python基础学习笔记——完结
文章目录
-
-
-
- 一. python概述
-
- 1.1 概述
- 1.2 优缺点
- 1.3 应用场景
- 二. python解释器和集成环境的安装
-
- 2.1. 编程语言分类
- 2.2 基本环境搭建
- 2.3 集成开发环境pycharm基本配置
- 三. 基本语法
-
- 3.1 python标准开发规范
- 3.2 标准的输入输出
- 3.3 变量与常量
- 四. 数据类型
-
- 4.1. 数值
- 4.2 字符串
- 4.3 列表
- 4.4 元祖
- 4.5 字典
- 4.6 集合
- 4.7 列表、元组、字典、集合间的区别差异
- 4.8 查看数据类型type()函数
- 五. 数据类型转换
-
- 5.1类型转换表如下
- 5.2 int函数
- 5.3 float函数
- 5.4 bool函数
- 5.5 eval函数
- 六. 进制之间的转换
-
- 6.1 进制的划分
- 6.2 十进制转二进制
- 6.3 二进制转十进制
- 6.4 通过python内置方法进行转换
- 七. 运算符
-
- 7.1 算数运算符
- 7.2 混合运算符
- 7.3 比较运算符
- 7.4 逻辑运算符
- 7.5 成员运算符
- 7.6 身份运算符
- 7.7 位运算
- 八. 程序结构
-
- 8.1 if语句
- 8.2 while循环
- 8.3 循环关键字
- 8.4 for循环遍历
- 8.5 range()函数
- 九. 函数
-
- 9.1 函数的概述和意义
- 9.2 函数的声明
- 9.3 函数的调用
- 9.4函数的参数
- 9.5 函数的返回值
- 9.6 递归函数
- 9.7 函数参数类型问题
- 十. 函数进阶
-
- 10.1 命名空间
- 10.2 作用域
- 10.3 全局变量和局部变量
- 10.4 global和nonlocal
- 10.5 内置高阶函数
- 10.6 匿名函数
- 10.7 嵌套作用域和lambda
- 10.8 闭包函数
- 10.9 装饰器
- 十一. 模块
-
- 11.1 概述
- 11.2 为什么要使用模块
- 11.3 模块的命名
- 11.4 模块的引入
- 十二. 包
-
- 12.1 概述
- 12.2 包的引入
- 十三. 内置模块
-
- 13.1 random模块
- 13.2 sys模块
- 13.3 string模块
- 13.4 time模块
- 13.5 时间的操作: 三种时间的转换
- 十四. 面向对像
-
- 14.1 概述
- 14.2 术语介绍
- 14.3 类的声明
- 14.4 对象的创建
- 14.5 魔术方法
- 14.6 面向对象的三大特性
- 14.7 面相对像三大特性总结
- 14.8 类属性和实例属性
- 14.9 静态方法、类方法、实例方法
- 14.10 反射方法
- 十五. 设计模式
-
- 15.1 单例模式
- 15.2 工厂模式
- 十六. 文件操作
-
- 16.1 文件分类
- 16.2 文件读写
- 十七. os模块
-
- 17.1 os常见方法
- 17.2 os.path 方法
- 17.3 os 其他方法
- 十八. 异常处理
-
- 18.1 程序异常
- 18.2 触发异常
- 十九. 多任务
-
- 19.1 概述
- 19.2 同步和异步
- 19.3 操作系统实现多任务:
- 19.4 python实现多任务
- 二十.进程和线程
-
- 20.1 进程
- 20.2 线程
- 20.3 使用场景
- 二十一. 多线程创建
-
- 21.1 使用threading 模块创建线程
- 21.2给线程传递参数
- 21.3 使用继承方式创建线程
- 21.4 实例方法
- 24.5 等待线程 join()
- 21.6 守护线程 setDaemon()
- 21.7 threading 模块提供的方法
- 21.8 线程会共享全局变量
- 21.9 互斥锁
- 21.10 死锁
- 21.11 生产者与消费者模式
- 21.12 threasLocal
- 21.13 pythonGIL锁
- 二十二. re模块
-
- 22.1 python中操作正则表达式
- 22.2 正则表达式元字符
- 22.3 正则表达式分组
- 22.4 贪婪模式和非贪婪模式
- 二十三. 迭代器
- 二十四. 生成器
- 二十五. unittest
- 二十六. python2 vs python3
-
- 26.1 print
- 26.2 range与xrange
- 26.3 字符串
- 26.4 异常处理
- 26.5 打开文件
- 26.6 标准输入
- 26.7 除法运算
- 26.8 自定义类
- 二十七. linux
-
- 27.1 概述
- 27.2 发展历史
- 27.3 系统特性
- 27.4 系统目录
- 27.4 命令操作
- 27.5 计划任务
- 二十八. Vim编辑器
-
- 28.1 模式切换
- 二十九. 网络和防火墙配置
-
- 29.1 网络配置
- 29.2 防火墙设置
- 三十. ssh服务
-
- 30.1 概述
- 30.2 常用命令
- 30.3 免密码登录
- 三十一. shell脚本
-
- 31.1 shell脚本的基本语法
- 31.2 第一个脚本程序
- 31.3 变量
- 31.4 程序控制结构
- 31.5 文件判断
- 31.6 字符串判断
- 31.7 数值比较
- 31.8 逻辑判断
- 31.9 case 分支语句
- 31.10 循环语句
- 31.11 数字运算
- 31.12 数组
- 31.13 shell函数
- 31.14 案例
- 三十二. git版本控制器
-
- 32.1 概述
- 32.2 git的工作流程
- 32.3 创建远程创库
- 32.4 连接远程仓库
- 32.5 版本管理
- 32.6 分支管理
- 32.7 本地仓库关联远程创库
- 三十三. mysql数据库
-
- 33.1 数据库概述
- 33.2 数据库专业术语
- 33.3 数据库分类
- 33.4 数据库的安装
- 33.5 数据库操作
- 33.6 数据类型
- 33.7 约束
- 33.8 数据的增删改查
- 33.9 表关系
- 33.10 多表查询
- 33.11 事务
- 33.12 索引
- 33.13 视图
- 33.14 触发器
- 33.15 用户权限管理
- 33.16.存储过程
- 三十四. python连接数据库
-
- 34.1 安装第三方模块pymysql
- 34.2. 连接数据步骤
-
-
一. python概述
1.1 概述
- 1989年圣诞节, 创始人 吉多.范罗苏姆,俗称"龟叔", 开始开发python
- 1991年第一个python解释器诞生
- python是ABC语言的一种继承
- python是一种高级语言,同事也是一门弱语言,程序员可以花更多的时间用于思考程序逻辑,而不是具体的细节
1.2 优缺点
- 优点
- 简单易学
- 相对于其他语言,基础语法简单
- 开发效率高
- python有大量的第三方库
- 跨平台
- python程序可移植到windows, linux, Mac等平台上运行
- 可扩展性
- python可以使用C语言进行功能拓展
- 简单易学
- 缺点
- 代码无法加密
- 运行效率低(相对而言)
1.3 应用场景
- 服务器操作系统的自动化运维
- Web应用开发
- 网络爬虫
- 数据分析
- 人工智能
二. python解释器和集成环境的安装
2.1. 编程语言分类
- 解释型语言,例如:python
- 运行效率较低
- 编译型语言, 例如: C
- 执行效率非常高,但是不能跨平台
2.2 基本环境搭建
-
python解释器:运行python代码的软件,主要目的就是将python代码翻译计算机硬件可以直接运行的二进制数据
-
python解释器类型
- Cpython: 底层有C语言开发,官方维护,可以和C语言嵌入开发
- Jpython: 底层由java语言开发,可以和java语言混合开发
- Pypy: 将python解释性特性,转换成编译解释运行的特性
- Ipython: 优化了解释器方案,提升为一种简单的编辑工具
-
解释器下载与安装
-
从官网下载: www.python.org
-
双击.exe文件
-
自定义安装
-
测试是否安装成功
-
在命令行输入: python, 出现下图表示安装成功
-

-
如果出现以下情况,检查python解释器是否加入环境变量中

-
-
-
集成环境Anaconda搭建
- Anaconda集成环境中包含了大量的第三方模块,在数据分析中不需要手动安装大量的模块和包
- 下载网址: https://repo.anaconda.com/archive/


2.3 集成开发环境pycharm基本配置
- 配置python解释器
- 字体调整
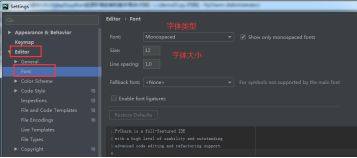
- 开启: ctrl+鼠标波轮调整字体大小






三. 基本语法
3.1 python标准开发规范
-
文件命名规范
- python程序的后缀名 .py
- 文件名使用英文或拼音,最好使用英文
-
注释
-
多行注释: “”“注释内容”""
- 每一个文件最开始都要添加文档注释内容,描述其功能和作用
-
单行注释: #
- 只给重要的代码添加注释
-
3.2 标准的输入输出
-
标准输出
-
print("输出内容") # 默认换行输出 print("输出内容") # 不换行输出 print('数据1','数据2') # 一次输出多个数据
-
-
标准输入
-
input("提示内容") # 从键盘输入一个信息到程序中
-
3.3 变量与常量
- 变量: 临时存储数据的容器
- 变量的赋值: 变量名=值
- 变量的修改: 变量名=新的值
- 删除变量: del 变量名, 变量名=None
- 变量的命名:
- 由字母数字和下划线组成, 不能以数字开头
- 不能使用系统的保留关键字
- 多个单词使用下划线分隔
- 常量:在项目开发中有些特殊的数据,在开始定义后,后面操作时不做修改,这种变量我们把它叫做常量,在python中语法上没有对应的要求说,变量中的值不能修改
- 常量命名: 全部使用大写
四. 数据类型
4.1. 数值
- 整形
- 浮点型
- 布尔型
- 复数
4.2 字符串
-
定义
- 只要是使用单引号/双引号/三引号包裹起来的数据都是字符串
-
性质
- 字符串一旦创建,在内存中就无法在进行修改了,如果需要修改实质上是在内存中重新分配空间重存储新的字符串.
- 有索引
- 和列表一样有切片
- 拼接使用 : +
- 重复使用: 字符串*数值
-
内置方法
- center 居中
- ljust 左对齐
- rjust 右对齐
- strip 去除字符串两边的空格
- lstrip 去字符串左边空格除
- rstrip 去除字符串右边的空格
- upper 将小写字母全部转换为大写字母
- lower 将大写字母全部转换为小写
- capitalize 首字母大写
- title 单词首字母大写
- expandtabs() 把字符串中的 tab 符号(’\t’)转为空格,tab 符号(’\t’)默认的空格数是
- find 从左往右查找字符串,返回其索引,无结果时返回-1
- rfind 从右往左查找字符串,返回其索引
- index 查找字符串,返回其索引,无结果时报错
- rindex() 从右往左查找,返回其索引,无结果时报错
- count 统计字符出现的个数
- replace(old, new, count=-1) 替换字符串中的字符,默认全部替换
- translate() 按照对应关系来替换内容 需要使用maketrans生成映射表
- split 切割字符串,从左往右,默认切割全部,也可指定切割次数
- rsplit 切割字符串,从右往左,默认切割全部,也可指定切割次数
- splitlines 按行切割字符串
- partition() 分割字符串,带有分割字符
- join 字符串的拼接
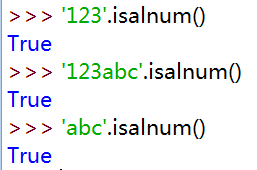
- isalnum 判断字符串是否完全由字母或数字组成
- isalpha 判断字符串是否完全由字母组成
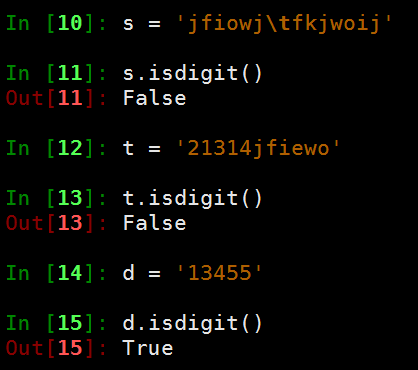
- isdigit 判断字符串是否完全由数字组成
- isupper判断是否全是大写
- islower 判断是否全部小些
- istitle 判断字符串是否满足title格式
- isspace 判断字符串是否完全由空格组成
- startswith判断是否以开始,可以指定范围
- endswith判断是否以结束,可以指定范围
- center 居中
-
字符串编码
-
*方法** *描述* code(编码方式) 编码,将字符串转换成字节码 code(解码方式) 解码,将字符串转换成字符串 -
在计算机中所有的信息最终都表示为一个二进制的字符串
-
在计算机种中,1 字节对应 8 位二进制数
-
1 字节可以组合出 256 种状态
-
256 中状态每一个都对应一个符号,就能表示 256 个字符
-
美国人制定了一套编码,用于描述英语中的字符和这 8 位二进制数的对应关系,这被称为 ASCII 码。
-
ASCII 码一共定义了 128 个字符
-
128 个字符只使用了 8 位二进制数中的后面 7 位,最前面的一位统一规定为 0
-
-
万国码Unicode:规定了世界上所有的字符都对应一个唯一的编号
-
UTF-8编码:对Unicode的具体实现,UTF-8规定了字符在电脑上的保存形式
-
可变长 可以使用 1 - 4 个字节表示一个字符 根据字符的不同变换长度
-
英文占1个字节,中文占3个字节。
-
UTF-8兼容ASCII码
-
-
-
转义字符
-
*转义符号** *意义* 产生一个反斜杠符号() 产生一个单引号(‘) 产生一个双引号(“) 表示换行 横向制表符 ewline 连续(当一行代码太长换行是使用) ther 其他字符不转义,保留原有字符
-



























