Kettle构建Hadoop ETL实践(十):并行、集群与分区
目录
一、数据分发方式与多线程
1. 数据行分发
2. 记录行合并
3. 记录行再分发
4. 数据流水线
5. 多线程的问题
6. 作业中的并行执行
二、Carte子服务器
1. 创建Carte子服务器
2. 定义子服务器
3. 远程执行
4. 监视子服务器
5. Carte安全
6. 服务
三、集群转换
1. 定义一个静态集群
2. 设计集群转换
3. 执行和监控
4. 元数据转换
5. 配置动态集群
四、数据库分区
1. 在数据库连接中使用集群
2. 创建数据库分区schemas
3. 启用数据库分区
4. 数据库分区示例
5. 集群转换中的分区
五、小结
本专题前面系列文章详细说明了使用Kettle的转换和作业,实现Hadoop上多维数据仓库的ETL过程。通常Hadoop集群存储的数据量是TB到PB,如果Kettle要处理如此多的数据,就必须考虑如何有效使用所有的计算资源,并在一定时间内获取执行结果。
作为本专题的最后一篇文章,将深入介绍Kettle转换和作业的垂直和水平扩展。垂直扩展是尽可能使用单台服务器上的多个CPU核,水平扩展是尽可能使用多台计算机,使它们并行计算。第一部分先介绍转换内部的并行机制和多种垂直扩展方法。然后说明怎样在子服务器集群环境下进行水平扩展。最后描述如何利用Kettle数据库分区进一步提高并行计算的性能。
一、数据分发方式与多线程
在“Kettle与Hadoop(一)Kettle简介”中,我们知道了转换的基本组成部分是步骤,而且各个步骤是并行执行的。现在将更深入解释Kettle的多线程能力,以及应该如何通过这种能力垂直扩展一个转换。
默认情况下,转换中的每个步骤都在一个隔离的线程里并行执行。但可以为任何步骤增加线程数,我们也称之为“拷贝”。这种方法能够提高那些消耗大量CPU时间的转换步骤的性能。来看一个简单的例子,如图10-1所示,“×2”的符号表示该步骤将有两份拷贝同时运行。右键单击步骤,选择菜单中的“改变开始复制的数量”,在弹出的对话框设置步骤线程数。
 图10-1 在多个拷贝下运行一个步骤
图10-1 在多个拷贝下运行一个步骤
注意所有步骤拷贝只维护一份步骤的描述。也就是说,一个步骤仅是一个任务的定义,而一个步骤拷贝则表示一个实际执行任务的线程。
1. 数据行分发
Kettle转换中,各步骤之间行集(row set)的发送有分发和复制两种方式,我们用一个简单的例子辅助说明。定义一个转换,以t1表作为输入,输出到表t2和t3。t1表中有1-10十个整数。当创建第二个跳(hop)时,会弹出一个警告窗口,如图10-2所示。
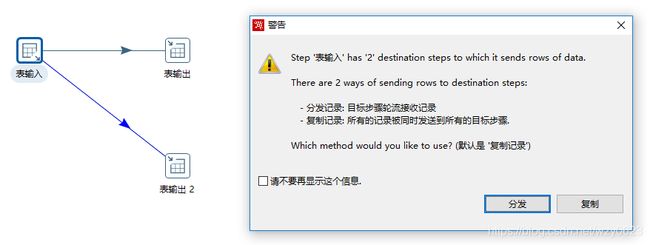 图10-2 一个警告对话框
图10-2 一个警告对话框
表输入步骤将向两个表输出步骤发送数据行,此时可以选择采用分发或复制两种方式之一,缺省为分发方式。分发方式执行后,t2、t3表的数据如下。
mysql> select * from t2; mysql> select * from t3;
+------+ +------+
| a | | a |
+------+ +------+
| 1 | | 2 |
| 3 | | 4 |
| 5 | | 6 |
| 7 | | 8 |
| 9 | | 10 |
+------+ +------+
5 rows in set (0.00 sec) 5 rows in set (0.00 sec)本例中,“表输入”步骤里的记录发送给两个“表输出”步骤。默认情况下,分发工作使用轮询方式进行。也就是第一表输出步骤获取第一条记录,第一表输出步骤获取第二条记录,如此循环,直到没有记录分发为止。
复制方式是将全部数据行发送给所有输出跳,例如同时往数据库表和文件里写入数据。本例以复制方式执行后,t2、t3表都将具有t1表的全部10行数据。通常情况下每一条记录仅仅处理一次,所以复制的情况用的比较少。下面看一下多线程分发的情况。图10-3所示的转换中,输入单线程,两个输出,一个单线程、另一个两线程。
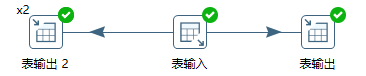 图10-3 两个表输出步骤一个单线程、另一个两线程
图10-3 两个表输出步骤一个单线程、另一个两线程
转换执行后,t2、t3表的数据如下。输入线程轮询分发,单线程输出每次写一行,两线程输出每次写两行。
mysql> select * from t2; mysql> select * from t3;
+------+ +------+
| a | | a |
+------+ +------+
| 1 | | 3 |
| 4 | | 6 |
| 7 | | 2 |
| 10 | | 9 |
+------+ | 5 |
4 rows in set (0.00 sec) | 8 |
+------+
6 rows in set (0.00 sec)图10-4所示的转换中,输入单线程、两个输出均为两线程。
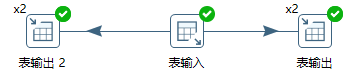 图10-4 两个表输出步骤均为两线程
图10-4 两个表输出步骤均为两线程
转换执行后,t2、t3表的数据如下。输入线程向两个输出步骤轮询分发数据行,两个输出步骤每次写两行。
mysql> select * from t2; mysql> select * from t3;
+------+ +------+
| a | | a |
+------+ +------+
| 2 | | 4 |
| 6 | | 3 |
| 1 | | 8 |
| 10 | | 7 |
| 5 | +------+
| 9 | 4 rows in set (0.00 sec)
+------+
6 rows in set (0.00 sec)2. 记录行合并
前面例子都是表输入步骤为单线程的情况。当有几个步骤或者一个步骤的多份拷贝同时发送给单个步骤拷贝时,会发生记录行合并,如图10-5所示。
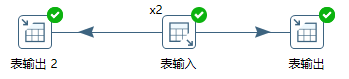 图10-5 合并记录行
图10-5 合并记录行
转换执行后,t2、t3表的数据如下。可以看到,每个输入线程都以分发方式并行将数据行依次发给每个输出跳,结果t2表数据为两倍的单数、而t3表数据为两倍的双数。
mysql> select * from t2; mysql> select * from t3;
+------+ +------+
| a | | a |
+------+ +------+
| 1 | | 2 |
| 3 | | 4 |
| 5 | | 6 |
| 7 | | 8 |
| 9 | | 10 |
| 1 | | 2 |
| 3 | | 4 |
| 5 | | 6 |
| 7 | | 8 |
| 9 | | 10 |
+------+ +------+
10 rows in set (0.00 sec) 10 rows in set (0.00 sec)从“表输出”步骤来看,并不是依次从每个数据源逐条读取数据行。如果这样做会导致比较严重的性能问题,例如一个步骤输送数据很慢,而另一个步骤输送数据很快。实际上数据行都是从前面步骤批量读取的,因此也不能保证从前面步骤的多个拷贝中读取记录的顺序!
