网易轻舟服务网格数据面性能优化实践
本文分析了服务网格数据面的性能瓶颈,并引出基于用户态协议栈的加速方案。详细介绍了VPP+VCL的用户态协议栈开源社区方案,其针对服务网格sidecar加速的优势和不足,以及网易数帆做了哪些增强,从而实现对服务网格sidecar的无侵入加速。最后介绍VPP+VCL用户态方案在加速网易轻舟云原生平台服务网格产品的落地实践,并给出实际的性能测试结果。
引子
服务网格通过引入sidecar提升了监控、流控、熔断等服务治理能力且对业务无侵入,但同时sidecar的引入在整个网络路径上也相当于增加了两个网络处理单元,从而不可避免的会引入时延。
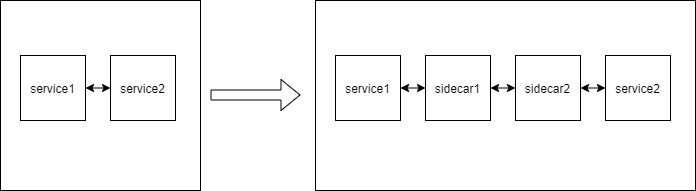
从业务方的角度来看,引入sidecar后的时延肯定是越短越好,特别是业务方微服务化后对时延敏感的业务,如内部各模块之间的服务化调用。
所以,本文中的性能如果没有特别说明,都是指时延指标。
时延分析
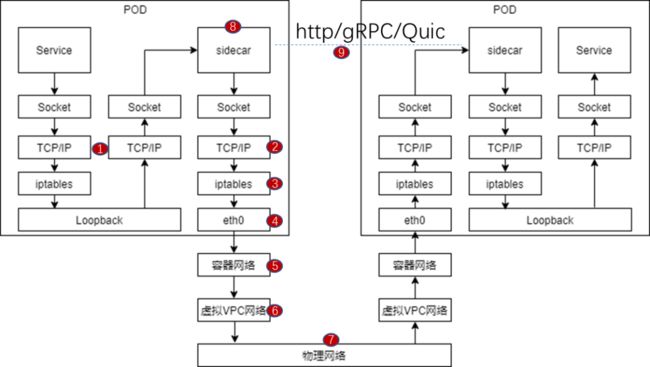
如果打开整个端到端的通信链路可以看出,sidecar引入后整个应用之间的通信链路其实是非常长的。应用发送的请求被iptables劫持后,经过内核协议栈发送给sidecar,sidecar经过处理后再通过内核协议栈发送出去,这里一般要先经过容器网络,虚拟VPC网络,再经过物理网络,之后才被接收端的sidecar收到,sidecar处理后再通过内核协议栈发送给最终的应用,整个过程要经过6次内核协议栈,而响应报文也要反向重复这一过程。但是如果去掉sidecar呢?可以看到只需要经过两次内核协议栈就可以了,相当于sidecar引入后多增加了4次内核协议栈的调用,另外还多引入了几次iptables报文处理。
总体来看,整个链路包括物理网络、虚拟网络、Guest主机网络几个部分。其中,物理网络链路(包含在图中的⑦部分)不可控,这里不做讨论。而虚拟网络链路又分为虚拟VPC网络和容器网络。下面就来逐个分析下各个阶段可能的时延优化措施。
虚拟VPC网络
先看虚拟VPC网络(包含在图中的⑥部分)。一般来说,虚拟化会带来约10%的时延开销,那么这部分开销可以省掉吗?答案是肯定的,我们可以使用裸机容器的方案,略去中间的虚拟化层。
容器网络
再看容器网络(包含在图中的⑤部分)。这部分依赖于具体的容器网络方案,比如你网桥用的是Linux bridge、OVS还是VPP,虚拟端口用的是veth还是VF,性能都会不一样。VF+用户态OVS会是一个相对成熟以及性能较好的方案。RDMA也会是一个优化方向,不过这会牵扯到业务端改造,无法做到无侵入,同时还需要综合考虑组网以及硬件成本等因素。
Guest主机网络
最后重点来看Guest主机网络(图中①②③④⑧⑨部分),Guest可能为容器,也可能为虚拟机,这里仅考虑Guest为容器的情况。
-
①是指应用和sidecar之间的通信链路。通常会使用iptables做报文劫持,再通过环回口将报文转发到sidecar,过程中会经过两次内核协议栈。这里是有一些可加速的点可以做的,比如可以借助eBPF/sockmap bypass部分内核协议栈,或者基于eBPF改写转发逻辑实现对于iptables的加速,总体来说,这块的性能有10%的提升空间。目前网易轻舟解决方案中也有相应的产品化实现;
-
⑨是应用层面的通信协议,目前有gRPC/quic协议等优化方向,不过对业务有侵入性,依赖于业务端改造;
-
⑧是sidecar自身转发逻辑,以目前业界比较流行的Envoy为例,这块本身转发逻辑的优化空间不大,在10%以内;