4.3 列表
-
概述
- 列表是组合数据类型中的一种,用list关键字来表示
- 列表中元素可以重复 可以是不同类型的数据
-
格式
- 变量 = []
- 变量 = list()
-
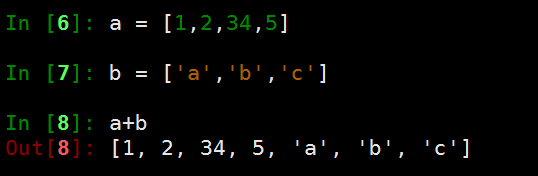
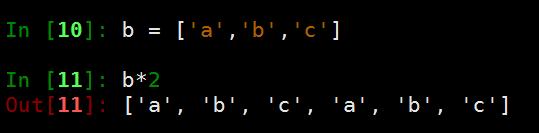
列表的序列操作
- 列表相加
- 列表与数相乘
- 列表的索引
- 从左往右 索引值 从 0 开始依次递增
- 从右往左索引值从 -1开始依次递减
- 列表的切片
- 格式: 变量名[start: end : step]
- start: 开始的索引位置
- end: 结束位置 可以省略不写 不写代表取到最后
- step: 步长 默认是1 可以省略

- 列表的遍历
- 列表解包
- 列表相加
-
列表的内置方法
-
dir(list) 查看列表的所有内置方法
-
help(list.方法名) 查看该方法的帮助文档
-
增加操作
- append() 追加,在列表的尾部加入指定的元素
- extend() 将指定序列的元素依次追加到列表的尾部(合并),不会去重复内容
- insert(index , data) 将指定的元素插入到对应的索引位上,注意负索引倒序插入,超过索引就会在末尾插入
- append() 追加,在列表的尾部加入指定的元素
-
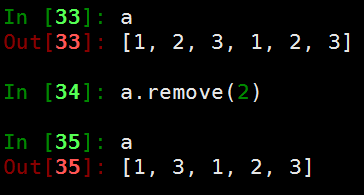
删除操作
- pop([index]) 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
- remove(data) 函数用于移除列表中某个值的第一个匹配项。没有返回值
- clear() 该方法用于清空列表
- pop([index]) 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
-
查找操作
- count() 计数,返回要计数的元素在列表当中的个数
- index(data[,start,end]) 函数用于从列表中找出某个值第一个匹配项的索引位置, 可以指定查询范围
- len() python的内置方法,获取列表内元素的个数
-
排序
- reverse() 顺序倒序
- sort(key,reverse=False)
- 如果是字符串则按照ASCII码表顺序进行排序
- key=函数 通过这个函数指定排序规则
- reverse=True 降序排序, 默认升序

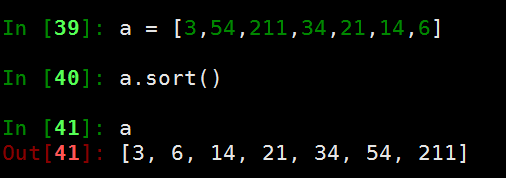
- sorted()
- python内置的函数功能和sort类似
- 区别在于: sorted 会返回一个新的排序后的列表, sort: 在原列表上做修改

- reverse() 顺序倒序
-
深拷贝与浅拷贝
- 浅拷贝
- 深拷贝
- 浅拷贝
-
列表推导式
-
变量名=[表达式 for 变量 in 列表] 或者 变量名= [表达式 for 变量 in 列表 if 条件] -

-
-










4.4 元祖
- 定义与性质
- tuple() ,元素和元素之间使用,号隔开
- 不可变的,可以存储有序的,不同类型的,可以重复的 序列数据类型.
- 使用for循环进行遍历
- 同列表一样可以进行切片操作
- 拼接和重复解包,也同列表一样
- 内置方法
- count() 返回元组当中指定元素的个数
- index() 从左往右返回第一个遇到的指定元素的索引,如果没有,报错
- enumerate()内置函数一般配合循环遍历使用

4.5 字典
-
定义与性质
-
使用{}包裹,一个key对应一个value,key和value之间使用:,一对kev,value就是一个数据,数据和数据之间使用逗号隔开.
-
格式: {key:value,key:value}
-
字典是项目开发过程中使用频率最高的一个组合数据类型。它用于存放具有映射关系的数据.
-
使用 dict()创建空字典,dict创建字典的三种方式
-
dict({key:value}) dict([(key,value),(key,value)]) dict(key=value,key=value)
-
-
字典的key:只能是不可变类型
-
字典中的值可以重复,但是key是不能重复的
-
-
字典的操作方法
-
setdefault(key,default_value) 指定key和value,如果key存在什么都不改变
-
pop(key) 弹出,返回并删除指定键对应的值
-
popitem() 随机弹出一个键值对
-
clear() 清空字典
-
del 删除整个字典,或者通过字典的key删除对应键值对;Python内置方法,不是字典独有的方法;
-
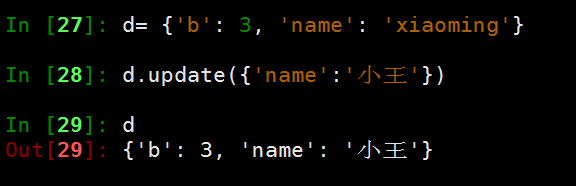
update({key:value}) 传递一个字典,如果key相同则覆盖,没有的key则添加
-
get(key, default) 以键取值,如果指定键不存在,默认返回None,可以指定返回内容
-
key 通过指定的key找对应的值 dict[‘key’]
-
keys() 以列表返回一个字典所有的键
-
values() 以列表返回字典中的所有值
-
items() 返回字典键值呈元组形式的格式
-
通过key获取数据和get获取数据的区别:如果key不存在,使用key获取会报错,使用get 不会报错 默认返回None 可以设置默认的返回值
-





4.6 集合
-
集合的声明格式
- 变量名={元素1,元素2,元素3,…}
- 变量名=set(序列)
-
性质
- 集合是盛放多个数据的一种类型
- 集合中的数据是无序,是不能重复的.
-
内置方法
- add()
- 添加一个数据
- update({})
- 添加多个数据
- pop()
- 随机返回并删除一个数据
- remove()
- 删除指定的数据
- clear()
- 清空
- del
- 删除整个集合


- add()
-
双集合操作
-
交集(& 或者 intersection) 取公共部分
-
并集 (| 或者 union) 取去除重复部分内容
-
差集 (- 或者 difference)取set1或者set2中除去公共部分的内容
-
反交集 (^ 或者 symmetric_difference)
-
子集 (< 或者 issubset)
-
超集 (> 或者 issuperset)

-
4.7 列表、元组、字典、集合间的区别差异
-
列表: 数据量过大时不建议使用列表存储数据,取数据效率会比较低,推荐使用字典
-
格式:[] ,list
-
有序的,可以修改的,可以重复的,可以是不同类型
-
-
元组:
-
格式:(),tuple()
-
有序的,不可以修改,可以重复,可以是不同类型的数据
-
-
集合:
-
格式: set() ,set
-
无序,无法修改集合中的某一个元素,里面的数据是不重复,可以存不同类型的数据
-
-
字典:
-
格式:{},dict
-
key-value形式,无序, key不能重复,value可以重复,value可以是不同类型的,key必须是不可变类型的数据
-
4.8 查看数据类型type()函数
-
type(1) type("见覅额及")
五. 数据类型转换
5.1类型转换表如下
| 函数 | 说明 |
|---|---|
| int(x) | 将x转换成 整型 |
| float(x) | 将x转换成 浮点型 |
| bool(x) | 将x转换成 布尔类型 |
| str(x) | 将x转换成 字符串类型 |
| chr() | 将一个整数按照utf-8编码表,转换成一个字符 |
| eval() | 计算字符串中有效的python表达式 |
5.2 int函数
-
bool转int
-
int(False) # 结果是: 0 int(True) # 结果是: 1
-
-
float转int,直接将小数点后面的数删除
-
int(1.23) # 结果是: 1
-
5.3 float函数
-
bool转float
-
float(True) # 结果是: 1.0 float(Flse) # 结果是: 0.0
-
-
int转float
-
float(1) # 结果是: 1.0 float(30) # 结果是: 30.0
-
-
str转float,只能转纯整数型或纯浮点数值型字符串
-
float('123') # 结果是: 123.0 float("1.3") # 结果是: 1.3 float("积分") # 报错
-
5.4 bool函数
- int转bool
- 0为Flase,其他全为True
- float转bool
- 0.0为Flase, 其他全为True
- str转bool
- 空字符串为Flase,其他全为True
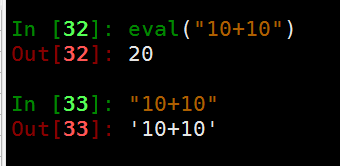
5.5 eval函数
- 将字符串类型的数值表达式,当做数值表达式正常执行
六. 进制之间的转换
6.1 进制的划分
- 十进制,以十为基数,0-9,
- 十六进制,以16为基数, 0-9a-f, 0x开头,不区分大小写
- 八进制,以8为基数,0-7,0o开头,不区分大小写
- 二进制,以2为基数,0-1,0b开头,不区分大小写
6.2 十进制转二进制
- 十进制数除 2 取余法,直到商为0
- 将余数从后往前排列,即得到该十进制的二进制表示
6.3 二进制转十进制
-
把二进制数按权展开、相加即得十进制数
-
例如: 1010计算方式
1 ∗ 2 3 + 0 ∗ 2 2 + 1 ∗ 2 1 + 0 ∗ 2 0 1*2^3+0*2^2+1*2^1+0*2^0 1∗23+0∗22+1∗21+0∗20
6.4 通过python内置方法进行转换
| 函数 | 说明 |
|---|---|
| hex(int) | 将10进制转换成 16进制 |
| oct(int) | 将10进制转换成 8进制 |
| bin(int) | 将10进制转换成 2进制 |
| int(str,指定的进制) | 将指定进制的字符串转换成 十进制数据 |
七. 运算符
7.1 算数运算符
-
操作符号 描述 + 加法运算符当两边都是数值时我们做加法运算如果两边都是字符串,做字符串拼接 - 减法运算符 * 乘法运算符两边都是数值做乘法运算粮油一遍是字符串,做字符串的复制 / 除法运算符 % 取模数运算符 // 整除运算符(不会四舍五入) ** 幂运算符,求指数运算 -
数值类型的混合运算中,类型自动升级: 会现将被操作的对象(数值)转换成,复杂度高的操作对象(数值),然后做运算 ,最终结果是,复杂度高的这个类型
-
复杂度优先级: bool
7.2 混合运算符
-
操作符号 描述 += 自加运算,加法运算的优化版本 -= 同上 *= 同上 /= 同上 %= 同上 //= 同上 **= 同上
7.3 比较运算符
-
操作符号 描述 > 判断符号左侧的数据是否大于右侧的数据 >= 判断符号左侧的数据是否大于等于右侧数据 < 判断符号左侧的数据是否小于右侧的数据 <= 判断符号左侧的数据是否小于等于右侧数据 == 判断符号两侧的数据是否相等 != 判断符号两侧的数据是否不相等 -
比较运算符:数据等值比较,返回****布尔类型****的结果
7.4 逻辑运算符
| 操作符号 | 描述 |
| -------- | ---------------------------------------- |
| and | 符号两边的条件都为真(True),结果为True |
| or | 符号两边的条件都为假(False),结果为False |
| not | 符号右侧的条件,取反 |
| and | 两边为真则为真 | 其他都为假 |
| ---- | -------------- | ------------ |
| or | 两边都为假则假 | 其他都是真 |
| not | 为真结果为假 | 为假结果为真 |
-
优先级:or
-
可通过加()提升优先级
-
and: 如果第一个值为假 则直接输出假的值
-
1 and 2 —> 2
-
1 and 0 ---->0
-
0 and 1 ---->0
-
-
or: 两边有一个为真则为真,如果第一个值为真值,直接返回第一个值
-
0 or 1 —> 1
-
1 or 3 —> 1
-
7.5 成员运算符
- in 判断某一个数据是否属于另一个数据, 返回bool类型
- not in 与上面相反
7.6 身份运算符
- is 判断两个数据是否属于同一个数据, 返回bool类型
7.7 位运算
- 左移: <<
- 将数据转换成二进制向左移动一位,然后在转换成原来的进制显示出来
- 2<<1 表示2左移一位,结果是4
- 右移: >>
- 将数据转换成二进制向右移动一位,然后在转换成原来的进制显示出来
- 2>>1 表示2右移一位,结果是1
八. 程序结构
8.1 if语句
-
单分支
-
if 条件表达式: # 只有条件表达式成立才会执行程序体 程序体 -
条件表达式后面一定要加 ==:==号分支内的代码段必须使用 缩进
-
-
双分支
-
if 条件表达式: 真区间代码段 else: 假区间代码段 -
条件表达式为真 执行真区间代码, 当条件表达式不成立 执行假区间代码段
-
-
多分支
-
if 条件表达式1: 代码段1 elif 条件表达式2: 代码段2 elif 条件3: 代码段3 else: else代码段 -
判断第一个条件是否成立,如果成立则执行代码段1
-
如果不成立,继续判断第二个条件,如果第二个条件成立,执行代码段2,如果不成立继续向下面的条件进行判断
-
如果条件都不成立,执行else中的代码
-
else可以省略不写
-
-
嵌套分支, 分支当中嵌套分支
-
if 条件表达式1: if 条件表达式2: 代码段2 else: else 区间代码
-
-
三元表达式
-
格式: 变量 = 条件为真返回的结果 if 判断条件 else 条件为假返回的结果
-
result = "合格" if s >= 60 else "不合格"
-
8.2 while循环
-
格式
-
while 条件表达式: 循环的代码段 -
判断条件表达式是否成立,成立我们执行循环体中的代码,执行完之后不会结束,而是再次进行条件判断,如果成功继续执行循环体,当条件不成立时,循环就不在执行了
-
-
死循环
-
while True: 循环体代码 -
条件一直为真的循环,死循环,永真循环,一般情况配合break来去终止循序
-
-
循环嵌套
-
while 条件表达式: while 条件表达式: 代码段 -
外层循环一次,内存循环需要循环结束,才能能会外层循环
-
8.3 循环关键字
- break
- 在循环中,强制结束整个循环,循环内break后面的代码不在执行
- continue
- 终止本次循环,直接进入下一次循环,continue后面的代码不在执行
8.4 for循环遍历
-
for循环与while循环的区别
- for循环主要适用于对有序的数据进行遍历
- while 循环 根据指定的条件重复执行指定的代码
-
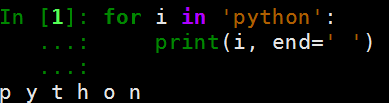
for循环代码格式
-
for 临时变量 in 一串数据: 代码段 -
for循环的循环次数是由 数据的个数来决定的,每循环一次,将这个一串数据中的,一个个数据拿出来赋值给临时变量,在循环内可以通过临时变量操作 这个被遍历出来的数据
-
例如:
-
-
8.5 range()函数
- range函数可以帮助我们生成一个指定范围内容的数列
- 格式 range(start, end, step)
- start: 开始的位置,可以省略不写, 默认从0开始
- end: 结束的位置, 不包含end
- step: 步长值, 默认值1 可以省略不写
九. 函数
9.1 函数的概述和意义
- 函数
- 一段具有特定功能的代码段
- 可以重复调用,不调用不执行
- 可更好的提升代码的复用性
9.2 函数的声明
-
def 函数名([形参]): “””注释说明””” 函数中的代码 [return] # 可有可无
9.3 函数的调用
-
函数名([实参]) -

