Curve技术解析之MDS元数据管理
curve简介
curve是今年7月份开源的一个⾼性能、⾼可⽤、⾼可靠的分布式存储系统,主打⾼性能、低延迟。
Curve设计可以作为多种存储场景的底层存储:例如块存储,对象存储,云原⽣数据库,EC等。
当前Curve已实现⾼性能块存储,并且基于这⼀场景对接了openstack 和 k8s。openstack上主要是⽤作云主机的系统盘和云盘,⽬前已经在线上稳定一年多了。k8s上主要是想作为计算节点的数据⽬录,这个场景⽬前在灰度环境中测试验证中。
当前curve的整个项目已经完全开源到github,感兴趣的小伙伴可以去star&&fork围观一下。
- github主页:https://opencurve.github.io/
- github代码仓库:https://github.com/opencurve/curve
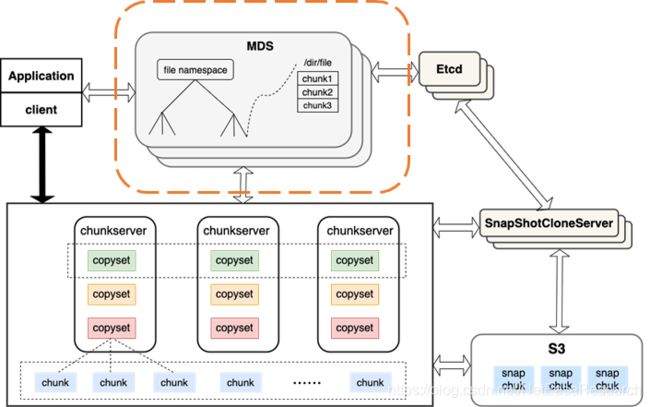
Curve存储系统的基础设计框架与经典的GFS基本类似,采⽤有中⼼节点的架构,核⼼服务由三个部分组成:
- 元数据节点MDS,主要有两个职责,⼀⽅⾯管理和存储元数据信息,另⼀⽅⾯感知集群状态并进⾏调度。元数据存储在etcd中。
- 数据节点chunkserver, ⼀⽅⾯负责数据的存储,另⼀⽅⾯负责数据⼀致性(如果底层是多副本,需要负责副本间的数据⼀致性)。
- 客⼾端client, 向上层应⽤提供对⽂件的操作接⼝(open、read、write等), 会和mds以及chunkserver交互,与mds交互实现对元数据的增删改查;与chunkserver交互实现对数据的增删改查。
还有一个快照克隆服务器:
- 快照克隆服务器独⽴于核⼼服务,对外提供了http接⼝,⽤于处理和管理快照克隆任务。
这篇文章会介绍一下curve的元数据的管理,主要是mds的元数据的管理。
mds是curve的元数据管理服务,负责整个集群的元数据管理。mds的所有元数据信息都会持久化到kv存储中,curve选择了etcd作为元数据的存储。
为了加快元数据的访问,mds还在内存维护了一个元数据的cache。cache采用LRU(Least Recently Used)淘汰策略,cache最多缓存的记录条目数量,通过mds的配置文件进行配置。
mds存储的元数据包含拓扑信息的元数据,namespace的元数据。所有的信息都是经过一定的编码,以kv的方式保存在元数据中。不同类型的元数据的编码方式不同,所有保存在mds的元数据的key都是以 “prefix + 其他字段”的方式进行编码。value则是对应的元数据序列化为字符串。
不同类型的元数据的前缀不同,这些前缀比如:
const char FILEINFOKEYPREFIX[] = "01";
const char SEGMENTINFOKEYPREFIX[] = "02";
const char SNAPSHOTFILEINFOKEYPREFIX[] = "03";
const char CHUNKSTOREKEY[] = "05";
const char TOPOLOGYITEMPRIFIX[] = "10";拓扑元数据信息
curve的拓扑信息由mds的topology模块管理,topology管理集群的 topo元数据信息。用于管理和组织机器,利用底层机器的放置、网络的规划以面向业务提供如下功能和非功能需求。
- 故障域的隔离:比如副本的放置分布在不同机器,不同机架,或是不同的交换机下面。
- 隔离和共享:不同用户的数据可以实现固定物理资源的隔离和共享。
下图是一个topology的层级关系图。一个集群可以支持1到多个Pool,每个Pool下有多个zone,每个zone由多个server组成,每个server上有多个chunkserver。
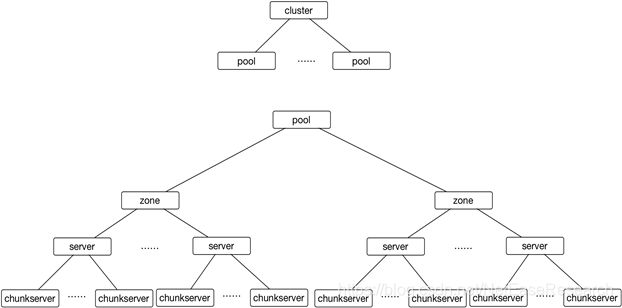
介绍一下各个组件的概念。
- pool: 用于实现对机器资源进行物理隔离,server不能跨Pool交互。运维上,建议以pool为单元进行物理资源的扩容。
- zone: 故障隔离的基本单元,一般来说属于不同zone的机器至少是部署在不同的机架,一个server必须归属于一个zone。
- server: 用于抽象描述一台物理服务器,chunkserver必须归属一个于server。
- Chunkserver: 用于抽象描述物理服务器上的一块物理磁盘(SSD),chunkserver以一块磁盘作为最小的服务单元。
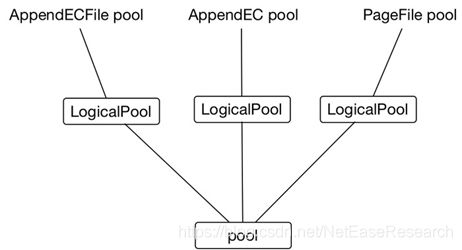
curve在上物理pool之上又引入了逻辑pool的概念,以实现统一存储系统的需求,即在单个存储系统中可以同时支持块存储、对象存储、进行对象存储。
Curve底层通过不同的⽂件类型⽀撑不同上层应⽤, curve的数据组织形式是⽂件。Curve提供三种⽂件类型,PageFile、AppendFile、AppendECFile
- PageFile支持块设备。
- AppendFile支持在线对象存储(规划中)。
- AppendECFile支持近线对象存储可以共存(规划中)。
目前我们只实现了对块存储的支持。
如下图所示LogicalPool与物理pool为多对一的关系,一个物理pool可以存放各种类型的file。当然由于curve支持多个pool,可以选择一个logicalPool独享一个pool。
topo的元数据信息的来源有两种:
一部分是curve集群上线时确定的;还有一部分是集群在运行的过程中,通过心跳上报的信息。
集群上线的topo信息,这个是集群上线时,在配置文件中指定。比如下面是一个新集群上线的例子,一个简单的配置文件如下。在这个集群中,有一个物理pool pool1,这个物理pool由3个zone组成,分别为zone1, zone2, zone3。每个zone有一台server。在物理pool上,还创建了一个逻辑pool,逻辑pool使用3个zone,采用3副本。

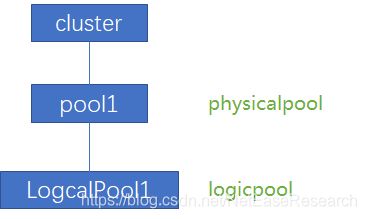
cluster_map:
servers:
- name: server1
internalip: 192.168.0.1
internalport: 8200
externalip: 192.168.0.1
externalport: 8200
zone: zone1
physicalpool: pool1
- name: server2
internalip: 192.168.0.2
internalport: 8200
externalip: 192.168.0.2
externalport: 8200
zone: zone2
physicalpool: pool1
- name: server3
internalip: 192.168.0.3
internalport: 8200
externalip: 192.168.0.3
externalport: 8200
zone: zone3
physicalpool: pool1
logicalpools:
- name: logicalPool1
physicalpool: pool1
type: 0
replicasnum: 3
copysetnum: 100
zonenum: 3
scatterwidth: 0心跳上报的topo信息,主要是chunkserver和mds之间的心跳信息。chunkserver会定期向mds发行心跳信息,在心跳信息中其实带有chunkserver的状态信息,比如chunkserver上的负载、容量、副本状态、是否可用等信息。mds根据收到上报的信息,更新拓扑元数据。如果mds一段时间没有收到chunkserver心跳,还会修改chunkserver的状态。

- Online: chunk server在线,正常服务。
- Unstable: chunk server一段时间没收到心跳(默认30s),但是还没有到达offline的时间(默认30min),chunkserver状态改为unstable状态,打印一条warning日志。
- Offline :chunk server超过offline的时间没有收到心跳(默认30min), chunkserver状态改为offline,打印一条error日志。调度模块感知到offline状态,触发chunk server的recover修复。
namespace元数据信息
curve目前仅支持块存储,每个块设备在mds都有一个对应的文件。为了方便管理,curve还引入类似于文件系统那种层次结构。一个curve集群在curvefs中有且仅有一个根目录“/”,根目录在系统初始化的时候自动创建。目录可以嵌套,目录下可以存放子目录或者文件。
curve的namespace信息一方面保存着文件和目录的元数据信息,一方面还保存着文件和目录的层次关系。
无论是目录,还是文件,统一都用FileInfo表示,区别在于他们的类型不一样。
FileInfo的编码方式:
- key:prefix(2Byte)+parentId(8Byte)+fileName;
- Value:FileInfo序列化后的字符串。
FileInfo的各个字段含义如下:

如下图所示的一个curvefs的目录层次结构,根目录下有目录home和文件tmp,home下有目录dir1,目录dir2,文件filez,dir1下有文件filex,dir2下有文件filey。
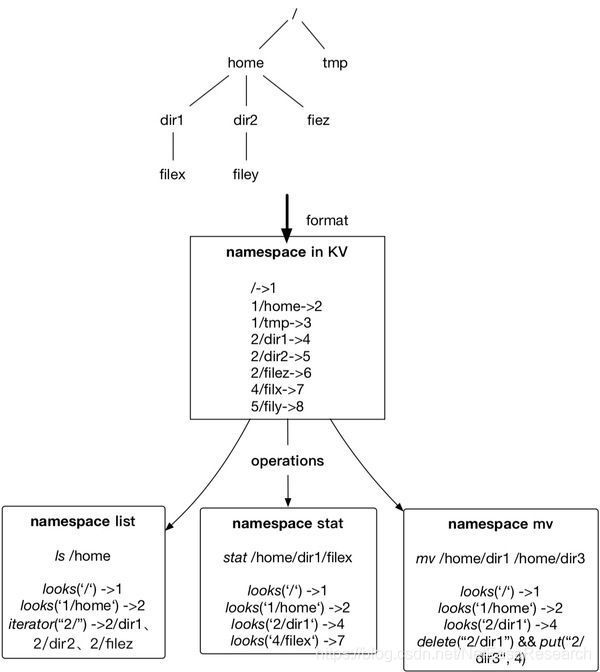
如上所示。这些文件和目录经过编码,以kv的方式保存在etcd中。文件和目录的key的前缀都相同,这里省略了prefix,在KV中,Key是ParentID + "/"+ BaseName,Value是自身的文件ID;这种方式可以很好地平衡几个需求:
- 文件列目录:列出目录下的所有文件和目录
- 文件查找:查找一个具体的文件
- 目录重命名:对一个目录/文件进行重命名
地址空间的映射元数据信息:
curve的空间采用瘦分配(thin provisioning)的方式进行空间分配,也就是说一开始卷在创建的时候,是没有实际分配空间的,仅仅是在元数据中记录了文件的长度和空间分配的粒度,真正的空间分配只有在地址真正第一次真正访问到的时候才会触发。
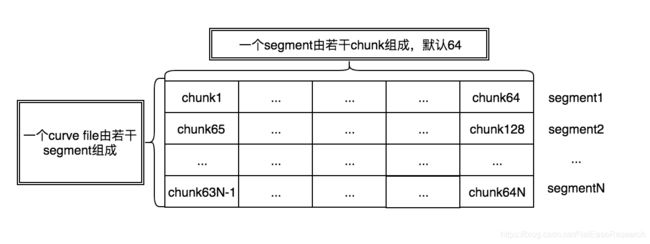
curve的底层按照chunk进行空间管理,但是chunk的切分粒度比较小,如果按照chunk进行分配,大量chunk分配会对元数据造成一定的压力,而且对性能也有影响。所有chunk的分配按照批量分配的原则,也就是一次性分配一批chunk。在chunk之上引入了一个segment的概念。Segment是⼀个逻辑概念,也是空间分配的基本单元。在curve中,一个curve文件会按照segment为粒度去进行空间分配。chunk外⾯包⼀层segment的好处是减少元数据量。
如下图所示,一个curve的文件由若干个segment组成,segment的大小由配置文件指定,目前curve的默认的segment的粒度为1GB,所以curve的文件大小必须是1GB的整数倍。一个segment由若干个chunk组成。
client在对空间进行读写请求之前,会先去mds查询指定offset和length的空间所在的segment的元数据信息。并把这个元数据信息缓存在client本地,以后client就可以使用缓存在本地的元数据信息对数据进行访问。segment元数据信息包含了以下的字段。

