【摘要】
本文介绍两个文本文件进行比对,按照需求找出文件中数据相同或不同时,会遇到的几种情况,并用 esProc SPL 举例实现。请点击文本文件比对示例了解详情
在数据处理业务中,有时需要比较两个文本文件内容有哪些相同或不同的数据,本文将介绍文本文件比对的几种情况,如整行比对、关键列比对,同时又分小文件、大文件比对,并提供用 esProc SPL 编写的代码示例。esProc 是专业的数据计算引擎,SPL 中有一套完善的集合运算领域的函数库,做文件比对很方便,写出的代码非常简洁。
- 小文件比对
1.1 整行比对
有两个文本文件,其每一行是一个字符串,要对这两个文件中整行内容进行比对。处理此问题可以把文件的每一行读成一个字符串,组成一个集合,然后通过两个集合的运算得出结果。
报名绘画、舞蹈兴趣班的同学学号姓名分别记录在paint.txt和dance.txt中,paint.txt部分数据如下所示:
20121102-Joan
20121107-Jack
20121113-Mike
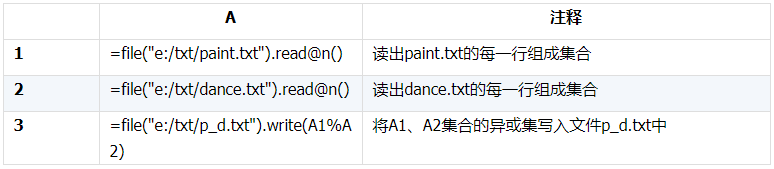
1.1.1. 找相同
把两个文件中整行内容相同的行都找出来,即求两集合的交集。
示例:请找出报了这两个兴趣班的所有同学,记录在p_d.txt文件中。
esProc SPL脚本如下:

1.1.2. 找不同
找不同有以下两种情况:
1、 找出两个文件中所有不相同的行。
示例:找出所有只报了一个兴趣班的同学, esProc SPL脚本如下:
2、找出一个文件中有而另一个文件中没有的行。
示例:找出只报了绘画班的同学和只报了舞蹈班的同学, esProc SPL脚本如下:

1.2 关键列比对
两个文本文件,有多列数据,第一行是列名,第二行开始是数据记录,要对两个文件中关键列的内容进行比对。处理此问题可以把文件读成数据集,取出关键列的记录值组成一个集合,然后通过两个集合的运算得出结果。
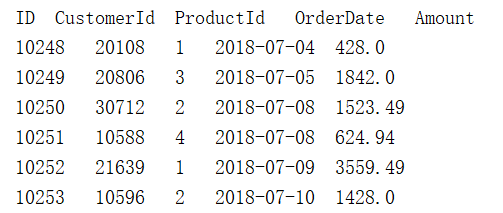
有2018、2019年的销售订单表order_2018.txt和order_2019.txt,两文件有相同的列结构,部分数据如下所示:
1.2.1. 找相同
把两个文件中关键列值相同的都找出来。
示例:请找出这两年都购买了同一种产品的用户CustomerId和产品ProductId,记录在c_p.txt文件中。
esProc SPL脚本如下:

c_p.txt文件中部分数据如下:
CustomerId ProductId
20108 1
20806 3
1.2.2. 找不同
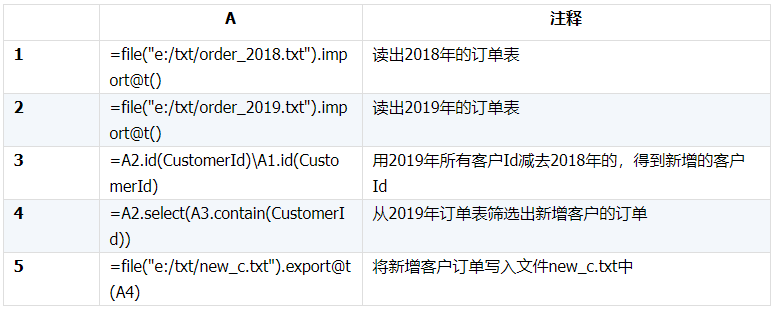
示例1:找出2019年新增客户的订单情况,保存在文件new_c.txt中, esProc SPL脚本如下:
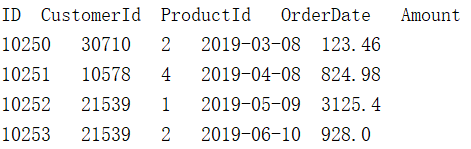
new_c.txt中部分数据如下:
示例2:找出2019年所有流失的客户Id,保存在文件lost_c.txt中, esProc SPL脚本如下:

- 大文件比对
大文件数据不能一次性全部装进内存,不能象小文件数据那样全部读出来再进行比对,需要分批读出数据去比较。esProc SPL提供了游标来处理大文件运算,使大文件比对运算也变得十分方便。
2.1 整行比对
有两个大文本文件,其每一行是一个字符串,要对这两个文件中整行内容进行比对。处理此问题要把文件的每一行读成一个字符串,成为游标中的一条记录,然后通过两个游标的运算得出结果。
现有各州房产产权人员登记表大文件,里面记录产权人的身份证及姓名,部分数据如下所示:
510121198802213364-Joan
110113199203259852-Jack
201264197206271113-Mike
2.1.1. 找相同
把两个文件中整行内容相同的行都找出来,即求两文件的交集。
示例:请找出在Washington和New York两个州都有房产的人员,记录在w_n.txt文件中。
esProc SPL脚本如下:

【注】:若文件中的数据是排好序的,则不再调用sortx函数,以下同
2.1.2. 找不同
示例:现有全国房产产权人员总表all.txt和Washington房产产权人员登记表,请检查总表中是否有遗漏的Washington人员,结果记录在lost_w.txt中。
esProc SPL脚本如下:

2.2 关键列比对
与小文件比对不同,大文件进行关键列比对时要用游标来操作,先按关键列排序,再对两个游标数据进行有序归并计算出需要的结果。
本节仍用小文件比对时的2018、2019年的销售订单表order_2018.txt和order_2019.txt,只是数据量大大增加到大文件的规模。
2.2.1. 找相同
把两个文件中关键列值相同的都找出来。
示例:请找出这两年都购买了同一种产品的用户CustomerId和产品ProductId,记录在c_p.txt文件中。
esProc SPL脚本如下:

2.2.2. 找不同
示例1:找出2019年新增客户的订单情况,保存在文件new_c.txt中, esProc SPL脚本如下:

注:groupx的结果已经按分组字段CustomerId排序。
示例2:找出2019年所有流失的客户Id,保存在文件lost_c.txt中, esProc SPL脚本如下:

- 大文件与小文件比对
大文件与小文件对比时,可以把小文件数据全部读进内存,大文件用游标处理,与小文件的数据进行连接计算。
3.1 整行比对
还用上小节的例子,大文件是各州房产产权人员登记表,小文件是某城市房产产权人员登记表。
3.1.1. 找相同
把两个文件中整行内容相同的行都找出来,即求两文件的交集。
示例:请找出在Washington州和New York城都有房产的人员,记录在w_n.txt文件中。
esProc SPL脚本如下:

3.1.2. 找不同
示例:请检查New York州登记表中是否有遗漏的New York城的人员,结果记录在lost_w.txt中。
esProc SPL脚本如下:

3.2 关键列比对
本节使用2019年的销售订单表order_2019.txt和2019年之前所有年份的订单表order_old.txt,前者是小文件,后者是大文件。
3.2.1. 找相同
示例:请找出2019年及之前某年都购买了同一种产品的用户CustomerId和产品ProductId,记录在c_p.txt文件中。
esProc SPL脚本如下:

3.2.2. 找不同
示例1:找出2019年新增客户的订单情况,保存在文件new_c.txt中, esProc SPL脚本如下:

示例2:找出2019年所有流失的客户Id,保存在文件lost_c.txt中, esProc SPL脚本如下:

《SPL CookBook》,中有更多相关计算示例。