前言
Hello,everybody,我是asong,今天与大家一起来聊一聊面试中几个常见的缓存问题。为什么会突然想做一篇这个文章呢,今天翻了一下我当初准备面试时整理的一些资料,发现缓存在面试中占比还是很高的,当初为了面试也是背了好久的,不过因为都是背的,现在也有点忘了,今天就想着好好整理一下这一部分,好好记录一下。因为自己能力有限,这一篇主讲通俗易懂,不涉及太难的缓存使用场景。好啦,我们开始吧。
缓存应用
缓存在我们平常的项目中多多少少都会使用到,缓存使用的使用场景还是比较多的,缓存是分布式系统中的重要组件,主要解决高并发、大数据场景下,热点数据访问的性能问题。提高性能的数据快速访问。一提到缓存,这些是我们都能想到的一些缓存应用场景,但是我们是不太清楚缓存的本质思想是什么的。缓存的基本思想就是我们非常熟悉的空间换时间。缓存也并不是那么的高大上,虽然他可以为系统的性能进行提升。缓存的思想实际在操作系统或者其他地方都被大量用到。 比如 CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。 再比如操作系统在 页表方案 基础之上引入了 快表 来加速虚拟地址到物理地址的转换。我们可以把快表理解为一种特殊的高速缓冲存储器(Cache)。
上面简单介绍了缓存的基本思想,现在回到业务系统来说:我们为了避免用户在请求数据的时候获取速度过于缓慢,所以我们在数据库之上增加了缓存这一层来弥补。画个图能更加方便大家的理解:
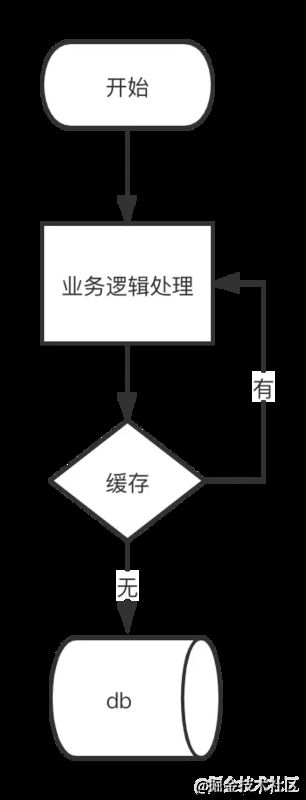
简单点说当我们查询一条数据时,先去查询缓存,如果缓存有就直接返回,如果没有就去查询数据库,然后返回。这种情况下就可能会出现一些现象。
1. 缓存雪崩
1.1 什么是缓存雪崩
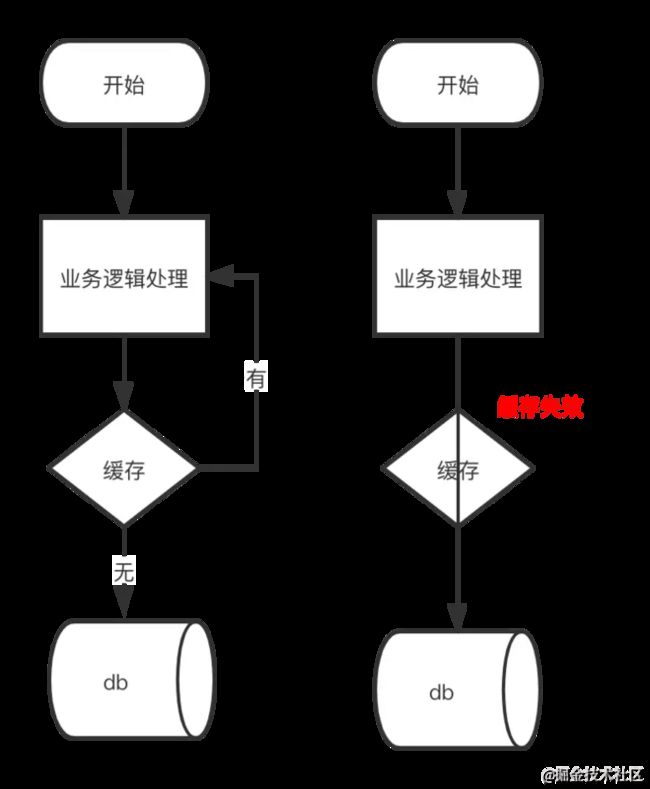
这里我们通过一个例子进行分析。比如马老师的某宝,我们打开某宝的首页时,看到一些图片呀、推荐店铺信息呀等等,这些都属于热点数据,为什么他们会加载的那么快呢?因为使用到了缓存呗。这些热点数据都做了缓存,假设现在把这些热点数据的缓存失效时间为一样,现在我们马老师要做一个秒杀活动,假设在秒杀活动时每秒有8000个请求,本来有缓存我们是可以扛住每秒 6000 个请求,但是缓存当时所有的Key都失效了。此时 1 秒 8000 个请求全部落数据库,数据库必然扛不住,它会报一下警,真实情况可能DBA都没反应过来就直接挂了。此时,如果没用什么特别的方案来处理这个故障,DBA 很着急,重启数据库,但是数据库立马又被新的流量给打死了。上面造成缓存雪崩的原因是因为失效时间造成,还有一种可能是因为缓存服务宕机。
1.2 解决办法
这里分三个时间段进行进行分析
1.2.1 事前
