CPU Flame Graphs
确定 CPU 忙的原因是性能分析的常规任务,这通常涉及分析堆栈跟踪。以固定速率采样分析是查看哪些代码路径是热门代码(On-CPU)的粗糙但有效的方法。它通常通过创建一个时间中断来收集当前程序计数器、函数地址或整个堆栈回溯,并将这些中断转换为可读的摘要报告。
分析数据可能长数千行,难以理解。火焰图是采样堆栈跟踪的可视化效果,可快速识别热代码路径。有关 CPU 分析以外的此可视化效果的使用,请参阅Flame Graphs主页。
火焰图可与任何操作系统上的任何 CPU 探查器一起使用。我的示例使用 Linux perf_events、DTrace、SystemTap 和 ktap。有关其他探查器示例,请参阅Updates列表;有关火焰图软件,请参阅 github。
在此页面上,我将介绍和解释 CPU 火焰图,列出创建它们的通用说明,然后讨论特定语言的生成。
目录:
1. Problem
2. Flame Graph
3. Description
4. Instructions
5. Examples
6. C
7. C++
8. Java
9. Node.js
10. Other Languages
11. Other Uses
12. Background
13. References
- Problem
在这里, 我使用 Linux perf_events (又名 "perf" 命令) 来分析正在消耗 Cpu 的 bash 程序:

perf record 命令以 99 赫兹 (-F 99) 采样,在我们的目标 PID (-p 13204) 上采样,并捕获堆栈跟踪 (-g --),用于调用图形信息。
perf report 命令在将数百个堆栈跟踪样本汇总为文本。类似的代码路径是一起,摘要显示为树形图,每个叶上都有百分比。从左上到右下读取路径,该路径遵循代码路径的祖先(及其堆栈跟踪示例)。百分比必须相乘,以确定完整堆栈跟踪的绝对频率。
显示的第一个堆栈do_redirection_internal())仅占样本的 2%。下一个堆栈跟踪(execute_builtin_or_function(),1%。因此,在阅读了这个文本屏幕后,我们只能占到样本的3%。为了了解 CPU 的大部分时间花费在哪里,我们希望了解超过 50% 的代码路径。我们可能需要做更多的阅读。
Too Much Data
上述输出已被截断,仅显示超过 8,000 行输出中的 45 行。可视化的完整输出如下所示:

你能看到前面两个堆栈吗?他们在左上角。(Other versions: text, larger JPG.)
{kind=link}
有时,CPU 时间的大部分位于单个代码路径中,perf 报表在单个屏幕上轻松汇总此内容。但是,您通常需要阅读许多屏幕全文才能了解配置文件,这既耗时又乏味。
- The Flame Graph
现在,我们用火焰图显示相同数据:
如果您的浏览器中遇到问题,请尝试直接 SVG 或 PNG 版本。
{kind=link}
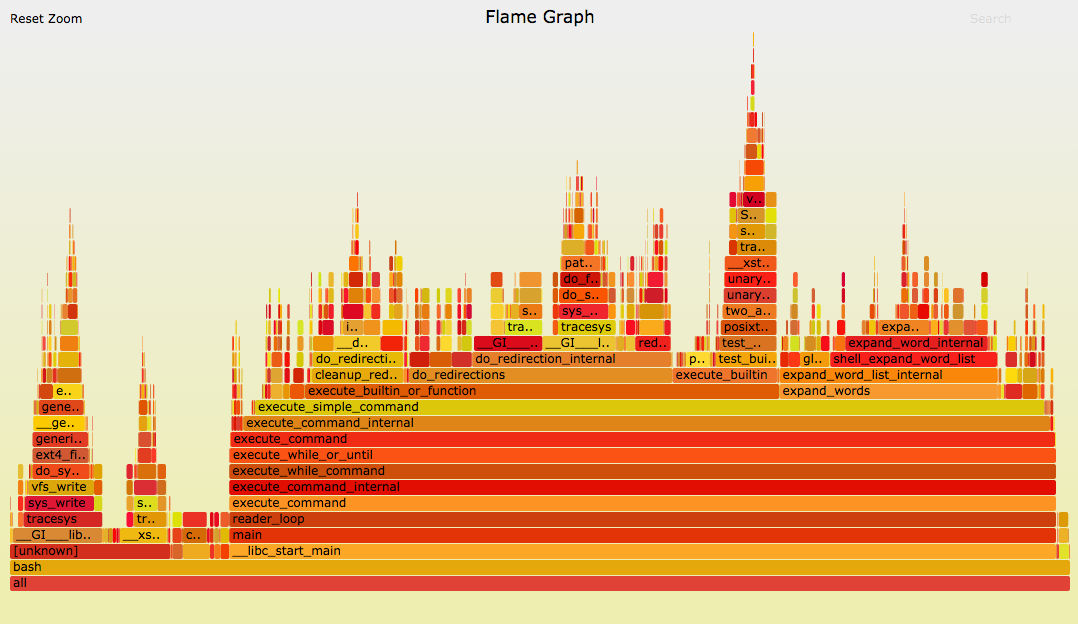{kind=link}
使用火焰图时,所有数据都同时在屏幕上,最热的代码路径作为最宽的函数立即显而易见。
- Description
我会仔细解释这一点:它可能看起来类似于来自探查器的其他可视化效果,但它是不同的。
- 每个框表示堆栈中的函数(a "stack frame")。
- y 轴显示堆栈深度(number of frames on the stack)。顶部框显示 on-CPU 的函数。下面是祖先函数。函数下方的函数是它的父函数,就像前面显示的堆栈跟踪一样。(某些火焰图实现倾向于反转顺序并使用"冰柱布局",因此火焰看起来颠倒过来。
