高级数据结构
我们知道Python的变量数据类型有整型、浮点型、复数、字符串和布尔型,我们会发现这些类型结构都比较的简单。在我们学习数学时,有整数、浮点数等这些基本的数据类型,还有数组等这种高级的数据类型供我们来处理一些复杂的数据问题使用。那么Python语言作为一门高级的编程语言,对这些高级的数据结构也是支持的。
下面让我们一块来看下Python的中高级数据结构。
列表与元组
什么是列表
列表,Python 类为list,一种Python的高级数据结构,使用中括号包含,其中内部元素使用逗号分隔,内部元素可以是任何类型包含空。有点像我们数学中学习的数组。
a = [1,2,3]
b = ['1',2,None]
c = [1,2,[3,4]]
d = []
e = [1]知识点:
- 列表中的元素是有序的。
列表的操作
列表的下标操作
- 获取列表中的值
列表和字符串一样是可以通过下标来获取指定位置的元素的。列表的下标是从1开始的,最大下标值为元素个数减1或-1表示。
>>> a = [1,2,3]
>>> print(a[1])
2- 列表更新
可通过列表的下标来替换更新列表中指定元素。
>>> a = [1,2,3]
>>> a[2] = '2'
>>> a
[1, 2, '2']
>>>- 列表的删除
>>> a
[1, 2, '2']
>>> del a[2]
>>> a
[1, 2]- 切片
可通过下标来做列表的截取等操作,在Python中也叫切片。格式如:list[start_index:end_index:step_length]start_index开始下标省略时,默认为 0 ;end_index结束下标省略时,默认为最大下标,及长度-1或-1;step_length步长省略时,默认为1。
>>> a
[1, 2, 3, 4]
>>> a[1:-1]
[2, 3]
>>> t = [1,2,3,4,5]
>>> t[::2]
[1, 3, 5]运算符及内建函数操作
- 可用使用内建函数
len来获取列表的长度,该长度及列表元素的个数。
>>> a
[1, 2]
>>> len(a)
2
>>> a[::2]
[1, 3]- 列表可使用运算符
+实现连接操作。
>>> [1,2,3]+[5,6,7]
[1, 2, 3, 5, 6, 7]- 可以使用内建函数
reversed将列表反转,该函数返回一个迭代器(可理解为一个可遍历对象即可,后边会讲解)。
>>> a = [1,2,3,4]
>>> reversed(a)
>>> list(reversed(a))
[4, 3, 2, 1] 除了使用reversed 函数,也可使用列表的切片来反转:
>>> a
[1, 2, 3, 4]
>>> a[::-1]
[4, 3, 2, 1]- python 可使用
*来实现重复。
>>> [1]*2
[1, 1]- 列表也支持
in、not in成员运算符
>>> 3 in [1,2,3]
True
>>> 3 not in [1,2,3]
False列表的方法
>>> dir(list)
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']-
list.append(obj)在列表末尾添加新的对象 -
list.count(obj)统计某个元素在列表中出现的次数 -
list.extend(seq)在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) -
list.index(obj)从列表中找出某个值第一个匹配项的索引位置 -
list.insert(index, obj)将对象插入列表 -
list.pop([index=-1]])移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 -
list.remove(obj)移除列表中某个值的第一个匹配项 -