-
函数必须先声明再调用
-
函数之间可以相互调用
9.4函数的参数
-
形参: 定义函数时,在()中传入的
-
实参: 调用函数时,在()中写入的
-
实参和形参位置一一对应
-
格式
-
def 函数名(参数1, 参数2) 代码块 函数名(数据1, 数据2) -

-
关键字参数
- 通过形参名=实参这种格式传递参数,不受形参位置的影响,根据关键词给指定的形参传递参数

-
默认值参数
- 在声明函数时, 给形参设置默认的值

-
可变参数(*args, **kwargs)
- *args: 元组参数(非关键字收集参数)
- 调用函数时,将传递的多余的位置参数进行收集,收集到args参数中,是元组类型

- **kwargs:字典参数(关键字收集参数)
- 将多余的关键字参数,使用**kwargs参数以字典形式进行收集

- 参数顺序" : 位置参数,元组参数,关键字参数,默认值参数,字典参数
- *args: 元组参数(非关键字收集参数)
9.5 函数的返回值
- 使用return返回函数的结果
- 没有返回值的函数,默认返回的是None
- return 可以跟多个值, 返回的是一个元组
- return也可以结束函数
9.6 递归函数
-
函数自己调用自己,我们称之为递归函数
-
递归函数必须留有出口, 不然会报错
-
递归的层级 最大996
-
递归函数的原理: 利用压栈操作
-
缺点: 消耗内存, 效率比较低
-
优点: 逻辑直观
-
例如: 计算100之内的和
def sum_num(num=100): if num == 0: return 0 return num+sum_num(num-1)
9.7 函数参数类型问题
-
给函数传递不可变类型的参数,函数内部修改数据,对函数外部的变量没有影响

-
可变类型, 影响其值

十. 函数进阶
10.1 命名空间
-
概述
- 命名空间指的是保存程序中的变量名和值的地方.本质上是一个字典,字典的key就是变量名,value就是变量对应的数据.
- 局部命名空间: 函数内部
- 全局命名空间, python文件中
- 内置命名空间: python解释器层面, builitins, python各个系统层级
-
访问命名空间
- 局部命名空间使用locals()函数来访问
- 全局命名空间的访问使用 globals() 函数访问
-
命名空间加载顺序
- 内置命名空间–>全局命名空间–>局部命名空间
-
命名空间的查找顺序
- 使用某个变量时, 先从局部命名空间查找, 如果找到了就停止搜索,如果没有找到,去全局命名空间查找,找到了停止,如果没有找到,去内置命名空间去查找,如果没找到就报错
10.2 作用域
-
概述
-
作用域指的是变量在程序中的可应用范围
-
作用域按照变量的定义位置可以划分为四类即:L, E, G, B
-
Local( 函数内部 ) 局部作用域
-
Enclosing(嵌套函数的外层函数内部)嵌套作用域
-
Global(模块全局)全局作用域
-
Built-in(内建)内建作用域

-
-
-
内层作用域访问外层作用域的顺序
-
L–>E–>G–>B
-
*内层作用中可以访问,外层作用域当中数据*
*在外层作用域中,不能访问内层作用域中的数据*
-
-
在 Python 中,模块(module),类(class)、函数(def、lambda)会产生新的作用域
条件判断(if……else)、循环语句(for x in data)、异常捕捉不会产生作用域
在分支,循环,异常处理中声明的变量,作为范围是属于当前作用域的
-
10.3 全局变量和局部变量
- 在函数中定义的变量称为局部变量, 只在函数内部生效
- 在程序一开始的定义的变量称为全局变量,全局变量的作用域是整个函数
- 当全局变量是不可变数据类型,函数无法修改全局变量的值, 强制修改会报错
- 在局部变量中可以访问全局变量
- 当全局变量是可变数据类型,函数可以修改全局变量,修改后,全局变量中的数据会受影响
10.4 global和nonlocal
-
global可以将局部变量变成一个全局变量

-
nonlocal关键字可以在内函数中修改外层(非全局)变量

10.5 内置高阶函数

-
abs() 绝对值函数
-
max() 最大值函数
-
max(iterable, key, default) 求迭代器的最大值
-
其中 iterable 为迭代器,max 会 for i in … 遍历一遍这个迭代器
-
然后将迭代器的每一个返回值当做参数传给 key=func 中的 func
-
然后将 func 的执行结果传给 key,然后以 key 为标准进行大小的判断

-
-
map() 映射函数
-
有两个参数,第一个参数是一个函数,第二个参数是可迭代的内容
-
函数会依次作用在可迭代内容的每一个元素上进行计算,然后返回一个新的可迭代内容
-
例如: 将列表lst1 = [1,2,3] 的每个值都乘以2

-
-
filter() 过滤函数
-
用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表
-
该函数接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断 , 然后返回 True 或 False,最后将返回 True 的元素放到新列表中
-
例如: 将列表lst=[1,2,3,4,5,6,7,8,0] 过滤出所有的偶数
In [24]: lst=[1,2,3,4,5,6,7,8,0] In [25]: def fun(item): ...: if item%2 == 0: ...: return True ...: In [26]: filter(fun,lst) Out[26]:In [27]: list(filter(fun, lst)) Out[27]: [2, 4, 6, 8, 0]
-
-
zip() 函数
-
接受任意多个可迭代对象作为参数 , 将对象中对应的元素打包成一个 tuple
-
返回一个可迭代的 zip 对象 . 这个可迭代对象可以使用循环的方式列出其元素
-
若多个可迭代对象的长度不一致 , 则所返回的列表与长度最短的可迭代对象相同
-
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ey5GOWZI-1598969697157)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20200819194514705.png)]
-
案例: 通过t1=(“a”,”b”),t2=(“c”,”d”) 生成[{“a”:”c”},{“b”:”d”}]
t1 = ("a","b") t2 = ("c","d") res = list(zip(t1,t2)) def fun(item): d = dict() d[item[0]] = item[1] return d print(list(map(fun,res)))
-

10.6 匿名函数
-
匿名函数的定义使用lambda
-
本质为一个函数,没有名字的函数,针对简单函数提供的一种简洁的操作语法
-
语法格式
-
变量 = lambda [参数1,参数2…] : 表达式
-
参数:可选,通常以逗号分隔的变量表达式形式,也就是位置参数
-
注意 : 表达式中不能包含 循环,return , 可以包含 if…else… 语句(三元表达式)
-
表达式计算的结果直接返回
-
匿名函数用处: 一般配合高阶函数使用
-
优点: 代码简洁,
-
缺点: 可读性差难于理解, 不推荐使用
-
案例: 使用filter函数过滤所有的奇数 lst = [1,2,3,4,5,6,7,8,9,10]
-
In [8]: list(filter(lambda x : x%2==0, lst)) Out[8]: [2, 4, 6, 8, 10]
-
-
10.7 嵌套作用域和lambda
-
lambda 表达式也会产生一个新的局部作用域。在 def 定义的函数中嵌套 labmbda 表达式能够看到所有 def 定义的函数中可用的变量
-
# 例1 def make_actions(): acts = [] for i in range(5): acts.append(lambda x: i ** x) return acts funcs = make_actions() print(funcs[0](2)) # 16 print(funcs[1](2)) # 16 print(funcs[2](2)) # 16 # 例2 def make_actions(): acts = [] for i in range(5): acts.append(lambda x, y=1: i ** x) return acts funcs = make_actions() print(funcs[0](2)) # 0 print(funcs[1](2)) # 1 print(funcs[2](2)) # 4
-
10.8 闭包函数
-
概述
- 闭包函数本质就是函数
- 在函数外面是无法访问函数内部数据的,通过闭包函数在函数外面访问函数内部的数据
- 使用闭包有风险,占用内存,可能会导致内存溢出,闭包在使用中将函数内部的局部变量永久保存在内存中.
-
闭包函数的必要条件
- 函数的嵌套定义
- 内部函数使用外部函数的变量
- 外部函数必须有返回值, 返回内部函数名
-
闭包函数的执行
def fun(): name = "liming" def inner(): print(name) age = 12 return name, age return inner if __name__ == '__main__': # 调用外层函数 fun , 把内层函数inner返回给inner_function变量 # inner只是赋值给了inner_function, 没有被调用 # 注意此时name依然存在,没有被释放, 因为内层函数引用了name的值, # 且内层函数赋值给了全局变量inner_function inner_function = fun() # 相当于 inner_function = inner # 调用内层函数inner print(inner_function()) # 相当于 inner() -
闭包的作用
- 让函数内部的局部变量, 在函数执行完成后, 让外部能够操作这个变量, 延长了函数内部变量的生命周期
-
应用场景:
-
在项目开发中可以使用闭包函数,对程序进行扩展
-
例如: 检测某个函数的执行时间
import time def execution_time(func): def inner(): start_time = time.time() func() end_time = time.time() print(f'函数执行共用时{end_time-start_time}') return inner def program(): print("这是个一程序") time.sleep(2) print("执行结束") if __name__ == '__main__': # 调用闭包的外层函数,传入要检测的函数, 将内层函数inner返回给inner_function inner_function = execution_time(program) # 调用inner_function, 即inner函数 inner_function()
-
10.9 装饰器
-
概述
- 装饰器函数本质就是一个闭包, 也是一个函数
- 装饰器有其固定的语法格式
-
作用
- 在不修改原函数及其调用方式的情况下对原函数功能进行拓展
-
格式
-
@装饰器名称
被装饰的函数
-
def outer(func): def inner(*args, **kwargs): # 被装饰函数之前执行的代码 ret = func(*args, **kwargs) # 被装饰的函数 # 被装饰函数之后执行的代码 return ret return inner @outer def function(*args, **kwargs): pass
-
-
案例1: 修改年龄(带参数的装饰器)
def outer(fun): def inner(name, age): print(f"修改前的年龄{age}") age -= 2 fun(name, age) return inner @outer # 相当于 change_age = outer(change_age) 即把inner赋值给change_age def change_age(name, age): print(f"我是{name}, 今年{age}岁") if __name__ == '__main__': change_age("李明", 20) -
案例2: 测试程序执行时间( 带返回值的装饰器)
import time def outer(func): def inner(*args, **kwargs): start_time = time.time() ret = func(*args, **kwargs) # 被装饰的函数 end_time = time.time() print(f'函数执行共用时{end_time-start_time}') return ret return inner @outer def function(): print("这是个一程序") time.sleep(2) print("执行结束") return "ok" if __name__ == '__main__': ret = function() print(ret)
十一. 模块
11.1 概述
- 模块就是包含了一定功能的python文件
- 每个 Python 文件都是一个独立的模块
11.2 为什么要使用模块
- 我们会根据不同的功能,将代码放在不同的文件中
- 提高代码的可复用性
- 多个文件,每个文件独立功能,代码量相对较少,可读性提高
11.3 模块的命名
- 根据软件中不同的功能将代码拆分出来,并根据功能命名, pep8规则
- 不要使用中文,不要和系统模块名冲突
11.4 模块的引入
-
绝对引入
-
当引入一个模块时,python解析器对模块位置的搜索顺序是
- 当前目录
- 如果不在当前目录,python则搜索在shell变量pythonPATH下的每个目录
-
我们导入的范围也可以通过修改sys.path这个列表获得暂时的修改。例如通过 sys.path.append()添加目录,导入额外目录的模块。
-
列表是有序的,当搜索的过程当中,在第一个路径下搜索到了,就停止搜索。而且sys.path第一个路 径是脚本的当前路径,所以禁止大家讲自己的脚本命名成模块的名称。因此需要注意的是:自己模块命名的时候不能和系统的模块名称相同
-
基本引入方式
-
import 模块名 import 模块名,模块名
-
-
给模块起别名
-
格式: import 模块名 as 别名
-
-
直接引入模块中的内容
-
from 模块名 import 指定功能 from 模块名 import 功能1,功能2 from 模块名 import * (不推荐)
-
-
-
相对引入
-
相对引入必须给路径
-
格式
-
格式: from . import 模块名 from . import 模块名 as 别名 from .模块名 import 具体内容 -
注意:从当前文件夹下导入 注意启动文件时必须要带路径
-
python -m 文件夹.要执行的python文件名
-
-
十二. 包
12.1 概述
-
包 (package),程序包的简称,在 Python 中就是一个文件夹,通过文件夹管理 Python
模块的操作方式
-
将不同功能的模块放到不同的文件夹中去管理,这个文件夹就是我们的程序包
-
python中的包和普通的文件夹不同,Python中标准的包,包含了一个__init__.py的文件
-
一般__init__.py这个模块成为包声明模块
12.2 包的引入
-
绝对引入
-
基本引入方式[推荐]
- 格式: from 包名 import 模块名
-
起别名
- 格式: from 包名 import 模块名 as 别名
-
直接引入包
-
格式: import 包名
-
注意: 需要修改引入包文件夹下的 init.py文件
-
-
指定哪些模块可以被引入
- 添加:from . import 允许导入的模块名
-
一次性引入指定包中所有的模块
-
格式: from 包名 import *
-
注意: 修改包下的__init__.py文件
-
1方案:添加 from . import 需要导入的模块
-
2方案:添加 all = [“模块名”] 引入导入的模块
-
-
-
相对引入
-
格式: from .包名 import 模块名
-
注意:需要在命令行项目同级目录下执行 python -m 项目名.主文件名
-
备注:当前包被其他模块通过 import 引入使用时,init.py 中的代码会自动执行
-
-
-
name 属性:
- 如果当前文件被当做模块使用 name 是当前文件的文件名
-
如果当前文件 仅仅作为python文件执行,name 的值 “mian”
十三. 内置模块
13.1 random模块
- random.random() 产生大于 0 且小于 1 之间的小数
- random.uniform(a, b) 产生指定范围内的随机小数
- random.randint(a, b) 产生a, b范围内的整数, 包含开头和结尾
- random.randrange(start. stop, [step])产生 start,stop 范围内的整数,包含开头不包含结尾
- random.choice(lst) 随机返回序列中的一个数据
- random.shuffle() 在源列表的基础上去打乱, 没有返回值
13.2 sys模块
- sys.version 返回解释器的版本号
- sys.path 返回模块的搜索路径
- sys.argv 接收命令行下的参数
13.3 string模块
- .string.ascii_letters 获取所有ascii码中字母字符的字符串(包含大写和小写)
- .string.ascii_uppercase 获取所有ascii码中的大写英文字母
- string.ascii_lowercase 获取所有ascii码中的小写英文字母
- string.octdigits 获取所有的八进制进制数字字符
- string.hexdigits 获取所有16进制的数字字符
- printable 获取所有可以打印的字符
- whitespace 获取所有空白字符
- punctuation 获取所有的标点符号
13.4 time模块
- 计算机表示时间的方式一般有三种:
- 时间戳 计算机识别 表示从1970年1月1日 00:00:00 开始到现在的秒数
- 时间元组 操作时间
- 格式化时间 人能看懂的 ‘2020/8/21’
- time.slep(number) 睡眠等待
- time.time() # 当前系统时间的时间戳 float类型
- time.localtime() # 当前系统时间 时间元祖共有9个元素(年,月,日,时,分,秒,一周的第几日,一年的第几天,夏令时)
- 注意: 周 从0开始 0代表周一
- time.strftime(‘%Y-%m-%d %H:%M:%S’) 格式化时间字符串:
- %y 两位数的年份(00-99)
- %Y 四位数的年份(0000-9999)
- %m 月份(1-12)
- %d 月中第几天(0-31)
- %H 24小时制 (0-23)
- %l 12小时制(01-12)
- %M 分钟 (00-59)
- %S 秒 (00-59)
- %a 简化的星期名称
- %A 完成的
- %b 简化的月份
- %B 完整的月份
- %j 一年内的第几天(001-366)
13.5 时间的操作: 三种时间的转换
- 时间戳转格式化字符串: 先将时间戳转换成时间元组,然后将时间元组转化成格式化时间
- 时间戳转换成时间元组: time.localtime(120000)
- 时间元组转格式化字符串: time.strftime(“Y%-%m-%d”,time.localtime(120000))
- 格式化时间转时间戳: 先将格式化时间转成时间元组,然后将时间元组转成时间戳
- 将格式化字符串转换成时间元组: time.strptime(‘1970-01-02’,’Y%-m%-%d’)
- 时间元组转成时间戳: time.mktime(time.localtime(120000))
- 时间元组转成结构化时间: 星期 月 日 时:分:秒 年
- time.asctime(time.localtime())
十四. 面向对像
14.1 概述
-
面向对象
-
面向对象就是我们说的 面向对象编程(Object Oriented Programming,OOP):
-
就是一种编程****思想****,解决问题的一种思路
-
面向对象,解决问题时关注的不是解决问题的步骤和过程,关注的是参与解决问题的对象,以及他们的行为
-
优点: 生活的还原度高,可以表示生活中所有的事物,描述每种类型的事物的****特征*和*行为**** 可以解决较为复杂的问题,功能的拓展性非常好
-
缺点: 在还原某些场景时,没有直接去解决问题,而是首先表示这些参与的对象类型,开始编写代码时较为复杂,准备时间较长. 功能的稳定性相对不足 面向对象效率要低于面向过程
-
适用场景: 对软件功能的扩展性要求高,但是稳定性要求一般的项目
-
-
面向过程
- 也是一种编程思想,解决问题时关注的是****解决问题的步骤*和*过程****
- 最直观的实现方式就是****函数式编程****,通过定义函数描述步骤
- 通过函数的调用完成过程的执行,最终解决我们的问题
- 优点: 思路清晰 过程明确 解决问题的稳定性非常好
- 缺点: 功能依赖性太强 扩展性差
- 适用场景: 软件对于功能的稳定性比较高,对扩展性要求不是很高的情况下,可以选择面向过程
- 适用案例: 由于面向过程 代码和代码之间的依赖性太强(****耦合度高****),所以编写代码的时候必须对代码的前后关联关系非常了解,才能开发较为成熟的软件
-
面向过程和面向对象的区别
- 都是编程思想,分别有各自的使用场景,面向过程更适合稳定性要求高的项目,面向对象更适合于对软件的拓展性要求高的项目
- *面向过程解决问题的核心:解决问题的步骤*
- 将关键的步骤封装成了函数,通过函数控制运行流程
- *面向对象解决问题的核心:参与解决问题的对象*
- 面向对象的最直观的体现是 类和对象 对象和对象行为的关系
14.2 术语介绍
- 类
- 将具有共同特征以及行为的一组对象进行抽象,抽象出来的东西,描述一类事物的概念
- 对象
- 实际存在的物体,包含了具体属性和方法的实体,这个事物是通过类创建创建出来的,属于一个类
- 属性
- 就是一个变量 可以存储数据 用于描述生活中一个事物的特征
- 方法
- 方法就是一个函数,当函数声明在类中,就成为方法,描述一个事物的行为
- 构造方法
- 通过指定的类创建对象的方法,通过构造方法可以按照我们的需要来创建对应类的对象
- 类和对象的关系
- 类和对象是计算机编程语言中的用于描述事物的载体。****它们的关系是,对象是类的实例,类是对象的模板****
14.3 类的声明
-
Python中提供了一个关键字 class 来声明一个类
-
基本语法:
class 类名: “””类的文档注释””” def __init__(self,name): “””声明属性的方法””” # 自定义属性: 固定语法 self.name = name def study(self): “””方法文档注释””” print(f“””{self.name}正在学习中..”””) -
类的声明规则:
- 类声明前后: 间隔两个空行
- 类名: 帕斯卡命名法[大驼峰命名法]
- 类的文档注释: 描述类的作用和使用注意事项
- init()方法:固定语法,用来声明类型的的属性
- 类的属性名: 遵循变量的命名
- 类方法名: 遵循函数命名
14.4 对象的创建
- 对象是通过类创建出来的,一个类可以创建多个相互独立的对象
- 格式: 引用变量 = 类名(参数列表)
- 使用对象的属性: 引用变量.属性名
- 使用对象方法 : 引用变量.方法名()
14.5 魔术方法
14.6 面向对象的三大特性
-
封装
-
定义
- 将一个对象的数据隐藏在对象内部, 不让外界直接访问, 而是通过对象提供的方法来访问这些隐私的数据,这样就可以在访问方法中添加访问条件限制. 目的是对数据的有效组织和数据安全性的保护
- 就是将数据包裹起来, 不让外部直接访问
-
属性的封装方法(私有化属性)
-
class Person: def __init__(self,name,gender,gae): self.name=name # 公共属性 self._gender = gender #受保护属性:约定私有属性,规范上要求不要直接访问 self.__age = age # 私有属性: 语法上不能通过属性名称直接访问 -
私有属性可以访问: 对像名._类名__属性名
-
面试题: 请解释一下为什么python中面向对象开发时,两个下划线开头的属性不能直接访问,编写代码就是为了来运算的,不能访问还有什么意义
- 属性私有化时python层面的操作, 底层解释器在解释时将两个下滑线开头的属性进行了自动转换变成了_类名__属性名形式,原来属性名已经不存在了,所以不能直接访问,但是可以通过转换后的语法访问
- 数据就是参与运算的,私有化属性数据有两个用途,第一可以用在当前类型中的业务流程中, 如对象的一个临时基数属性等等, 第二可以使用类提供的访问私有属性的方法类获取数据参与类外部的运算
-
-
属性的访问方法
-
属性私有化之后, 只能在当前类内部访问, 为了数据的可用性,一般回提供私有访问属性的操作方法
-
语法格式
-
获取__name属性的方法
def get_name(self,name): #get_属性名()... return self.__name -
修改__name属性方法
def set_name(self,name): #set_属性名()... self.__name = name
-
-
-
添加访问限制
-
外界通过set/get方法访问数据时, 可以给get/set添加设置访问条件
-
添加set_age属性的方法:
def set_age(self, age) if 判断是否合法: self.__age = age return '非法数据要进行的操作' -
添加get_name属性方法:
def get_name(self): if 判断是否有权限 return self.__name return "没有权限要进行的操作"
-
-
总结:
- 封装,将对象的数据隐藏在内部,不让外界直接访问,而是通过提供的属性访问set/get方法完成数据的访问和赋值,在set/get方法中添加访问条件限制,完成私有数据的保护
- 封装是面向对象非常重要的特性, 通过封装可以有效完成数据的保护
- Python中提供封装语法在很多时候完成定制化数据访问,比较常用
- 实际项目工程中,如果开发的是工具插件类的通用程序,一般手工封装数据并添加添加访问条件和限制.
- 主要用于底层程序软件来发时,处于数据保护的目的,编写封装的代码,完成有条件的限制访问数据
-
封装拓展: 自定义属性
- 封装主要用于类内部属性的私有化操作,但是为了提高面向对象的****普遍适用性****,提供了一种特殊语句,可以通过类创建的对象,给当前对象自己拓展新的属性
- 在类的外部给已经创建的对象添加属性(扩展属性):
- 好处: 提高了对象的普适性,可以让对象更加适合不同的应用场景
- 坏处: 破坏了程序的统一性,不同的开发人员,可能扩展同一个属性的名字不一样,最终会导致对象没有办法操作[报错/失控]
- 魔法属性: slots = []
- 可以限制类型中只能出现哪些名称的属性,配合对象外部属性扩展使用
- 推荐使用,防止开发人员恶意拓展
- 方法按照属性赋值的方式访问: @property/@上一个方法名.setter

- 添加装饰器之后, 可以像操作属性一样操作方法
- 实例.name 获取私有属性
- 实例名.name = name 操作属性方法
-
-
继承
-
定义: 面向对象的三大特性之一, 主要体现了基于类的代码复用, 通过继承关系可以关联两个类
-
基本语法:
class Father: “””父类””” .... class Son(Father): “””子类””” ....- 一个子类Son继承了父类Father,在Son中就可以直接使用父类的公共属性和方法了
- python中所有的类都是直接或者间接继承object类的,所以我们在类中会有__new__方法 __init__方法 __str__方法 …
-
调用父类中的初始化方法, 子类中编写初始化方法, 父类中的方法不会直接调用, 必需手动调用
def __init__(self,name,age,gender,level): # 初始化父类方法 super().__init__(name,age,gender)- 继承关系中, 子类也可以通过____bases____属性查看当前类型继承的父类信息
-
方法的覆盖/方法的重写
- 是继承中比较重要的功能之一
- 子类当中定义了和父类中名字以及参相同的方法, 会覆盖父类的方法
- 在继承中,子类中可以重新编写和父类****相同名称的属性或者方法****,方法的重新编写成为方法覆盖(子类的方法覆盖了父类同名的方法)或者方法重写(子类重写了父类继承过来的方法)
- 在执行代码时,解释器会检查子类中重写类父类的方法,如果没有重写就直接执行父类中的方法,如果重写了就会执行子类中的方法,这也是多态的一种体现
-
继承体现了开发原则中的里氏代换原则,所有出现父类的地方否可以使用子类进行替换
-
继承的特征:
- 在不指定继承的父类时,所有类都继承自系统的object类
- 子类继承父类后就拥有了父类中除了私有成员外的所有成员包括魔术方法
- 子类继承父类后, 并不会把父类中的成员复制给子类, 而是去引用继承的类
- 子类继承父类后可以重写父类中的方法, 叫做重写/覆盖
- 子类重写父类的方法, 依然可以使用super().父类的方法名()的方式调用父类的方法
- 子类中如果定义了父类中不存在的方法, 成为对父类的扩展
-
单继承: 一个类只能继承一个父类的方式, 一个父类可以被多个子类继承
-
多继承: 一个子类继承多个父类的方式
-
语法格式
class Case(A,B,C): pass -
存在的问题: 一个子类继承多个父类时, 该子类继承类所有的父类方法, 但是如果其中多个父类拥有同名的方法会出现一些问题
-
例如:
class A: def say(self): print("A") class B: def say(self): print("B") class C(A, B): pass c = C() c.say() # 结果是 A -
多继承模式下继承顺序, 使用了广度优先的查询原则
-
python提供了 mro()方法用于确定继承关系中属性和方法的查询操作顺序
-
案例:
class F: def say(self): print("我是F") class A(F): def say(self): super().say() print("我是A") class B(F): def say(self): super().say() print("我是B") class C(A,B): def say(self): super().say() print("我是C") c = C() c.say() # 结果是什么 B A F C # 可以通过 类名.mro() 方法查看继承的顺序
-
-
-
多态
- 面向对象中唯一一个特殊的特性, 没有固定的语法结构, 体现的是程序运行过程中的状态改变和行为的多样性
- 可以通过继承关系来完成角色的关系切换
- 可以通过继承中方法的重写,完成行为方法的切换
- 可以通过代码结构的设计,完成行为的多样性
14.7 面相对像三大特性总结
-
封装:
-
学会操作语法即可,能看懂什么样的操作方式是封装
-
两个下划线开头,对属性或者方法进行封装操作
-
给私有属性提供访问方法
-
封装实际项目中,开发应用程序时很少些,编写通用底层模块时使用比较多
-
-
-
继承:
- 面相对像的三大特征的核心,不仅是一个特征,同时是面相对像编程的基础
-
多态
- 面相对像变成拓展, 以继承为基础, 没有固定语法
14.8 类属性和实例属性
-
概述
- 属性是描述对象特征的, 通常对象的特征都是每个对象自己独有的数据, 但是某些情况下也会出现一些现象 共有的属性
- 实例属性和类属性都是类中的数据,但是声明和访问上有所不同
-
实例属性
-
声明
-
实例属性的声明,包含在类型中的 init() 初始化方法中,使用 self 关键字将属性绑定到当前对象上
-
例如:
def __init__(self,title,content): """实例属性""" self.title = title self.content = content
-
-
访问
-
实例属性在类型内部可以通过self关键字引用, 在类型外部可以通过对象的引用变量访问和修改
-
例如:
class Article: def __init__(self,title,content): """实例属性""" self.title = title self.content = content def save(self): print(f"{self.title}正在保存") article = Article("标题","内容..") print(article.title)
-
-
-
类属性
-
声明
-
类属性声明在类型的内部, 方法的外部
-
例如:
class Article: # 文章最大字数限制 content_max_size = 120
-
-
访问
-
类属性能被当前类型的所有对象访问, 或者能直接通过类名称访问
-
例如:
# 对象名访问 print(article.content_max_size) # 类名访问 print(Article.content_max_size)
-
-
修改
- 类属性只能被类名称引用并修改, 不能通过对象的引用变量修改
-
-
总结:
-
类属性:
-
当前类的属性
声明位置:在类的内部,方法的外面
访问数据:当前类型名称 当前类创建的所有对象
修改数据:通过当前类名去修改
-
-
实例属性:
-
当前实例的属性
-
声明位置: 声明在__init__(self)中
-
访问数据: 只能被当前对象访问
-
修改数据:只能被当前对象修改
-
-
14.9 静态方法、类方法、实例方法
- 概述
- 方法本质上是一个函数, 在面向对象编程中将函数绑定到类中, 成为了功能跟加强大的属于每个对象的方法, 用于描述对象的行为
- 实例方法
- 声明在类型内部的普通方法,第一个参数是当前对象本身;实例方法在执行过程中可以访问当前对象的所有属性 / 方法、当前类型的属性 / 方法等;实例方法在使用过程中只能被对象的变量调用执行
- 类方法
- 类方法是声明在类内部,方法上使用装饰器 @classmethod 声明的方法,第一个参数是当前类本身,约定俗 成使用 cls 表示;类方法****只能访问当前类型的类属性****,****不能访问任何对象的实例属性****;类方法能被当前****类型调用****,也****能被实例对象调用****
- 静态方法
- 静态方法本质上是被统一管理在类中的函数,声明在类的内部,方法上使用装饰器 @staticmethod 声明的方法;静态方法是独立的方法,****不能访问类的任何信息****;静态方法可以****被类名称直接调用****,也可以****被对象的变量调用执行****
- 总结