- x 轴跨越样本总体。它不显示时间从左到右的传递,就像大多数图形一样。从左到右排序没有意义(按字母顺序排序以最大化帧合并)。
- 框的宽度显示它在 On-CPU 或 On-CPU 的祖先的一部分的总时间(基于样本计数)。具有宽框的函数在执行时可能比使用窄框的函数消耗更多的 CPU,或者,它们可能只是被调用更频繁。未显示呼叫计数(或通过采样已知)。
- 如果多个线程同时运行和采样,样本计数可能会超过已用时间。
火焰图颜色不固定,通常随机挑选为暖色(支持其他有意义的调色板)。此可视化效果称为"火焰图",因为它首次用于显示 CPU 上的热内容,并且,它看起来像火焰。它也是交互式的:鼠标悬停在SVG上以显示细节,然后单击以缩放。
./flamegraph.pl --color=io --title="Off-CPU Time Flame Graph" --countname=us
- Instructions
火焰图FlameGraph tool工具和说明的代码在 github 上。这是一个简单的 Perl 程序,输出 SVG。它们分三个步骤生成:
1. Capture stacks
2. Fold stacks
3. flamegraph.pl
第一步是使用您选择的探查器。有关使用 perf、DTrace、SystemTap 和 ktap 的一些示例,请参阅下文。
第二步生成基于行的输出文件便于flamegraph.pl读取,也可以进行 grep'd 以筛选感兴趣的函数。有一组简单的 Perl 程序来做到这一点,名为 stackcollapse*.pl,用于处理来自不同探查器的输出。
perf
Linux perf_events具有多种功能,包括 CPU 采样。使用它来采样所有 CPU 并生成火焰图:
# git clone https://github.com/brendangregg/FlameGraph # or download it from github
# cd FlameGraph
# perf record -F 99 -a -g -- sleep 60
# perf script | ./stackcollapse-perf.pl > out.perf-folded
# ./flamegraph.pl out.perf-folded > perf-kernel.svg
perf record 命令在所有 CPU (-a) 上以 99 赫兹 (-F 99) 的速度采样,捕获堆栈跟踪,以便以后可以生成函数祖先的调用图 (-g)。示例保存在 perf.data 文件中,由 perf script 读取。
我创建中间文件perf-folded,使其在从同一数据创建多个过滤火焰图时速度更快一些。例如:
# perf script | ./stackcollapse-perf.pl > out.perf-folded
# grep -v cpu_idle out.perf-folded | ./flamegraph.pl > nonidle.svg
# grep ext4 out.perf-folded | ./flamegraph.pl > ext4internals.svg
# egrep 'system_call.*sys_(read|write)' out.perf-folded | ./flamegraph.pl > rw.svg
处理 perf report的结果会更有效率一点;更好的是, perf report可以有一个报表样式 (例如, "- g 折叠"), 直接输出折叠堆栈, 无需stackcollapse-perf.pl。甚至有一个直接输出火焰图SVG的 perf 模式,不过,这将错过能够修改折叠堆栈的价值。
For more details, see my perf_events Flame Graphs page.