list.reverse()反向列表中元素 -
list.sort(cmp=None, key=None, reverse=False)对原列表进行排序 -
list.clear()清空列表 -
list.copy()复制列表
什么是元组
元组,Python中类为 tuple。使用小括号包括,内部元素使用逗号分隔,可为任意值。与列表不同之处为,其内部元素不可修改,及不能做删除、更新操作。
>>> a = (1,2,3)
>>> b = ('1',[2,3])
>>> c = ('1','2',(3,4))
>>> d = ()
>>> e = (1,)说明:
- 当元组中元素只有一个时,结尾要加逗号。若不加逗号,python解释器将解释成元素本身的类型,而非元组类型。
元组的操作
通过下标操作
- 通过小标来获取元素值,使用方法同列表。
- 切片的处理,使用方法同列表。
- 不可通过下标做删除和更新操作。
>>> c[0] = 1
Traceback (most recent call last):
File "", line 1, in
TypeError: 'tuple' object does not support item assignment
>>> del c[0]
Traceback (most recent call last):
File "", line 1, in
TypeError: 'tuple' object doesn't support item deletion 运算符及内建函数操作
- 元组本身是不可变,但是可通过
+来构成新的元组。
>>> a
(1, 2, 3)
>>> b
('1', [2, 3])
>>> a + b
(1, 2, 3, '1', [2, 3])- 可使用内建函数
len获取元组长度。 - 可使用
*元素符实现元素的重复。
>>> a
(1, 2, 3)
>>> a*2
(1, 2, 3, 1, 2, 3)- 元组也支持
in和not in成员运算符。
字典与集合
字典的定义
在编程世界中,有一种高级结构是使用比较广泛的,即key和value值一一对应的映射结构。它就像一个字典一样,通过关键字key,来找到对应的value值。该种结构在Python中叫做字典,英文为dict,使用大括号包括,其中元素为冒号分隔key-value对,中间用逗号分隔。
结构如下:
>>> a = {'name':'Tim', 'age':18}
>>> b = {}
>>> c = dict(name='Tim', age=18)
>>> d = {(1,2):'Time'}知识点:
- 字典中,key 值唯一,且类型为不可变类型,如字符串、元组、数字。
- value 值可以为任意类型;
- 字典中的元素是无序的。
字典的操作
获取字典某元素
可使用key和方法get来获取字典中的值。
>>> a = {'name':'Tim', 'age':18}
>>> a['name']
'Tim'
>>> a.get('name','')
'Tim'
>>> a['address']
Traceback (most recent call last):
File "", line 1, in
KeyError: 'address' 知识点:
- 当字典没有没有该key时,使用key获取,会抛出
KeyError错误;使用get不会抛出,会返回None。- 可使用
get(key,[default])函数给
更新和删除字典
字典是可变的,可通过key来做更新和删除操作。
# 修改
>>> a
{'name': 'Tim', 'age': 18}
>>> a['address'] = 'Beijing'
>>> a
{'name': 'Tim', 'age': 18, 'address': 'Beijing'}
# 删除
>>> del a['age']
>>> a
{'name': 'Tim', 'address': 'Beijing'}字典的方法操作