14.10 反射方法
| *魔法方法* | *描述* |
|---|---|
| hasattr(obj, name) | 判断是否包含名称为name的属性 |
| setattr(obj, name, value) | 给名称为name的属性设置value数据 |
| getattr(obj, name) | 获取名称为name的属性的具体数据 |
| delattr(obj, name) | 删除名称为name的属性 |
In [4]: class A:
...: def __init__(self, name, age):
...: self.name = name
...: self.age = age
...: def say(self):
...: print("are you see")
...:
In [5]: a = A('张三', 19)
In [6]: hasattr(a, 'age')
Out[6]: True
In [7]: getattr(a, 'age')
Out[7]: 19
In [8]: setattr(a, 'age', 20)
In [9]: a.age
Out[9]: 20
In [10]: delattr(a, 'age')
In [11]: a.age
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
in
----> 1 a.age
AttributeError: 'A' object has no attribute 'age'
- 应用场景: 多人开发中, 开发者A开发登录功能, 开发者B使用登录功能, 可以使用以上方法判断A是否开发完成
十五. 设计模式
设计模式概述: 是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结
是软件开发人员在软件开发过程中面临的一般问题的解决方案, 常见的设计模式有23 种
15.1 单例模式
-
定义
- 项目中的某个类中处理项目中的公共数据,此时需要该类型创建的对象在任何其他对象访问时,任何时候任何方式获取到的都是同一个对象,以保证数据的一致性。类似这样的需 求通过设计模式中的单例模式可以得到完美的解决,让一个类型任何时候创建的对象都是同一个以保证数据的唯一性
-
基本语法
-
以类为例, 重复创建同一个对象
class MyData: __ins = None def __new__(cls, *args, **kwargs): if not cls.__ins: cls.__ins = objects.__new__(cls) return cls.__ins -
当我们创建对象时, 创建出来的对象都是同一个对象
-
15.2 工厂模式
-
定义
- 将复杂对象的创建过程封装在方法的内部,提供了一个简单的创建方式给用户使用
-
基本语法
class Motorbike: def __init__(self): self.brand = "摩托车" def run(self): print(f"开始我喜爱的{self.brand}车") class Minibus: def __init__(self): self.brand = "面包车" def run(self): print(f"开始我喜爱的{self.brand}车") class Sedan: def __init__(self): self.brand = "小轿车" def run(self): print(f"开始我喜爱的{self.brand}车") # 定义工厂类 class Factory: def buy_vehicle(selfm,brand): if brand == 1: return Motorbike() elif brand == 2: return Minibus() elif brand == 3: return Sedan() else: return "没有你需要的车" factory = Factory() # 根据传递的参数来选择创建不同的对象 moto = factory.buy_vehicle(1) moto.run()
十六. 文件操作
16.1 文件分类
- 文本文件
- 是由字符组成, 编程的源代码,txt. 使用记事本打开不会出现乱码的文件
- 二进制文件
- 是由二进制数据组成,图片 音频 视频 world … 使用记事本打开会出现乱码
16.2 文件读写
-
python操作文件
- open(file,mode=’r’,encoding=None,buffering=-1) 直接对文件内容进行操作
- file: 需要操作文件,可以写绝对路径,可以写相对路径
- model: 文件的操作模式 默认r
- r: 以只读的方式打开文件
- w: 写, 如果文件不存在,会新创建一个文件, 如果文件已经存在,并且有内容,会将原内容覆盖掉
- a: 追加写, 如果文件不存在会新创建一个文件, 如果文件存在,并有内容,不会覆盖原内容,跟在原内容后面继续写入新的数据
- br: 以只读的形式打开二进制文件
- bw: 以写入的方式打开文件
- ab: 二进制文件的追加写
- + 增强功能 一般配合读写使用
- r+ 可读可写
- w+ 可读可写
- a+ 可读可写
- encoding: 指定以哪一种编码格式去操作文件
- buffering:如果buffering的值被设为-1,0就不会寄存。如果buffering的值取值1,访问文件时会寄存行 若是大于1,表明是寄存区的大小。若是负值,则缓冲大小则为系统默认
- open(file,mode=’r’,encoding=None,buffering=-1) 直接对文件内容进行操作
-
读取操作:
- read() 读取文件所有内容
- readline() readline 每次读取一行,并且自带换行功能 每一行末尾会读到 \n
- readlines() readlines,一次性以行的形式读取文件的所有内容并返回一个 list,需要去遍历读出来
-
写入操作
- write(‘’)
- writelines(lst) 将多行内容一次性写入文件
-
with语法
-
将文件的操作步骤进行优化处理,不需要手动关闭
-
基本语法
with open(filename, '读写方式', encoding='编码格式') as f: 操作文件
-
-
csv文件读写
-
python自带csv模块, 可以对csv文件进行读写操作
-
基本语法
import csv # 向文件写入数据: csv.writer对象 with open(文件,mode=”w”,encode=””) as f: # 获取writer对象 writer = csv.writer(f) # 写入一行数据 列表类型 writer.writerow(lst) # 写入多行数据 二维列表 writer.writerows(写入多行数据) # 读取数据: reader对象 with open(文件,mode=’r,’,encode=””) as f: # 获取reader对象 reader = csv.reader(f) # 打印读取的文件 for i in reader: print(i)
-
-
乱码
- python读写文件时,默认使用编码为平台编码, 注意编码方式,当文件的写入保存,和文件打开读取的编码不一致时会出现乱码.
十七. os模块
17.1 os常见方法
| *方法* | *描述* |
|---|---|
| os.rename(old,new) | 重命名文件 |
| os.remove(filepath) | 删除文件 |
| os.mkdir(path) | 创建目录 |
| os.makedirs(path) | 创建多级目录 |
| os.remdir(path) | 删除目录,目录必须为空 |
| os.removedirs(path) | 删除多级空目录 |
| os.getcwd() | 获取当前工作路径 |
| os.listdir() | 默认获取当前目录下文件列表,通过传参可以指定路径 |
| os.chdir(path) | 切换所在路径 |
In [12]: import os
In [13]: os.cpu_count()
Out[13]: 2
In [14]: os.system('python')
Python 3.5.2 (default, Apr 16 2020, 17:47:17)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> exit()
Out[14]: 0
In [15]: ls
app_private_key.pem ch08www/ mod_wsgi-4.6.4/ shop/
app_public_key.pem code/ mongodb-linux-x86_64-ubuntu1604-4.2.8.tgz wechat.py
In [16]: os.rename('./wechat.py', 'wechet.py')
In [17]: ls
app_private_key.pem ch08www/ mod_wsgi-4.6.4/ shop/
app_public_key.pem code/ mongodb-linux-x86_64-ubuntu1604-4.2.8.tgz wechet.py
17.2 os.path 方法
| os.path.exits(path) | 判断文件是否存在 |
|---|---|
| os.path.isfile(path) | 判断是否是文件 |
| os.path.isdir(path) | 判断是否是目录 |
| os.path.abspath(相对路径) | 获取绝对路径 |
| os.path.isabs(path) | 判断是否是绝对路径 |
| os.path.basename(path) | 获取路径中的最后一部分内容 |
| os.path.dirname(path) | 获取父目录部分 |
| os.path.getsize(path) | 获取文件大小 返回的是字节 |
| os.path.join(path1, path2) | 对两个路径进行拼接 |
17.3 os 其他方法
- chmod: 文件授权
- curdir: 获取当前路径
- getcudb: 二进制的 当前工作目录
- getenv: 获取指定环境变量
- getlogin: 获取当前登录用户
- os.cpu_count(): 获取当前操作系统cpu的核心数
- os.system(command): 指定DOS命令
十八. 异常处理
18.1 程序异常
-
概述
- 异常是指在语法正确的前提下, 程序运行时报错就是异常
- 异常的出现会导致程序直接崩溃退出, 不在继续向后运行, 所以一般程序中要针对常见的异常进行处理, 保证出现了问题后, 程序能正常运行
- 编写代码要有容错性: 允许用户操作时出现的错误
-
常见异常
- syntaxError : 语法错误
- NameError : 名字错误
- IndexError : 索引错误
- ZeroDividionError: 除零错误
- KeyError : 键错误
- valueError: 值错误
-
异常处理
-
捕获单个异常
-
语法格式
try: ...代码... .... except 异常类型: ...处理异常的代码... -
程序从上往下执行,先执行try中的代码,如果代码报错,不会据需向下执行,而是执行except中的代码, 如果try中的代码俺没有报错,except中的代码不会执行
-
-
捕获多个异常
-
语法格式
多分支结构: try: ...代码... .... except 异常类型1: ...处理异常的代码... except 异常类型2: 异常类型2处理代码 except 异常类型3: 异常捕获3 ....... -
程序从上往下执行,先执行try中的代码,如果代码没有报错,except代码都不会执行
-
如果try代码出错了,程序会依次和except中的异常类型比较,执行对应异常类型中的处理程序,其他except不在执行,如果都不符合,程序抛出异常终止.
-
根据不同的异常,单独处理
元组结构: try: 代码 except(异常1,异常2,异常3) as 别名: 捕获异常 -
try只要异常,只要异常类型符合元组中的某一个类型,直接执行异常捕获,
-
-
捕获所有异常
-
语法格式
try: 执行的代码 except: 执行异常 # except后面不写异常类型, 表示可以捕获所有异常信息 或者 try: 执行的代码 except Exception: 执行异常 # Exception 是所有异常的父异常,try抛出的异常,Exceptio都能捕获
-
-
else格式
try: 执行的代码 except 异常类型 as 变量名: 执行异常 .... else: ...代码...- 如果try中的代码,没有异常,会执行else中的代码, 如果try中的代码抛出了异常,else中的代码不会执行
- 注意: else一定要有except, 直接使用else会报错
-
try…finally 格式
try: 执行的代码 except 异常类型 as 变量名: 执行异常 .... finally: ...代码...- 不管try是否有异常,最终都会执行finally中的代码.
-
18.2 触发异常
-
在实际业务中我们可以根据用户需求和实际情况手动抛出异常
-
python中提供了Exception类 ,来实例化异常
- 抛出系统异常
格式 描述 raise Exception(“异常提示信息”) 当程序执行到raise 时,会自动的触发异常,让程序结束 -
我们也可以根据系统提供的Exception类 自定义自己的异常类
class name(Exception): def __init__(self): pass def __str__(self): return “异常提示信息”
十九. 多任务
19.1 概述
- 任务可以理解为程序, 多任务即多个程序同时执行
- 单核处理器实现多任务: 调度算法, 时间片轮转
- 并发: 多个任务交替执行, cpu轮番调度, 假并发
- 并行: 多个任务同时执行, 真并发, 多个cpu一起执行
- 并发和并行都是多任务场景
- 多任务没有顺序, 同时执行,最终执行的耗时时间, 由耗时最长的任务决定
19.2 同步和异步
- 同步: 同指的是协同, 配合完成, 描述的是串行执行,多个任务按照顺序依次执行的过程
- 异步: 描述并发和并行, 多个任务同一个时段内同时执行, 每个任务都不会等待其他任务执行结束去执行
19.3 操作系统实现多任务:
- 多任务操作系统最大的特点就是同时运行多个程序
- 操作系统实现多任务指的是CPU轮询机制
- CPU执行多任务, 使用的是并发操作, 同一时刻只执行一个任务
- 时间片: 一个任务执行的一个单元时间, 当这个时间片执行结束, cpu就会切换到下一个时间片, 执行下一个任务
19.4 python实现多任务
- 多线程, 多进程, 协程
- 在单核处理器无法发挥多进程优势
- 开启进程的数量一般不大于cpu核心的两倍
二十.进程和线程
20.1 进程
-
正在运行的一个程序就是一个进程
-
程序只有一个, 进程可以有多个
-
进程是系统进行资源分配的最小单位, 每一个进程都有自己的独立的内存和资源
-
是程序执行的最小单位
-
进程和进程之间相互独立, 资源不共享
20.2 线程
-
线程是进程中的一个执行线路,或者是流程
-
一个进程中至少有一个主线程, 可以包含多个线程
-
线程是任务调度的最小单位, 程序真正执行的时候,调用的是线程
-
多线程之间共享进程资源,相对于进程来说线程更节省资源
-
进程之间的切换重量级, 线程之间的切换轻量级
20.3 使用场景
- 进程适用于计算密集型操作
- 线程适用于I/O密集型操作
二十一. 多线程创建
21.1 使用threading 模块创建线程
import threading
import time
def dance():
for i in range(3):
time.sleep(1)
print("=====唱歌======")
def song():
for i in range(3):
time.sleep(1)
print("=====跳舞======")
if __name__ == '__main__':
t1 = threading.Thread(target=dance)
t2 = threading.Thread(target=song)
t1.start()
t2.start()
21.2给线程传递参数
- 给函数传递参数,使用线程的关键字 args=() 进行传递参数
import threading
import time
def dance(name):
for i in range(3):
time.sleep(1)
print(f"====={name}唱歌======")
def song(name):
for i in range(3):
time.sleep(1)
print(f"====={name}跳舞======")
if __name__ == '__main__':
t1 = threading.Thread(target=dance, args=('laoeang',))
t2 = threading.Thread(target=song, args=('xiaoli',))
t1.start()
t2.start()
21.3 使用继承方式创建线程
import threading
import time
class MyThread(threading.Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print(f"{self.name}唱了一首歌")
time.sleep(1)
if __name__ == "__main__":
t1 = MyThread("xiaowang")
t2 = MyThread("xiaoli")
t1.start()
t2.start()
21.4 实例方法
-
getName() 获取线程的名称
-
setName() 设置线程的名称
-
注意: 在继承的方式中, 会和name属性冲突, 传参时避免使用name属性名
-
isAlive/is_alive(): 返回当前线程的状态, 如果正在执行返回True, 如果没有执行或者执行结束返回False
import threading import time class MyThread(threading.Thread): def __init__(self, username): super().__init__() self.username = username def run(self): print(f"{self.username}唱了一首歌") time.sleep(1) if __name__ == "__main__": t1 = MyThread("xiaowang") t2 = MyThread("xiaoli") # 获取t1和t2的线程的名字 print(t1.getName()) print(t2.getName()) # 判断t1是否活着 print(t1.is_alive()) t1.start() print() print(t1.is_alive()) t2.start() # 设置t1的名字 t1.setName("t1") print() print(t1.getName())# 输出 Thread-1 Thread-2 False xiaowang唱了一首歌 True xiaoli唱了一首歌 t1 [Finished in 1.1s]
24.5 等待线程 join()
-
等待其他线程执行完成后主线程才会继续执行,
-
可以设置等待时间timeout, 如果超过改时间,主线程不会等待
import threading import time def func1(): time.sleep(1) print("我是线程 t1") def func2(): time.sleep(1) print("我是线程 t2") if __name__ == '__main__': t1 = threading.Thread(target=func1) t2 = threading.Thread(target=func2) t1.start() t1.join() t2.start() print("我是主线程")
21.6 守护线程 setDaemon()
-
当我们的主线程执行结束, 不管守护进程是否执行结束,都强制终止
-
守护线程的设置一定是在开启线程之前
import threading import time def func1(): time.sleep(2) print("我是线程 t1") def func2(): time.sleep(1) print("我是线程 t2") if __name__ == '__main__': t1 = threading.Thread(target=func1) t2 = threading.Thread(target=func2) t1.setDaemon(True) t1.start() t2.start() print("我是主线程") # t1没有被输出, t1的等待时长较长, 主线程执行结束, t1还没执行完
21.7 threading 模块提供的方法
- threading.currentThread() 返回当前线程对象
- threading.enumerate() 返回一个包含正在运行的线程list类型
- threading.activeCount() 返回正在运行的线程数量
21.8 线程会共享全局变量
-
多线程开发时, 共享全局变量, 会带来资源的竞争, 也就是出现了数据的不安全
-
产生原因: 多个线程同时访问同一个资源, 我们没有对数据进行保护, 造成数据破坏, 导致我们的线程的结果不可预期, 这种现象称为: 数据不安全
-
解决方法: 同步处理, 加锁
-
例如: 售票系统
import threading import time tackets = 10 def func(): global tackets while tackets > 0: tackets -= 1 time.sleep(0.1) print(f"窗口1售出了一张票, 还剩{tackets}张") def func1(): global tackets while tackets > 0: tackets -= 1 time.sleep(0.1) print(f"窗口1售出了一张票, 还剩{tackets}张") if __name__ == '__main__': t1 = threading.Thread(target=func) t2 = threading.Thread(target=func1) t1.start() t2.start()
21.9 互斥锁
-
某一个线程需要修改数据前, 现将其锁定, 此时资源属于锁定状态, 其他线程是不能对这个数据进行操作的, 直到当前线程将锁释放, 其他线程将当前数据锁定, 进行操作,操作完成释放锁,
-
每一次只能有一个线程进行写入操作, 从而保证数据的安全, 但是会牺牲效率
-
threading.Lock() 实现锁
-
acquire() 锁定
-
release() 释放
-
优点: 确保了某段关键代码只能由一个线程从头到尾完整的执行
-
缺点: 阻止了多线程并发执行, 包含锁的某段代码实际上只能以单线程模式执行, 效率大大降低了
-
例如: 多人卖票窗口
import threading import time tackets = 1000 def func(name): global tackets while tackets > 1: if lock.acquire(): tackets -= 1 if tackets < 0: # 判断票数, 防止多卖 break time.sleep(0.1) print(f"{name}售出了一张票, 还剩{tackets}张") lock.release() if __name__ == '__main__': lock = threading.Lock() t1 = threading.Thread(target=func, args=("t1",)) t2 = threading.Thread(target=func, args=("t2",)) t3 = threading.Thread(target=func, args=("t3",)) t1.start() t2.start() t3.start()
21.10 死锁
-
由于可以存在多个锁, 不同的线程持有不同的锁,并试图获取对方持有的锁时, 可能会造成死锁
-
在多个线程共享资源的时候, 如果两个线程分别占有一部分资源, 并且同时等待对方资源, 就会造成死锁现象
-
锁嵌套也会造成死锁
-
非全局变量不需要加锁
-
对于全局变量,在多线程中要注意数据错乱现象
-
在多线程开发中,全局变量是多个线程都共享的数据,而局部变量是各自线程的,是非共享的
import threading import time def func1(): print("func1") if lock1.acquire(): print("t1锁上了") time.sleep(0.1) if lock2.acquire(): # 此时会阻塞, 因为这个已经被fun2抢先上锁了 print("t2锁上了") lock2.release() print("t2释放") lock1.release() print("t1释放") def func2(): print("func2") if lock2.acquire(): print("t2锁上了") time.sleep(0.1) if lock1.acquire(): # 此时会阻塞, 因为这个已经被fun2抢先上锁了 print("t1锁上了") lock2.release() print("t1释放") lock1.release() print("t2释放") if __name__ == '__main__': lock1 = threading.Lock() lock2 = threading.Lock() t1 = threading.Thread(target=func1) t2 = threading.Thread(target=func2) t1.start() t2.start()
21.11 生产者与消费者模式
-
队列
-
python中的 queue模块中提供了同步的\数据安全的队列类,
-
FIFO 先入先出队列
-
LIFO 后入先出队列
-
PriorityQueue 优先级队列
-
这些队列都实现了锁, 能够在多线程中直接使用, 可以使用队列来实现线程间的同步
-
python2 和 python 队列的区别
-
from Queue import Queue # python2 from queue import Queue # python3
-
-
基本使用
from queue import Queue # 先入先出 q = Queue() # 声明一个先进先出队列 # q.empty() 检测是否为空 # q.full() 检测是否存满 满了返回True # q.qsize() 获取队列中数据的个数 # q.put() 存放数据 # q.get() 获取数据 如果数据不存在 程序阻塞 # q.get_nowait() 获取数据不等待 # q = Queue(maxsize=3) # 声明指定长度的队列 # 优先级队列 import queue q = ProprityQueue() q = queue.PriorityQueue() q.put((1,'123')) # 先入后出 q = queue.LeftQueue()
-
-
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题
-
该模式通过平衡生产者线程和消费线程的工作能力来提高程序的整体处理数据的速度
-
为什么要使用生产者和消费者模式?
- 在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。****为了解决这个问题于是引入了生产者和消费者模式****
-
什么是生产者消费者模式?
- 生产者消费者模式****是通过一个容器来解决生产者和消费者的强耦合问题****。****生产者和消费者彼此之间不直接通讯****,****而通过阻塞队列来进行通讯****,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,****阻塞队列就相当于一个缓冲区****,****平衡了生产者和消费者的处理能力****
-
案例: 包子铺
import threading import queue import time num = 0 # 生产者线程 def func1(name): global num while True: num += 1 q.put(f"{num}号包子") print(f"{name}完成{num}号包子") # 消费者线程 def func2(name): while True: res = q.get() print(f"{name}获取了{res},并一口吃了这个包子") time.sleep(0.1) if __name__ == '__main__': q = queue.Queue(10) t1 = threading.Thread(target=func1, args=("王大厨",)) t2 = threading.Thread(target=func1, args=("李大厨",)) t3 = threading.Thread(target=func2, args=("小王",)) t1.start() t2.start() t3.start()
21.12 threasLocal
-
在多线程环境下,每个线程都有自己的数据。一个线程使用自己的局部变量比使用全局变量好,因为局部变量只有线程自己能看见,不会影响其他线程,而全局变量的修改必须加锁, 加锁会导致效率变低
-
使用局部变量: 如果函数有多层函数调用,在最里层函数需要使用这个数据,中间函数的调用过程都必须传参数
-
threadLocal可以解决以上问题

