内容概述
本文简要介绍下,当项目使用多个数据库的时候,druid如何配置。
文章目录
在之前的文章,SpringBoot系列:1.快速搭建web api项目,提到可以通过很简单的配置实现数据库的访问,例如:
spring:
datasource:
druid:
url: jdbc:mysql://localhost:3306/test_db?zeroDateTimeBehavior=convertToNull&useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: 123456单个数据源的时候,只要加上这些配置,配置druid-spring-boot-starter。无需其他配置代码,就可以实现数据库的访问。
但是实际应用中,即使是微服务,通常也需要访问一个以上的数据库,这时候就需要做些额外的配置,来实现多数据源的访问。下面我们以两个数据源为例,展示下实现的过程。
1.添加两个不同的配置到application.xml中
首先添加要访问的两个数据源的配置信息,假设我们有两个数据库,
test_db作为主库biztest_db作为业务扩展库
则配置内容如下,这里放入spring的配置作对比,可以看到dbconfig是可以独立定义的配置,在程序中可通过 @ConfigurationProperties注解获取。
spring:
redis:
database: 0
host: localhost
port: 6379
session:
store-type: redis
timeout: 600s
dbconfig:
maindb: ##这里只是配置的名字,可以自定义,不会影响连接
url: jdbc:mysql://localhost:3306/test_db?zeroDateTimeBehavior=convertToNull&useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: 123456
bizdb: ##这里只是配置的名字,可以自定义,不会影响连接
url: jdbc:mysql://localhost:6306/biztest_db?zeroDateTimeBehavior=convertToNull&useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
username: biz_rw
password: 6543212.自定义配置类
为了实现对两个数据库的连接,需要分别写两个配置类,配置类的主要功能是:
- 根据不同的配置,生成不同的mysql连接所需的datasource和sqlsession对象,用于对数据库的连接访问。
- 通过
@MapperScan注解,指定哪些mapper使用哪个sqlsession去访问。
下面看配置类的源码,后面会具体的分析下,首先是主库配置类:
@Configuration
@MapperScan(basePackages = "com.yourcom.proname.repository.mapper.testDb*", sqlSessionFactoryRef = "mainSqlSessionFactory")
public class MainDb {
@Primary
@Bean(name = "mainDataSource")
@ConfigurationProperties(prefix = "dbconfig.maindb") //获取application.yml里面的配置信息
public DataSource druidDataSource() {
return DruidDataSourceBuilder.create().build();
}
@Primary
@Bean(name = "mainTransactionManager")
public DataSourceTransactionManager masterTransactionManager(@Qualifier(value = "mainDataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Primary
@Bean(name = "mainSqlSessionFactory")
@ConfigurationPropertiesBinding()
public SqlSessionFactory sqlSessionFactory(@Qualifier(value = "mainDataSource") DataSource dataSource) throws Exception {
MybatisSqlSessionFactoryBean factoryBean = new MybatisSqlSessionFactoryBean();
factoryBean.setDataSource(dataSource);
return factoryBean.getObject();
}
}biz扩展库的配置类:
@Configuration
@MapperScan(basePackages = "com.yourcom.proname.repository.mapper.bizDb*", sqlSessionFactoryRef = "bizSqlSessionFactory")
public class BizDb {
@Bean(name = "bizDataSource")
@ConfigurationProperties(prefix = "dbconfig.bizdb")
public DataSource druidDataSource() {
return DruidDataSourceBuilder.create().build();
}
@Bean(name = "bizTransactionManager")
public DataSourceTransactionManager masterTransactionManager(@Qualifier(value = "bizDataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Bean(name = "bizSqlSessionFactory")
@ConfigurationPropertiesBinding()
public SqlSessionFactory sqlSessionFactory(@Qualifier(value = "bizDataSource") DataSource dataSource) throws Exception {
MybatisSqlSessionFactoryBean factoryBean = new MybatisSqlSessionFactoryBean();
factoryBean.setDataSource(dataSource);
return factoryBean.getObject();
}
}
代码的详细解释:
数据库访问的流程中会创建两个比较重要的对象,datasource和sqlsession。
- 用于管理数据库的连接和会话,不同的数据库要创建不同的配置。
- 对应到上面代码中就是
mainDataSource和mainSqlSessionFactory,这里使用了mybatis中的sqlsession。
@MapperScan,指定要扫描的mapper包,和这个包中的mapper要使用的sqlsession。- 单数据源的时候不用写配置类,这个注解可以直接写在
WebDemoApplication启动类上面。 - 多数据源时,要分别写在每个数据源的配置类上,分别指定对应的mapper使用的sqlsession。这样在开发时直接使用mapper就可以,会自动访问对应的数据库。
- 单数据源的时候不用写配置类,这个注解可以直接写在
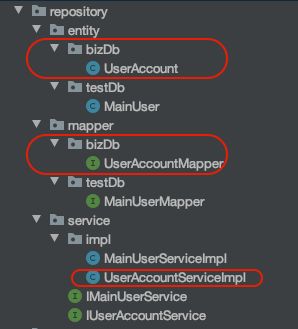
配置之后通过生成工具,生成的代码结构如下,其中testDb中就是主库test_db的mapper,bizDb中就是扩展库biztest_db的mapper。在biztest_db中,有一张表:user_account,对应的生成了UserAccountMapper实体类。
3.在controller中使用
下面看下如何在controller中访问不同数据库中的表。
这里实现一个接口,先通过userId判断主库中用户是否存在,然后获取用户的账户信息。
@RestController
public class UserController {
@Resource
IMainUserService mainUserService;
@Resource
IUserAccountService userAccountService;
/**
* 根据id获取用户账户信息
*
* @return
*/
@GetMapping("user/account")
public CommonResVo getUserAccount(Integer userId) throws Exception {
MainUser mainUser = mainUserService.getById(userId);
if (mainUser == null) {
throw new Exception("用户不存在");
}
UserAccount userAccount = userAccountService.getOne(new LambdaQueryWrapper().eq(UserAccount::getUserId, mainUser.getUserId()));
return CommonResVo.success(userAccount);
}
} 这里使用的是service,和mapper的使用差不多,功能更全一点。可以看到,在使用时不再需要关心应该使用哪个数据库,只要用对了表,直接使用就可以。
代码的完整示例地址:https://gitee.com/dothetrick/...
以上内容属个人学习总结,如有不当之处,欢迎在评论中指正
欢迎关注我的公众号查看更多文章:
