eBPF 在网易轻舟云原生的应用实践
作者 | 李阳,陈启钧
策划 | 田晓旭
首发 | InfoQ
eBPF 是 Linux 内核近几年最为引人注目的特性之一,通过一个内核内置的字节码虚拟机,完成数据包过滤、调用栈跟踪、耗时统计、热点分析等等高级功能,是 Linux 系统和 Linux 应用的功能 / 性能分析利器。本文将介绍 eBPF 的技术特点,及 eBPF 在网易杭研轻舟系统探测和网络性能优化方面的应用。
1. 技术浅析—eBPF 好在哪里
eBPF 是 Linux Kernel 3.15 中引入的全新设计,将原先的 BPF 发展成一个指令集更复杂、应用范围更广的“内核虚拟机”。
eBPF 支持在用户态将 C 语言编写的一小段“内核代码”注入到内核中运行,注入时要先用 llvm 编译得到使用 BPF 指令集的 ELF 文件,然后从 ELF 文件中解析出可以注入内核的部分,最后用 bpf_load_program() 方法完成注入。 用户态程序和注入到内核中的程序通过共用一个位于内核中的 eBPF MAP 实现通信。为了防止注入的代码导致内核崩溃,eBPF 会对注入的代码进行严格检查,拒绝不合格的代码的注入。
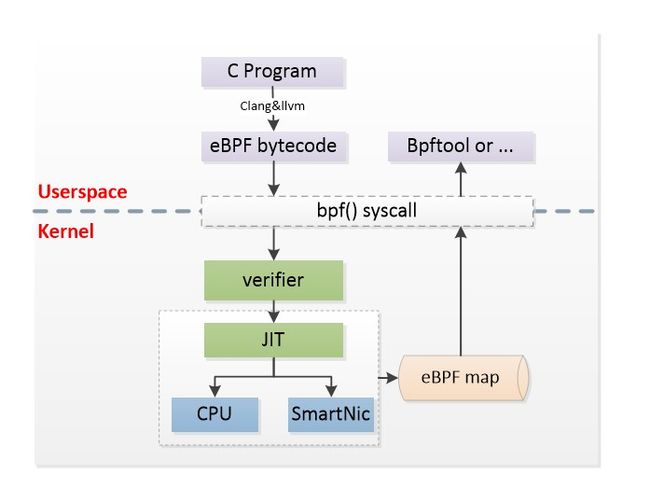
1.1 eBPF 的技术优势
eBPF 具备一些非常棒的特性,使得我们在内核层面的监控变得更加便捷、高效,并且非常安全:
- 平台无关,由 JIT 负责将 BPF 代码翻译成最终的处理器指令;
- 内核无关,辅助函数(Helper functions)使得 BPF 能够通过一组内核定义的函数调用(Function call)来从内核中查询数据,或者将数据推送到内核。不同类型的 BPF 程序能够使用的辅助函数可能是不同的;
- 安全检查,和内核模块不同,BPF 程序会被一个位于内核中的校验器(in-kernel verifier)进行校验,以确保它们不会造成内核崩溃、程序永远能够终止等;
- 方便升级,对于网络场景(例如 TC 和 XDP),BPF 程序可以在无需重启内核、系统服务或容器的情况下实现原子更新,并且不会导致网络中断;
- 通信方式,eBPF MAP,跟 Ftrace 提供的 ring buffer 相比就是数据常驻内存,不会读取之后就消失;
- 事件驱动,BPF 程序在内核中的执行总是事件驱动的;
1.2 eBPF 和其他 trace 工具的对比
在 eBPF 出现之前,Linux 已经存在多种成熟的 trace 机制和相应的上层工具:
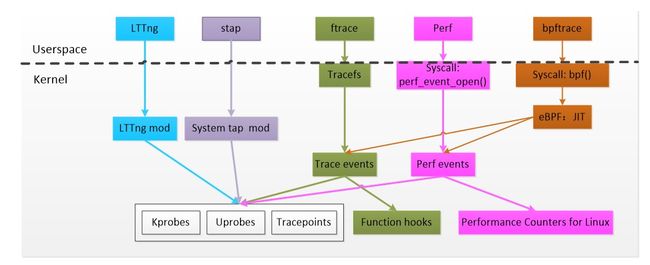
如上图所示,eBPF 借助 perf_event 和 trace_event 几乎支持对目前所有已知 trace 功能的支持,唯一与传统 trace 工具不同的是,attach 到每个探测点的 probe 函数是运行在 JIT 虚拟机上的 eBPF 程序,具备上面提到平台无关、内核无关、安全等一系列更优的特性。
2 热点追踪—eBPF 有哪些应用场景
eBPF 应用主要分为两个场景,一是系统探测、二是网络方面性能优化(包括数据面传输和规则匹配等场景)。
2.1 在系统探测方面
在国外,Google 已经开始用 BPF 做 profiling,找出在分布式系统中应用消耗多少 CPU。而且,他们也开始将 BPF 的使用范围扩展到流量优化和网络安全。
在国内,字节跳动利用 eBPF 技术开发了一款名为 sysprobe 的监控工具,用来定位分析线上业务的性能瓶颈等。
基于 eBPF 开源的探测工具推荐两个:
- BCC 是 eBPF 的一个外围工具集,使得 “编写 BPF 代码 - 编译成字节码 - 注入内核 - 获取结果 - 展示” 整个过程更加便捷。此外 BCC 项目还有一个非常丰富的探测工具集合。
- Bpftrace 可以理解为是 eBPF 的高级追踪语言,动态的翻译这些语言,生成 eBPF 后端程序并通过 BCC 工具实现和 Linux BPF 系统进行交互。
2.2 在网络性能优化方面
Facebook 用 BPF 重写了他们的大部分基础设施。例如使用 BPF 替换了 iptables 和 network filter,并且 Facebook 基本上已经将他们的负载均衡器从 IPVS 换成了 BPF,此外他们还将 BPF 用在流量优化(traffic optimization)、网络安全等方面。
Redhat 则正在开发一个叫 bpffilter 的上游项目,将来会替换掉内核里的 iptables,也就是说,内核里基于 iptables 做包过滤的功能,以后都会用 BPF 替换。
国内方面腾讯云也对外宣称利用 eBPF 替换 conntrack 模块使 k8s service 短链接性能提升 40%。
3. 牛刀小试—eBPF 在网易轻舟的应用及落地
eBPF 在网易轻舟的应用也分为系统探测和网络性能优化两个方面。
3.1 系统探测
我们现有监控工具只能监控内核主动暴漏的数据,存在监控盲点。通过修改内核或开发内核模块的方式进行监控,上线周期长、风险高,针对不同版本内核的适配费时费力还容易出错。所以我们在开源项目 ebpf_exporter 的基础上完成 ebpf 监控子系统的开发。
eBPF 监控子系统架构:
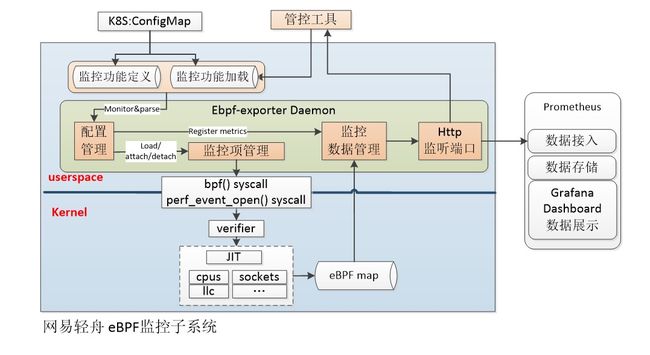
eBPF 监控子系统采用容器化部署,支持通过 K8s 部署和管理,监控数据通过 Prometheus 进行持久化存储并通过 Grafana 进行展示。eBPF 监控子系统具备如下特性:
- 平台无关且内核无关;
- 安全检查以保证绝对安全;
- 可对内核进行任意监控;
- 支持 pid/container/pod 级别的细粒度监控;
- 支持监控项动态开启、关闭;
- 支持监控项在线升级;
- 提供统一的监控项开发接口;
- 提供 metrics/json 格式的监控数据及统一的数据获取接口 ;
- 支持 K8s 部署、管理;