-
一个threadLocal变量虽然是全局变量, 但每个线程都只能读写自己线程的独立副本, 互不干扰, threadLocal解决了参数在一个线程中各个函数之间互相传递的问题
21.13 pythonGIL锁
- python中的多线程实质上是伪多线程, 因为cpython中使用GIL来控制线程的执行, 无法发挥多核处理器的优势, 相对于真多线程效率要低
- python 代码执行是右python虚拟机进行控制的
- python设计之初的考虑, 在主循环中同时只能有一个线程执行, 就像单核处理器中进行多任务一样, python中的多线程被称为伪多线程, python中的多线程不能发挥多核处理器的作用
- 内存可以有多个程序, 但同一个时刻只能有一个程序运行, 所以就算python解释器可以运行多个程序,但是在任意时刻, 只有一个程序被解释器执行
- GIL全局锁保证同一时刻只能有一个线程执行
- 由于受到GIL锁的影响, 多线程的效率并不会有多线程效率高, 但是也比单线程速度快
二十二. re模块
正则表达式: 也称为规则表达式, 英文名称Regular Expression, 专门用于进行文本检索、匹配、替代等操作的一种技术。正则表达式是一种独立的技术, 并不是某种编程语言独有的
22.1 python中操作正则表达式
- re.match(reg, info)
- 从头开始按照正则表达式, 去指定字符串info中匹配符合re规则的字符串
- 成功返回match对象, 不成功返回None
- re.search(reg, info)
- 描述整个字符串, 使用正则表达式进行匹配
- 匹配成功返回第一个匹配到的字符串, 如果没有匹配到返回None
- re.findall(reg, info)
- 扫描整个字符串, 将符合规则的字符串全部提取出来, 存到列表中
- re.finditer(reg,info)
- 扫描整个字符串, 将符规则的字符串存入一个可以迭代的对象中
- re.fullmatch(resg, info)
- 扫描整个字符串, 如果整个字符串符合规则则返回, 如果不符合就返回None
- re.split(reg, string)
- 将字符串拆分成一个字符串列表, 按照规则去拆分
- re.sub(reg, repl, string)
- 使用指定的字符串替换目标字符串中匹配到的字符
- re.I 匹配时忽略大小写
- re.M 多行匹配
- re.S 让 . 可以匹配所有的单个字符, 包括换行符
22.2 正则表达式元字符
-
元字符 描述 \ 将下一个字符标记符、或一个向后引用、或一个八进制转义符。例如,“\n”匹配\n。“\n”匹配换行符。序列“\”匹配“\”而“(”则匹配“(”。即相当于多种编程语言中都有的“转义字符”的概念。 ^ 匹配输入字行首。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 $ 匹配输入行尾。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 * 匹配前面的子表达式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等价于{0,}。 + 匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 ? 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”。?等价于{0,1}。 { n} n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 { n,} n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 { n,m} m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 .点 匹配除“\n”和"\r"之外的任何单个字符。要匹配包括“\n”和"\r"在内的任何字符,请使用像“[\s\S]”的模式。 (pattern) 匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“(”或“)”。 (?:pattern) 非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分时很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。 (?=pattern) 非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 (?!pattern) 非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。 (?<=pattern) 非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。*python的正则表达式没有完全按照正则表达式规范实现,所以一些高级特性建议使用其他语言如java、scala等 (? 非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(? x|y 匹配x或y。例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[z|f]ood”则匹配“zood”或“food”。 [xyz] 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 [^xyz] 负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”任一字符。 [a-z] 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身. [^a-z] 负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 \b 匹配一个单词的边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”;“\b1_”可以匹配“1_23”中的“1_”,但不能匹配“21_3”中的“1_”。 \B 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 \d 匹配一个数字字符。等价于[0-9]。grep 要加上-P,perl正则支持 \D 匹配一个非数字字符。等价于[^0-9]。grep要加上-P,perl正则支持 \f 匹配一个换页符。等价于\x0c和\cL。 \n 匹配一个换行符。等价于\x0a和\cJ。 \r 匹配一个回车符。等价于\x0d和\cM。 \s 匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 \S 匹配任何可见字符。等价于[^ \f\n\r\t\v]。 \t 匹配一个制表符。等价于\x09和\cI。 \v 匹配一个垂直制表符。等价于\x0b和\cK。 \w 匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集。 \W 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 \xn 匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。 *num* 匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。 *n* 标识一个八进制转义值或一个向后引用。如果*n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n*为一个八进制转义值。 *nm* 标识一个八进制转义值或一个向后引用。如果*nm之前至少有nm个获得子表达式,则nm为向后引用。如果*nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则*nm将匹配八进制转义值nm*。 *nml* 如果n为八进制数字(0-7),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。 \un 匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(©)。 \p{P} 小写 p 是 property 的意思,表示 Unicode 属性,用于 Unicode 正表达式的前缀。中括号内的“P”表示Unicode 字符集七个字符属性之一:标点字符。其他六个属性:L:字母;M:标记符号(一般不会单独出现);Z:分隔符(比如空格、换行等);S:符号(比如数学符号、货币符号等);N:数字(比如阿拉伯数字、罗马数字等);C:其他字符。*注:此语法部分语言不支持,例:javascript。 <> 匹配词(word)的开始(<)和结束(>)。例如正则表达式 能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"。注意:这个元字符不是所有的软件都支持的。 ( ) 将( 和 ) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用。 | 将两个匹配条件进行逻辑“或”(or)运算。例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。注意:这个元字符不是所有的软件都支持的。
22.3 正则表达式分组
-
正则表达式主要通过()进行分组, 以提取匹配结果的部分结果, 常用的分组有两种
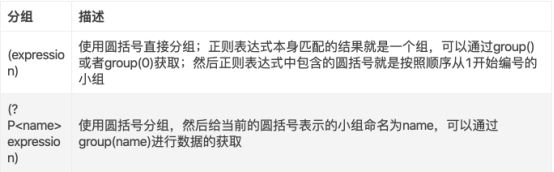
22.4 贪婪模式和非贪婪模式
-
贪婪模式:正则表达式匹配的一种模式,速度快,但是匹配的内容会从字符串两头向中间搜索匹配,一次尽可能多的匹配符合条件的字符串,一旦匹配选中,就不继续向字符串中间搜索了.
-
懒惰模式:从目标字符串按照顺序从头到位进行检索匹配,尽可能的检索到最小范围的匹配结果,语法结构是在贪婪模式的表达式后面加上一个符号?即可
-
正则表达式中加?和不加?的区别
- 正则表达式默认加*或者+是贪婪模式, 在匹配数据是使用 .* .+ 尽可能多的匹配数据, 贪婪匹配
- .*? .+? 是尽可能少的匹配数据, 非贪婪模式
二十三. 迭代器
-
什么是迭代对象
- 只要能被循环遍历的对象, 我们都可以称之为迭代对象
- 一个对象或者类包含_iter_()魔术方法, 这个类/对象就是可迭代对象
- _iter_()魔术方法:得到的是当前对象的迭代器
-
什么是迭代器
- iter(可迭代对象) 返回的就是迭代器
- 是一个可以记住遍历位置的对象
- 一个包含_next_()魔术方法的对象
- 通过_next_()方法可以遍历当前对象的数据, next(迭代器)
-
迭代器的方法
- _next_ 获取元素
- __length__hint 获取元素的个数
- _setstate_ 决定取值位置
-
迭代器特点
- 可迭代对象是可以使用循环遍历的一种特殊数据
- 比如, 字符串, 该对象包含了一个__iter__魔术方法
- 通过魔术方法的执行可以得到该对象的迭代器
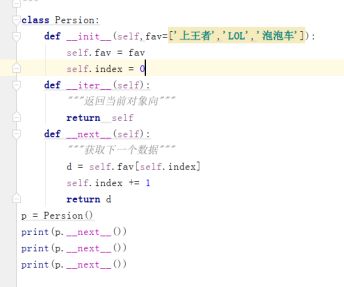
-
只定义一个迭代器
二十四. 生成器
python中一边循环, 一边计算的机制, 成为生成器, 生成器本质就是迭代器
-
为什么要使用生成器
- 项目中有大量的数据需要存储, 如果用列表, 会导致内存开销大, 消耗长
- 创建列表时不管数据有没有使用, 都存储在内存中
- 通过生成器生成, 进行优化, 记录生成数据的方法, 需要一个数据就生成一个数据
-
创建生成器的两种格式
-
生成器表达式
- 将列表推导式[]改成()
- 使用next()函数访问数据, 这种访问方式超出范围会报错
- 同一个数据不能生成第二次
-
生成器函数
def func(): print("开始") yield 1 print("第二个") yield 2- yield 不能和 return 共用
- yield和return相同都可以返回值,但是不同的是yield不会结束函数会记录函数执行的位置
-
-
生成器函数执行结束后会得到一个生成器返回值,并不会执行函数体, 使用next()之后才会执行函数体, 并且获得返回值
-
send() 获取下一个值得结果, 和next()基本一样, 但是在获取下一个值的时候给上一个yield位置传递一个数据
- 第一次使用生成器的时候使用next(), 如果使用send()必须传参数None
- 最后一个yield不能接收外部的值
-
yield form 循环遍历容器类型
for i in range(4): yield 等价于 yield from range(4)
二十五. unittest
软件测试是一种实际输出与预期输出之间的审核或者比较过程。
-
单元测试
- 单元测试是用来对一个模块/一个函数/一个类来进行正确性检验的测试工作
-
单元测试中核心概念
- test case: 一个py文件就是一个测试用例, 是一个完整的测试流程
- test suite: 测试用例集合
- text runner: 用来执行测试用例
- test fixture: 测试用例环境的搭建和销毁
- setUP 加载初始化数据
- tearDown 释放数据
-
unittest 使用步骤
(1)导入unittest模块,被测文件或者其中的类
(2)创建一个测试类,被继承unittest.TestCase
(3)重写setUp和tearDown方法(如果有初始化条件和结束条件)
(4)定义测试函数,函数名以test_开头。测试用例
(5)调用unittset.main()方法运行测试用例--------无此方法也是可以运行
-
断言Assert----结果对比的函数
-
设置断言,当一条测试用例执行失败,不会影响其他测试用例的执行
*Method*** *Checks that* *New In* sertEqual(a,b):相等 a == b sertNotEqual(a,b) a != b sertTrue(x) bool(x) is True sertFalse(x) bool(x) is False sertIs(a,b) a is b:判断是否是同一对象(id(a)) 3.1 serNottIs(a,b) a is not b 3.1 sertIsNone(x) x is None 3.1 sertIsNotNone(x) x is not None 3.1 sertIn(a,b):a是否在b中 a in b 3.1 sertNotIn(a,b) a not in b 3.1 sertIsInstance(a,b):实例对象 isInstance(a,b) 3.2 sertNotIsInstance(a,b) not isInstance(a,b) 3.2
-
二十六. python2 vs python3
26.1 print
- Python2中print为class, Python3中print为一个函数
26.2 range与xrange
- range()在python2中会得到一个列表, 在Python3中会得到一个range生成器
- python2中xrange()得到的是一个生成器, python3中改为了range()
26.3 字符串
- Python2中存储字符串, 是使用8bit字符串存储方式
- python2 底层使用ASCII编码的方式, 所以字符串有两种不同的方式str和unicode
- python3使用的是utf8编码
26.4 异常处理
-
Python2中的异常处理语法
try: ... except Exception, e: ... -
python3中异常处理语法
try: ... except Exception as e: ...
26.5 打开文件
- python中打开文件
- f=file()
- f=open()
- python3中打开文件
- f=open
26.6 标准输入
- python2输入
- res = raw_input()
- res = input()
- python3标准输入
- res = input()
26.7 除法运算
- python2 中 /表示的是整除, 但是加上浮点数就是真实除法
- python3 中, /表示的就是真实除法, //表示整除
26.8 自定义类
- python2 中保留了原始的类型继承关系和经典类, 同时也支持继承object二衍生的新式类, 所以再多继承中会出现两种不同的数据检索方式, 让大中型项目的开发变得扑朔迷离
- python3中废弃了经典类, 只保留了新式类, 也就是现在我们通用的自定义类型, 直接或间接继承object
二十七. linux
27.1 概述
操作系统简称OS是架构在硬件基础上的系统软件, 主要用于管理计算机资源和软件资源的计算机程序, 操作系统的主要职责就是调度硬件资源和CPU、内存、硬盘等完成软件程序的数据运算, 同时调度输入设备、输出设备完成和用户之间的交互过程
27.2 发展历史
- 创始人: 拉瓦兹,莱纳斯, 主要受到Minix和Unix的思想启发
- 1991年发布
27.3 系统特性
- 安全免费
- 多用户, 多任务
- 支持多种硬件平台
- 安全性和稳定性高
- linux内核版本号:6.12.13
- 主版本号 : 第几大版本
- 次版本号: 奇数表示开发测试版, 偶数表示稳定版
- 末版本号: 修改版本号, 做过第几次修改
27.4 系统目录
- /:根目录,所有文件的跟
- home:一般存储的是普通用户的用户目录
- bin:可执行的命令
- etc:配置信息
- root:管理员的用户目录
- var:一般存储日志文件
- usr:软件的默认安装目录
- sbin:只有管理员可以运行的命令,一般在此目录下
- opt:系统给用户预留目录, 或者自定义安装一些软件一般选择安装在此目录下
27.4 命令操作
命令的基本格式: 命令 【-选项】【参数】
-
帮助命令
- help或-h:用于查看指定命令的帮助信息,主要查看系统内置命令
- 例如: ls --help
- man:和help相似,主要用于查看外部命令
- 例如:man kill
- which: 用于查看指定命令在文件系统环境变量中的位置
- 例如:which 命令
- whereis: 用于查看指定命令在文件系统中的位置
- 例如:whereis 命令
- help或-h:用于查看指定命令的帮助信息,主要查看系统内置命令
-
系统常见命令:
-
clear: 清屏, 快捷方式:ctrl+l
-
ls:用于查看指定路径下的文件
- -a:用于查看路径下所有文件,包含隐藏文件
- -l:列表方式查看文件信息,包含文件权限、所属用户、组,文件大小以及文件名称
-
pwd:用于打印展示当前目录所在的路径
-
cd : 用于在命令行切换不同的路径
- cd /:进入系统根目录
- cd ~:进入系统当前用户目录
-
ifconfig : linux系统中查看网卡网路信息的命令
-
poweroff:关机命令
-
reboot:立即重启计算机
-
shutdown:关机命令
- shutdown -r now : 立即重启系统
- shutdown -r 10:10分钟后重启
- shutdown -r 20:35:指定时间重启
- shutdown -h now:立刻关闭计算机
- shutdown -h 10:10分钟后重启
- shutdown -c:取消shutdown命令执行操作
-
grep:用于过滤搜索特定字符,常配合管道命令使用
- -i:忽略字符大小写
-
|:管道
- 管道命令,将一个命令的输出结果,作为第二个命令的输入,经常和其他命令结合使用
-
find:查找文件
- find / -name “文件名”:通过文件名查找文件
- find / -size +5M: 通过文件大小检索文件
- find / -amin -10:查找系统中最后10分钟访问的文件
- find / -atime -2:查找系统中最后48小时访问的文件
- find / -empty : 查找系统中为空的文件后者文件夹
- find / -user python : 查找系统中属于python这个用户的文件
-
echo :用于在界面上显示后续的提示信息, 经常用来和定向符>一起使用创建文件
-
-
文件操作命令
文件操作命令,主要用于文件/目录的管理,包含文件的创建、重命名以及删除,文件夹的创建,重命名以及删除,文件/目录的复制、剪切等
- touch:用于创建一个空白文件, 通过指定选项可以修改已有文件的访问时间
- cp:用于将一个指定的目录,复制到目标目录
- -r: 用于赋值文件夹
- cp在赋值过程中可以改名,所以我们在实际工作中,有些文件在编辑之前需要先备份, 一般使用cp用文件备份 一般本分文件的名字 .bak结尾
- mv:用于将一个文件移动到另一个指定位置,经常用于文件的剪切和重命名
- mkdir:用于创建目录/文件夹
- -p:可以递归创建文件夹
- rm:用于删除文件/目录
- -r选项:删除指定路径中的目录
- -f选项:忽略文件提醒,直接删除
-
文件内容查看命令
-
cat 查看文件内容
- cat file 全文本浏览
- cat -n file 带行号文本浏览
- cat file1 file2 合并文本
-
head 头部浏览,查看文本文件头部内容,默认查看10行
- head -n 100 file 显示文件前100行内容
- head -n -100 file 显示文件最后100行以外的内容
-
tail 查看文本文件尾部内容, 默认查看10行
- tail -100 file 显示最后100行内容
- tail -n +100 file 从100行开始显示内容
- tail -100f file 显示最后一百行内能, 并且持续监控文件内容, 一本用于监听日志文件
-
more 分页查看
-
more file 分页查看文件能容
-
more +n file 设定从第n行开始显示file内容
-
more +/string file 从包含string的前两行开始显示
述 下滚动一页内容 向上滚动一页内容 下滚动一行内容 退出浏览 展示当前行号 展示当前文件名和当前行号
-
-
less 分页浏览文件内容, 类似more命令
-
less file 分页浏览file
-
less -N file 分页浏览file,并展示行号
-
less -m file 分页浏览file, 并显示百分比
描述 向前滚动一页 向后滚动一页 向前滚动一行 向后滚动一行 移动到最后一行 移动到第一行 ng ng 退出
-
-
sort 排序浏览, 将以默认的方式将文本文件的第一列以ASCII码的次序排列, 默认升序
- sort file 默认升序查看文件内容
- sort -r file 降序查看文件内容
- sort -u file 剔除文本文件中重复的内容
- sort -n file 按照数字顺序排序
-
sed 是一个流式编辑器功能非常强大
-
打印包含string字符的行
sed -n "/string/p" file -
获取指定行内容
sed -n '1,5p' file # 打印第1-5行内容 sed -n "3,5{=;p}" file # 打印第3-5行, 并且打印行号 sed -n "10p" file # 打印第十行内容
-
-
-
压缩命令
压缩解压缩在操作系统中一般称之为文件归档,也就是按照某种指定格式将文件整理出来
-
tar:可以将多个文件打包成一个文件,也可以将打包的文件拆分为多个文件
-
-c 创建归档文件(用于归档)
-x 解压(用于解压)
-v 显示归档过程(可选)
-f 指定文件(必须写,必须写在其他参数后面)
-t 查看归档文件中所有文件(了解)
-z 是指定解压缩的方式为 gzip 的编码方式 解压缩文件
-J 指定解压缩方式为xz 的编码方式 解压缩文件
-
tar -cvf target.tar file1 file2 :将多个文件打包成target.tar文件
-
tar -tvf target.tar:查看target.tar包文件中包含的文件列表
-
tar -xvf target.tar: 将target.tar包中的文件释放到当前目录
-
-
gzip:按照比例将文件进行压缩的命令, 通常和tar归档命令一起使用,有tar归档,gzip将这个归档的文件进行整理
- 压缩:gzip 文件.tar
- 解压缩:gzip -d 文件.tar.gz或者gunzip 文件.tar.gz
- 注意: gzip命令不能压缩目录
-
bzip2:用于文件压缩操作的常见命令
- 压缩:bzip2 -k 文件.tar
- 解压缩: bzip2 -d 文件.tar.bz2 或者bunzip 文件.tar.bz2
-
zip : 用于通用压缩,主要和windows操作系统平台之间的通用压缩格式
- 压缩: zip -r 压缩后的文件名 要压缩的文件
- 解压缩: unzip 压缩文件
-
xz: 命令也是一个文件打包压缩时经常遇到的命令,经常和tar命令一起使用
- 压缩: xz -z 归档文件.tar
- • 解压缩:xz -d 压缩文件.tar.xz
-
-
权限管理命令