字典的方法提供了更加丰富的操作功能:
-
radiansdict.clear()删除字典内所有元素 -
radiansdict.copy()返回一个字典的浅复制,返回原字典的引用 -
radiansdict.fromkeys()创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 -
radiansdict.get(key, default=None)返回指定键的值,如果值不在字典中返回default值 -
key in dict如果键在字典dict里返回true,否则返回false -
radiansdict.items()以列表返回可遍历的(键, 值) 元组数组 -
radiansdict.keys()以列表返回一个字典所有的键 -
radiansdict.setdefault(key, default=None)和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default -
radiansdict.update(dict2)把字典dict2的键/值对更新到dict里 -
radiansdict.values()以列表返回字典中的所有值 -
pop(key[,default])删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 -
popitem()随机返回并删除字典中的一对键和值(一般删除末尾对)。
集合的定义
集合(set)和字典(dict)类似,它是一组 key 的集合,但不存储 value。集合的特性就是:key 不能重复。
>>> s = {'1','2','3'} # 不推荐,当元素中有字典时,会报错
>>> s
{'2', '1', '3'}
>>> s2 = set(['1','2','3'])
>>> s2
{'2', '1', '3'}
>>> type(s)
>>> type(s2)
集合的操作
交集、并集和合集
Python中的集合与数学中的集合一样,也有交集、并集和合集。
>>> s1 = {1,2,3,4,5}
>>> s2 = {1,2,3}
>>> s3 = {4,5}
>>> s1&s2 # 交集
{1, 2, 3}
>>> s1|s2 # 并集
{1, 2, 3, 4, 5}
>>> s1 - s2 # 差差集
{4, 5}
>>> s3.issubset(s1) # s3 是否为s1 的子集
True
>>> s1.issuperset(s2) # s1 是否为 s2 的超集
True集合的方法操作
集合中常用方法如下:
-
set.add(obj)添加集合元素 -
set.remove(obj)删除集合元素 -
set.update(set)合并集合 -
set.pop()随机删除一个元素,并返回该元素
序列
序列(sequence),在Python中是一种具有相同特性的高级数据结构的统称,可以使用下标来获取元素和切分。到现在,我们学习了列表、元组、字典和集合4种高级数据结构。可以发现,列表和元组在操作上有许多相同的地方。除了列表和元组,还有字符串也是序列。可见列表、元组、字符串为序列,字典、集合、数值为非序列。
序列的通用操作
- 通过索引来获取元素值
- 分片操作
- 通过
+合并元素 - 通过
*来复制元素 - 支持成员运算符
- 最大值、最小值和长度函数支持
>>> l = [1,2,3]
>>> t = (1,2,3)
>>> s = '123'
>>> print(l[0],t[1],s[2])
1 2 3
>>> print(l[:1],t[:2],s[:-1])
[1] (1, 2) 12
>>> print(l+[4], t+(4,), s+'4' )
[1, 2, 3, 4] (1, 2, 3, 4) 1234
>>> print(l*2, t*2, s*2)