关于 eBPF“内核无关”特性的说明:
上述特性中,“平台无关”由 eBPF 机制自身提供(JIT),而内核无关这一特性则受多方面因素的影响,受限内核无关分为两个方面:
- 内核类型和数据结构是不断变化的,包括函数接口,eBPF 程序对内核的引用如何保证在不同版本内核中有效;
- 不同版本内核的内存布局也是不同的,具体信息必读从独立的内核环境中才能获得;
针对内存布局这个问题,目前我们无需多虑。因为 ebpf_exporter 是基于 BCC 技术实现的,而 BCC 则是通过即时编译的方式加载 eBPF 程序,基于 BCC 唯一的缺点就是每次加载会占用一些资源,多少取决于监控程序的数量和复杂度。
针对第一个问题(即 kernel 代码一直在变的问题),内核中的 eBPF 机制抽象了一组有限的“稳定的接口”,这些接口屏蔽了不同内核版本之间的差异,但这只是一组有限的接口,如果出于需求 eBPF 程序对内核耦合过深,我们依然需要通过#if#else 来迎合不同版本内核之间的差异(例如数据结构和函数接口的差异)。
所以 eBPF 的内核无关是有限的,需要 eBPF 机制和开发者共同努力实现。此外除了 BCC 这种即时编译的方案,还有另外一种名为 CO-RE (Compile Once – Run Everywhere) 的编译方式,其核心依赖于 BTF(更加先进的 DWARF 替代方案),该方案本文不做展开,感兴趣的同学可自行 Google CO-RE。
监控功能的开发:
eBPF 监控子系统是一个框架,本身不具备任何监控功能。eBPF 监控子系统开发完成后,我们又根据产品方、业务方以及运维方的需求,开发了一些具体的监控功能,例如:
- 监控 HTTP 协议的网络请求延迟。因为以往线上业务发生请求超时,我们无法确定延迟是发生在网络传输阶段,还是业务处理阶段,加大了问题排查的复杂度和难度。通过该监控功能,开发运维人员则可以清晰的知道延迟发生的具体阶段,大大缩短了相关问题的排查解决时间。
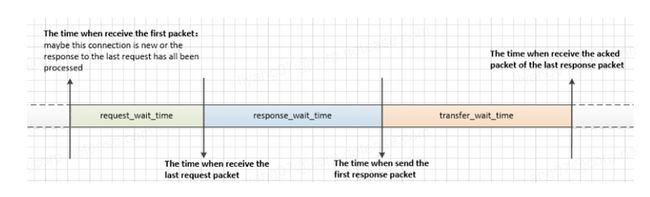
-
监控每个进程中各状态的 TCP 链接数。在引入 eBPF 监控之前,我们曾通过 inet_diag 实现了该监控功能,但是每次读取都是整个系统的全量,对于动辄几十万上百万连接的线上节点,非常占用 CPU 资源,没办法做到在线的实时监控。引入 eBPF 后,我们以非常小的代价达到了相同的监控效果,实测 QPS 性能只有 3.7% 的下降,对 CPU 资源的占用可以忽略不计。
-
开发了 cpucycles/instructions、llcreferences/misses 等一系列针对硬件 PMU 的监控功能用来支持混合部署中的调度功能。
更多的监控功能就不一一列举了,除了自研的一些监控,我们还将 BCC 工具集中一些功能引入了进来,目前主要用来支撑自动诊断、监控报警、性能调优等场景。
eBPF 开发中遇到的问题:
一直都在陈述 eBPF 的优点,但是在开发具体监控功能的过程中,依然存在诸多限制,包括内核实现方面的限制也有 eBPF 自身的一些限制,需要开发者充分的考虑,例如在多核平台上如何保证对 eBPF MAP 中数据修改操作的原子性、如何将监控数据与产生数据的进程关联起来等等。
有些问题我们可以解决,但是也有些问题我们目前也没找到好的解决方法,例如将监控数据与产生数据的进程关联起来这个问题,这是一个非常常见的问题,通常由内核的实现逻辑引入,该问题我们在监控 TCP 连接状态变化的场景中(连接建立过程不在进程上下文),通过记录 socket 创建以及 socket 继承等操作得到了解决,但是在 Block IO 相关的监控场景中就没那么好解决了,我们依然在这方面不断探索。
3.2 网络性能优化
在网络性能优化方面,网易轻舟也基于 ebpf 的 sockmap 和 sk redirect 功能研发了自己的 sockops 组件,主要用于加速 istio 架构中 sidecar 代理和本地进程之间的通信。
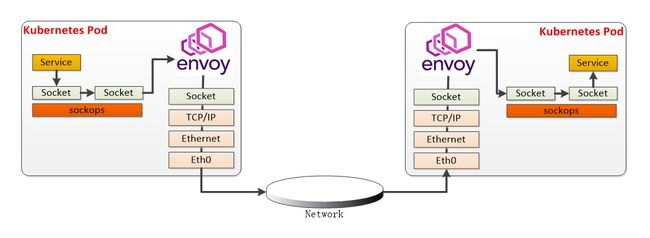
Sockops 技术原理说明:
Sockmap 是 eBPF 提供的一个特殊的 eBPF MAP 类型,主要用于 socket redirection,在 socket redirection 中,socket 被添加到 sockmap 中并由 key(主要是四元组)引用,然后该 socket 在调用 bpf_sockmap_redirect()时进行重定向。
sockops 的技术原理如下图所示,对于本地通信可以绕过 TCP/IP 协议栈将报文直接发给对端 socket,以此来提高性能。Sockops 组件技术原理如下图所示:
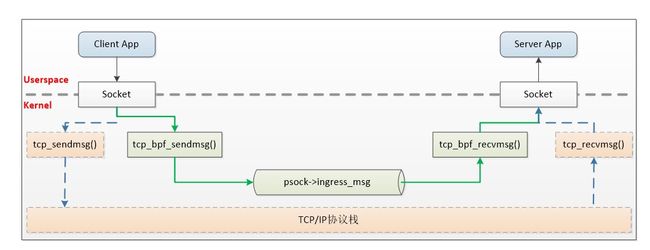
Sockops 数据面对轻舟服务网格场景的适配:
如果一个报文的 key(主要是四元组)在 sockmap 中被命中,那么该报文将绕过 TCP/IP 协议栈,而被直接发送给接收端的 socket,接收端的 socket 对应的就是下图中 sockmap 的 value 所存储的 skops 结构。

首先我们监听 TCP 链接状态的变化,在连接建立时,填充 sockmap。然后我们再通过 eBPF 的 sk_msg 功能 hook TCP 的发包流程(sendmsg/sendfile 等),并在 hook 函数中调用 bpf_sockmap_redirect()对 socket 进行重定向。
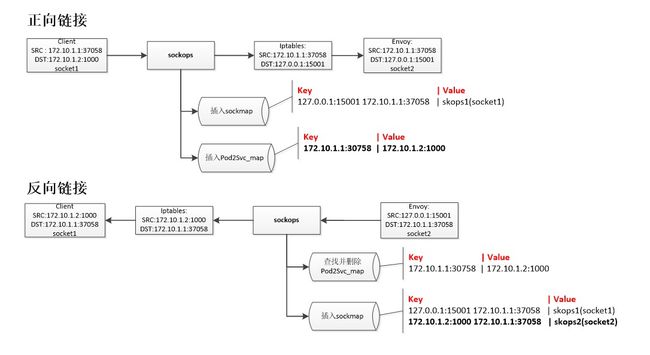
不过在 istio 环境中,该情况会变得稍微复杂一些,因为 istio 通过 iptables redirect 将 pod 访问 svc 的报文重定向到 envoy,加之 sockmap 的捕捉是在 iptable 规则之前,所以 sockmap 捕捉到的反向连接跟正向连接的源、目的地址不是一一对应的,找不到正向连接信息。我们的解决方案是新增一个 eBPF MAP,并在正向连接建立时,以源地址为 key,目的地址作为 value 存储起来,反向连接建立时根据反向链接的目的地址可以直接找到正向连接的完整信息。用一张图可以比较清晰的看懂这个过程:
Sockops 组件完整的架构设计如下图所示:

主要分为用户态 DaemonSet 程序和运行在内核中的 eBPF 程序两部分组成:
- 用户态 DaemonSet 程序,主要负责一些管控面的操作,包括监控 K8S、docker 的一些信息或者事件,然后动态更新 eBPF 程序的配置(用来支持细粒度开启关闭 sockops 功能),还包括编译加载 eBPF 程序、提供整个 sockops 组件的升级、对接 prometheus 提供自身的一些监控信息等功能;
- 内核态 eBPF 程序,则主要负责上面讲到的全部数据面的加速功能,并根据用户态 DaemonSet 程序同步的配置,具体实现一个细粒度的 scokops 功能的开启关闭;
Sockops 组件加速调优结果:
最终,我们通过 sockops 组件加速,envoy 单 worker 情况下:
- both sidecar 时延降低约 15-20%,qps 提高约 20%;
- client sidecar 时延降低约 10%,qps 提高约 20%;
4 未来展望
在系统探测方面,目前我们仅仅是通过 eBPF 解决了一些迫切的问题,这些问题通过常规的监控手段无法做到或者代价高昂。随着 eBPF 监控在内部的应用,我们还会逐步通过 eBPF 监控替换掉以往一些比较重的、对上层应用侵入比较深的监控功能,一来可以提高监控模块的性能,二来也提高了监控模块的可运维性。此外我们仍在开发一些相对复杂的 eBPF 监控功能,这些监控功能结合自动诊断平台,可以协助开发运维人员或者直接自动发现一些线上排查起来非常繁琐的问题,以此提高上层产品的 SLA 保障水平。
在网络性能优化方面,我们有一些对 iptables 依赖较重的场景(例如 kube-proxy),我们会利用 eBPF 并结合社区的一些成果,给出性能优化方案及原型的开发验证。目前已经有很多非常好的开源项目,提供了类似的功能,代表性的如 cilium,我们也针对 cilium 做了一系列验证,在性能及功能方面并未达到我们的预期,所以我们决定还是从我们自身的需求入手,借助社区已有的成果自研一个轻量级的组件来满足需求。
作者简介:
李阳,网易杭州研究院轻舟云原生系统资深开发工程师,7 年开发经验,曾就职于绿盟科技和 360 安全研究院,专注于 linux 内核开发、系统和网络安全及性能调优。目前在网易杭研负责虚拟化网络数据面的性能调优工作。
陈启钧,网易杭州研究院轻舟云原生资深开发工程师,十年以上开发经验,曾就职于华为,主要从事存储网络管理、容器以及网络虚拟化相关工作,专注于发现并解决问题。目前在网易杭研主要负责 VPC 网络、轻舟容器网络、轻舟服务网格等方面的性能调优工作,主要关注 Kubernetes、eBPF/XDP、用户态协议栈相关技术。