3. 记录行再分发
记录行再分发是指,X个步骤拷贝把记录行发送给Y个步骤拷贝,如图10-6所示。
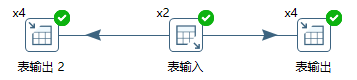 图10-6 记录行再分发
图10-6 记录行再分发
在本例中,两个表输入步骤拷贝都把记录行分发给四个目标表输出步骤拷贝。这个结果等同于图10-7的转换。
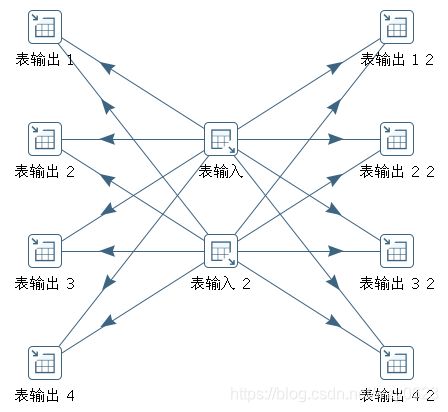 图10-7 记录行再分发展开
图10-7 记录行再分发展开
从图10-7可以看出,在表输入和表输出步骤之间有X*Y个行缓冲区。本例中两个源步骤和八个目标步骤之间有16个缓冲区(箭头)。在设计转换的时候要记住这一点,如果在转换末端有很慢的步骤,这些缓存都可能被填满,这样会增加内存消耗。默认情况下最大缓冲区的记录行数是10000(可在转换属性杂项标签页中的“记录集合里的记录数”属性进行设置),所以内存中能保存的记录行总数是160000行。
转换执行后,t2、t3表的数据如下。输出为四线程,因此输入的第一个线程将前四行发送到输出1,然后将接着的四行发送到输出2,然后再将接着的四行(此时只剩两行)发送到输出1。输入的第二个线程也同样执行这样的过程。最终t2表两个1、2、3、4、9、10,t3表有两个5、6、7、8。
mysql> select * from t2; mysql> select * from t3;
+------+ +------+
| a | | a |
+------+ +------+
| 2 | | 8 |
| 3 | | 7 |
| 4 | | 6 |
| 10 | | 7 |
| 3 | | 8 |
| 4 | | 5 |
| 1 | | 6 |
| 2 | | 5 |
| 9 | +------+
| 1 | 8 rows in set (0.00 sec)
| 10 |
| 9 |
+------+
12 rows in set (0.00 sec)由前面这些例子可以总结出分发方式下执行规律:每个输入步骤线程执行相同的工作,即轮流向每个输出步骤发送数据行,每次发送的行数等于相应输出步骤的线程数。但是,当输入步骤与输出步骤的线程数相等时并不符合这个规律。不要以为这是个bug,即使它很像,却是Kettle故意为之,称为数据流水线。
4. 数据流水线
数据流水线是再分发的一种特例,在数据流水线里源步骤和目标步骤的拷贝数相等(X==Y)。此时,前面步骤拷贝的记录行不是分发到下面所有的步骤拷贝。实际上,由源步骤的拷贝产生的记录行被发送到具有相同编号的目标步骤拷贝,图10-8是这种转换的例子。
 图10-8 数据流水线
图10-8 数据流水线
在技术上,它等同于图10-9的转换。
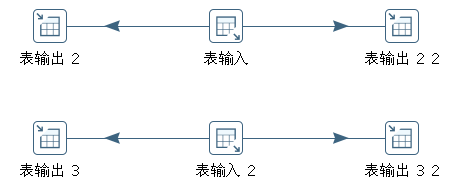 图10-9 数据流水线展开
图10-9 数据流水线展开
转换执行后,t2、t3表的数据与图10-5所示转换的执行结果相同。从现象看输入输出线程数相等时,结果如同X个独立的单线程转换。
分发和合并记录的过程会产生一点性能开销,通常情况下,最好让连续步骤的拷贝数相等,这样可以减少开销。这种减少步骤开销之间开销的过程,也可形象地比喻为将数据放进游泳池的泳道,彼此之间不受干扰。
5. 多线程的问题
通过前面的学习,我们知道了一个多线程转换中所有步骤拷贝都并行运行。接下来看这种执行模式可能产生的一些问题,以及如何解决这些问题。
(1)数据库连接
如果多线程软件处理数据库连接,推荐的方法是在转换执行的过程中为每个线程创建单一的连接,使得每个步骤拷贝都使用它们自己的事务或或者事务集,这也正式Kettle的默认配置。但有一个潜在的后果是,如果在同一转换里使用同一个数据库资源,如一个表或一个视图,很容易产生条件竞争问题。
一个常见的错误场景,就是在前面的步骤里向一个关系数据库表里写入数据,在随后的步骤里再读取这些数据。因为这两个步骤使用不同的数据库连接,而且是不同的事务,不能确保第一个步骤写入的数据,对其它正在执行读操作的步骤可见。
解决这个问题的简单方案是把这个转换分成两个不同的转换,然后将数据保存在临时表或文件中。另外一个方案是强制让所有步骤使用单一数据库连接(仅一个事务),启用转换设置对话框“杂项”标签页中的“使用唯一连接”选项即可。该选项意味着Kettle里用到的每个命名数据库都使用一个连接,直到转换执行完后才提交事务或者回滚。也就是说在执行过程中完全没有错误才提交,有任何错误就回滚。请注意,如果错误被错误处理步骤处理了,事务就不会回滚。使用这个选项的缺点是会降低转换的性能,原因之一是可能产生较大的事务,另外如果所有步骤和数据库的通信都由一个步骤的数据库连接来完成,在服务器端也只有一个服务器进程来处理请求。
(2)执行的顺序
由于所有步骤并行执行,所以转换中的步骤没有特定的执行顺序,但是数据集成过程中仍然有些工作需要按某种顺序执行。在大多数情况下,通过创建一个作业来解决这个问题,使任务可以按特定的顺序执行。在Kettle转换中,也有些步骤强制按某种顺序执行,下面有几个技巧。
- “执行SQL脚本”步骤
如果想在转换中的其它步骤开始前,先执行一段SQL脚本,可以使用“执行SQL脚本”步骤。正常模式下,这个步骤将在转换的初始化阶段执行SQL,就是说它优先于其它步骤执行。但是如果选中了这个步骤里的“执行每一行”选项,那么该步骤不会提前执行,而是按照在转换中的顺序执行。
- “Blocking step”步骤
如果希望所有的数据行都达到某个步骤后,才开始执行一个操作,可以使用“Blocking step”步骤。该步骤的默认配置是丢弃最后一行以外的所有数据,然后把最后一行数据传递给下一个步骤。这条数据将触发后面的步骤执行某个操作,这样就能确保在后面步骤处理之前,所有数据行已经在前面步骤处理完。
6. 作业中的并行执行
默认情况下,作业中的作业项按顺序执行,必须等待一个作业项执行完成后才开始执行下一个。然而,正如“https://wxy0327.blog.csdn.net/article/details/106348479#4.%20%E5%B9%B6%E8%A1%8C%E6%89%A7%E8%A1%8C”所述,在作业里也可以并行执行作业项。并行执行的情况下,一个作业项之后的多个作业项同时执行,由不同的线程启动每个并行执行的作业项。例如,希望并行更新多张维度表,可以按照图10-10的方式设计,选择Start作业项右键菜单中的“Run Next Entries in Parallel”选项即可。
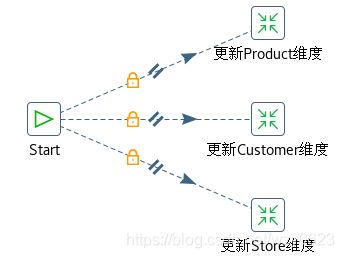 图10-10 并行更新多张维度表
图10-10 并行更新多张维度表
二、Carte子服务器
子服务器是Kettle的组成模块,用来远程执行转换和作业,物理上体现为Carte进程。Carte是一个轻量级的服务进程,可以支持远程监控,并为转换提供集群的能力,集群在下节介绍。子服务器是一个小型的HTTP服务器,也是集群的最小组成模块。用它来接收远程客户端的命令,这些命令用于作业和转换的部署、管理与监控。
正如“https://wxy0327.blog.csdn.net/article/details/107985148#%EF%BC%883%EF%BC%89Carte”所述,Carte程序用于子服务器远程执行转换和作业。启动子服务器需要指定主机名或IP地址,以及Web服务的端口号。下面在Kettle 8.3版本上,通过一个具体的例子描述子服务器的配置、创建、使用和监控,示例环境如下:
172.16.1.102:创建Carte子服务器。
172.16.1.101:创建转换,并在172.16.1.102上的子服务器上远程执行。
1. 创建Carte子服务器
在172.16.1.102上执行下面的步骤创建子服务器。
(1)创建配置文件
在Kettle的早期版本里,通过命令行指定配置选项。随着配置选项数目的增加,Kettle最近的版本使用XML格式的配置文件。例如创建如下内容的配置文件slave1.xml,描述一台子服务器的所有属性:
0
0
5
server1
172.16.1.102
8181
- max_log_lines:设置日志系统保存在内存中的最大日志行数。
- max_log_timeout_minutes:设置保存在内存中的日志行的最大存活时间(分钟)。对于运行时间很长的转换和作业,这是一个尤其重要的选项,防止子服务器内存溢出。
- object_timeout_minutes:默认情况下,在子服务器的状态报告中,可以看到所有转换和作业,这个参数可以自动地从状态报告列表中清除老的作业。
(2)启动子服务器
./carte.sh ~/kettle_hadoop/slave1.xml命令执行在控制台输出的最后信息如下,表示子服务器已经启动成功。
...
2020/12/03 09:32:32 - Carte - Installing timer to purge stale objects after 5 minutes.
2020/12/03 09:32:33 - Carte - 创建 web 服务监听器 @ 地址: 172.16.1.102:81812. 定义子服务器
在172.16.1.101上定义上步创建的子服务器。Spoon左侧的“主对象树”标签页中,右键单击“子服务器”树节点,选择“新建”。然后在弹出的新建对话框中,填入子服务器的具体属性,如图10-11所示。
 图10-11 定义子服务器
图10-11 定义子服务器
其中用户名、密码都是cluster。定义完子服务器后,可右键单击“server1”树节点,选择“Share”共享该子服务器,以便被所有转换和作业使用。
3. 远程执行
在172.16.1.101上执行下面的步骤远程执行转换。
(1)新建运行配置
在Spoon左侧的“主对象树”标签页中,右键单击“Run configurations”树节点,选择“New...”。在弹出对话框中配置运行属性,如图10-12所示。
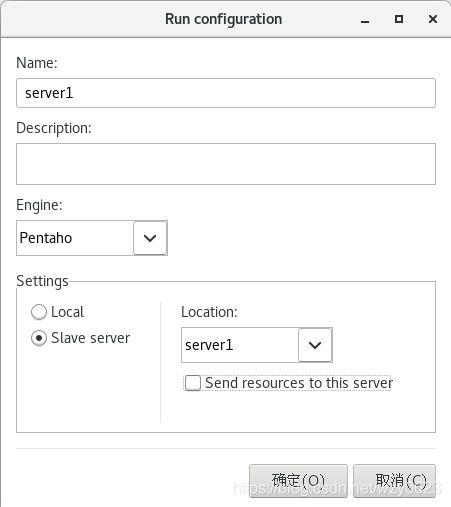 图10-12 配置运行属性
图10-12 配置运行属性
选择Pentaho作为运行转换的引擎时,运行配置对话框的设置部分包含以下选项:
- Local:选择本地Pentaho引擎运行。
- Slave server:选择此选项可将转换发送到远程服务器或Carte群集。
- Location:指定远程服务器的位置。
- Send resources to this server:远程执行前会将转换发送到子服务器。此选项是将转换的相关资源,例如引用的其它文件,也包含在发送到服务器的信息中。
(2)远程执行转换
在执行转换时弹出的“执行转换”对话框里指定要运行转换的远程子服务器,如图10-13中的server1。如果作业或转换被另一个作业调用,可以在作业或转换作业项的对话框里选择一个远程子服务器,此时作业或转换作业项即可远程执行。
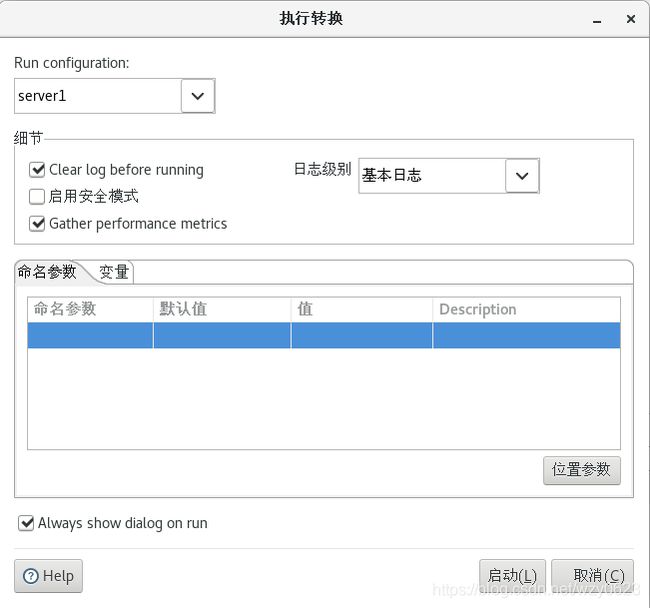 图10-13 选择远程子服务器
图10-13 选择远程子服务器
可见所谓远程执行,只是将本地定义的转换或作业的元数据及其相关资源传到远程子服务器上,然后再在子服务器上执行。转换或作业中用到的对象,如数据库连接等,必须在其运行的远程子服务器的Kettle中已经定义,否则不能正常执行。
4. 监视子服务器
有几种方法可以远程监视子服务器。
- Spoon:在Spoon树形菜单中右键单击子服务器,选择“Monitor”选项。就会在Spoon中出现一个监控界面,包含了所有运行在子服务器上的转换和作业的列表,如图10-14所示。
- Web浏览器:打开一个浏览器窗口,输入子服务器的地址,例如http://172.16.1.102:8181/,浏览器将显示一个子服务器菜单。通过这些菜单项,可以监控子服务器。
- PDI企业控制台:这是PDI企业版的一部分,企业控制台提供了监控和控制子服务器的功能。
- 自定义的应用:每个子服务器都以URL方式提供服务,返回的结果是XML格式的数据,可以通过它与子服务器通信。如果使用了Kettle的Java库,还可以利用Kettle的XML接口来解析这些XML。
 图10-14 在Spoon中监视子服务器
图10-14 在Spoon中监视子服务器
除此之外,从子服务器在控制台终端打印的日志,也可看到转换或作业的执行信息。
5. Carte安全
默认情况下Carte使用简单的HTTP认证,在文件pwd/kettle.pwd中定义了用户名和密码。Kettle默认的用户名/密码都是cluster。文件中的密码可以利用Kettle自带的Encr工具来混淆。要生成一个Carte密码文件,使用-carte选项,像这个例子:
sh encr.sh -carte Password4Carte
OBF:1ox61v8s1yf41v2p1pyr1lfe1vgt1vg11lc41pvv1v1p1yf21v9u1oyc使用文本编辑器,将返回的字符串追加到密码文件中用户名的后面:
Someuser: OBF:1ox61v8s1yf41v2p1pyr1lfe1vgt1vg11lc41pvv1v1p1yf21v9u1oycOBF:前缀告诉Carte这个字符串是被混淆的,如果不想混淆这个文件中的密码,也可以像下面这样指定明文密码:
Someuser:Password4Carte需要注意的是,密码是被混淆,而不是被加密。Kettle的encr算法仅仅是让密码更难识别,但绝不是不能识别。如果一个软件能读取这个密码,必须假设别的软件也能读取这个密码。因此应该给这个密码文件一些合适的权限。阻止他人未经授权访问kettle.pwd文件,能降低密码被破解的风险。
6. 服务
子服务器对外提供了一系列服务。表10-1列出了它定义的服务。这些服务位于Web服务的/kettle/的URI下面。在我们的例子里,就是http://172.16.1.102:8181/kettle/。所有服务都有xml=Y选项以返回XML,客户端就可以解析。表10-1还说明了服务使用的类(包org.pentaho.di.www)。
| 服务名称 |
描述 |
参数 |
Java类 |
| status |
返回所有转换和作业的状态 |
|
SlaveServerStatus |
| transStatus |
返回一个转换的状态并且列出所有步骤的状态 |
name(转换名称) from line(增量日志的开始记录行) |
SlaveServerTransStatus |
| prepareExecution |
准备转换,完成所有步骤的初始化工作 |
name(转换名称) |
WebResult |
| startExec |
执行转换 |
name(转换名称) |
WebResult |
| startTrans |
一次性初始化和执行转换。虽然方便,但是不适用在集群执行环境下,因为初始化需要在集群上同时执行 |
name(转换名称) |
WebResult |
| pauseTrans |
暂停或者恢复一个转换 |
name(转换名称) |
WebResult |
| stopTrans |
终止一个转换的执行 |
name(转换名称) |
WebResult |
| addTrans |
向子服务器中添加一个转换,客户端需要提交XML形式的转换给Carte |
|
TransConfiguration WebResult |
| allocateSocket |
在子服务器上分配一个服务器套接字。更多内容参考本篇后面的“集群转换” |
|
|
| sniffStep |
获取一个正在运行的转换中,经过某个步骤的所有数据行 |
trans(转换名称) step(步骤名称) copy(步骤的拷贝号) line(获取行数) type(输入还是输出) |
|
| startJob |
开始执行作业 |
name(作业名称) |
WebResult |
| stopJob |
终止执行作业 |
name(作业名称) |
WebResult |
| addJob |
向子服务器中添加一个作业,客户端需要提交XML形式的作业给Carte |
|
JobConfiguration WebResult |
| jobStatus |
获取单个作业的状态并列出作业下所有作业项的状态 |
name(作业名称) from(增量日志的开始记录行) |
SlaveServerJobStatus |
| registerSlave |
把一个子服务器注册到主服务器上(参考“集群转换”部分),需要客户端把子服务器的XML提交给子服务器 |
|
SlaveServerDetection WebResult(reply) |
| getSlaves |
获得主服务器下的所有子服务器的列表 |
|
节点下包含了几个SlaveServerDetection节点 |
| addExport |
把导出的.zip格式的作业或转换,传送给子服务器,文件保存为服务器的临时文件。客户端给Carte服务器提交zip文件的内容。这个方法总是返回XML |
|
WebResult里包含了临时文件的URL |
表10-1 子服务器服务
三、集群转换
集群技术可以用来水平扩展转换,使它们能以并行的方式运行在多台服务器上。转换的工作可以平均分到不同的服务器上。一个集群模式包括一个主服务器和多个子服务器,主服务器作为集群的控制器。只有在集群模式中,才有主服务器和子服务器的概念。作为控制器的Carte服务器就是主服务器,其它的Carte服务器就是子服务器。本节将介绍怎样配置和执行一个转换,让其运行在多台机器上。
集群模式也包含元数据,描述了主服务器和子服务器之间怎样通信。在Carte服务器之间通过TCP/IP套接字传递数据。之所以选择TCP/IP而不用Web Services作为数据交换的方式,是因为后者比较慢,而且会带来不必要的性能开销。
1. 定义一个静态集群
在定义一个集群模式之前,需要先定义一些子服务器。参考上一节的方法,我们已经定义了三个子服务器。其中名为master是主服务器,这是通过在子服务器对话框中勾选“是主服务器吗?”选项设置的,如图10-15所示,除此之外不需要给Carte传递任何特别的参数。图中的slave1、slave2为另外两个子服务器。
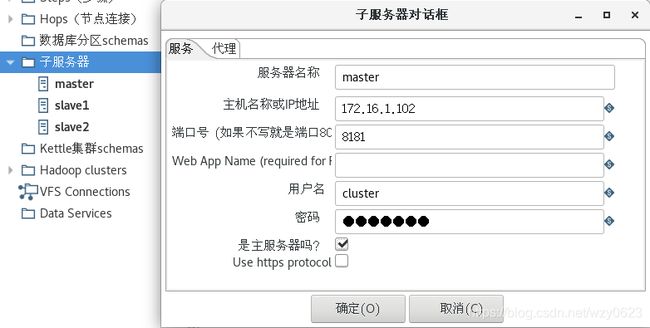 图10-15 构成Kettle集群的三个子服务器
图10-15 构成Kettle集群的三个子服务器
定义完子服务器,右键单击Spoon里的“Kettle集群schemas”节点,然后选择“新建”选项,在配置窗口里设置集群模式的所有选项。至少选择一个主服务器作为控制器并选择一个或更多子服务器,如图10-16所示。
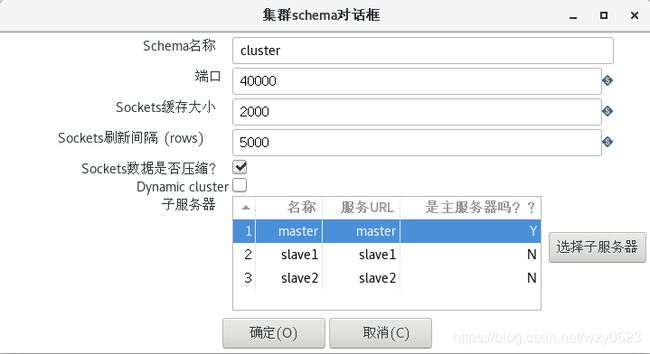 图10-16 集群schemas对话框
图10-16 集群schemas对话框
这里有几个重要的选项。
- 端口:在服务器之间传递数据的最小的TCP/IP端口号。这是一个起始端口号。如果你的集群转换需要50个端口,从初始端口号到初始端口号+50之间的所有端口都会被使用。
- Sockets缓存大小:缓存大小用来使子服务器之间通信更平滑。不要把这个值设置得太大,否则数据传输过程可能比较波动。
- Sockets刷新间隔(rows):因为进行Socket通信时,传递的数据行可能保存在Socket的缓存中。这里要设置一个刷新间隔,缓存中的数据行积累到一定数量,转换引擎就会执行flush操作,强制把数据推送给对方服务器。这个参数的大小,取决于子服务器之间的网络速度和延迟。
- Sockets数据是否压缩:设置子服务器之间传输的数据是否需要压缩。对于相对较慢的网络(如10Mbps),可以设置这个选项。设置该选项会导致集群转换变慢,因为压缩和解压数据流需要CPU时间。在网络不是瓶颈时,最好不启用这个选项。
- Dynamic cluster:如果设置了这个选项,Kettle会在主服务器上自动搜寻子服务器列表,来构建集群。
2. 设计集群转换
设计一个集群转换,需要先设计一个普通的转换。在转换里创建一个集群模式,然后选择希望通过集群方式运行的步骤。右键单击这个步骤,选择集群。选择完步骤要运行的集群模式后,转换将变成如图10-17所示的样子。
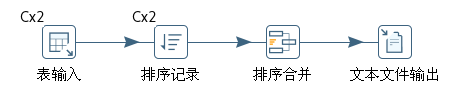 图10-17 一个集群转换
图10-17 一个集群转换
这个转换从表中读取数据,然后排序,再将数据写入一个文本文件。执行集群转换时,所有被定义成集群运行(在图10-15中有“C×2”标志)的步骤都在这个集群的子服务器上运行,而那些没有集群标识的步骤都在主服务器上运行。本例中“表输入”和“排序记录”两个步骤会在两个子服务器上并行执行,而“排序合并”和“文本文件输出”两个步骤只在主服务器上执行。
注意在图10-17中,“排序记录”步骤使用了两个不同的子服务器并行排序,所以就有两组排好序的数据行依次返回给主服务器。因为后面的步骤接收这两组数据,所以还要在后面的步骤里把这两组数据再排序,由“排序合并”步骤来完成这个工作,它从所有的输入步骤中逐行读取记录,然后进行多路合并排序。没有这个步骤,并行排序的结果是错误的。
如果转换中至少要有一个步骤被指定运行在一个集群上,这个转换才是一个集群转换。为了调试和开发,集群转换可以在Spoon的执行对话框中以非集群的方法执行。在一个转换中只能使用一个集群。
3. 执行和监控
执行下面的步骤执行集群转换。
(1)新建运行配置
在Spoon左侧的“主对象树”标签页中,右键单击“Run configurations”树节点,选择“New...”。在弹出对话框中配置运行属性,如图10-18所示。
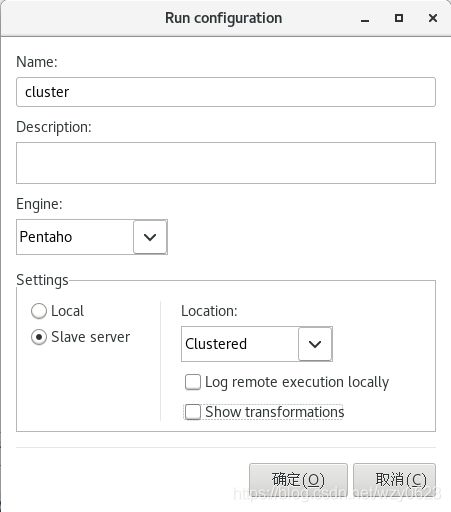 图10-18 配置集群运行属性
图10-18 配置集群运行属性
与图10-12所示的远程执行设置,这里的Location选择集群,并出现两个新选项:
- Log remote execution locally:显示来自群集节点的日志。
- Show transformations:显示集群运行时生成的转换。
(2)执行集群转换
在执行转换时弹出的“执行转换”对话框里指定要运行转换的集群运行配置,如本例中的cluster,然后启动转换。
在Spoon树形菜单中右键单击“Kettle集群schemas”下的集群名称,选择弹出菜单中的“Monitor all slave servers”,会在Spoon中出现一个所有主、子服务器的监控界面,每个服务器一个标签页,包含了所有运行在相应服务器上的转换和作业列表。本例集群中的三个服务器显示如图10-19所示。
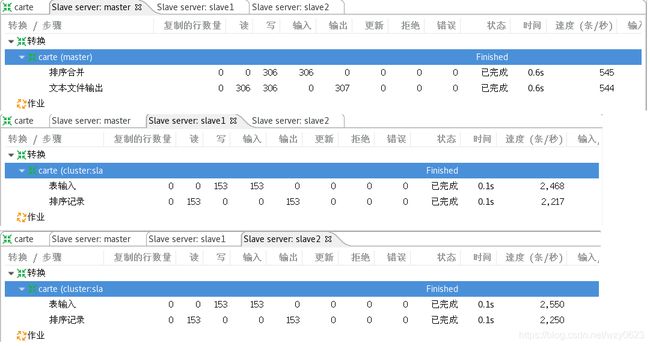 图10-19 集群服务器监控页面
图10-19 集群服务器监控页面
最后输出的文本文件在master服务器上生成。与远程执行一样,各主、子Carte服务器在控制台终端打印的日志,也可看到转换或作业的执行信息。
4. 元数据转换
主服务器和子服务器运行的并不是一样的转换。在主服务器和子服务器上运行的转换是由一个叫元数据转换(Metadata Transformations)的翻译流程产生的。在Spoon中设计的原始转换的元数据,被切分成多个转换,重新组织,再增加额外信息,然后发送给目标子服务器。
关于元数据转换,有以下三种类型的转换:
- 原始转换:用户在Spoon中设计的集群转换。
- 子服务器转换:它源自原始转换,运行在一个特定子服务器上的转换,集群里的每个子服务器都会有一个子服务器转换。
- 主服务器转换:它源自原始转换,运行在主服务器上的转换。
在图10-17这个集群例子里,生成了两个子服务器转换和一个主服务器转换。勾选集群运行配置中的“Show transformations”选项,将在集群转换运行时显示生成的转换。图10-20显示了本例的主服务器转换,图10-21显示了本例的子服务器转换。
 图10-20 主服务器转换
图10-20 主服务器转换
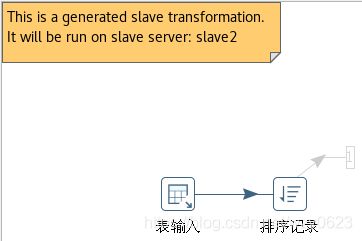 图10-21 子服务器转换
图10-21 子服务器转换
浅灰色编号的区域说明在步骤里有远程输入或输出连接,称之为远程步骤(Remote Steps)。在我们的例子里,有两个子服务器把数据从“排序记录”步骤发送到“排序合并”步骤。这意味着两个“排序记录”步骤都有一个远程输出步骤,并且“排序合并”步骤有两个远程输入步骤。如果将鼠标悬置到这个浅灰色的矩形内,将会获取更多关于该远程步骤的信息,还有分配的端口号,如图10-22所示。
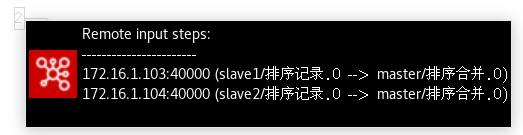 图10-22 远程步骤上的提示信息
图10-22 远程步骤上的提示信息
(1)规则
可以想象,操作这些元数据转换时,有很多可能性。以下几个通用的规则,可以确保逻辑操作正确:
- 如果一个步骤被配置成集群方式运行,它会被复制到一个子服务器转换。
- 如果一个步骤没有被配置成集群运行,它会被复制到一个主服务器转换。
- 发送数据给一个集群步骤的步骤被定义为远程输出步骤(发送数据通过TCP/IP sockets)。
- 从一个集群步骤接收数据的步骤被定义为远程输入步骤(接收数据通过TCP/IP sockets)。
下面的规则更复杂,因为它们处理集群里一些更加复杂的功能。
- 多份拷贝的步骤也可以在集群方式下运行。在这种情况下,远程输入和输出步骤将分发给不同的步骤拷贝。因为拷贝在远程机器上运行,所以太多的步骤拷贝没有意义。
- 一般情况,集群转换要尽量简单,这样更容易分析生成的转换。
- 当一个步骤要从特定的步骤里读取数据(信息步骤),在生成的转换里使用“Socket Reader”和“Socket Writer”步骤来做这个工作。
(2)数据流水线
记得在本篇前面介绍多线程与数据分发时提到数据流水线或数据的泳道:在Carte服务器之间交换的数据越多,转换就会越慢。理想情况下应该按照从头到尾并行执行的方式来组织数据。例如,处理100个XML文件会比处理一个单一的大文件更容易,因为在多份文件情况下数据能够被并行读取。
作为通用的规则,要使集群转换获取好的性能,应尽量让转换简单。在同一子服务器上,尽可能在泳道里做更多的事情,以减少服务器之间的数据传输。
5. 配置动态集群
有两种类型的Kettle集群,静态集群有一个固定的模式,它指定一个主服务器和两个或多个子服务器。而动态集群中仅需指定主服务器,子服务器则通过配置文件动态注册到主服务器。以下步骤配置并执行一个一主两从的动态集群转换。
(1)创建主服务器配置文件master.xml
0
0
5
master
172.16.1.102
8181
cluster
cluster
Y
(2)创建子服务器配置文件slave1.xml
0
0
5
master
172.16.1.102
8181
cluster
cluster
Y
Y
slave1
172.16.1.103
8181
cluster
cluster
N
masters节点定义一个或多个负载均衡Carte实例管理此子服务器。slaveserver节点包含有关此Carte子服务器实例的信息。
(3)启动主服务器
./carte.sh ~/kettle_hadoop/master.xml(4)启动子服务器
./carte.sh ~/kettle_hadoop/slave1.xml(5)按照(2)(4)步骤创建并启动第二个子服务器
(6)在Spoon新建一个动态集群,如图10-23所示
 图10-23 建立动态集群
图10-23 建立动态集群
勾选“Dynamic cluster”选项表示配置动态集群,与静态集群不同,子服务器列表中只加入了master。
(7)修改图10-17所示的转换,步骤选择动态集群,如图10-24所示
 图10-24 动态集群转换
图10-24 动态集群转换
此时会看到“表输入”和“排序记录”步骤的左上角出现“C×N”标志,说明这些步骤将在集群的所有子服务器上运行。
(8)以集群方式执行转换
四、数据库分区
分区是一个非常笼统的术语,广义地讲是将数据拆分成多个部分。在数据集成和数据库方面,分区指拆分表或数据库。表可以划分成不同的“表分区”(table partions),数据库可以划分成不同的片(shards)。
除了数据库外,也可以把文本或XML文件分区,例如按照每家商店或区域分区。由于数据集成工具需要支持各种分区技术,所以Kettle中的分区被设计成与源数据和目标数据无关。
分区是Kettle转换引擎的核心,每当一个步骤把数据行使用“分发模式”发送给多个目标步骤时,实际就是在进行分区,分发模式的分区使用“轮询”的方式。实际上这种方式并不比随机发送好多少,它也不是本节要讨论的一个分区方法。
我们讨论的Kettle分区,是指Kettle可根据一个分区规则把数据发送到某个特定步骤拷贝的能力。在Kettle里,一组给定的分区集叫做分区模式(partitioning schema),规则本身叫做分区方法(partitioning method)。分区模式要么包含一组命名分区列表,要么简单地包含几个分区。分区方法不是分区模式的一部分。
下面介绍Kettle 8.3中数据库分区的使用。
1. 在数据库连接中使用集群
在Kettle的数据库连接对话框中,可定义数据库分区,如图10-25所示。
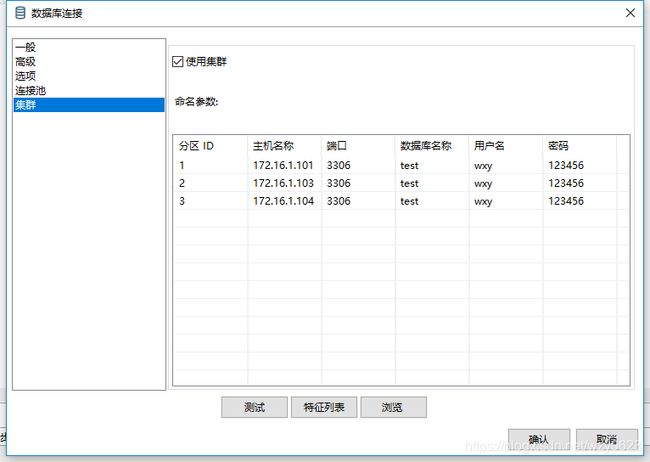 图10-25 数据库连接中配置集群
图10-25 数据库连接中配置集群
在“集群”标签,勾选“使用集群”,然后定义三个分区。这里的分区实际指的是数据库实例,需要指定自定义的分区ID,数据库实例的主机名(IP)、端口、数据库名、用户名和密码。定义分区的目的是为了从某一个分区甚至某一个物理数据库读取和写入数据。一旦在数据库连接里面定义了数据库分区,就可以基于这个信息创建了一个分区schema。
在“一般”标签,只要指定连接名称、连接类型和连接方式,在“设置”中都可以为空,如图10-26所示。Kettle假定所有的分区都是同一数据库类型和连接类型。
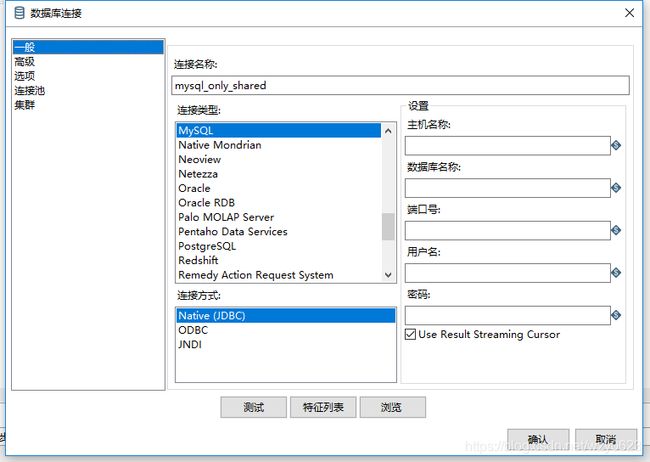 图10-26 使用集群的数据库连接
图10-26 使用集群的数据库连接
定义好分区后点击“测试”,结果如图10-27所示。
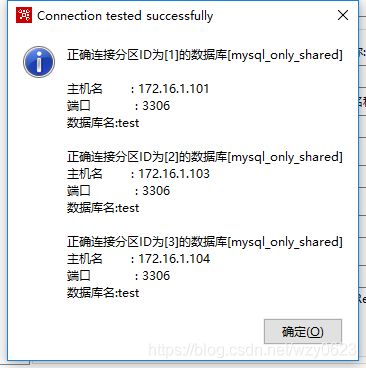 图10-27 测试数据库集群连接
图10-27 测试数据库集群连接
2. 创建数据库分区schemas
在“主对象树”的“数据库分区schemas”上点右键“新建”,在弹出窗口中输入“分区schema名称”,然后点击“导入分区”按钮,如图10-28所示。
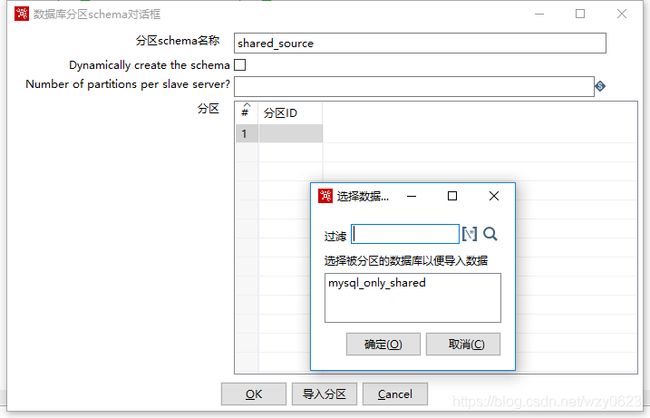 图10-28 配置数据库分区schemas
图10-28 配置数据库分区schemas
选择上一步定义的数据库连接mysql_only_shared,点“确定”按钮后,如图10-29所示。
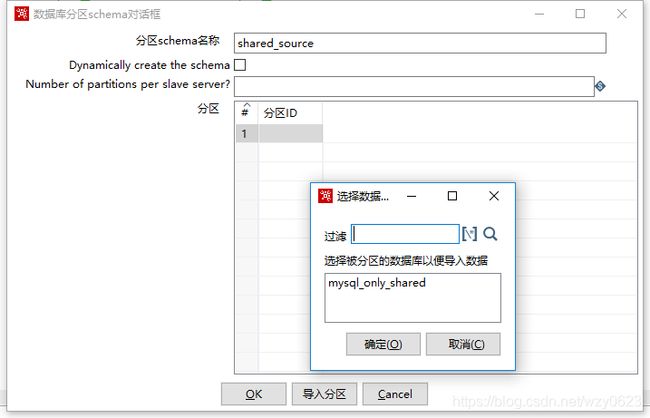 图10-29 导入数据库分区
图10-29 导入数据库分区
此时已经导入了上一步定义的三个数据库分区。点击“OK”保存。这样就定义了一个名为shared_source的数据库分区schema。再用同样的方法定义一个名为shared_target的数据库分区schema,所含分区也从mysql_only_shared导入。
至此,我们已经定义了一个包含三个分区的数据库连接,并将分区信息导入到两个数据库分区schema,如图10-30所示。
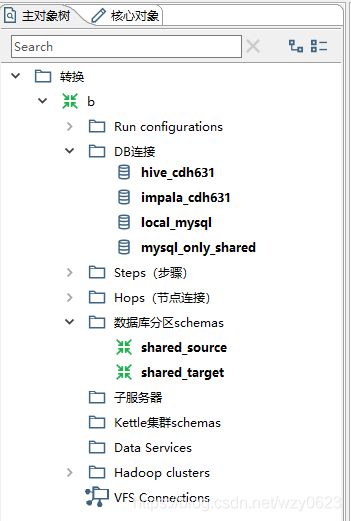 图10-30 两个数据库分区模式
图10-30 两个数据库分区模式
现在可以在任何步骤里面应用这两个数据库分区schema(就是说使用这个分区的数据库连接)。Kettle将为每个数据库分区产生一个步骤复制,并且它将连接物理数据库。
3. 启用数据库分区
点击步骤右键,选择“分区...”菜单项。此时会弹出一个对话框,选择使用哪个分区方法,如图10-31所示。
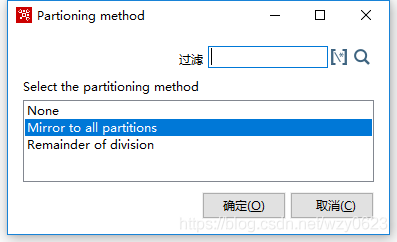 图10-31 选择分区方法
图10-31 选择分区方法
分区方法可以是下面的一种:
- None:不使用分区,标准的“Distribute rows”(轮询)或“Copy rows”(复制)规则被应用。
- Mirror to all partitions:使用已定义的数据库分区schema中的所有分区。
- Remainder of division:Kettle标准的分区方法。通过分区编号除以分区数目,产生的余数被用来决定记录行将发往哪个分区。例如在一个记录行里,如果有 “73” 标识的用户身份,而且有3个分区定义,这样这个记录行属于分区1,编号30属于分区0,编号14属于分区2。需要指定基于分区的字段。
选择“Mirror to all partitions”,在弹出窗口中选择已定义的分区schema,如图10-32所示。
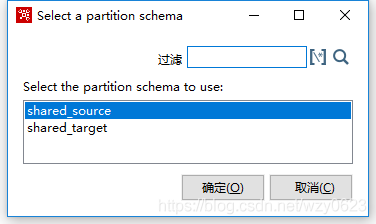 图10-32 选择分区模式
图10-32 选择分区模式
经此一番设置后,该步骤就将以分区方式执行,如图10-33所示。
 图10-33 使用数据库分区的表输入步骤
图10-33 使用数据库分区的表输入步骤
4. 数据库分区示例
(1)将三个mysql实例的数据导入到另一个mysql实例
转换如图10-34所示。
 图10-34 表输入使用分区
图10-34 表输入使用分区
“表输入”步骤连接的是mysql_only_shared。因为是按分区方式执行,实际读取的是三个分区的数据。表输出使用的是一个标准的单实例数据库连接。该转换执行的逻辑为:
db1.t1 + db2.t1 + db3.t1 -> db4.t4转换执行的结果是将三个mysql实例的数据导入到另一个mysql实例。如果将表输入步骤连接到一个标准的单实例数据库,虽然数据库连接本身没有使用集群,但依然会为每个分区复制一份步骤,其结果等同于3线程的复制分发。
(2)将一个mysql实例的数据分发到三个mysql实例
转换如图10-35所示。
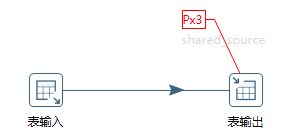 图10-35 表输出使用分区
图10-35 表输出使用分区
表输出步骤连接的是mysql_only_shared。因为是按分区方式执行,会向三个分区中的表输出数据。该转换执行的逻辑为:
db4.t4 -> db1.t2
db4.t4 -> db2.t2
db4.t4 -> db3.t2(3)将三个mysql实例的数据导入到另三个mysql实例
转换如图10-36所示。
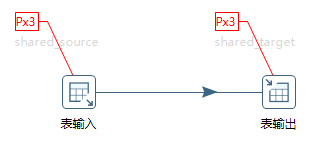 图10-36 输入输出使用不同分区
图10-36 输入输出使用不同分区
输入步骤使用的是shared_source分区schema,而输出步骤使用的是shared_target分区schema。该转换执行的逻辑为:
db1.t1 + db2.t1 + db3.t1 -> db4.t2
db1.t1 + db2.t1 + db3.t1 -> db5.t2
db1.t1 + db2.t1 + db3.t1 -> db6.t2(4)将三个mysql实例的数据导入相同实例的不同表中
转换还是如图10-36所示,与前一个例子只有一点区别:输入步骤与输出步骤使用的是同一个分区schema(shared_source)。该转换执行的逻辑为:
db1.t1 -> db1.t2
db2.t1 -> db2.t2
db3.t1 -> db3.t2在数据库连接中定义分区时需要注意一点,分区ID应该唯一,如果多个分区ID相同,则所有具有相同ID的分区都会连接到第一个具有该ID的分区。例如,我们把mysql_only_shared的分区定义改为如图10-37所示。
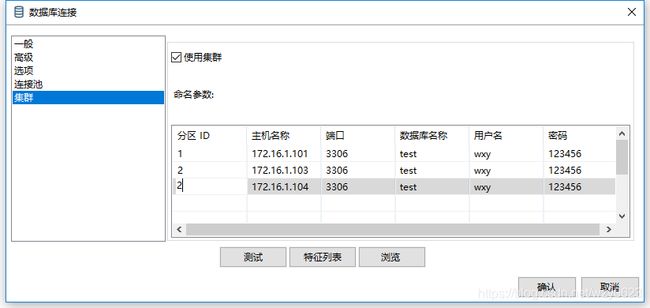 图10-37 分区有相同ID
图10-37 分区有相同ID
103与104两个分区的分区ID都是2。然后重新导入shared_source,并再次执行转换,结果只会向103中插入数据,而104没有执行任何操作。
从这个例子可以看到,Kettle里实现分区很简单:对于每个分区步骤,Kettle会根据所选择的分区方法启动多个步骤拷贝。如果定义了五个分区,就会有五个步骤拷贝。分区步骤的前一个步骤做重分区的工作。当一个步骤里数据没有分区,这个步骤把数据发送给一个分区步骤的时候,就是在做重分区的工作。使用一种分区模式分区的步骤把数据发送给使用另一个分区模式的步骤,也会做重新分区的工作。
本节实例的具体表数据和转换执行结果参见“Kettle数据库连接中的集群与分片”。其它数据库相关的步骤也和上面的例子类似,这样多个数据库可以并行处理。另外“Mirror to all partitions”分区方法可以并行将同样的数据写入多种数据库分区。这样在做数据库查询时,就可以把查询表的数据同时复制到多个数据库分区中,而不用再建立多个数据库连接。
5. 集群转换中的分区
如果在一个转换里定义了很多分区,转换里的步骤拷贝数会急剧增长。为了解决这个问题,需要把分区分散到集群中的子服务器中。
在转换执行过程中,分区平均分配给各个子服务器。如果使用静态分区列表的方式定义了一个分区模式,在运行时,那些分区将会被平均分配到子服务器上。这里有一个限制,分区的数量必须大于或等于子服务器的数量,通常是子服务器的整数倍(slaves × 2、slaves × 3等)。有一个解决分区过多问题的简单配置方法,就是指定每台子服务器上的分区数,这样在运行时就可以动态创建分区模式,不用事先指定分区列表。
记住如果在集群转换里使用了分区步骤,数据需要跨子服务器重新分区,这会导致相当多的数据通信。例如,有10台子服务器的一个集群,步骤A也有10份拷贝,但下面的步骤B设置为在每个子服务器上运行3个分区,这就需要创建10×30条数据路径,与图10-7中的例子相似。这些数据流向路径中的10×30-30=270条路径包含了远程步骤,会引起一些网络阻塞,以及CPU和内存的消耗,在设计带分区的集群转换时,要考虑这个问题。
五、小结
本篇介绍了转换的多线程、集群和数据库分区,重点内容包括:
- 介绍了一个转换如何并行执行步骤,如果一个步骤有多个步骤拷贝,如何分发数据行。介绍了数据行是如何被分发以及合并到一起的,并介绍了并发可能导致的几个问题。
- 介绍了如何在远程服务器上部署、执行、管理和监控转换和作业。
- 深入介绍了如何使用多台子服务器构建一个集群,如何构建转换来利用这些子服务器资源。
- 最后介绍了如何使用Kettle的数据库分区模式来并行处理数据库的读写操作。