python爬虫爬取图片
以天堂图片网为例。
1.分析网站
进入网站后的页面如下:
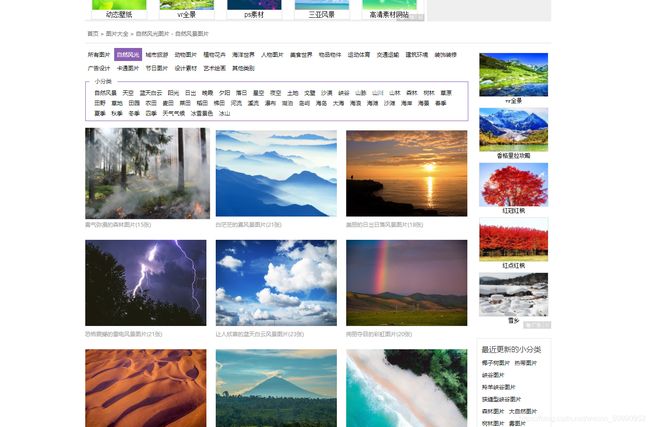
可以看到,我们想爬取的图片明显不在这个界面,那我们顺便点进去一个:
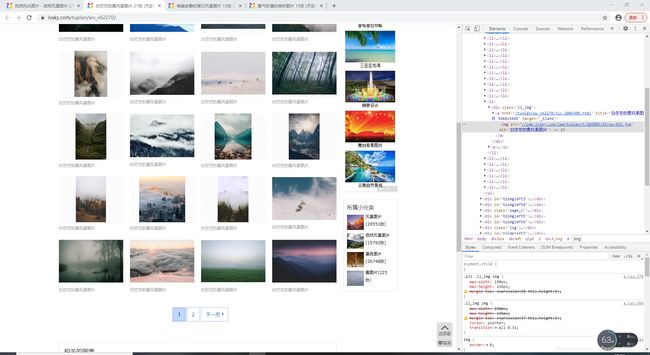
进去后是这样的,右键检查图片也可以发现我们需要的图片链接都是在这个界面的,那么到这里基本上就分析完成了,可以进行下一步了。
2.敲代码
养成好习惯,先把网站的headers获取一下(有些网站的访问并不需要headers):
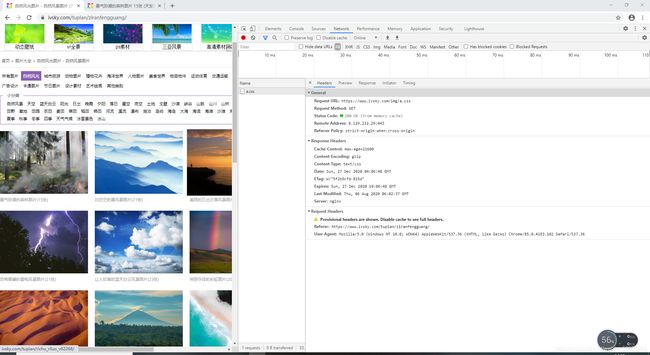
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'}
通过以上分析,也就是说我们要先访问初始网页,然后在初始界面里定位到目标网页的url,然后访问目标网页,并在目标网页里定位到具体的图片链接,然后将图片下载下来久好了。
接下来,是具体代码实现:
1.访问初始网页:
url_base='https://www.ivsky.com/tupian/ziranfengguang/'
response=requests.get(url,headers=headers)#访问网页
html=response.text
2.定位目标网页(这里我主要用的方法是正则表达式,当然也有很多其他的方法,看个人):
urls=re.findall('',html)#获取链接
for url in urls:#遍历链接
print(url)
3.访问目标网页
注意:以上步骤获得的url输出后是这样的
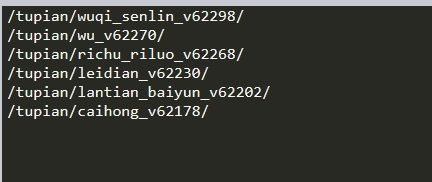
这样的url是不能直接用requests.get方法去访问的,也就是说,需要我们进行一些加工(可以直接手动点进去看一下网页的具体url):
url="https://www.ivsky.com/"+url#规范格式
response=requests.get(url,headers=headers)
html1=response.text
4.定位图片链接,并下载保存
我想将一个网页下的图片保存到一个文件夹,所有先创建一个文件夹,直接用它网页的标题做文件名(因为我个人比较懒,不想自己想名字):
dir_name=re.findall('(.*?)
',html1)#以标题为文件夹名
if not os.path.exists(str(dir_name)):#判断文件夹有无,没有则生成
os.mkdir(str(dir_name))
然后定位图片,下载:
注意:这里的图片链接有跟上面一样的问题
pics=re.findall(') ',html1)#获取图片
for pic in pics:#遍历图片
file_name=pic.split('/')[-1]#以/为分隔符,取最后一段作为文件名
pic="http:"+pic#规范格式
response=requests.get(pic,headers=headers)
with open(str(dir_name) + '/' + file_name,'wb') as f:#/为分级 wb代表二进制模式文件,允许写入文件,
f.write(response.content)
',html1)#获取图片
for pic in pics:#遍历图片
file_name=pic.split('/')[-1]#以/为分隔符,取最后一段作为文件名
pic="http:"+pic#规范格式
response=requests.get(pic,headers=headers)
with open(str(dir_name) + '/' + file_name,'wb') as f:#/为分级 wb代表二进制模式文件,允许写入文件,
f.write(response.content)
完整代码:
url_base='https://www.ivsky.com/tupian/ziranfengguang/'
response=requests.get(url,headers=headers)#访问网页
html=response.text
urls=re.findall('',html)#获取链接
for url in urls:#遍历链接
url="https://www.ivsky.com/"+url#规范格式
response=requests.get(url,headers=headers)
html1=response.text
dir_name=re.findall('(.*?)
',html1)#以标题为文件夹名
if not os.path.exists(str(dir_name)):#判断文件夹有无,没有则生成
os.mkdir(str(dir_name))
pics=re.findall('',html1)#获取图片
for pic in pics:#遍历图片
file_name=pic.split('/')[-1]#以/为分隔符,取最后一段作为文件名
pic="http:"+pic#规范格式
response=requests.get(pic,headers=headers)
with open(str(dir_name) + '/' + file_name,'wb') as f:#/为分级 wb代表二进制模式文件,允许写入文件,
f.write(response.content)
到这里,爬取图片的功能已经基本实现,但是(画重点了嗷!!!)
3.代码完善和纠错
很明显的啦!每个图片网站的图片怎么可能只有一页
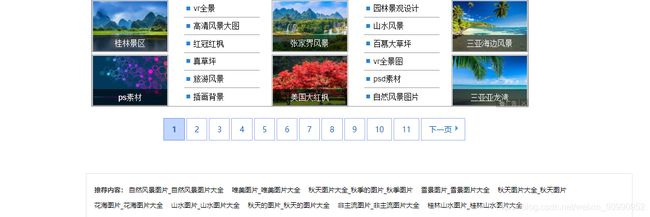
也就是说我们还需要加一个翻页的操作,因为天堂图片网是个静态网页,通过观察他的不同页的网址变化,其实不难找出规律:
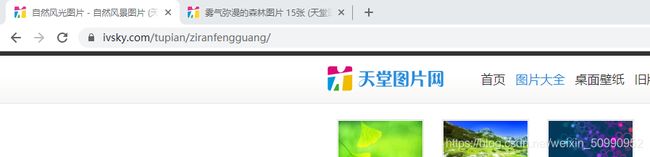
这是第一页
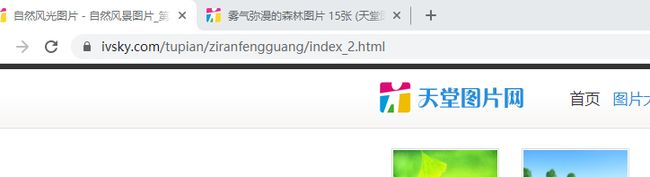
这是第二页,一目了然嘛。
那具体代码实现:
url_base='https://www.ivsky.com/tupian/ziranfengguang/'
for x in range(1):#定义爬取到的图片页
if x==1:
pass
else:
url=url_base+"index_"+str(x)+".html"
到这里,相信已经有细心的小伙伴发现了,那如果图片页里面也有好几页该这么办呢,不可能也像上面的一样,搞格式匹配吧,毕竟不是每个图片页都有好几页的。
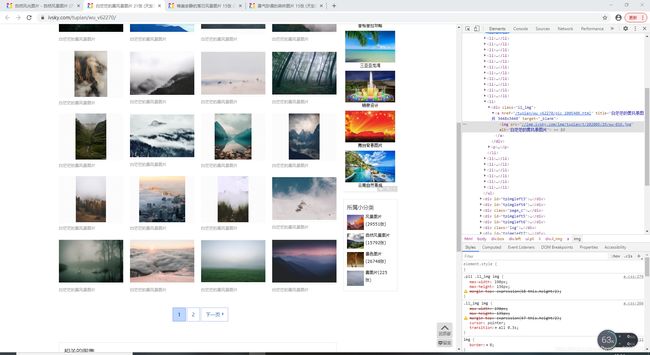
也就是说,我们在访问每一个图片页后,需先对是否有下一页进行一个判断,然后来决定接下来的执行过程,这里就又要用到正则表达式定位了。
具体代码实现:
next_page=re.findall("下一页",html1)
if next_page:#如果有下一页
for url in next_page:#因为直接得到的next_page是list型的,通过这个方式转换为str型
url="https://www.ivsky.com/"+url
response=requests.get(url,headers=headers)
html=response.text
``````
那么到这里,我们对天堂图片网的图片的爬虫才真正的已经基本上完成了,下面附上:
真—完整代码
import requests
import re
import os
import time
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'}
def get_pics(url):#获取图片函数
response=requests.get(url,headers=headers)#访问网页
html=response.text
urls=re.findall('',html)#获取链接
for url in urls:#遍历链接
time.sleep(1)
url="https://www.ivsky.com/"+url#规范格式
response=requests.get(url,headers=headers)
html1=response.text
dir_name=re.findall('(.*?)
',html1)#以标题为文件夹名
if not os.path.exists(str(dir_name)):#判断文件夹有无,没有则生成
os.mkdir(str(dir_name))
down_pics(html1,dir_name)
def down_pics(html1,dir_name):
pics=re.findall('',html1)#获取图片
for pic in pics:#遍历图片
file_name=pic.split('/')[-1]#以/为分隔符,取最后一段作为文件名
pic="http:"+pic#规范格式
response=requests.get(pic,headers=headers)
with open(str(dir_name) + '/' + file_name,'wb') as f:#/为分级 wb代表二进制模式文件,允许写入文件,
f.write(response.content)
next_page=re.findall("下一页",html1)
if next_page:#如果有下一页
for url in next_page:
url="https://www.ivsky.com/"+url
response=requests.get(url,headers=headers)
html=response.text
down_pics(html,dir_name)
if __name__ == "__main__":
url_base='https://www.ivsky.com/tupian/ziranfengguang/'
for x in range(1):#定义爬取到的图片页
if x==1:
pass
else:
url=url_base+"index_"+str(x)+".html"
get_pics(url)
以上方法应该可以用于大部分静态网页,如果你不能爬取图片,先考虑你的定位表达式有没有问题。如果是可以下载但无法打开,就要考虑你的headers是否写错,或者是网页设置了防盗链。
另外,特别提出,写正则表达式一定要根据网页源代码写,不要根据F12里面的写
写正则表达式一定要根据网页源代码写
写正则表达式一定要根据网页源代码写
写正则表达式一定要根据网页源代码写
重要的事情说三遍!!!
(如果你一定要问我为什么,可以自己去看看上面关于next_page的F12和网页源代码的区别)
写的不怎么样,大家见谅哈!!
下面应该还会写一个关于动态爬取图片的方法,大家想看的可以插个眼。