欢迎阅读
本文会通过实际场景介绍一下 GraphQL,目的是让你快速了解 GraphQL 是什么,以及基本工作思路,不包含实际用法,所以阅读很轻松。
一、GraphQL 是什么?
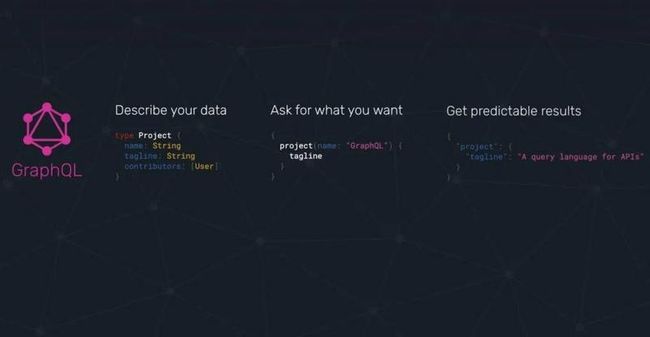
GraphQL 是后端数据查询语言,可以简单理解为 GraphQL 对标的是 REST 接口。
GraphQL 由 Facebook 开源,目前已经在 Facebook 中支撑千亿级的 API 接口调用,在 Facebook 之外正在被迅速应用。
我们不要被 GraphQL 这个名字误导了,第一次看见它时,我还以为这是一个图数据库的查询语言呢。
GraphQL 大体上的确是 "图查询" 的意思,但这个 "图" 是数据图谱的意思,不是图数据库。
二、GraphQL 思路
以上图为例,这是主流的 Feed 流形式,如何实现呢?
定下来界面中需要显示哪些数据元素之后,后端开始为其定制一个 REST 接口,查询出相关数据:
- Post 帖子
- 作者
- Like 喜欢
- Comment 评论
- Share 分享
后端程序员进行数据关联查询,取出其中需要的数据项,然后封装为一个易于前端操作的数据结构,例如 JSON 对象。
这样 Feed 流的接口就 OK 了,同样的,对于其他界面再进行相应的接口开发。
例如在帖子详情页面,涉及的数据还是 Feed 流中的这些,但具体的数据项不同了,例如:
- 帖子需要全文
- Like 需要点赞用户的图像列表、ID
- Comment 评论需要详情列表
因为数据项的不同,就需要针对这个界面需求重新开发吧。
如果你嫌麻烦,提供了一个大而全的接口,后端开发是简单了,但新问题来了,例如:
- 前端开发需要从结果数据中仔细挑出自己所需要的数据项。
- 接口返回数据中包含大量的前端无用数据,会占用更多的带宽,影响性能,例如 Facebook 那种千亿级的 API 调用量,这种带宽的浪费是不能容忍的。
有什么更好的办法呢?(如果你有更好的经验,欢迎发给我,我会分享给大家)
Facebook 为了解决这个问题,设计出了 GraphQL。
GraphQL 解决思路
对于上述场景,本质上是后端在应付前端的每个需求,是以前端需求为中心。
前端说我要这些数据,后端就去准备这些数据,来一个需求就处理一个需求。
Facebook 的想法是:
数据就是那样的,每个数据对象包含哪些项,根据各个数据对象的关系就可以形成数据的图谱了。后端负责构造这个数据图谱,前端根据数据图谱来查询自己所需要的数据。
这样前端与后端都是以数据图谱为中心了,后端就不用伺候前端各种不同类型的需求了,前端也可以自由的精准查询数据了。
感觉比较抽象是吧,看下面的示例代码:
# ----------- 定义数据类型 -----------
type Post {
id: String!
title: String!
description: String
comments: [Comment]
likes:[Like]
}
type Comment{
id:String
}
type Like{
id:String
}
# ----------- 定义查询接口 -----------
type Query {
recentPosts(count: Int, offset: Int): [Post]!
}
type Mutation {
writePost(title: String!, category: String) : Post!
}(上面代码可横向滑动)
其中分为2个部分:
- 上面部分定义了数据类型,例如 Post,指明包含哪些数据项,其中的
comments、likes关联了其他的数据类型,这样就描绘出了数据对象之间的关系。 - 下面部分定义了查询接口,供前端调用。
然后我们看前端怎么用。

上图中,左边是前端的调用方式,右边是返回的数据结果。
前端调用了 recentPosts 接口,并指明了只需要返回 id,所以,返回结果中只有 id 数据项。

上图中,前端调用了 recentPosts 接口,这次指明了需要:
- Post 的 id 项
- likes 的 id 项
- comments 的 id 项
在右边的返回结果中可以看到,应前端的需求返回了相应数据。
三、小结
在以数据图谱为中心之后,后端省心了,前端自由了。所以 GraphQL 的核心就是构建好这个数据图谱。
以上就是 GraphQL 基本内容了,如果对它有兴趣,可以留言告诉我,之后我会整理一个 GraphQL 的使用教程。
写在最后
欢迎大家关注我的公众号【风平浪静如码】,海量Java相关文章,学习资料都会在里面更新,整理的资料也会放在里面。
觉得写的还不错的就点个赞,加个关注呗!点关注,不迷路,持续更新!!!