-
②③④即为协议栈的优化。容器分为业务容器和sidecar容器,对于计算节点,一般会运行在同一个POD内。容器中的应用依赖于socket接口进行通信,目前底层都是基于内核的TCP/IP协议栈,内核和用户态的频繁切换会带来性能开销,同时内核协议栈处理本身也会占用CPU资源。下图中以fortio测试场景看Envoy CPU占比,通过火焰图可以看出该场景下内核协议栈占比将近50%,基本上和Envoy本身转发逻辑对半分。
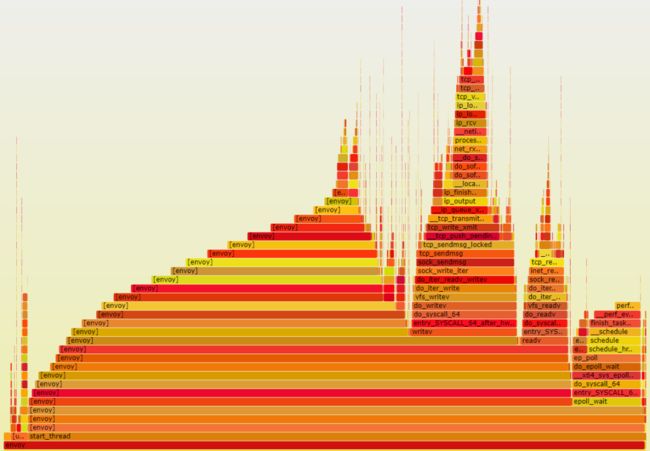
由于针对Envoy本身转发逻辑的优化提升空间不大,所以针对协议栈优化的重要性凸显。而且如果后续对于Envoy本身转发逻辑可以进一步优化,那么内核协议栈的占比会进一步提升,这样协议栈的优化的作用也会愈发明显。那么如何优化内核协议栈这块开销呢?消除内核和用户态的切换开销,以及bypass内核复杂的TCP/IP协议栈实现,是最直接有效的方法,而这就非用户态协议栈莫属了。
用户态协议栈选型
目前,社区也有不少的用户态协议栈开源实现,比如腾讯开源的F-Stack,有google参与的LKL,华为开源的DMM等,以及思科开源的VPP+VCL。那么,该如何选型呢?
首先,要考虑单位资源占用下的性价比。用户态协议栈一般依赖于DPDK将报文收发卸载到用户态,使用DPDK带来的问题是polling模式会独占CPU。这对于perhost的应用不会有问题,可以预先规划出几个核来使用。但是对于sidecar这种perpod的应用则会带来问题,一个host上几十甚至上百个POD会导致CPU资源只够给sidecar用了,真正的业务应用则无CPU可用。所以就要求用户态协议栈从架构上可以支持DPDK收发和应用的分离部署。目前测试来看,F-Stack性能最好,不过F-Stack无法支持分离部署;DMM性能依赖于底层对接用户态协议栈(如VPP/F-Stack)的性能,另外DMM虽然支持分离部署,不过DMM自己又引入了一个轮询线程,还是会独占CPU;LKL性能目前只能做到和内核态相当,且不支持分离部署;VPP+VCL可以实现分离部署,而且性能也较好。
其次,是侵入性。用户态协议栈通常会有自己的一套socket接口,无法做到和现有接口兼容,这样就会要求业务也需要修改代码来适配这套接口。有些用户态协议栈会在此基础上实现一层屏蔽层,使用PRELOAD方式来完成socket接口劫持,从而实现对业务的无侵入。目前各用户态协议栈基本上都实现了此屏蔽层。
另外,就是兼容性,或者说扩展性。内核协议栈之所以复杂,效率低,一个很重要的原因就是需要兼容不同的使用方式。举个简单的例子,有的应用是多进程的,如Nginx,而有的是多线程的,如Envoy。而用户态协议栈应该都可以支持,或者说通过简单的扩展可以支持。不过这里也有一个折中,需要在兼容性和性能方面做一个权衡。目前F-Stack对多线程还不支持,扩展起来也比较困难,所以F-Stack支持Envoy的话,首先需要将Envoy改造成多进程。
最后,就是成熟度。总体来说,开源的用户态协议栈还没有到很成熟的阶段,目前流行的开源用户态协议栈也或多或少会有些限制。比如,F-Stack相对成熟且性能较好,但是DPDK收发和应用绑定导致资源占用大;LKL兼容性好但是性能一般;VPP+VCL各方面则比较均衡且支持DPDK收发和应用的分离部署,性能介于F-Stack和LKL之间。
VPP+VCL用户态协议栈
VPP
