ORM查询语言(OQL)简介--概念篇
相关文章内容索引:
一、SQL与ORM
关系数据库(RDBMS)的查询有SQL(Structured Query Language)结构化查询语言,相比高级程序语言(命令式语言)而言,SQL主要描述想要做什么,而不是命令式语言的具体如何做,因此,SQL也被称为第四代语言(4GL),它为现代大多数的关系数据库系统所支持。SQL的核心是对“关系”的操作,数据库理论研究证明,SQL是关系上完备的,但是当代大多数高级语言都是面向对象的,高级语言程序要跟关系数据库进行交互,SQL就成了必须的桥梁,由于SQL基于的“关系”和程序语言的“对象”是不同的体系,它们之间要完成很好的交互,就得有一个“映射”过程,实现这个过程的程序,就是ORM(Object/Relation Mapping)。
应用程序调用ORM的方法,ORM自动生成相应的SQL语句到数据库进行查询,然后ORM将接收到的关系数据映射成实体对象。如果没有使用ORM,那么通常应用程序会拆分出一个数据访问层(DAL)来生成SQL语句并执行相应的查询。所以,ORM出现后,在一定程度上,它可以取代DAL,这使得你少了一个层的工作量,对于提高工作效率是很重要的。
下图是应用程序使用ORM和使用传统的DAL的一个示意图。
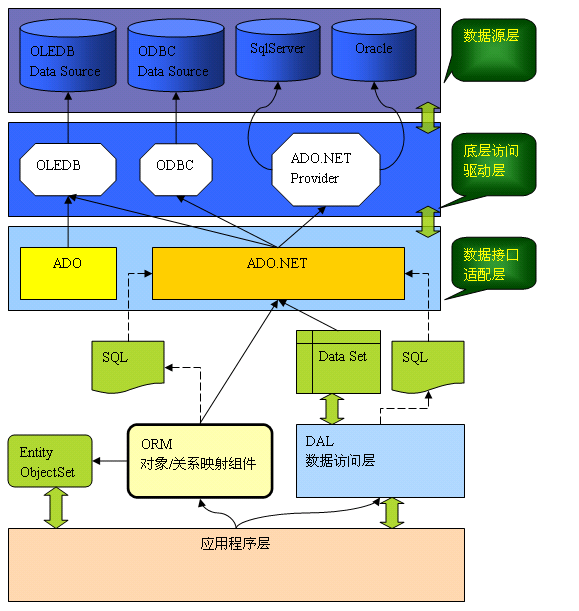
(图1:两种数据访问架构)
二、ORM带来的问题
使用ORM后,再也不用去写那些枯燥的DAL代码了,不用拼接那些可能存在安全问题或者敲错字段名的SQL语句,但是我们发现,仅仅使用ORM它反而丧失了SQL的灵活性,这也是不少人拒绝使用ORM的理由。我们看看很多人的ORM是怎么定义数据操作接口的,他们常常把这些接口方法由实体类去实现,从而制造一个个充血的实体类:
{
void Add();
void Update();
void Delete();
List<T> GetAll();
T GetOne( int id);
}
使用充血实体类,在使用上还是比较方便的,但是Insert \Update\Delete 都只能操作一条数据,GetAll 方法不仅仅把全部数据拿出来了,而且还可能把不需要的字段值也拿了出来,那个GetOne方法,也许实际上表的主键并不是int 类型的,那么这些定义就会有问题。。。
所以,我们见到很多使用了ORM的项目,不管数据是否全部需要,先拿出来再说,不管主键是不是int 类型,先定一个方法在那里,大不了是个空方法,不管当前实体是否需要Delete功能(比如某些系统用户数据是不能删除的),都基类给直接实现了。。。。。。
三、ORM查询语言
1,分离关注点
那么,这些问题ORM能够解决吗?ORM本来是完成“对象-关系映射”的,但这里大多数的ORM都包含了“生成SQL”的功能,而要实现SQL那样的灵活性,那么我们必须分离出ORM这个关注点,将“生成SQL”的功能从ORM中抽取出来,这样我们就能够有更多的精力致力于发明一个面向对象的,用于ORM查询的语言,这就是OQL。
ORM查询语言,其实早就有了,从早期的Hibernate的HQL,到MS的Linq(Linq2SQL,EF其实内部都是使用Linq生成的SQL),它们都可以生成复杂的SQL语句,它们都是直接作用于ORM框架的。几乎在与Linq同一时期,PDF.NET也发明了自己的ORM查询语言,称为OQL。下面提到的OQL,都是指的PDF的OQL。
2,PDF.NET的ORM框架
PDF.NET的ORM框架包括4个部分:
- EntityObject :PDF.NET实体类;
- OQL:ORM查询语言,以实体类对象为操作对象,生成查询表达式,供实体查询对象使用。
- AdoHelper:数据访问提供程序抽象类,封装了对ADO.NET的各种访问,包括事物操作;框架默认提供了OledbProvider、OdbcProvider、AccessProvider、SqlServerProvider、OracleProvider等,要支持更多的数据库,只需要继承AdoHelper即可。
- EntityQuery<T> :实体查询对象,它是一个O/R Mapping对象,它操作涉及的对象类型是一个实体类;在对象内部,它会把OQL转换成SQL,然后调用AdoHelper完成查询。
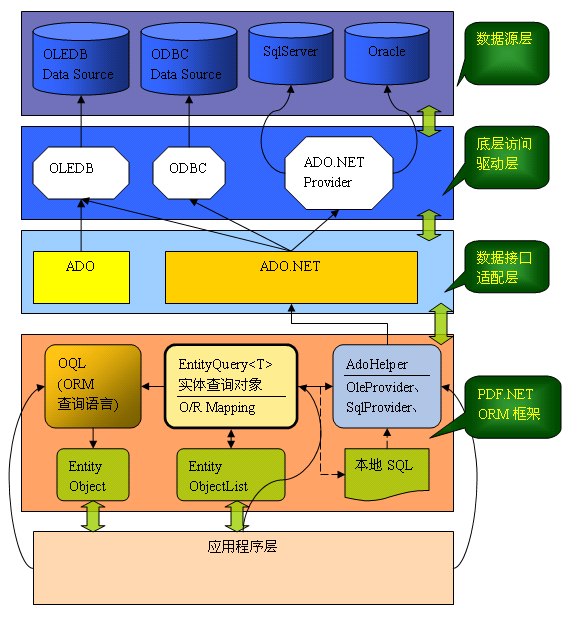
(图2:PDF.NET OQL 架构)
如果仅从查询调用端来观察,我们发现OQL,跟SQL逻辑上是等价的,一个是“对象化”的查询,一个是“结构化”的查询:
对象化查询:OQL->ORM-> Objects
等于
结构化查询:SQL ->DB-> DataSet
如果最终效果Object==DataSet,那么OQL==SQL。
所以,OQL的设计目标,就是要它生成的SQL语句效果基本达到手写的SQL语句一样。由于SQL的具体实现又有很多不同的版本,所以很多时候SqlServer用的SQL语句在Oracle 上不一定能够使用,只有那些完全标准的SQL语句才是通用的,因此,OQL的设计,也必须是这样标准的SQL规范,目前,实现的是SQL92标准规范。
3,OQL查询范式
下面是OQL支持的查询范式举例,注意下面的定义里面使用了“BNF”范式,为了避免大家误会,这里补充下BFN的内容,详细内容请参考这个链接:http://baike.baidu.com/view/1137652.htm
巴科斯范式的内容
在双引号中的字("word")代表着这些字符本身。而double_quote用来代表双引号。
在双引号外的字(有可能有下划线)代表着语法部分。
尖括号( < > )内包含的为必选项。
方括号( [ ] )内包含的为可选项。
大括号( { } )内包含的为可重复0至无数次的项。
竖线( | )表示在其左右两边任选一项,相当于"OR"的意思。
::= 是“被定义为”的意思。
1,数据查询:
[.[InnerJoin | LeftJoin|RightJoin ](entityObject2). On(entityObject.PK,entityObject2.FK)]
[.[InnerJoin| LeftJoin|RightJoin ](entityObject3). On(entityObject.PK,entityObject3.FK)]
. Select( [ entityObjectX.Property1 ][, entityObjectX.Property2][{,…} ])
. Where( [< entityObject.Property1>[, entityObject.Property2][,…]] | [ OQL2 ]| [ OQLCompare ])
.GroupBy(entityObjectX.PropertyN,”< asc>|< desc>”)
.HavingBy(entityObjectX.PropertyM)
. End;
如果需要分页,仅需要这样操作:
执行该方法,会生成特定数据库平台的分页SQL语句。
2,数据统计:
. Select(). Count(entityObject.PropertyX,<””>|<"CountAsName">)
. Where( [< entityObject.Property1>[, entityObject.Property2][,…]] | [ OQL2 ]| [ OQLCompare ])
. End;
3,数据更新:
. Update( [ entityObject.Property1 ][, entityObject.Property2][{,…} ])
. Where( [< entityObject.Property1>[, entityObject.Property2][,…]] | [ OQL2 ]| [ OQLCompare ])
. End;
4,数据删除:
. Delete()
.Where( [< entityObject.Property1>[, entityObject.Property2][,…]] | [ OQL2 ]| [ OQLCompare ])
. End;
下篇我们将使用实例来讲解OQL的具体使用,敬请期待。
注:PDF.NET现在已经开源,有关框架的详细信息,请看官网介绍: http://www.pwmis.com/sqlmap
开源信息介绍:
shawn(630235793) 1:10:46
大体浏览了一下,感觉还不错
shawn(630235793) 1:14:32
只是博文过于技术细节化而缺少了框架解决的具体问题域、面向的使用者类型,以及整体架构思想与基于关系数据访问框架的差异性描述,让读者一上来很难理解ORM框架的意图。
回复:
这些问题的确没有表述清楚,也是因为我的撰文水平有限,没有想到这些问题,也不知道该怎样来表述。
PDF.NET的OQL要解决的主要问题就是让ORM操作能够有SQL那样的灵活性,现有大多数ORM框架都是基于CRUD方法级别的操作,还没有像SQL那样具有语言级别的操作,要不然它怎么会被称为4GL呢?现在,我觉得LINQ也具有了这样的能力,而我框架中的OQL,也有这样的能力,所以我大胆的称呼它是一个“ORM Query Laguage”,就像SQL是提供给RDBMS的查询引擎使用一样,OQL是提供给ORM使用的。
所以,OQL面向的使用者是那些喜欢ORM方式来访问数据库,又喜欢SQL的灵活性的技术人员,或者是提供给喜欢其中一种(ORM或者SQL)而不太喜欢另外一种方式的人,让他们有机会体会到另一种方式的优势。
整体思想就是,用面向对象的方式来操作数据库,用OO的方式来写SQL!
PS:OQL与LINQ相比,它更接近于SQL风格,用惯了SQL的人,第一次接触LINQ是很不习惯的,至少我是如此。
shawn(630235793) 2012-10-6 1:39:15
数据访问框架设计的初始设想,首先应该是满足调用层的使用要求,换句话说请求是事务性的,还是非事务性的。如果用户的请求是事务性的,在访问层应该提供事务性的处理机制。而不是应用层自己来对是否事务性进行处理。这些应该放在访问层的对外交互接口处提供给用户来选择比较合理。
所以,框架内部的分层,我感觉还应该再多考虑一下比较好。
回复:
实体层的接口是有的,只是这个图里面不好放置而且不是重点,省略了。
是否使用事物,是放在访问层的对外交互接口处提供给用户来选择的。
毕竟数据访问框架对于用户来讲就应该屏蔽所有数据库之间操作的差异性,所有与数据库相关的一切操作都封装于内部。对于用户来讲这些都是完全不必去考虑的,只需要提出具体请求是什么就可以了。对于如何解读用户请求、如何根据用户选择的具体数据库,而将请求翻译成底层数据库操作指令等等,这些都是访问层内部机制完成的。
回复:
正如你所说,框架正是这样去做的,OQL屏蔽了SQL不同数据库之间的差异,它会根据具体使用的数据库,去生成本地化的SQL。
跟 linq 有什么相似/区别?
广州-海華²º¹²<[email protected]> 17:05:45
这篇博文里主推的理念,让人想到 linq。
pdf.net 主推的应该是:linq 般好用,但是性能卓越
回复:
LINQ是.NET独有的特性,“语言集成查询”,它是集成在.NET语言中的,这是它的先天优势。LINQ基于表达式树,所以它要求必须是.NET平台而且框架版本要求在.NET3.5及以上。
PDF.NET的OQL跟LINQ一样都是ORM框架使用的语言,但是OQL语法更接近于SQL,很容易上手,而且,OQL没有使用.NET的高级特性,这使得它只要是面向对象的语言而且支持泛型即可实现,因此将它移植到C++、Java是完全可能的,而且在.NET平台上,它也仅需.NET2.0版本的支持。