DTrace
DTrace 可用于在支持它(Solaris、BSD)的系统上对 CPU 上堆栈跟踪进行配置文件。下面的示例使用 DTrace 为名为"mysqld"的进程以 99 赫兹对用户级堆栈进行采样,然后生成火焰图(请参阅稍后的 MySQL 示例):
# git clone https://github.com/brendangregg/FlameGraph # or download it from github
# cd FlameGraph
# dtrace -x ustackframes=100 -n 'profile-99 /execname == "mysqld" && arg1/ {
@[ustack()] = count(); } tick-60s { exit(0); }' -o out.stacks
# ./stackcollapse.pl out.stacks > out.folded
# ./flamegraph.pl out.folded > out.svg
中间文件out.folded是没有必要的,因为stackcollapse.pl的输出可以直接通过管道传递给flamegraph.pl。然而,有些情况下,如果想使用vi编辑文件(例如,在采样内核时,要查找和删除空闲线程)就很方便。
要解释"arg1"检查:arg1 是user-land程序计数器,因此确认它是非零的;arg0 是内核。以下是用于测试内核的 DTrace 命令示例:
# dtrace -x stackframes=100 -n 'profile-199 /arg0/ {
@[stack()] = count(); } tick-60s { exit(0); }' -o out.stacks
这一次,所有线程都进行采样,因此输出将包含许多空闲线程样本(您可以使用 DTrace 筛选它们,也可以使用 grep/vi 筛选折叠的输出)。速率也增加到 199 赫兹,因为捕获内核堆栈比用户级堆栈便宜得多。奇数编号的速率 99 和 199 用于避免与其他活动一致采样并产生误导性结果。
SystemTap
SystemTap 还可以通过timer.profile 探测器对堆栈跟踪进行采样,该探测器以系统时钟速率(CONFIG_HZ)。与将示例转储到文件以进行以后聚合和报表的 perf 不同,SystemTap 可以在内核中执行聚合,并把小得多报告传递给user-land。收集的数据和生成的输出可以通过其脚本语言进一步自定义。
在 Fedora 16 上使用 SystemTap v1.7 生成火焰图:
# stap -s 32 -D MAXBACKTRACE=100 -D MAXSTRINGLEN=4096 -D MAXMAPENTRIES=10240 \
-D MAXACTION=10000 -D STP_OVERLOAD_THRESHOLD=5000000000 --all-modules \
-ve 'global s; probe timer.profile { s[backtrace()] <<< 1; }
probe end { foreach (i in s+) { print_stack(i);
printf("\t%d\n", @count(s[i])); } } probe timer.s(60) { exit(); }' \
> out.stap-stacks
# ./stackcollapse-stap.pl out.stap-stacks > out.stap-folded
# cat out.stap-folded | ./flamegraph.pl > stap-kernel.svg
上面使用了六个选项 (-s 32,-D...) 增加了各种SystemTap限制。火焰图唯一真正需要的是"-D MAXBACKTRACE=100 -D MAXSTRINGLEN=4096",这样堆栈轨迹不会截断;在繁忙工作负载上长时间采样(本例中为 60 秒)时,需要其他采样,以避免各种阈值和溢出错误。
使用timer.profile 探针,以 100 赫兹对所有 CPU 进行采样:有点粗糙,并冒着lockstep采样的风险。上次我检查时,计时器.hz(997) 探头以正确的速率发射,但无法读取堆栈回溯。
ktap
ktap 已经通过 ktap 的scripts/profiling/stack_profile.kp 脚本支持 CPU 火焰图,该脚本捕获示例数据。下面是使用 ktap one-liner而不是该脚本的步骤:
# ktap -e 's = ptable(); profile-1ms { s[backtrace(12, -1)] <<< 1 }
trace_end { for (k, v in pairs(s)) { print(k, count(v), "\n") } }
tick-30s { exit(0) }' -o out.kstacks
# sed 's/ //g' out.kstacks | stackcollapse.pl > out.kstacks.folded
# ./flamegraph.pl out.kstacks.folded > out.kstacks.svg
sed(1) 命令删除制表符(这是制表符,而不是一系列空格),stackcollapse.pl处理文本。一stackcollapse-ktap.pl可以轻松地编写到直接处理 ktap 输出,并避免对 sed(1) 的需要。
This full example is on my ktap page under ktap Flame Graphs.
Other Profilers
有关其他探查器,请参阅Flame Graphs主页上的更新链接。其中包括戴夫·帕切科的node.js functions,马克·普罗布斯特的OS X上的Flame Graphs for Instruments,以及布鲁斯·道森在微软Windows上的Summarizing Xperf CPU Usage with Flame Graphs。
- Examples
下一个示例使用 DTrace 分析 MySQL,然后使用 DTrace 分析 Linux 内核的两个 CPU perf_events。这些是不支持单击缩放的旧示例(您仍然可以按鼠标悬停查看详细信息)。
Linux 示例是在 KVM (Ubuntu 主机) 下运行的 3.2.9 (Fedora 16 来宾) 上生成的,并配有一个虚拟 CPU。某些代码路径和采样比率在裸机上会大不相同:例如,网络不会通过 virtio-net 驱动程序进行处理。
MySQL
这是导致我创建火焰图的原始性能问题。这是一个生产 MySQL 数据库, 消耗的 CPU 比希望的要多。可用的探查器是 DTrace, 我使用它频率计数 CPU 用户级堆栈:
# dtrace -x ustackframes=100 -n 'profile-997 /execname == "mysqld"/ {
@[ustack()] = count(); } tick-60s { exit(0); }'
dtrace: description 'profile-997 ' matched 2 probes
CPU ID FUNCTION:NAME
1 75195 :tick-60s
[...]