- chmod u+x/g+w/o+r 文件
- u表示用户
- g表示组
- o表示其他用户
- chmod u+x/g+w/o+r 文件
-
用户管理命令
- useradd 新用户 : 添加用户,要使用root用户
- userdel 用户 : 删除用户,要使用root用户
- 默认只删除用户和密码,不删除用户文件
- -r: 移除家目录中的用户文件
- passwd 用户: 修改指定用户的密码
-
系统管理命令
- free -h : 查看内存使用情况
- df -h : 查看磁盘使用情况
- top命令:用于查看当前系统中的所有工作进程的信息
- ps : 用于查看和检索指定进程的信息
- a : 显示一个终端所有的进程
- x: 显示没有控制终端的进程
- u: 选择有效用户
- f: 全部列出
- USER: 用户名
PID: 进程ID(Process ID)
%CPU: 进程的cpu占用率
%MEM: 进程的内存占用率
VSZ: 进程所使用的虚存的大小(Virtual Size)
RSS: 进程使用的驻留集大小或者是实际内存的大小,Kbytes字节。
TTY: 与进程关联的终端(tty)
STAT: 进程的状态:进程状态使用字符表示的(STAT的状态码)
TIME: 进程使用的总cpu时间
COMMAND: 正在执行的命令行命令
- kill : 命令用于结束指定的进程, 一般配合 -9 强制杀死进程
-
软件管理命令
- yum : yum 命令是在 Fedora 和 RedHat 以及 SUSE 中基于 rpm 的软件包管理器,它可以使系统管理人员交互和自动化地更细与管理 RPM 软件包,能够从指定的服务器自动下载 RPM 包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软体包,无须繁琐地一次次
- 安装操作
yum install #全部安装
yum install package1 #安装指定的安装包package1 - 更新操作
yum update #全部更新
yum update package1 #更新指定程序包package1
yum check-update #检查可更新的程序
yum upgrade package1 #升级指定程序包package1 - 查找操作
yum info package1 #显示安装包信息package1
yum list #显示所有已经安装和可以安装的程序包
yum list package1 #显示指定程序包安装情况package1
yum search #查找软件包 - 删除程序
yum remove#删除程序包package_name
yum deplist package1 #查看程序package1依赖情况
27.5 计划任务
-
突发性任务 atd 临时性的一次性的,只执行一次
-
查看任务是否启动
systemctl status atd -
编辑突发任务
-
min: 分钟
-
days : 天
-
17:00 2020-9-5 指定年月日和时分去执行任务
-
例如:
at now+1min 一分钟后执行
at 15:00 下午3点执行
-
-
快捷键
- ctrl + d 保存任务
- ctrl + c 编辑过程中撤销任务
- at -l 查看当前所有突发任务
- atrm 任务id 删除执行突发任务
-
-
定时任务 crontab
周期性循环执行, 一般用于定期删除日志和备份文件,定期爬取数据
-
查看服务有没有启动
crontab -u root -e- -u 用户名
- -e 编辑
- -l 查看所有的定时任务
- -r 删除所有的定时任务
-
格式
-
* * * * * 要执行的命令 -
六个*分别代表 分 时 日 月 周
-
分钟: 0-59
-
时: 0-23
-
月: 1-12
-
周: 0-7 0和7都代表周日
-
/ 代表频率
-
, 离散的数据
-
如果定时任务执行的脚本有输出,或者脚本有异常,我们在终端是看不到信息的,在/var/spool/mail目录下对应用户的文件中,可以看到输出信息和异常信息
-
案例
-
每天的8:00执行一次 2.py
0 8 * * * python 2.py -
每年的五月一日 10:05 执行一次 2.py
5 10 1 5 * python 3.py -
每天的三点和六点各执行一次2.py
0 3,6 * * * python 2.py -
每天的3点,4点,5点各执行一次2.py
0 3-5 * * * python 2.py -
每天的8:20,9:20,10:20 各执行一次2.py
20 8-10 * * * python 2.py -
每天的3,4,5点 没五分钟各执行一次2.py
60/5 3-5 * * * python 2.py -
每周的周一 10点执行一次2.py
0 10 * * 1 python 2.py
-
-
-
二十八. Vim编辑器
28.1 模式切换
-
命令模式: vim打开文件进入的模式就是命令模式, 其他模式按ESC键进入命令模式
*按键* *描述* x 删除当前光标所在的字符,相当于delete【常用】 X 删除光标前面一个字符,相当于backspace dd 删除光标所在行【常用】 ndd n为数字,连续删除光标后n行【常用】 yy 复制光标所在行【常用】 nyy n为数字,复制光标所在的向下n行 p 将已复制的数据在光标下一行粘贴 P 将已复制的数据在光标上一行粘贴 u 复原前一个动作 G 移动到这个档案的最后一行【常用】 gg 移动到这个档案的第一行【常用】 n回车 n 为数字。光标向下移动 n 行【常用】 -
插入模式: 插入模式一般也称为输入模式, 在命令模式下按i, a …等进入输入模式
按键 描述 a 光标后面插入字符 A 行尾插入字符 i 光标前面插入 I 行首插入字符 o 光标下一行输入字符 O 光标上一行输入字符 -
底线模式: 底线模式也称末行模式,在命令模式下,按 shift+: 进入底线模式,可以进行文件的保存,退出,搜索等操作
指令 描述 :w 保存文件 :w! 强制保存文件 :q 不保存退出文件 :q! 不保存并强制退出文件 :wq 保存并退出文件 :wq! 强制保存并退出文件 :set nu 显示行号 :set nonu 取消行号
二十九. 网络和防火墙配置
29.1 网络配置
-
centos通常会自动分配ip地址,不需要我们自己配置,但是自动分配会导致Ip地址动态变化
-
在开发环境中,通常不需要自动配置, 通过修改配置文件的方式,指定ip地址以及网络配置
-
使用 ifconfig 查看网卡信息
-
编辑配置文件/etc/sysconfig/network-scripts/ifcfg-ens33, 使用管理员权限
-
编辑配置文件/etc/sysconfig/network-scripts/ifcfg-ens33: ( 每个人的最后一个文件可能不太一样)
[python@localhost network-scripts]$ sudo vim /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE=Ethernet PROXY_METHOD=none BROWSER_ONLY=no BOOTPROTO=dhcp DEFROUTE=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_FAILURE_FATAL=no IPV6_ADDR_GEN_MODE=stable-privacy NAME=ens33 UUID=6298ef16-d306-499a-8d81-c5afcffff260 DEVICE=ens33 ONBOOT=yes ~ -
修改自动分配ip为静态分配
- 把 BOOTPROTO=dhcp 修改为 BOOTPROTO=static
-
在VMware虚拟机中点击 编辑—>虚拟网络编辑器
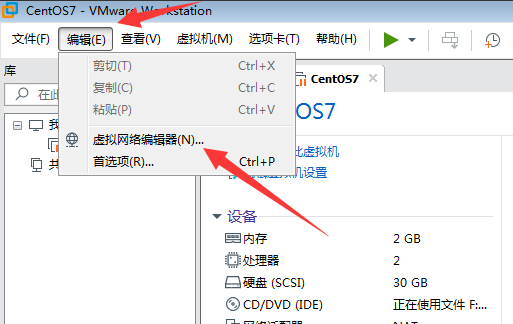-
在打开的虚拟网络编辑器中点击 VMbet8 NAT模式