如果缓存雪崩造成的原因是因为缓存服务宕机造成的,可以将redis采用集群部署,可以使用 主从+哨兵 ,Redis Cluster 来避免 Redis 全盘崩溃的情况。若缓存雪崩是因为大量缓存因为失效时间而造成的,我们在批量往redis存数据的时候,把每个Key的失效时间都加个随机值就好了,这样可以保证数据不会在同一时间大面积失效,或者设置热点数据永远不过期,有更新操作就更新缓存就可以了。
1.2.2 事中
如果我们之前没有考虑缓存雪崩的问题,那么在实际使用中真的发生缓存雪崩了,我们该怎么办呢?这时我们就要考虑使用其他方法避免出现这种情况了。我们可以使用ehcache 本地缓存 + Hystrix 限流&降级 ,避免 MySQL 被打死的情况发生。
这里使用echache本地缓存的目的就是考虑在 Redis Cluster 完全不可用的时候,ehcache 本地缓存还能够支撑一阵。
使用 Hystrix 进行 限流 & 降级 ,比如一秒来了5000个请求,我们可以设置假设只能有一秒 2000 个请求能通过这个组件,那么其他剩余的 3000 请求就会走限流逻辑,然后去调用我们自己开发的降级组件(降级)。比如设置的一些默认值呀之类的。以此来保护最后的 MySQL 不会被大量的请求给打死。
1.2.3 事后
如果缓存服务宕机了,这里我们可以开启Redis 持久化 RDB+AOF,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
综上所述,可画出如下图所示:

2. 缓存穿透
2.1 什么是缓存穿透
在正常的情况下,用户查询数据都是存在的,但是在异常情况下,缓存与数据都没有数据,但是用户不断发起请求,这样每次请求都会打到数据库上面去,这时的用户很可能是攻击者,攻击会导致数据库压力过大,严重会击垮数据库。
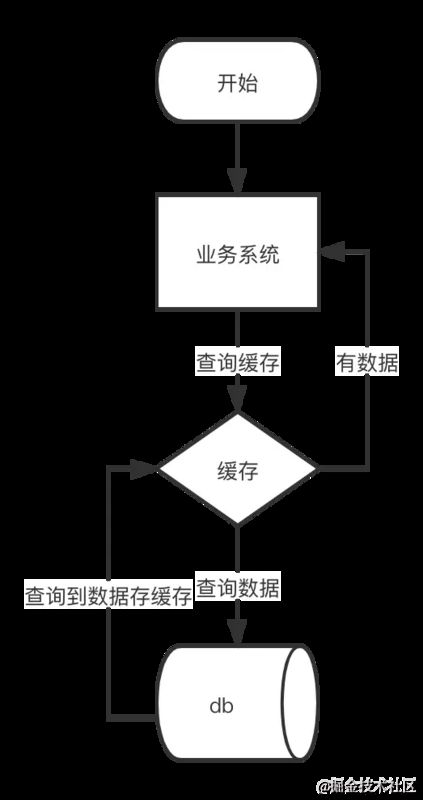
2.2 解决办法
2.2.1 添加参数校验
我刚入职的时候,我的老大就跟我说过,作为一名后端开发工程师,不要相信前端传来的东西,所以数据一定要在后端进行校验。我们可以在接口层添加校验,不合法的直接返回即可,没必要做后续的操作。
2.2.2 缓存空值
上面我们也介绍了,之所以会发生穿透,就是因为缓存中没有存储这些空数据的key。从而导致每次查询都到数据库去了。
那么我们就可以为这些key 设置的值设置为null 丢到缓存里面去。后面再出现查询这个key 的请求的时候,直接返回null ,就不用在到 数据库中去走一圈了。但是别忘了设置过期时间。
2.2.3 布隆过滤器
redis的一个高级用法就是使用布隆过滤器(Bloom Filter),BloomFilter 类似于一个hase set 用来判断某个元素(key)是否存在于某个集合中。这个也能很好的防止缓存穿透的发生,他的原理也很简单就是利用高效的数据结构和算法快速判断出你这个Key是否在数据库中存在,不存在你return就好了,存在你就去查了DB刷新KV再return。
