卷积
卷积在数据分析中无处不在。几十年来,它们一直被用于信号和图像处理。最近,它们成为现代神经网络的重要组成部分。如果你处理数据的话,你可能会遇到错综复杂的问题。
数学上,卷积表示为:

尽管离散卷积在计算应用程序中更为常见,但在本文的大部分内容中我将使用连续形式,因为使用连续变量来证明卷积定理(下面讨论)要容易得多。之后,我们将回到离散情况,并使用傅立叶变换在 PyTorch 中实现它。离散卷积可以看作是连续卷积的近似,其中连续函数离散在规则网格上。因此,我们不会为这个离散的案例重新证明卷积定理。
卷积定理
从数学上来说,卷积定理可以这样描述:
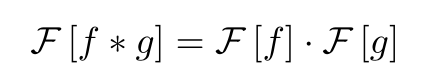
其中的连续傅里叶变换是(达到正常化常数) :
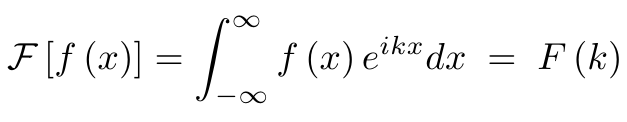
换句话说,位置空间中的卷积等价于频率空间中的直乘。这个想法是相当不直观的,但是对于连续的情况来说,证明卷积定理是惊人的容易。要做到这一点,首先要写出等式的左边。
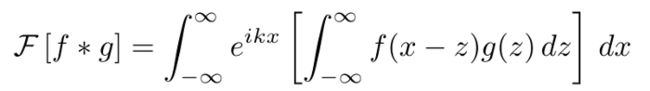
现在切换积分的顺序,替换变量(x = y + z) ,并分离两个被积函数。
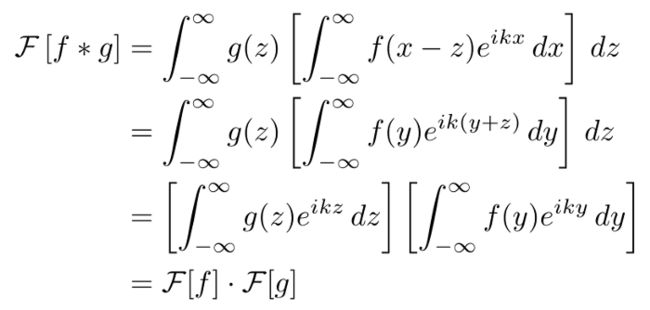
我们为什么要关心这一切?
因为快速傅里叶变换的算法复杂度低于卷积。直接卷积运算具有复杂度 O(n^2) ,因为在 f 中,我们传递 g 中的每个元素,所以可以在 O(nlogn)时间内计算出快速傅立叶变换。当输入数组很大时,它们比卷积要快得多。在这些情况下,我们可以使用卷积定理计算频率空间中的卷积,然后执行逆傅里叶变换回到位置空间。
当输入较小时(例如3x3卷积内核) ,直接卷积仍然更快。在机器学习应用程序中,使用小内核更为常见,因此像 PyTorch 和 Tensorflow 这样的深度学习库只提供直接卷积的实现。但是在现实世界中有很多使用大内核的用例,其中傅立叶卷积算法更有效。
PyTorch 实现
现在,我将演示如何在 PyTorch 中实现傅里叶卷积函数。它应该模仿 torch.nn.functional.convNd 的功能,并利用 fft,而不需要用户做任何额外的工作。因此,它应该接受三个 Tensors (signal、kernel 和可选 bias)和应用于输入的 padding。从概念上讲,这个函数的内部工作原理是:
def fft_conv( signal: Tensor, kernel: Tensor, bias: Tensor = None, padding: int = 0, ) -> Tensor: # 1. Pad the input signal & kernel tensors # 2. Compute FFT for both signal & kernel # 3. Multiply the transformed Tensors together # 4. Compute inverse FFT # 5. Add bias and return
让我们按照上面显示的操作顺序逐步构建 FFT 卷积。对于这个例子,我将构建一个一维傅里叶卷积,但是将其扩展到二维和三维卷积是很简单的。
1. 填充输入数组
我们需要确保 signal 和 kernel 在填充之后有相同的大小。应用初始填充 signal,然后调整 kernel 的填充以匹配。
# 1. Pad the input signal & kernel tensors signal = f.pad(signal, [padding, padding]) kernel_padding = [0, signal.size(-1) - kernel.size(-1)] padded_kernel = f.pad(kernel, kernel_padding)
注意,我只在一边填充 kernel。我们希望原始内核位于填充数组的左侧,这样它就可以与 signal 数组的开始对齐。
2. 计算傅立叶变换
这非常简单,因为 n 维 fft 已经在 PyTorch 中实现了。我们简单地使用内置函数,并计算沿每个张量的最后一个维数的 FFT。
# 2. Perform fourier convolution signal_fr = rfftn(signal, dim=-1) kernel_fr = rfftn(padded_kernel, dim=-1)
3. 变换张量相乘
令人惊讶的是,这是我们功能中最复杂的部分。这有两个原因。(1) PyTorch 卷积运行于多维张量上,因此我们的 signal 和 kernel 张量实际上是三维的。从 PyTorch 文档中的这个方程式,我们可以看到矩阵乘法是在前两个维度上运行的(不包括偏差项) :

