香港科技大学赵振杰:如何能让机器拥有物理常识
⬆⬆⬆ 点击蓝字
关注我们
AI TIME欢迎每一位AI爱好者的加入!
人机交互和智能化是当前发展机器人技术的两大挑战。在人与机器人交互的过程中,机器人需要拥有物理常识,才能更好的理解人类指派的复杂任务。语言是人与机器人之间交互的一种比较自然的方式,所以使自然语言处理拥有物理常识是必要的。举个例子,向机器人发出命令:“帮我倒杯水”,那么机器人需要理解杯子可以用来盛水,可以被抓取,然后通过识别环境中的物体,找到杯子,合理的规划机械动作以完成倒水的任务。目前基于自然语言处理的人与机器人的交互技术中,大多数是基于深度强化学习方法的,而深度强化学习所依赖的神经网络模型并不能很好地学习物理常识。
本期AI TIME PhD直播间,我们有幸邀请到了香港科技大学计算机科学与工程系博士生赵振杰分享他的观点。讲者分享了具有物理常识的自然语言处理的起源和发展,同时也分享了讲者本人研究的使用知识图谱补全的方法来完成物理常识的学习。

赵振杰:香港科技大学计算机科学与工程系博士生,导师为麻晓娟教授。主要研究方向为人机交互和自然语言处理。

一、起源和发展:让机器拥有物理常识
1.1起源
负采样
SHRDLU是Terry Winograd在博士期间设计的自然语言理解程序系统。在这个系统里,用户可以通过与计算机进行对话,从而在一个积木世界里搭建想要的模型。用户可以完成移动目标、命名集合以及查询状态等操作。由于此系统是基于规则的系统,仅能够接收比较简单的语言指令,并且积木世界的状态也比较简单,所需的词汇量大概在50个左右。虽然SHRELU的系统仅能接受比较简单的指令,但是却在某种程度上证明了人类的认知过程可以通过语言的形式表示为一种算法,从而在计算机里实现。
1.2发展
负采样
近些年来,类似于SHRDLU的想法,学者通过强化学习的方法,使得计算机能够接收一段复杂的语言指令,并完成复杂虚拟空间或真实空间的导航和操作任务,一般称为指令跟从(instruction following)或空间推理(spatial reasoning)。比如在教机器人新技能中,She & Chai通过将人说话的指令、环境状态和机器动作表达为谓词逻辑形式,在人机互动中使用强化学习的方式,使得机器人学习到完成任务的最优策略(She & Chai, 2017)。
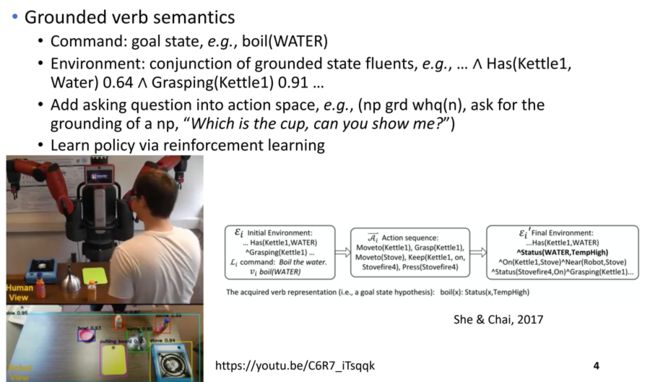
图1:指令跟从(She & Chal, 2017)
进一步,Blukls等使用两阶段的学习方法,首先通过监督学习获得从文本和图像相对应的目标概率图,然后根据该概率图使用深度强化学习的方法学习控制机器人策略网络,从而使机器人可以理解语义信息更加丰富的指令,并在真实环境中执行更加复杂的操作(Blukls et al, 2019)。

图2:空间推理(Blukls et al, 2019)
二、动机与挑战:人机交互
2.1动机
负采样
在人机交互中,人给的命令通常是high level的目标,机器人需要将其转变可执行的low level动作,在执行的过程中,机器人需要有一定的物理常识才能在不造成破坏的情况下安全可靠的完成任务。同时,在对话过程中,机器人需要理解物理常识,才能给人更合理的反馈,从而实现流畅的人机协作。
2.2挑战
负采样
首先需要明确的是物理常识是什么?根据Forbes等人的定义,物理常识指的是物体的物理性质以及如何操作它们,具体包括三个子任务:物体属性关系(object property)、物体功能关系(object affordance)和功能属性关系(affordance property)。