libc.so.1`__priocntlset+0xa
libc.so.1`getparam+0x83
libc.so.1`pthread_getschedparam+0x3c
libc.so.1`pthread_setschedprio+0x1f
mysqld`_Z16dispatch_command19enum_server_commandP3THDPcj+0x9ab
mysqld`_Z10do_commandP3THD+0x198
mysqld`handle_one_connection+0x1a6
libc.so.1`_thrp_setup+0x8d
libc.so.1`_lwp_start
4884
mysqld`_Z13add_to_statusP17system_status_varS0_+0x47
mysqld`_Z22calc_sum_of_all_statusP17system_status_var+0x67
mysqld`_Z16dispatch_command19enum_server_commandP3THDPcj+0x1222
mysqld`_Z10do_commandP3THD+0x198
mysqld`handle_one_connection+0x1a6
libc.so.1`_thrp_setup+0x8d
libc.so.1`_lwp_start
5530
此处显示了最后两个最常见的堆栈。最后一次是在 CPU 上采样 5,530 次,看起来是 MySQL 在做一些系统状态内务管理。如果这是最热的, 我们知道我们有一个 Cpu 问题, 也许我应该去寻找可调性来禁用系统统计数据。
问题是,大部分输出都从此屏幕截图中截断("[...]"),并且(与 Linux perf 不同),DTrace 不打印百分比,因此您不确定这些堆栈真正重要多少。我根据样本总数(即 348,427)手动计算百分比,结果令我沮丧的是,这两个堆栈仅代表不到 3% 的 CPU 样本。