[1, 2, 3, 1, 2, 3] (1, 2, 3, 1, 2, 3) 123123
>>> print(2 in l, 2 in t, '2' in s)
True True True
>>> print(max(l), min(t), len(s))
3 1 3可变类型和不可变类型
除了序列,Python中还可以根据数据结构内存中的数值是否可以被改变,分为可变类型和不可变类型。
这里的可变不可变,是指内存中的值是否可以被改变。如果是不可变类型,在对对象本身操作的时候,必须在内存中新申请一块区域(因为老区域#不可变#)。如果是可变类型,对对象操作的时候,不需要再在其他地方申请内存,只需要在此对象后面连续申请(+/-)即可,也就是它的地址会保持不变,但区域会变长或者变短。
- 可变类型(mutable):列表,字典,集合;
- 不可变类型(unmutable):数字,字符串,元组;
深copy和浅copy
在学习字典时,字典有个copy,可以得到字典的副本。其他类型如何处理呢,Python提供了一个内置的copy库用来支持其他类型的复制。copy库主要有2个方法,copy 和 deepcopy分别表示浅拷贝和深拷贝。浅拷贝是新创建了一个跟原对象一样的类型,但是其内容是对原对象元素的引用。这个拷贝的对象本身是新的,但内容不是。拷贝序列类型对象(列表元组)时,默认是浅拷贝。
下面咱们来分析下浅拷贝和深拷贝的区别。
普通情况下,赋值只是创建一个变量,该变量指向值内存地址,如下例:
n4 = n3 = n2 = n1 = "123/'Wu'"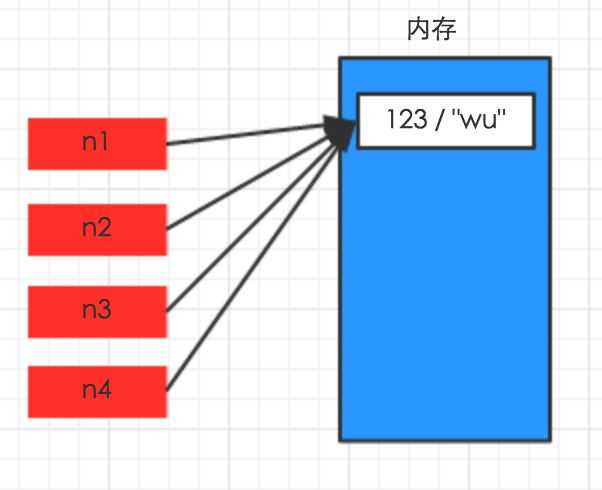
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n2 = n1
浅拷贝,在内存中只额外创建第一层数据,如下图:
import copy
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n3 = copy.copy(n1)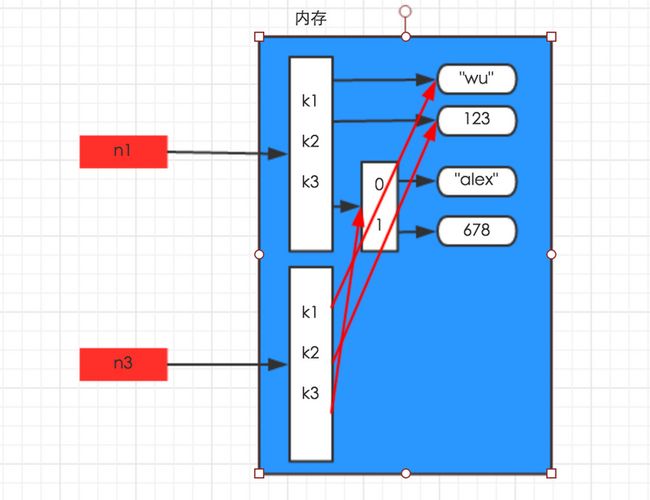
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化),如下图:
import copy
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n4 = copy.deepcopy(n1)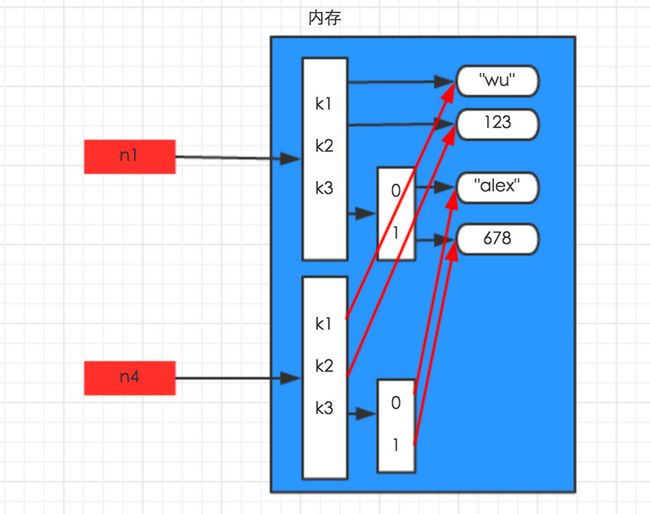
图片来源:博客地址
总结
到此,我们把Python的基本语法和数据结构过了一遍。那我们来总结下,我们都学到了什么:
- 1、高级数据结构及其操作:列表、元组、字典、集合、序列;
这些只是基本语法的组成元素。在程序运行时,可能会有多种情况,需要对这些结构做判断或者需要按顺序读取列表的全部元素,那么这个时候便需要逻辑处理结构。下一章,我们来讲解Python中的逻辑处理的控制流语法。
练习
- 1、现在有一个包含N个元素的元组或者是序列,怎样将它里面的值解压后同时赋值给N个变量?
>>> data = [ 'ACME', 50, 91.1, (2012, 12, 21) ]
>>> name, shares, price, date = data
>>> data = [ 'ACME', 50, 91.1, (2012, 12, 21) ]
>>> _, shares, price, _ = data- 2、怎样从一个集合中获得最大或者最小的N个元素列表?
max([1,2,2,3])
min([1,2,3,4])- 3、大家知道字典是无序的,如何给字典排序?
from collections import OrderedDict
d = OrderedDict()
d['foo'] = 1
d['bar'] = 2
d['spam'] = 3
d['grok'] = 4
print(d)