VPP全称Vector Packet Processing,Cisco 2002年开发的商用代码。2016年2月11号,Linux基金会创建FD.io项目。Cisco将VPP代码的开源版本加入该项目,目前已成为该项目的核心。VPP具备成熟的二三层交换和路由功能,同时graph node+插件化提供了灵活的框架扩展性。
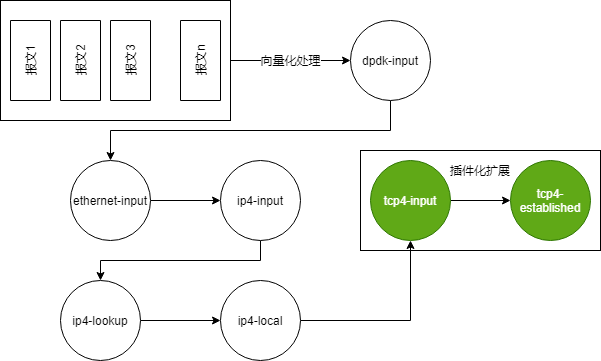
VPP平台是通过graph node串联起来形成一条datapath来处理报文,可以通过插件的形式引入新的graph node或者重新排列报文的graph node。将插件添加到插件目录中,运行程序的时候就会自动加载插件。VPP平台可以用于构建任何类型的报文处理应用,比如负载均衡、防火墙、IDS、主机栈。
通过创建插件,也可以任意扩展如下功能:
-
自定义新的graph node。
-
重新排列graph node。
-
添加底层API
VCL
VCL全称VPP Communication Library,2017年左右正式提交加入VPP工程,目的是打造一个四层的主机栈。VCL自上到下分为三层:LDP、VLS、VCL。LDP(LD_PRELOAD)层通过LD_PRELOAD机制实现对于应用的无侵入加速;VLS(VCL locked sessions)层通过引入session锁来支持session共享的场景,比如多进程(如Nginx)的accept竞争;VCL层主要负责和后端VPP的通信。
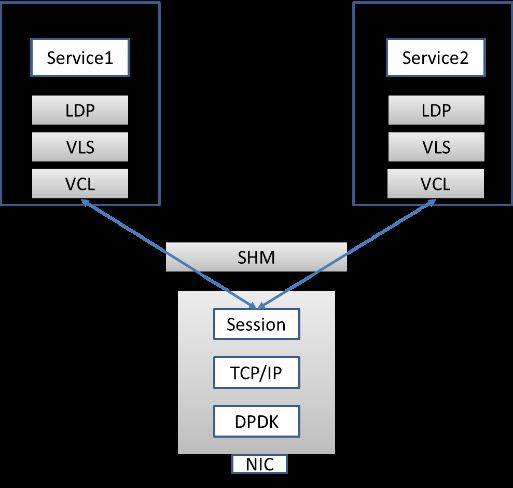
VCL和VPP支持分离部署,并通过共享内存实现高效通信。整个用户态协议栈的实现在后端VPP实现,由于前端VCL的实现功能相对简单,这样可以提高Service对CPU的利用率,从而提升性能。
性能对比测试
我们使用VF口搭建一个简单的测试环境来测试用户态协议栈相对于内核态协议栈的性能对比情况。
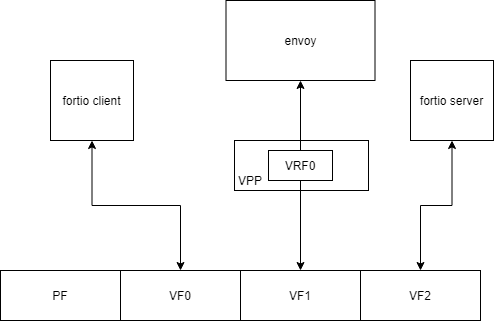
这里主要测试P90的时延情况,在64并发连接及以上,用户态协议栈相对于内核态协议栈时延可以降低30-35%。Envoy是典型的CPU密集型应用,如果消除内核态的CPU占用,让Envoy有更多的CPU可以用来处理自身的业务逻辑,则可以获得更低的时延。所以实测过程中,如果我们加上背景流量,让Envoy来不及处理报文引发报文排队,会发现用户态协议栈相对于内核态协议栈的时延降低效果更明显,在目前30-35%的基础上还会有10%的时延降低。

轻舟服务网格用户态协议栈加速落地实践
如前所属,目前用户态协议栈的开源实现不够成熟,所以在网易轻舟云原生平台服务网格组件落地过程中,还是遇到了不小的挑战。
多线程支持
轻舟服务网格支持Istio,sidecar使用Envoy。Envoy是典型的多线程架构,启动时可以配置worker数从而确定启用的工作线程数。VPP+VCL社区版本对多线程的支持仅限于dispatch+worker的线程架构,dispatch线程调用epoll_wait获取读写事件,之后通知worker线程进行报文处理。而Envoy中各个工作线程地位均等,都会独立进行epoll_wait获取读写事件以及报文处理工作。这里需要解决两大问题,一是需要各个工作线程独立向VPP进行注册成为app worker;另一个是要解决session在各个app worker间的迁移问题。目前我们针对多线程支持的相关patch已经合入社区。
CPU资源占用问题