相同的 MySQL 配置文件数据,呈现为火焰图:

您可以对元素进行鼠标悬停以查看百分比(但无法单击缩放,因为这是旧版本),显示分析数据中元素的频繁存在。您还可以单独查看 SVG 或 PNG 版本。
{kind=link}
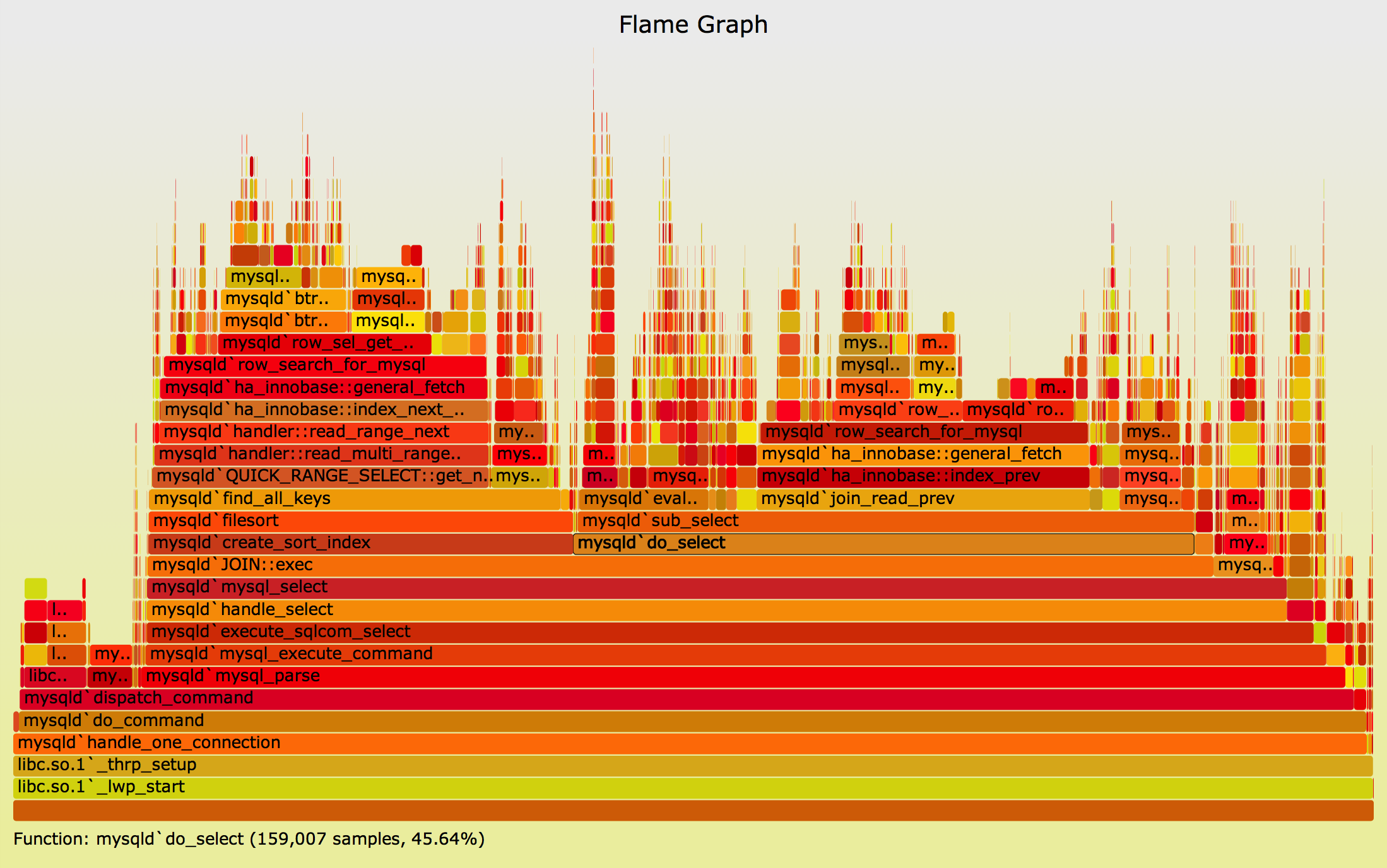{kind=link}
较早截断的文本输出将 MySQL 状态堆栈标识为最热。火焰图显示了现实:大多数时候真的是在JOIN::exec。这指出了调查的方向:JOIN::exec,以及上面的功能,并导致问题得到解决。
File Systems
作为不同工作负载的示例,这显示了在存档 ext4 文件系统时 Linux 内核 CPU 时间(SVG, PNG):
{kind=link}
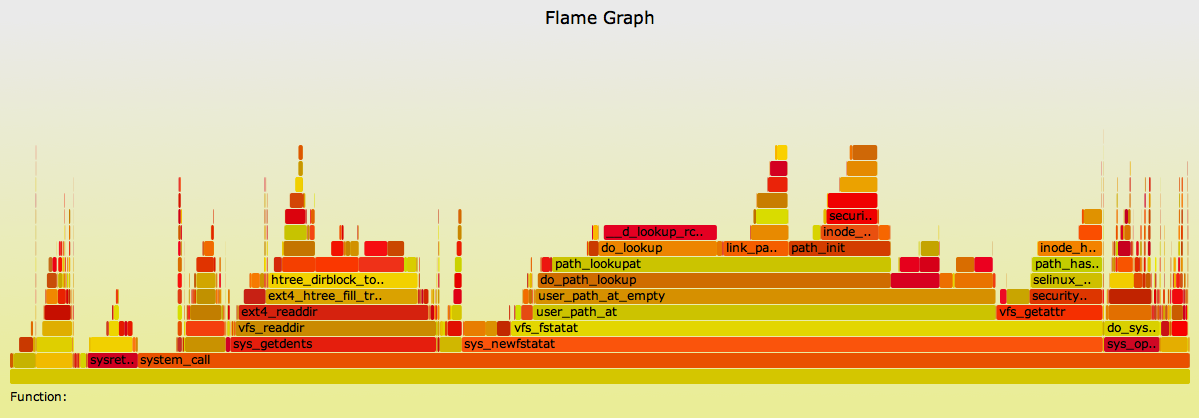{kind=link}

这显示了文件系统的读取以及内核 CPU 时间花费的时间。大多数内核时间是在 sys_newfstatat() 和 sys_getdents(): 元数据工作作为文件系统的步行。sys_openat() 在右侧,因为打开文件要读取,然后是 mmap()d(查看 sys_getdents(),这些是按字母顺序排列的),最后页面有故障进入用户空间(请参阅左侧的 page_fault() )。
然后,移动字节的实际工作将用user-land中的 mmap'd 段的上(内核火焰图中未显示)。如果归档程序使用 read() 系统调用代替,此火焰图将看起来非常不同,并且具有较大的 sys_read() 组件。
Short Lived Processes
对于此火焰图,我执行了短期进程工作负载,以查看内核时间在创建中花费的时间(SVG, PNG):
{kind=link}
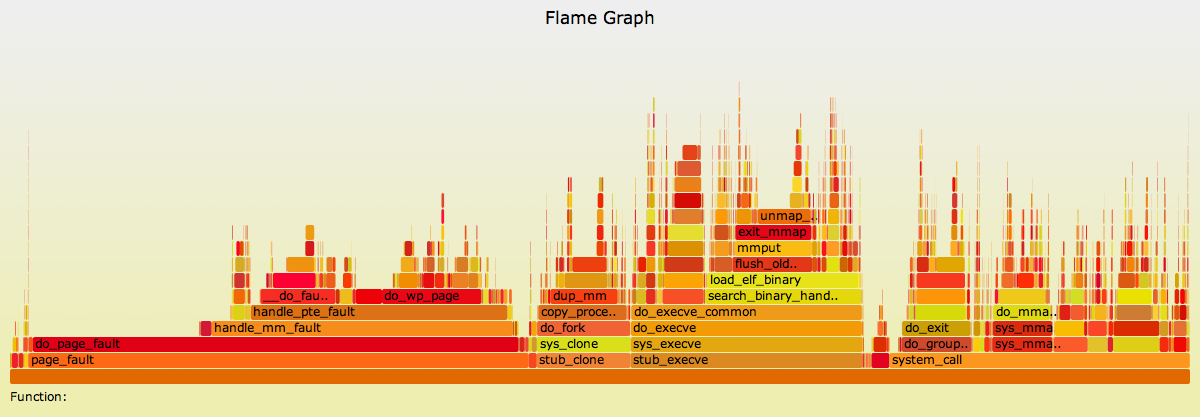{kind=link}

除了性能分析之外,这也是学习Linux内核内部功能的一个很好的工具。
User+Kernel Flame Graph
