作者:Ron Sobol
翻译:Bach(才云)
校对:星空下的文仔(才云)、bot(才云)
Kubernetes Scheduler 是 Kubernetes 控制平面的核心组件之一。它在控制平面上运行,将 Pod 分配给节点,同时平衡节点之间的资源利用率。将 Pod 分配给新节点后,在该节点上运行的 kubelet 会在 Kubernetes API 中检索 Pod 定义,根据节点上的 Pod 规范创建资源和容器。换句话说,Scheduler 在控制平面内运行,并将工作负载分配给 Kubernetes 集群。
本文将对 Kubernetes Scheduler 进行深入研究,首先概述一般的调度以及具有亲和力(affinity)和 taint 的驱逐调度,然后讨论调度程序的瓶颈以及生产中可能遇到的问题,最后研究如何微调调度程序的参数以适合集群。
调度简介
Kubernetes 调度是将 Pod 分配给集群中匹配节点的过程。Scheduler 监控新创建的 Pod,并为其分配最佳节点。它会根据 Kubernetes 的调度原则和我们的配置选项选择最佳节点。最简单的配置选项是直接在 PodSpec 设置 nodeName:

上面的 nginx pod 默认情况下将在 node-01 上运行,但是 nodeName 有许多限制导致无法正常运行 Pod,例如云中节点名称未知、资源节点不足以及节点网络间歇性问题等。因此,除了测试或开发期间,我们最好不使用 nodeName。
如果要在一组特定的节点上运行 Pod,可以使用 nodeSelector。我们在 PodSpec 中将 nodeSelector 定义为一组键值对:

对于上面的 nginx pod,Kubernetes Scheduler 将找到一个磁盘类型为 ssd 的节点。当然,该节点可以具有其他标签。我们可以在 Kubernetes 参考文档中查看标签的完整列表。
地址:https://kubernetes.io/docs/re...
使用 nodeSelector 有约束 Pod 可以在有特定标签的节点上运行。但它的使用仅受标签及其值限制。Kubernetes 中有两个更全面的功能来表达更复杂的调度需求:节点亲和力(node affinity),标记容器以将其吸引到一组节点上;taint 和 toleration,标记节点以排斥 Pod。这些功能将在下面讨论。
节点亲和力
节点亲和力(Node Affinity)是在 Pod 上定义的一组约束,用于确定哪些节点适合进行调度,即使用亲和性规则为 Pod 的节点分配定义硬性要求和软性要求。例如可以将 Pod 配置为仅运行带有 GPU 的节点,并且最好使用 NVIDIA_TESLA_V100 运行深度学习工作负载。Scheduler 会评估规则,并在定义的约束内找到合适的节点。与 nodeSelectors 相似,节点亲和性规则可与节点标签一起使用,但它比 nodeSelectors 更强大。
我们可以为 podspec 添加四个相似性规则:
- requiredDuringSchedulingIgnoredDuringExecution
- requiredDuringSchedulingRequiredDuringExecution
- preferredDuringSchedulingIgnoredDuringExecution
- preferredDuringSchedulingRequiredDuringExecution