VPP+VCL在epoll_wait接口中支持两类fd的轮询,一类是使用用户态协议栈的fd;另一类是无法使用用户态协议栈的fd,比如eventfd,unix socket,管道等,这些还是继续走内核态协议栈。Envoy中目前就会同时有这两类fd的存在。为了在一次epoll_wait里同时支持这两类fd的轮询,目前社区的做法是在应用指定的超时时间内,不停的以0作为超时时间去依次调用用户态的vls_epoll_wait和内核态的epoll_wait接口,这最终会导致即使没有报文需要处理,Envoy占用的CPU也会达到近100%,这显然是无法接受的。
这里需要针对用户态引入一个内核的eventfd让VPP通知VCL产生了事件,目前这套机制社区是有的。当然,实现的时候需要考虑eventfd本身带来的性能开销,所以不能每次有报文就通过eventfd进行通知,需要有一定的策略。然后就可以将这个eventfd所加入的epoll fd和内核态的epoll fd使用嵌套的方式统一到一起,从而让应用指定的超时时间真正生效,而不会出现CPU 100%占用的情况。目前我们相关的代码修改patch已经合入社区。
双栈支持
Envoy中对外提供HTTP接口查询状态信息,实际使用过程中从安全性角度考虑,我们会配置其监听127.0.0.1地址,这样必须管理员登录到容器中才能查询相关信息。另外为了支持healthcheck,Envoy会作为客户端通过127.0.0.1地址连接到pilot-agent。可以看到,从管控面的角度是需要Envoy支持内核态协议栈的,而数据面考虑到性能继续走用户态协议栈。目前社区版本还不支持这种双栈的情况。
其实,双栈支持的思路比较简单。应用调用socket接口的时候需要同时创建出内核态协议栈和用户态协议栈的handle,最终在bind的时候根据绑定的IP地址是否为localhost地址来确定真正使用内核态协议栈还是用户态协议栈,或者connect的时候根据目的IP地址是否为localhost地址来确定。我们针对双栈支持的相关patch目前已经提交社区。
总结
针对内核态协议栈的优化,目前有两个方向:一是使用XDP+eBPF来改写内核,通过简化实现来达到优化效果,但是优化之后的代码还是跑在内核态;另一个就是用户态协议栈,让优化后的代码完全跑在用户态。针对Envoy或者Nginx、Redis这种用户态应用的加速,用户态协议栈可以完全消除用户态和内核态的切换开销,甚至让协议栈卸载到单独的进程上处理,性能上无疑是最优的,但是技术难度和风险也最大。当然,我们也可以选择使用XDP+eBPF做局部优化,典型的如针对iptables的优化。
而且用户态协议栈对于所有用户态的应用加速其实都是适用的,而不仅仅是针对服务网格sidecar的加速。目前我们正在网易轻舟的服务网格中做相关的产品化工作,包括计算节点的sidecar,也包括API网关。后续我们也会将其扩展到通用的互联网应用的加速,如Nginx,Redis等。
作者简介
虎啸,网易数帆系统开发专家,15年软件开发经验。先后就职于华三和华为,从事过安全、视频监控、大数据和网络虚拟化等产品研发,目前在网易数帆专注于高性能网络的技术预研和产品落地工作。
百川,网易技术委员会委员,网易数帆轻舟事业部技术总监,2012 年浙江大学博士毕业后加入网易杭州研究院,负责基础设施研发/运维至今。在虚拟化、网络、容器、大规模基础设施管理以及分布式系统等技术架构有多年经验,当前主要兴趣点在云原生技术方向。
云原生技术分享预告
2020年12月16-17日,来自CNCF、VMware、PingCAP、网易数帆、阿里云等17位重磅演讲嘉宾,带来2天主题分享,立体化解析云原生前沿技术与实践。活动详情如图,名额有限,欢迎点击这里,或识别下图二维码报名。