此示例显示 illumos 内核虚拟机管理程序主机上的用户和内核堆栈(SVG, PNG) :
{kind=link}
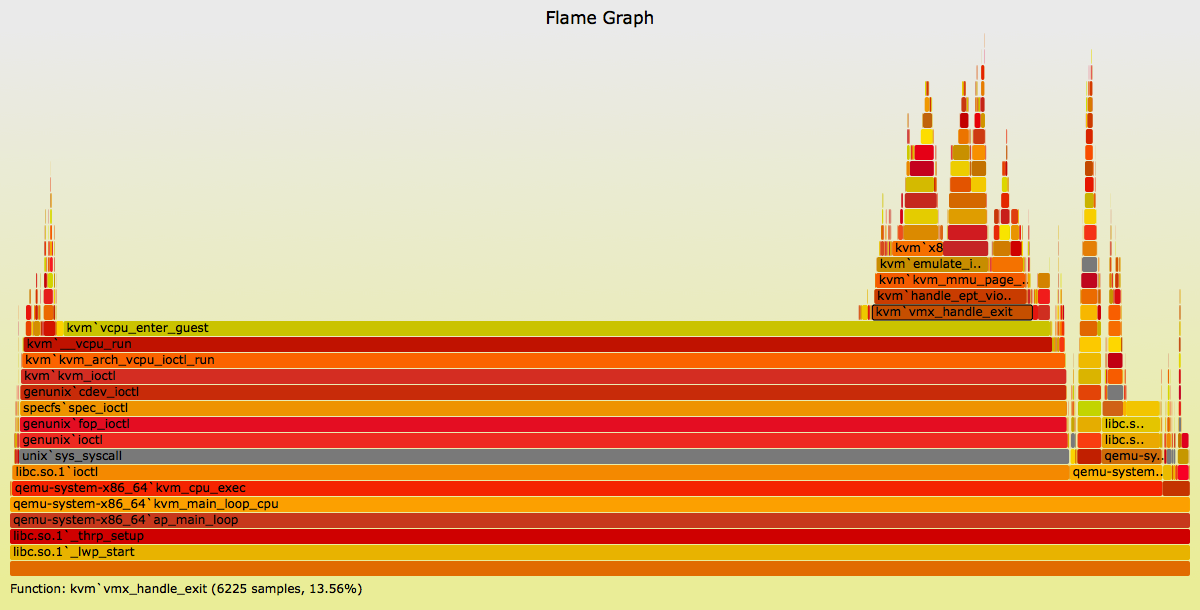{kind=link}

您还可以查看独立的 SVG和 PNG 版本。这显示了 qemu 线程 3 的 CPU 使用情况,即 KVM 虚拟 CPU。包括用户和内核堆栈(DTrace 可以同时访问这两个堆栈),系统调用介于彩色灰色之间。
系统(vcpu_enter_guest)是该虚拟 CPU 在虚拟机内执行代码的地方。我更感兴趣的是右边的山,来检查KVM出口代码路径的性能。
- C
易于分析,请参阅步骤说明Instructions。一个陷阱是,许多编译器(包括 gcc)不将帧指针寄存器作为编译器优化,这打破了基于帧指针的堆栈步走。这通常发生在通过 Linux 存储库安装的软件中,并且您的火焰图将丢失塔。修复程序包括:
- Recompile with -fno-omit-frame-pointer.
- On Linux: install debuginfo for the software with DWARF data and use perf's DWARF stack walker.
- C++
易于分析,但可能会因为与 C 相同的原因而遭受堆栈跟踪损坏:请参阅profiling C部分。
- Java
我的 JavaOne 2016 使用火焰图在 Linux 上讨论 Java 性能分析,总结了使用 Linux perf 生成混合模式火焰图的最新技术。
Background
为了生成火焰图,您需要一个可以采样堆栈轨迹的探查器。历史上有两种类型的探查器:
- System profilers: like Linux perf, which shows system code paths (eg, JVM GC, syscalls, TCP), but not Java methods.