这四个规则由两个条件组成:必需或首选条件,以及两个阶段:计划和执行。以 required 开头的规则描述了必须满足的严格要求。以 preferred 开头的规则是软性要求,将强制执行但不能保证。调度阶段是指将 Pod 首次分配给节点。执行阶段适用于在调度分配后节点标签发生更改的情况。
如果规则声明为 IgnoredDuringExecution,Scheduler 在第一次分配后不会检查其有效性。但如果使用 RequiredDuringExecution 指定了规则,Scheduler 会通过将容器移至合适的节点来确保规则的有效性。
以下是示例:
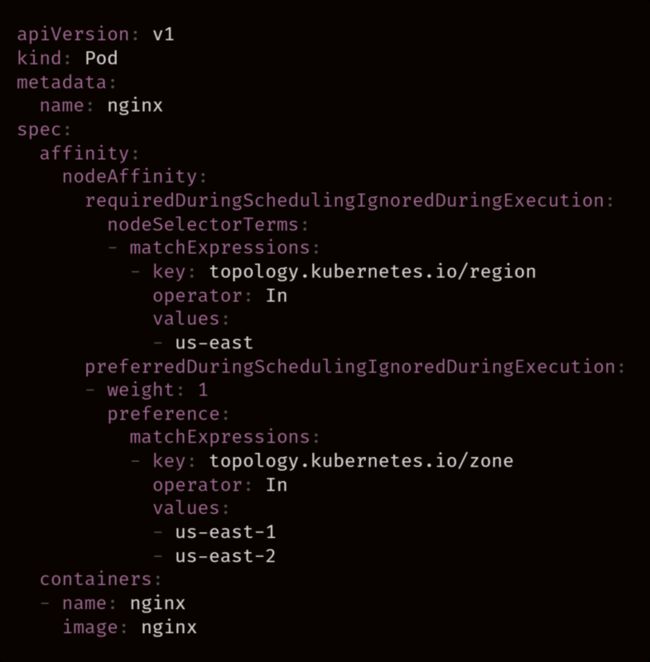
上面的 Nginx Pod 具有节点亲和性规则,该规则让 Kubernetes Scheduler 将 Pod 放置在 us-east 的节点上。第二条规则指示优先使用 us-east-1 或 us-east-2。
使用亲和性规则,我们可以让 Kubernetes 调度决策适用于自定义需求。
K8sMeetup
Taint 与 Toleration
集群中并非所有 Kubernetes 节点都相同。某些节点可能具有特殊的硬件,例如 GPU、磁盘或网络功能。同样,我们可能需要将一些节点专用于测试、数据保护或用户组。我们可以将 Taint 添加到节点以排斥 Pod,如以下示例所示:
kubectl taint nodes node1 test-environment=true:NoSchedule
使用 test-environment=true:NoScheduletaint 时,除非在 podspec 具有匹配的 toleration,否则 Kubernetes Scheduler 将不会分配任何 pod :

taint 和 tolerations 共同发挥作用,让 Kubernetes Scheduler 专用于某些节点并分配特定 Pod。
调度瓶颈
尽管 Kubernetes Scheduler 能选择最佳节点,但是在 Pod 开始运行之后,“最佳节点”可能会改变。所以从长远来看,Pod 的资源使用及其节点分配可能存在问题。
资源请求(Request)和限制(Limit):“Noisy Neighbor”
“Noisy Neighbor”并不特定于 Kubernetes。任何多租户系统都是它们的潜在地。假设有两个容器 A 和 B,它们在同一节点上运行。如果 Pod B 试图通过消耗所有 CPU 或内存来创造 noise,Pod A 将出现问题。如果我们为容器设置了资源请求和限制就能控制住 neighbor。Kubernetes 将确保为容器安排其请求的资源,并且不会消耗超出其资源限制的资源。如果在生产中运行 Kubernetes,最好设置资源请求和限制以确保系统可靠。
系统进程资源不足
Kubernetes 节点主要是连接到 Kubernetes 控制平面的虚拟机。因此,节点上也有自己的操作系统和相关进程。如果 Kubernetes 工作负载消耗了所有资源,则这些节点将无法运行,并会发生各种问题问题。我们需要在 kubelet 中使用 –system -reserved 设置保留资源,以防止发生这种情况。
抢占或调度 Pod
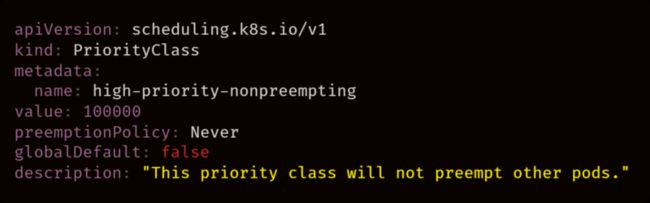
如果 Kubernetes Scheduler 无法将 Pod 调度到可用节点,则可以从节点抢占(preempt)或驱逐(evict)一些 Pod 以分配资源。如果看到 Pod 在集群中移动而没有发现特定原因,可以使用优先级类对其进行定义。同样,如果没有调度好 Pod,并且正在等待其他 Pod,也需要检查其优先级。
以下是示例:
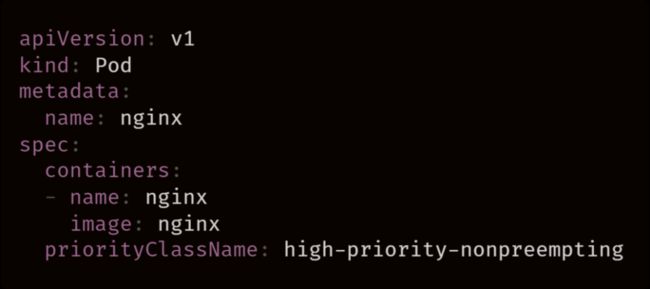
可以通过以下方式在 podspec 中为分配优先级:
调度框架
Kubernetes Scheduler 具有可插拔的调度框架架构,可向框架添加一组新的插件。插件实现 Plugin API,并被编译到调度程序中。下面我们将讨论调度框架的工作流、扩展点和 Plugin API。
工作流和扩展点
调度 Pod 包括两个阶段:调度周期(scheduling cycle)和绑定周期(binding cycle)。在调度周期中,Scheduler 会找到一个可用节点,然后在绑定过程中,将决策应用于集群。
下图说明了阶段和扩展点的流程:
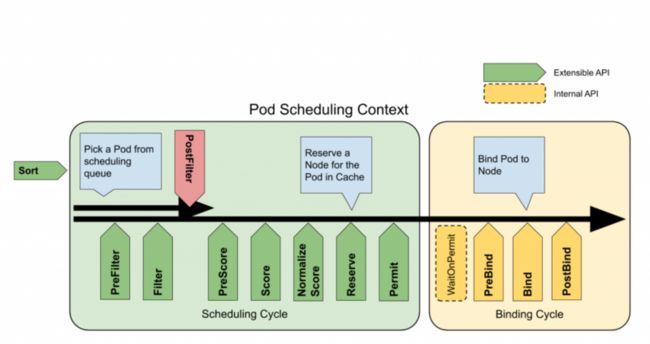
调度工作流(来源:Kubernetes 文档)
工作流中的以下几点对插件扩展开放:
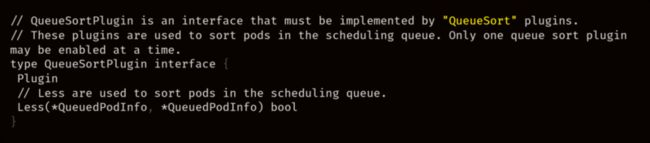
- QueueSort:对队列中的 Pod 进行排序
- PreFilter:检查预处理 Pod 的相关信息以安排调度周期
- Filter:过滤不适合该 Pod 的节点
- PostFilter:如果找不到可用于 Pod 的可行节点,调用该插件
- PreScore:运行 PreScore 任务以生成一个可共享状态供 Score 插件使用
- Score:通过调用每个 Score 插件对过滤的节点进行排名
- NormalizeScore:合并分数并计算节点的最终排名
- Reserve:在绑定周期之前选择保留的节点
- Permit:批准或拒绝调度周期结果
- PreBind:执行任何先决条件工作,例如配置网络卷
- Bind:将 Pod 分配给 Kubernetes API 中的节点
- PostBind:通知绑定周期的结果
插件扩展实现了 Plugin API,是 Kubernetes Scheduler 的一部分。我们可以在 Kubernetes 存储库中检查。插件应使用以下名称进行注册:

插件还实现了相关的扩展点,如下所示:
Scheduler 性能调整
Kubernetes Scheduler 有一个工作流来查找和绑定 Pod 的可行节点。当集群中的节点数量非常多时,Scheduler 的工作量将成倍增加。在大型集群中,可能需要很长时间才能找到最佳节点,因此要微调调度程序的性能,以在延迟和准确性之间找到折中方案。
percentageOfNodesToScore 将限制节点的数量来计算自己的分数。默认情况下,Kubernetes 在 100 节点集群的 50% 和 5000 节点集群的 10% 之间设置线性阈值。默认最小值为 5%,它要确保至少考虑集群中 5% 节点的调度。
下面的示例展示了如何通过性能调整 kube-scheduler 来手动设置阈值:
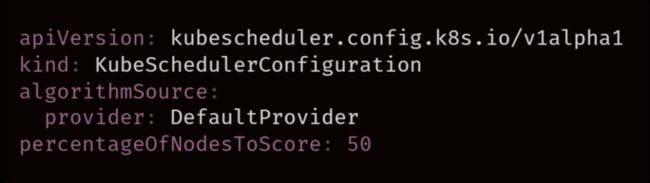
如果有一个庞大的集群并且 Kubernetes 工作负载不能承受 Kubernetes Scheduler 引起的延迟,那么更改百分比是个好主意。
总结
本文涵盖了 Kubernetes 调度的大多方面,从 Pod 和节点的配置开始,包括 nodeSelector、亲和性规则、taint 和 toleration,然后介绍了 Kubernetes Scheduler 框架、扩展点、API 以及可能发生的与资源相关的瓶颈,最后展示了性能调整设置。尽管 Kubernetes Scheduler 能简单地将 Pod 分配给节点,但是了解其动态性并对其进行配置以实现可靠的生产级 Kubernetes 设置至关重要。