图3:物理常识是什么
通过语言进行的人机交互是一种比较自然的方式,并且目前大多数自然语言处理技术强依赖于神经网络。然而,Forbes等人在CogSci 2019的一篇文章中指出,神经网络模型并不能很好的学习物理常识。虽然对于文本中常见的物体属性关系和物体功能关系,像预训练模型BERT这样的大规模神经网络模型能够有较好的预测效果,但对于需要一定推理能力的功能属性关系,BERT并不能做很好的预测。一般认为,像BERT这样的神经网络模型仅仅能够学习文本中显式存在的关联关系。
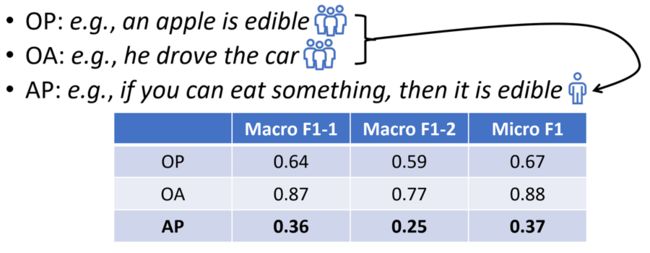
图4:BERT对物体属性关系、物体功能关系和功能属性关系的预测结果对比
三、方法和实验:学习物理常识
3.1方法
负采样
由于BERT在预测物体属性关系和物体功能关系上都有较好的效果,那么能不能通过物体属性关系和物体功能关系的预测来提升对功能属性关系预测的性能,从而提升模型的泛化能力呢?讲者将物理常识学习描述成为了一个知识图谱补全的问题,通过张量分解的方法,隐式的建模物体属性关系、物体功能关系和功能属性关系三者之间的联系,从而提升功能属性关系的预测性能。相比于一般的知识图谱补全问题,物理常识的知识图谱面临两个挑战:
1)训练样本较少,而且很多物理常识难于在文本数据中找到;
2)物理常识的关系数目较少,而且都是多对多的关系。
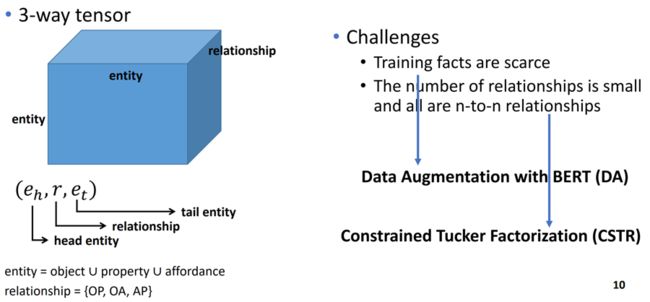
图5:物理常识的知识图谱面临的问题和解决方法
a. 基于BERT的数据增强
面对训练样本少的困难,参照Forbes的做法——使用BERT来做数据增强。先将事实转写为一句话, 把这句话作为fine-tuned BERT模型的输入,最后将模型输出的预测标签作为该样本的标签。由于BRET对物体属性关系和物体功能关系才有较好的预测性能,所以讲者只对物体属性关系和物体功能关系做了数据增强。讲者遍历了所有可能的物体属性对和物体功能对,以生成训练数据。
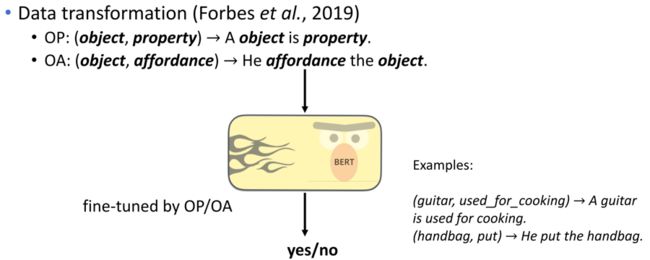
图6:基于BERT的数据增强
b. 具有约束的Tucker分解
讲者参照Balazevic等人的工作,使用Tucker分解的方法,通过引入一个核张量,使得模型可以建模各关系之间的隐含的联系。
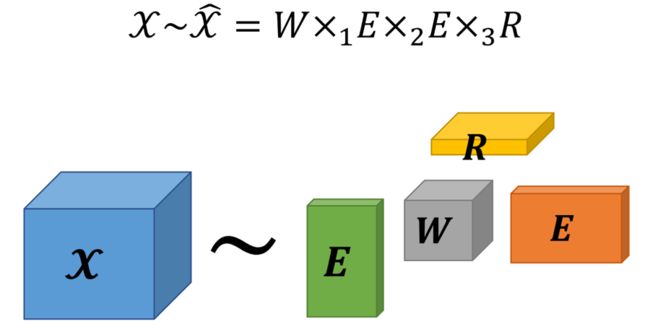
图7:Tucker分解
由于物理常识学习的知识图谱补全与其他知识图谱补全相比有自己的特殊之处,讲者针对物理常识学习添加了两个必要的约束——类型约束和否定关系。类型约束的目的是去除不可能的关系,比如对于一个样本(A,B),只有当A属于物体类,B属于属性类,(A,B)才有可能有物体属性这样一个关系。面对物理常识关系条目较少的问题,讲者通过引入否定关系增加关系数量,同时也可以利用在文本中出现的否定关系作为训练样本,比如(person, NOT-OP, a_tool),即人不是工具。
3.2发现
负采样
a.数据集
使用Forbes给出的数据集,其中包含80个物体、50个属性和504个功能。以下是数据集的详细统计数据:
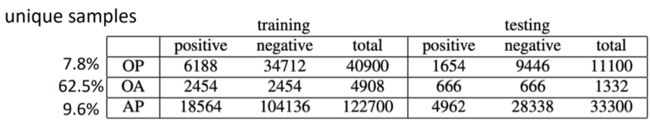
图8:物理常识数据集
数据集中有许多重复的样本和较多的噪声,如一个样本既是正样本又是负样本。
b.任务
知识图谱补全有两个任务:三元组分类和链接预测。三元组分类是预测一个事实三元组是否正确,而链接预测是在已知第一个实体和关系的情况下预测第二个实体。以下是三元组分类和链接预测的评价标准:

图9:三元组分类和链接预测的评价评价标准
c.对比
与经典的知识图谱嵌入方法TransE, TransD, RESCAL, DistMult, ComplEx, SimplE, Tucker在三元组分类和链接预测上进行对比,以下是对比结果:
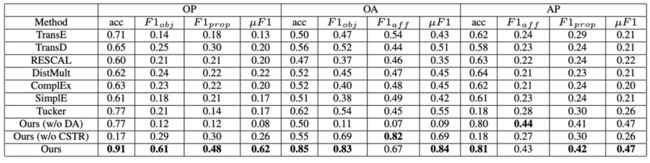
图10:三元组分类结果对比
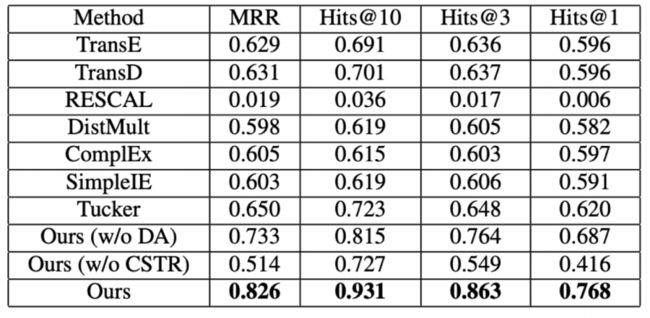
图11:链接预测结果对比
实验结果验证了实验方法的有效性。同时通过消融实验验证了所使用的数据增强和具有约束的Tucker分解方法均对最后结果起到了作用。
总结
讲者通过将物理常识学习转变为知识图谱补全问题,并使用了基于BERT的数据增强和具有约束的Tucker分解的方法,此模型在三元组分类和链接预测任务中较之前的模型取得了更好的预测结果,同时也在训练样本少且噪声多的情况下较好地建立更多更准确的物理常识。这是人机交互中让机器理解物理常识的初步工作,希望能够帮助有物理交互的自然语言处理任务。
相关文献及链接:
Zhao, Z., Papalexakis, E., and Ma, X. (2020). Learning Physical Common Sense as Knowledge Graph Completion via BERT Data Augmentation and Constrained Tucker Factorization.
https://www.aminer.cn/pub/5f7fe6d80205f07f689733b5/learning-physical-common-sense-as-knowledge-graph-completion-via-bert-data-augmentation
References:
Maxwell Forbes, Ari Holtzman, and Yejin Choi. 2019. Do neural language representations learn physical commonsense?
https://arxiv.org/abs/1908.02899
Ivana Balazevic, Carl Allen, and Timothy Hospedales. 2019. TuckER: Tensor factorization for knowledge graph completion.
https://arxiv.org/abs/1901.09590
负采样
整理:蒋予婕
排版:杨梦蒗
审稿:赵振杰
本周直播预告:


AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你,请将简历等信息发至[email protected]!
微信联系:AITIME_HY

AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注
(直播回放:https://b23.tv/PxZV1v)
(点击“阅读原文”下载本次报告ppt)