- JVM profilers: like hprof, LJP, and commercial profilers. These show Java methods, but usually not system code paths.
可以使用 (1) 执行火焰图,具体方法如前所述。(2) 取决于要使用的探查器。火焰图软件包括stackcollapse-ljp.pl,用于处理Lightweight Java Profiler (LJP)的输出。我的博客文章Java Flame Graphs总结了如何使用 LJP。如果创建系统火焰图(例如,在 Linux 上使用 perf)以及 LJP 火焰图,通常可以通过检查两者来解决所有问题。
理想情况下,我们有一个火焰图可以实现这一切:系统和Java代码路径。除了方便之外,它还在Java上下文中显示系统代码路径,这对正确理解配置文件至关重要。
问题是让系统探查器了解 Java 方法和堆栈跟踪。例如,如果您使用Linux的perf_events ,你会看到十六进制数字和断开的堆栈跟踪,因为它无法将地址转换为 Java 符号,并且无法跟踪 JVM 堆栈。DTrace 长期以来一直支持 jstack() 操作,但该操作也有问题,稍后将介绍。
有两个具体问题:
- The JVM compiles methods on the fly (just-in-time: JIT), and doesn't expose a traditional symbol table for system profilers to read.
- The JVM also uses the frame pointer register (RBP on x86-64) as a general purpose register, breaking traditional stack walking.
Linux perf_events
解决上述两个问题的一种方法:
- A JVMTI agent, perf-map-agent (previously here), which can provide a Java symbol table for perf to read (/tmp/perf-PID.map).
- The -XX:+PreserveFramePointer JVM option, so that perf can walk frame pointer-based stacks.
将 PreserveFramePointer 添加到 JDK8u60 中,以方便 perf 和火焰图生成(我通过电子邮件发送了一个原型到热点编译器开发人员邮件列表,[A hotspot patch for stack profiling (frame pointer),该修补程序成为 JDK-8068945: Use RBP register as proper frame pointer in JIT compiled code on x64。我在 Netflix Tech 博客上总结了最后一步: Java in Flames。以下是更新的步骤:
- install perf-map-agent:
sudo bash
apt-get install cmake
export JAVA_HOME=/path-to-your-new-jdk8
cd /destination-for-perf-map-agent # I use /usr/lib/jvm
git clone --depth=1 https://github.com/jvm-profil...
erf-map-agent
cmake .
make - profiling and flame graph generation:
git clone --depth=1 https://github.com/brendangre...
sudo bash
perf record -F 49 -a -g -- sleep 30; ./FlameGraph/jmaps
perf script > out.stacks01
cat out.stacks01 | ./FlameGraph/stackcollapse-perf.pl | grep -v cpu_idle | \
/FlameGraph/flamegraph.pl --color=java --hash > out.stacks01.sv
请注意,jmap(调用 perf 映射代理执行符号转储的帮助程序脚本)要在 perf 记录后立即运行,以最大限度地减少符号改动。
产生火焰图的示例是 (SVG, 支持点击缩放):
{kind=link}

运行flamegraph.pl使用 --color=java,它使用不同的帧类型使用不同的色调。绿色为 Java,黄色C++,橙色为内核,红色为剩余(本机用户级别或内核模块)。
这是目前的概念证明,并且不支持该修补程序。有关讨论和状态,请参阅邮件列表,以及有关此方法的注意事项。返回帧指针确实会花费一些性能(取决于工作负载,可能可以忽略不计),并且火焰图不显示内线方法。我希望修补程序作为可调选项包含在内,例如 -XX:NoOmitFramePointer。
DTrace
DTrace 使用 jstack() 操作可以分析用户级堆栈以及 Java 方法和类。(In theory: see the bugs listed below.)它使用的功能称为"DTrace ustack helper"(搜索该术语以了解有关它们了解更多信息)。因此,要为 Java 程序生成 CPU 火焰图,可以使用以下方法收集堆栈:
# dtrace -n 'profile-97 /execname == "java"/ { @[jstack(100, 8000)] = count(); }
tick-30s { exit(0); }' -o out.javastacks_01
然后,可以将输出文件stackcollapse.pl和 flamegraph.pl,如前面各节所示。
ustack 帮助器操作是 jstack(),如果工作,您将有看起来像这样的堆栈:
libjvm.so`jni_GetObjectField+0x10f
libnet.so`Java_java_net_PlainSocketImpl_socketAvailable+0x39
java/net/PlainSocketImpl.socketAvailable()I*
java/net/PlainSocketImpl.available()I*
java/lang/Thread.run()V
0xfb60035e
libjvm.so`__1cJJavaCallsLcall_helper6FpnJJavaValue_pnMmethodHa...