上面介绍了三种方法,用哪种方法最好呢?下面我们来分析一下:
第一种方法,添加参数校验,这里是必须要添加,不过只能过滤掉一些特殊值,比如传的id为负数,如果传的正常id,这里参数校验就不起作用了。
第二种方法,如果有一些恶意攻击,攻击会带来大量的ke y是不存在的,这样采用第二种方法就不合适了。所以针对这种key 异常多,请求重复率比较低的数据,我们就没有必要进行缓存,使用第三种方案直接过滤掉。
如果对于空数据key有限的,重复率比较高的,我们则可以采用第二种方式进行缓存。
3. 缓存击穿
3.1 什么是缓存击穿
我们在平常高并发的系统中,大量的请求同时查询一个key时,假设此时,这个key正好失效了,就会导致大量的请求都打到数据库上面去,这种现象我们称为击穿。
这么看缓存击穿和缓存雪崩有点像,但是又有一点不一样,缓存雪崩是因为大面积的缓存失效,打崩了DB,而缓存击穿不同的是缓存击穿是指一个Key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个Key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个完好无损的桶上凿开了一个洞。
缓存击穿带来的问题就是会造成某一时刻数据库请求量过大,压力剧增。
3.2 解决办法
3.2.1 不过期
我们简单粗暴点,直接让热点数据永远不过期,定时任务定期去刷新数据就可以了。不过这样设置需要区分场景,比如某宝首页可以这么做。
3.2.2 互斥锁
为了避免出现缓存击穿的情况,我们可以在第一个请求去查询数据库的时候对他加一个互斥锁,其余的查询请求都会被阻塞住,直到锁被释放,后面的线程进来发现已经有缓存了,就直接走缓存,从而保护数据库。但是也是由于它会阻塞其他的线程,此时系统吞吐量会下降。需要结合实际的业务去考虑是否要这么做。
总结
好啦,分析到这里就结束了,这一简单介绍了Redis的雪崩,击穿,穿透,三者其实都差不多,但是又有一些区别,在面试中其实这是问到缓存必问的,大家不要把三者搞混了,因为缓存雪崩、穿透和击穿,是缓存最大的问题,要么不出现,一旦出现就是致命性的问题,
再次强调一下,上面这三个知识点真的很重要,因为我们在项目设计时,这些都是要考虑的,所以一定知其所以然。
最后打一波预告吧,下一篇文章内容:《缓存更新的套路》;敬请期待。
结尾给大家发一个小福利吧,最近我在看[微服务架构设计模式]这一本书,讲的很好,自己也收集了一本PDF,有需要的小伙可以到自行下载。获取方式:关注公众号:[Golang梦工厂],后台回复:[微服务],即可获取。
我翻译了一份GIN中文文档,会定期进行维护,有需要的小伙伴后台回复[gin]即可下载。
我是asong,一名普普通通的程序猿,让我一起慢慢变强吧。我自己建了一个golang交流群,有需要的小伙伴加我vx,我拉你入群。欢迎各位的关注,我们下期见~~~

推荐往期文章: