刘洋——联邦学习技术在金融领域的研究与应用
⬆⬆⬆ 点击蓝字
关注我们
AI TIME欢迎每一位AI爱好者的加入!
2020 年 9 月 26 日,在由中国科协主办,清华大学计算机科学与技术系、AI TIME 论道承办的《2020 中国科技峰会系列活动青年科学家沙龙——人工智能学术生态与产业创新》上,微众银行人工智能部门资深研究员刘洋博士进行了题为《联邦学习在金融领域的应用》的主题报告,介绍了联邦学习的相关理论,并以微众银行的一系列应用为主,介绍了联邦学习的产业落地现状。

图 1:联邦学习在金融领域的研究与应用
作为中国首家互联网银行,微众银行成立至今已近 6 年,其最主要的产品是在手机微信端深入绑定的微粒贷,能够为大家提供及时迅速的金融理财、借款等业务。微众银行人工智能项目组于 2016 年成立,经过几年的积累,已经在联邦学习领域取得了诸多研究成果,并成功落地。
研究背景

图 2:联邦学习的研究背景
近年来,人工智能技术处于高速发展期。然而,随着人工智能技术发展进入深水区,出现了越来越多的壁垒和难题,数据孤岛就是其中之一。在实际的应用落地场景中,很难实现企业与企业之间的数据共享,即使在同一个企业中,不同部门之间的数据共享也十分困难。因此,往往只有少数的大型互联网公司才拥有真正的「大数据」,大多数小微企业和中小型企业面临着数据量小、数据维度稀少等问题,这些问题严重制约着人工智能技术的发展。
另一方面,在过去的几年中,人们对数据隐私保护的意识逐渐增强,相关的法律法规也得以逐步完善(例如,欧盟出台的通用数据保护条例 GDPR 和国内出台的网络安全法等越来越强的监管措施)。在此背景之下,数据共享也面临着越来越大的挑战,数据隐私保护也成为了在人工智能技术进一步发展的过程中,人们急需解决的重要难题,但同时也为安全的人工智能技术发展带来了巨大的机遇。
联邦学习概述
因此,微众银行顺势而为,提出了名为「联邦学习」的解决方案。为了说明联邦学习的基本概念,我们不妨将机器学习的模型比作为羊,将数据比作草。在过去,机器学习算法将所有草放在一起,把羊带到这堆草旁喂羊。然而,由于如今我们面临着数据保护和数据孤岛等难题,需要设计一种新的喂羊方式,即所有的草留在其本身所在的位置,我们将羊牵到各个草的所在地喂羊,我们期望该过程得到的效果与传统的方法几乎相同,且草与草之间没有进行数据交互,从而保护了各企业之间的数据安全。
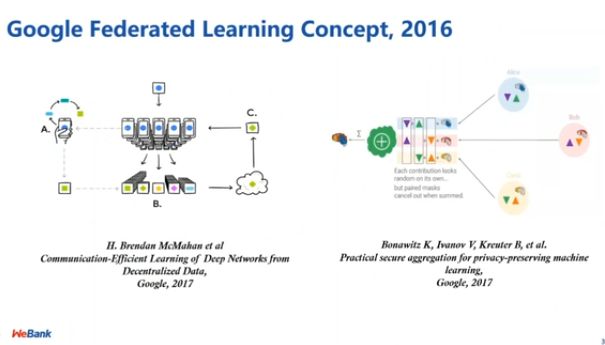
图 3:谷歌提出的「Federated Learning」
这一理想概念起源于谷歌在 2016 年提出的用于手机端联邦训练的「Federated Learning」。基于该方法,如果我们想要在安卓的手机端共同训练一个 NLP 的模型,可以先在各个手机端加载一个 NLP 模型,而手机端的用户可以在本地通过自己的数据更新这个模型的参数。接着,在无需上传手机端本地数据的情况下,各手机端模型的参数会被上传至云端,而云端只需要聚合这些模型参数,再进行下一轮的更新。
那么,我们上传的模型参数是否会泄露原始数据呢?在过去的几年中,研究人员针对这一问题展开了大量的研究。例如,谷歌提出了一种保护中间上传数据的方案——「安全聚合」(secure aggregation)。通过将秘密共享的手段应用于中间数据,我们可以保证云端无法「知晓」手机端的数据。该方案将手机端的数据分成若干子部分,而我们将这些子部分加合起来不会改变最终的结果。
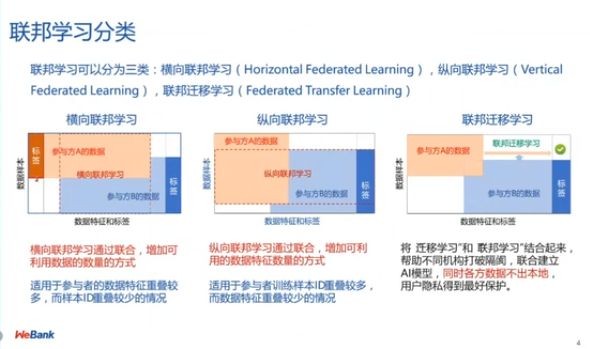
图 4:联邦学习的分类
经过近几年的发展,面对各种各样的应用场景,人们研发出了更多使用联邦学习的方式。因此,微众银行也将联邦学习原本的概念发展并且延伸到其它的应用领域和落地场景中。具体而言,我们将当下的联邦学习技术归纳为三类:横向联邦学习、纵向联邦学习和联邦迁移学习。分类标准如下:
(1)横向联邦学习:在上文所介绍的谷歌的「Federateed Learning」中,参与联邦学习的各方数据特征相同,但贡献数据的用户不同。此时,如果我们从数据样本和数据特征两个维度上考虑联邦学习使用的数据,数据是按照参与用户的维度横向分割的(参与者的数据特征重叠较多,样本 ID 重叠较少)。
(2)纵向联邦学习:在金融等领域中,我们往往会遇到参与联邦学习的各方数据特征不同的场景。例如,在不同的企业中、不同的场景下,相同的用户可能留下了不同的数据,如果我们能够将这些数据集中起来,将会有助于对用户行为的预测。此时,如果我们从数据样本和数据特征两个维度上考虑联邦学习使用的数据,数据是按照数据特征的纬度纵向分割的(参与者训练样本 ID 重叠较多,数据特征重叠较少)。
(3)联邦迁移学习:参与联邦学习各方的数据不同、用户不相同,数据特征也不相同,各方持有的数据重叠程度较小。此时,我们需要引入迁移学习对原始的训练和任务进行补充和增强。
联邦学习系统架构

图 5:微众银行提出的联邦学习架构
微众银行提出了一种主要针对于纵向联邦学习的联邦学习系统架构,该架构主要包含两个部分。首先,我们需要在加密空间上对样本进行对齐,识别出参与联邦学习的各个相同的用户。在识别出这些用户后,我们通过协作者 C 对这些用户的数据进行加密模型训练。加密训练包含以下步骤:公钥的分发与收集、加密过程中中间结果的交互、加密汇总梯度与损失、更新双方模型。
值得注意的是,在训练的过程中,我们传递的并不是数据本身,也不是数据的加密形式,而是模型使用数据在运算过程中产生的中间结果的加密形式,从而在加密中间结果上进行加密的梯度更新和损失的计算。最后,我们在加密的情况下更新双方的模型。在整个过程中,我们在保证模型的效果与传统训练方法完全一致的前提条件下,没有向其它各方泄露任何的底层数据,从而保证了数据安全。同时,这一系统架构也保证了建模的公平性,即参与着需要共同博弈。

图 6:联邦学习的应用场景
在过去的几年中,以微众银行团队为代表的一批研究人员成功地将联邦学习技术推广至不同的行业应用场景下。除了本次演讲主要提到的金融领域外,联邦学习在零售、智慧城市、智慧安防等应用场景下也取得了巨大的成功。近年来,国内的各大互联网企业陆续在联邦学习上进行各种各样的布局,针对联邦学习的开源项目层出不穷,国内联邦学习的发展趋势十分蓬勃。
联邦学习框架与标准

图 7:全球首个工业级联邦学习框架——「FATE」
作为联邦学习研究的领导者,微众银行首先开源了其人工智能团队自主研发的全球首个工业级联邦学习框架——「FATE」。FATE 是一种非常全面的分布式安全计算框架,在隐私保护方面,FATE 提供了针对多方安全计算的协议(包括同态加密等技术)。此外,微众银行近年来利用高效率的在线推理、迁移学习等技术解决了不同场景下的实际应用问题,并且在平衡效率和隐私的问题上进行了很多的尝试和努力。在 FATE 框架中,微众银行分阶段地体现和更新了这些实战经验。

图 8:FATE 框架发展现状
迄今为止,微众银行已经与超过 300 多家企业和 200 多家高校展开了合作。目前,微众银行已将「FATE」框架捐献给了「Linux Foundation」,成为了「Linux Foundation」的一个托管项目。目前,FATE 社区已经具有十分完备的运维机制,欢迎感兴趣的开发者对 FATE 框架进行尝试。