所有的⽂件在curve中都是由多个Segment组成的。每个segment的元数据记录着改segment是从哪个logicalpool分配出来,这个segment的size,组成这个segment的chunk的size,这个segment在文件中的偏移,以及这个组成这个segment的每一个chunk的信息。
Segment的持久化,Segment的编码方式:
- key:prefix(2Byte)+文件的inodeid(8Byte)+offset(8Byte);
- Value:PageFileSegment序列化后的字符串。
Segment是由多个chunk组成的,这⾥的chunk是实际的物理存储单元,对应着chunk server上的⼀个物理⽂件。chunk的元数据,包含了chunk所属的copyset id和chunkid。

每个chunk实际上由多个副本的组成的,chunk的实际的存储位置,由copyset确定。copy保存着chunk的复制组的成员关系,在copyset中,记录着chunk的3个副本实际上分布在哪些chunkserver节点上。copyeset类似于ceph中的pg。为什么不直接记录chunk的3个副本,而是通过chunk→copyset,copyset→三个副本的方式存储元数据呢?
这里简要介绍下引入copyset的好处,后期curve团队还会对copyset进行更加详细的介绍。
- 减少元数据量:⼀般来说实际物理⽂件chunk不会设置的太⼤,⼀般都是M级别的。如果直接去记录这些chunk的信息,元数据量会很⼤。引⼊copyset可以⼈为就是分组,对于chunk的信息记录就是组信息+组内信息,数据量会少很多。如果为每个Chunk去保存复制组成员关系,需要至少 ChunkID+3×NodeID=20 个byte,而如果在Chunk到复制组之间引入一个CopySet,每个Chunk可以用ChunkID+CopySetID=12个byte。
- 减少复制组数量:如果一个数据节点存在 256K个复制组,复制组的内存资源占用将会非常恐怖;复制组之间的通信将会非常复杂,例如复制组内Primary给Secondary定期发送心跳进行探活,在256K个复制组的情况下,心跳的流量将会非常大;而引入CopySet的概念之后,可以以CopySet的粒度进行探活、配置变更,降低开销。
- 提高数据可靠性:在数据复制组过度打散的情况下,在发生多个节点同时故障的情况下,数据的可靠性会受到影响。引入CopySet,可提高分布式存储系统中的数据持久性,降低数据丢失的概率。
小结
至此,这篇文章分别从拓扑信息的元数据、namespace元数据、地址空间映射元数据三个方面,介绍了curve的mds的元数据的管理,介绍了拓扑信息的组成,元数据的持久化,空间的分配等。后续curve团队还会陆续对curve其他部分进行介绍,欢迎大家持续关注。
欢迎大家来curve逛逛,https://github.com/opencurve/curve。如果大家对curve有疑问或者想参加curve的开发,欢迎给我们提issue或者pr。
curve还有一个微信群,7*24h为大家答疑解惑,可以搜索opencurve加好友,拉大家进群。
作者:陈威,网易数帆存储团队资深开发工程师,有多年存储阵列、分布式存储研发运维经验。
如有理解和描述上有疏漏或者错误的地方,欢迎共同交流;参考已经在参考文献中注明,但仍有可能有疏漏的地方,有任何侵权或者不明确的地方,欢迎指出,必定及时更正或者删除;文章供于学习交流,转载注明出处
Curve MDS技术解读视频
Curve核心组件之MDS元数据节点
技术分享预告:网易数帆 Curve 核心开发团队将带来精心准备的 新一代开源分布式存储 - Curve 技术系列公开课(直播+回放),每周五晚19:00为大家揭开 Curve 技术的奥妙及 Curve 社区的规划,本周五为 Curve Client 的主题,敬请点击左下角“阅读原文”或识别下图二维码收看!