libjvm.so`__1cCosUos_exception_wrapper6FpFpnJJavaValue_pnMmeth...
libjvm.so`__1cJJavaCallsMcall_virtual6FpnJJavaValue_nGHandle_n...
libjvm.so`__1cMthread_entry6FpnKJavaThread_pnGThread__v_+0x113
libjvm.so`__1cKJavaThreadDrun6M_v_+0x2c6
libjvm.so`java_start+0x1f2
libc.so.1`_thrp_setup+0x88
libc.so.1`_lwp_start
9请注意,它包括libjvm帧和类/方法:java/net/PlainSocketImpl.available()等。如果没有可见的类/方法,只有十六进制数字,则需要让 jstack() 先工作。
不幸的是,这个方法有多个问题。首先,jstack() 在许多 JVM 版本中都不起作用。有关列表,请参阅bug JDK-7187999。幸运的是,第一个问题有解决方法,在Adam's email和 illumos issue 3123 中描述,最终的用法(自从他最初的建议以来已更改)涉及在启动 Java 程序时设置一个环境变量,以确保加载 ustack 帮助程序。例如:
illumos# LD_AUDIT_32=/usr/lib/dtrace/libdtrace_forceload.so java myprog
请注意,这可能会增加超过 60 秒的启动时间。(这本身需要性能分析。)
将生成的火焰图视为 SVG 或 PNG。工作负载是 ttcp(测试 TCP),这是用 Java 编写的 TCP 基准。火焰图显示,大多数 CPU 时间都花在套接字写入()中,9.2% 的时间用于 releaseFD()。
{kind=link}
{kind=link}
第二个问题,jstack() 可能无法正确走堆栈,由于错误 JDK-6276264,在 2005 年提交,截至 2014 年未修复。对于我的生产工作负载,几乎所有采样堆栈都由于此 Bug 而损坏。jstack() 无法使用。
- Node.js
v8 与 Java 有类似的问题。理想情况下,我们希望使用一些探查器来采样系统代码路径和 v8 JavaScript 代码路径。
Linux perf_events
使用perf_events(v8选项 --perf_basic_prof或perf_basic_prof_only_functions)可以分析JavaScript堆栈。请参阅我的博客Node Flame Graphs on Linux。还有特雷弗·诺里斯的原始说明instructions,还有他的example。
Here is an example Linux perf CPU flame graph (SVG):
{kind=link}

这使用 --color=js 使用不同的色调:green == JS, aqua == built-ins, yellow == C++, red == system(本机用户级别和内核)。
My example here is little more than hello world, so there's very little JavaScript (green frames) to be seen. Here's a more interesting example.
DTrace
与 Java 一样,DTrace 采用不同的方法,使用"ustack helper"。见戴夫·帕切科的post,在那里他也演示火焰图。
- Other Languages
请参阅Flame Graphs Updates部分,并搜索您感兴趣的语言。
- Other Uses
火焰图可视化适用于任何堆栈跟踪和值组合,而不仅仅是堆叠具有 CPU 样本计数的跟踪,如上述值。例如,您可以跟踪设备 I/O、系统调用、CPU 外事件、特定函数调用和内存分配。对于其中任何一个,可以收集堆栈跟踪以及相关值:计数、字节或延迟。请参阅Flame Graphs页面上的其他类型的类型。
- Background & Acknowledgements
我出于必要而创建此可视化效果:我从各种不同的性能问题中提供了大量堆栈示例数据,需要快速挖掘这些数据。我首先尝试创建一些基于文本的工具来汇总数据,但收效甚微。然后,我想起了Neelakanth Nadgir(另一个Roch Bourbonnais创建了并给我看)创建的定时可视化效果,并认为堆栈示例可以以类似的方式呈现。Neel 的可视化效果看起来很棒,但跟踪每个函数条目和返回我的工作负载的过程对性能的影响太大。在我的情况下,更重要的是要有准确的百分比来量化代码路径,而不是时间排序。这意味着我可以对堆栈(低开销)进行采样,而不是跟踪函数(高开销)。
第一个可视化工作,并立即确定了 KVM 代码的性能改进(一些添加的功能比预期的成本更高)。从那以后,我多次使用它进行内核和应用程序分析,其他人也一直在广泛的目标上使用它,包括节点.js分析。狩猎快乐!
- References
- The Flame Graph page, and github repo
- Linux perf_events wiki
- The Unofficial Linux Perf Events Web-Page
- The SystemTap homepage
- My Linux Performance Checklist, which includes perf_events, SystemTap and other tools
See the Flame Graph: Updates section for other articles, examples, and instructions for using flame graphs on many other targets, including Ruby, OS X, Lua, Erlang, node.js, and Oracle.