我们将需要包括这个矩阵乘法,以及对转换后的维度的直接乘法。
PyTorch 实际上实现了互相关/值方法而不是卷积方法。(TensorFlow 和其他深度学习库也是如此。)互相关与卷积密切相关,但有一个重要的标志变化:

与卷积相比,这有效地逆转了核的方向(g)。我们不是手动翻转内核,而是在傅里叶空间中利用内核的共轭复数来纠正这个问题。由于我们不需要创建一个全新的 Tensor,所以这样做的速度明显更快,内存效率也更高。(本文末尾的附录中简要说明了这种方法的工作原理。)
# 3. Multiply the transformed matrices def complex_matmul(a: Tensor, b: Tensor) -> Tensor: """Multiplies two complex-valued tensors.""" # Scalar matrix multiplication of two tensors, over only the first two dimensions. # Dimensions 3 and higher will have the same shape after multiplication. scalar_matmul = partial(torch.einsum, "ab..., cb... -> ac...") # Compute the real and imaginary parts independently, then manually insert them # into the output Tensor. This is fairly hacky but necessary for PyTorch 1.7.0, # because Autograd is not enabled for complex matrix operations yet. Not exactly # idiomatic PyTorch code, but it should work for all future versions (>= 1.7.0). real = scalar_matmul(a.real, b.real) - scalar_matmul(a.imag, b.imag) imag = scalar_matmul(a.imag, b.real) + scalar_matmul(a.real, b.imag) c = torch.zeros(real.shape, dtype=torch.complex64) c.real, c.imag = real, imag return c # Conjugate the kernel for cross-correlation kernel_fr.imag *= -1 output_fr = complex_matmul(signal_fr, kernel_fr)
PyTorch 1.7改进了对复数的支持,但是在 autograd 中还不支持对复数张量的许多操作。现在,我们必须编写我们自己的复杂 matmul 方法作为一个补丁。虽然不是很理想,但是它确实有效,并且在未来的版本中不会出现问题。
4. 计算逆变换
使用 torch.irfftn 可以直接计算逆变换,然后裁剪出额外的数组填充。
# 4. Compute inverse FFT, and remove extra padded values output = irfftn(output_fr, dim=-1) output = output[:, :, :signal.size(-1) - kernel.size(-1) + 1]
5. 添加偏执项并返回
添加偏差项也很容易。请记住,对于输出阵列中的每个通道,偏置项都有一个元素,并相应地调整其形状。
# 5. Optionally, add a bias term before returning. if bias is not None: output += bias.view(1, -1, 1)
将上述代码整合在一起
为了完整起见,让我们将所有这些代码片段编译成一个内聚函数。
def fft_conv_1d(
signal: Tensor, kernel: Tensor, bias: Tensor = None, padding: int = 0,
) -> Tensor:
"""
Args:
signal: (Tensor) Input tensor to be convolved with the kernel.
kernel: (Tensor) Convolution kernel.
bias: (Optional, Tensor) Bias tensor to add to the output.
padding: (int) Number of zero samples to pad the input on the last dimension.
Returns:
(Tensor) Convolved tensor
"""
# 1. Pad the input signal & kernel tensors
signal = f.pad(signal, [padding, padding])
kernel_padding = [0, signal.size(-1) - kernel.size(-1)]
padded_kernel = f.pad(kernel, kernel_padding)
# 2. Perform fourier convolution
signal_fr = rfftn(signal, dim=-1)
kernel_fr = rfftn(padded_kernel, dim=-1)
# 3. Multiply the transformed matrices
kernel_fr.imag *= -1
output_fr = complex_matmul(signal_fr, kernel_fr)
# 4. Compute inverse FFT, and remove extra padded values
output = irfftn(output_fr, dim=-1)
output = output[:, :, :signal.size(-1) - kernel.size(-1) + 1]
# 5. Optionally, add a bias term before returning.
if bias is not None:
output += bias.view(1, -1, 1)
return output
直接卷积测试
最后,我们将使用 torch.nn.functional.conv1d 来确认这在数值上等同于直接一维卷积。我们为所有输入构造随机张量,并测量输出值的相对差异。
import torch
import torch.nn.functional as f
torch.manual_seed(1234)
kernel = torch.randn(2, 3, 1025)
signal = torch.randn(3, 3, 4096)
bias = torch.randn(2)
y0 = f.conv1d(signal, kernel, bias=bias, padding=512)
y1 = fft_conv_1d(signal, kernel, bias=bias, padding=512)
abs_error = torch.abs(y0 - y1)
print(f'\nAbs Error Mean: {abs_error.mean():.3E}')
print(f'Abs Error Std Dev: {abs_error.std():.3E}')
# Abs Error Mean: 1.272E-05
考虑到我们使用的是32位精度,每个元素相差大约1e-5ー相当精确!让我们也执行一个快速的基准来测量每个方法的速度:
from timeit import timeit
direct_time = timeit(
"f.conv1d(signal, kernel, bias=bias, padding=512)",
globals=locals(),
number=100
) / 100
fourier_time = timeit(
"fft_conv_1d(signal, kernel, bias=bias, padding=512)",
globals=locals(),
number=100
) / 100
print(f"Direct time: {direct_time:.3E} s")
print(f"Fourier time: {fourier_time:.3E} s")
# Direct time: 1.523E-02 s
# Fourier time: 1.149E-03 s
测量的基准将随着您使用的机器而发生显著的变化。(我正在用一台非常旧的 Macbook Pro 进行测试。)对于1025的内核,傅里叶卷积似乎要快10倍以上。
总结
我希望这已经提供了一个彻底的介绍傅里叶卷积。我认为这是一个非常酷的技巧,在现实世界中有很多应用程序可以使用它。我也喜欢数学,所以看到编程和纯数学的结合是很有趣的。欢迎和鼓励所有的评论和建设性的批评,如果你喜欢这篇文章,请鼓掌!
附录:
卷积 vs. 互相关
在本文的前面,我们通过在傅里叶空间中取得内核的互相关共轭复数来实现。这实际上颠倒了 kernel 的方向,现在我想演示一下为什么会这样。首先,记住卷积和互相关的公式:

然后,让我们来看看 g(x) 的傅里叶变换:

注意,g(x)是实值的,所以它不受共轭复数变化的影响。然后,更改变量(y =-x)并简化表达式。

到此这篇关于PyTorch 中的傅里叶卷积实现示例的文章就介绍到这了,更多相关PyTorch 傅里叶卷积内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!