcloud import WordCloud
# 定义相关函数
def create_wordcloud(comments,name):
'''
根据评论列表创建词云
'''
content = ''.join(comments)
wl = jieba.cut(content,cut_all=True)
wl_space_split = ' '.join(wl)
wc = WordCloud('simhei.ttf',
background_color='white', # 背景颜色
width=1000,
height=600,).generate(wl_space_split)
wc.to_file('%s.png'%name)
# 词云数据分析
with open('姜子牙.txt','r') as f:
comments_jiang = json.loads(f.read())
create_wordcloud(comments_jiang,'姜子牙评论')
with open('哪吒.txt','r') as f:
comments_ne = json.loads(f.read())
create_wordcloud(comments_ne,'哪吒评论')
先利用jieba对评论进行分词处理,再利用wordcloud对词频进行统计并绘制出词云。
2.2 结果展示
- 《姜子牙》评论词云:

可以看出:在关于《姜子牙》的评论中,往往会伴随着与《哪吒》的比较。同时,其中的剧情、故事也是大家比较关注的一个问题。
- 《哪吒》评论词云:

可以看出:在关于《哪吒》的评论中,大家往往涉及到了国产、动画等关键词,而这也与大家对《哪吒》的主流定位不谋而合。
写在最后
本文仅从数据的角度出发进行分析,仅代表个人观点,如有不足还请批评指正。
最后,感谢各位大大的耐心阅读~
创作不易,大侠请留步… 动起可爱的双手,来个赞再走呗 (๑◕ܫ←๑)