图 9:联邦学习标准制定
为了进一步推广联邦学习,目前由微众银行牵头,联合 30 多家企业和团体参与到了国际和国家联邦学习标准的制定工作中。
联邦学习在金融领域的应用案例
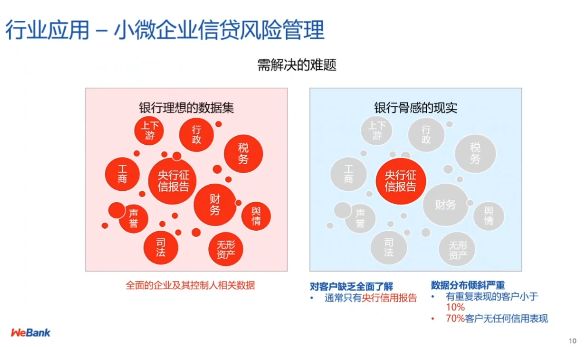
图 10:贷款风险管理场景下的数据交互难题
目前,在金融领域中,微众银行主要将联邦学习技术用于小微企业信贷以及个人贷款的风险管理,旨在解决银行在此类场景下存在的「数据维度缺失」、「数据低频」等问题。在银行中,我们可能收集到的数据包括征信报告以及用户在银行的一些表现数据。然而,由于用户使用银行的频次非常低,我们还需要结合第三方的数据(例如,来自互联网及其它数据源的数据)进行风控建模。实际上,在互联网金融领域中,利用上游数据的概念已经较为常见,但是随着监管越来越严,数据出库的难度日益提升,我们希望通过联邦学习技术搭建一个桥梁,连接银行数据以及其它的互联网数据。

图 11:基于联邦学习建立企业风控模型
例如,我们可以通过联邦学习技术打通企业征信和发票数据的交互渠道。此时,在合作企业段,数据可能包括这些小微企业的流水,这些流水是高频且相关的,流水的状况可以很好地反映一个企业的资金流和经营状况。通过使用联邦学习技术,我们可以对企业的征信进行更好的预测和评分。
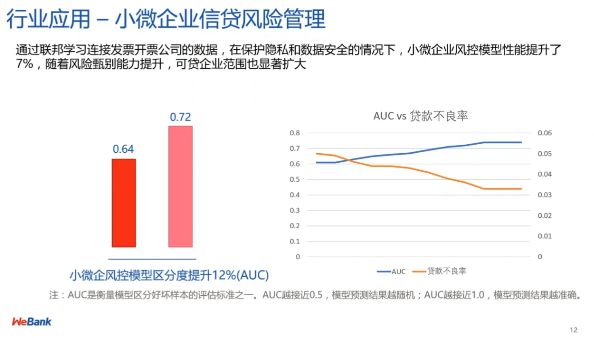
图 12:企业信贷风控管理效果提升
如图 12 所示,在采用联邦学习综合考虑银行与合作企业数据的情况下,对小微企业风控模型的区分度优于仅仅使用银行自身数据的风控效果,这种效果的提升可以体现在贷款不良率的减少和 AUC 的提升等方面。
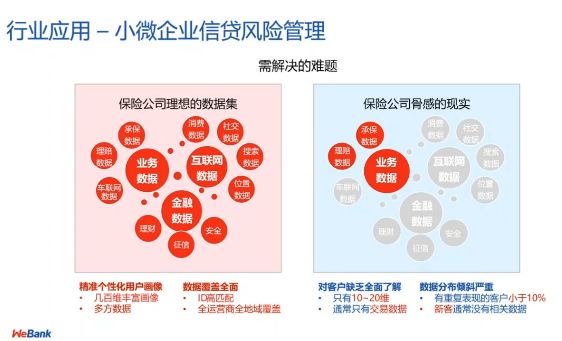
图 13:保险公司承保场景下的数据交互难题
此外,微众银行也将联邦学习技术运用于保险公司的承保数据。在该场景下,我们需要接入客户的多维精准画像。构建此类精准画像往往需要用到一些互联网数据(例如,腾讯、阿里巴巴等大型互联网企业持有的数据),从用户的商品交易、社交等方面对其进行精准的个性化分析。我们可以将这种个性化分析技术运用到对用户的保险理赔场景下。

图 14:基于联邦学习的保险定价模型
众银行已将联邦学习技术成功应用于保险定价,在实现保险权益个性化定价占比提升 8 倍的同事,提升了购买转化率。

图 15:保险权益定价效果提升
目前,微众银行在金融行业中对联邦学习进行了一系列卓有成效的推广,也遇到了诸多新的挑战。

图 16:全球第一本联邦学习专著
近期,由微众银行首席人工智能官杨强教授领衔编撰了全球首部介绍联邦学习的专著,并顺利出版发行了中、英文两个版本,介绍了联邦学习理论研究进展与业务落地现状。
整理:熊宇轩
审稿:刘洋
排版:田雨晴
AI Time欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你,请将简历等信息发至[email protected]!
微信联系:AITIME_HY

AI Time是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注
(点击“阅读原文”查看直播回放)