-
点击NAT设置,

-
在弹出的NAT设置中,找到网关IP复制下来, 然后关闭

-
点击DHCP设置

-
在弹出的DNCP设置中, 查看起始IP地址和结束IP地址,

-
在第一步打开的配置文件最后添加:
-
IPADDR=192.168.48.168 #这个IP地址在起始IP地址的最后三位数和结束IP地址的最后三位数之间, 前面的数字是一样的,根据自己的写
-
DNS1=114.114.114.114 #添加DNS解析,也可以自己在网上收
DNS2=8.8.8.8 #这个是谷歌的DNS解析,可以两个都写,也可以写一个
-
GATEWAY=192.168.48.2 #这个是第六步中网关IP地址
-
-
完整的配置如下:
TYPE=Ethernet PROXY_METHOD=none BROWSER_ONLY=no BOOTPROTO=static # 静态配置IP DEFROUTE=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_FAILURE_FATAL=no IPV6_ADDR_GEN_MODE=stable-privacy NAME=ens33 UUID=6298ef16-d306-499a-8d81-c5afcffff260 DEVICE=ens33 ONBOOT=yes IPADDR=192.168.48.168 # 静态IP地址 DNS1=114.114.114.114 # DNS解析 DNS2=8.8.8.8 # 备用DNS GATEWAY=192.168.48.2 # 网关 -
最后,重启网络配置, 使上面的配置生效
systemctl restart network
-
29.2 防火墙设置
- 关闭防火墙
- systemctl stop firewalld
- 关闭开机启动
- systemctl disable firewalld
- 查看关闭状态
- systemctl status firewalld
三十. ssh服务
30.1 概述
- SSH是专门为远程登录会话和其他网络服务提供的安全性协议
- SSH服务端的进程名是sshd, 负责监听远程客户端连接,并处理
- ssh客户端包含ssh以及scp(远程拷贝), slogin(远程登录) sftp(远程ftp文件传输)
30.2 常用命令
-
查看sshd是否启动
systemctl status sshd -
scp : 主要用于远程文件传输
-
从本地向服务端上传文件
scp 本机文件的路径 用户名@服务端ip:/要上传的路径 -
从服务端下载文件到本地
scp 用户名@服务端ip:/下载的文件路径 本机文件的路径 -
如果要下载文件夹或上传文件夹加 -r 参数
-
30.3 免密码登录
-
在客户端生成密钥对
ssh-keygen -t rsa -
将生成的密钥对上传到服务器
ssh-copy-id 用户名@服务器ip地址 -
免密码登录命令:
ssh -i 本地私钥路径 用户名@ip地址三十一. shell脚本
shell编程就是通过终端编写的脚本程序,辅助开发人员完成命令的工程自动化操作
shell编程语言是一个解释性执行的编程语言
31.1 shell脚本的基本语法
- 脚本编写规范
- shell脚本程序是linux系统中的一种特殊文件
- 属于用户的脚本程序,全部放在指定的路径的scripts目录下
- 脚本第一行使用: #!/bin/sh 或者 #!/bin/bash 指定程序的执行者
31.2 第一个脚本程序
- # : 表示注释, 第一行#/bin/sh内容不是注释
- echo : 标准输出, 类似于python中的print()
- echo -n 输出信息 #不换行输出
- read : 标准输入, 读取用户从键盘输出的信息
- read 变量名 # 不带提示信息
- read -p 变量名 # 带提示信息
- read -s -p 提示信息 变量名 # 带提示信息, 输入信息不回显
- 运行shell脚本的两种方式
- 在当前脚本同级目录下 ./文件名.sh 需要给文件添加执行权限
- 使用命令方式执行: sh ./文件名.sh
31.3 变量
-
变量就是一个标识符, 有特殊的意义
-
由数字字母下划线组成, 不能以数字开头
-
变量必须先声明, 后使用
-
变量名不要使用特殊符号, 不要以$开头, 不能以关键字命名
-
在使用变量的时候后面不能直接跟字母
-
声明变量的格式
- $变量名
- ${变量名}
-
案例:
read -p '请输入账号:' username read -p '请输入密码:' password echo "您的账号是$username" echo "您的密码是$pwd" name="李四" echo "I am ${name}abc"
31.4 程序控制结构
-
if : 选择结构
-
单分支基本语法
if 条件 then 要执行的代码块 fi -
双分支语法结构
if 条件1;then 条件为真时要执行的代码块 else 条件不为真时要执行的代码块 fi -
多分支
if 条件1;then 条件1为真实执行的代码 elif 条件2;then 条件2为真实要执行的代码 else 条件都不成立时要执行的代码 fi
-
31.5 文件判断
-
-e 判断文件是否存在if [ -e 文件路径 ] -d 判断是否是文件夹if [ -d 文件路径 ] -f 判断是否文件if [ -f 文件路径 ] -r 判断文件是否是可读 -w 判断文件时都是可写的 -x 判断文件是否可执行 -
案例: 给定一个路径判断路径是否存在, 存在判断是否是文件夹,是文件夹执行备份,不存在创建该目录
#!/bin/sh bpath="/root/" cd $bpath if [ -d './back' ] then echo "开始执行备份" cp -r ./back ./back.bak else echo "目录不存在,创建目录" mkdir back fi
31.6 字符串判断
| =/== | 判断两个字符是否相等[ $a = $b ] |
|---|---|
| != | 判断两个字符是否不想等 |
| -z | 判断字符串长度是否为0 如果为0返回true[ -z $变量 ] |
| -n | 判断字符串是否不为空 不为空返回true[ -n “$变量” ] |
-
案例:1. 根据用户输入的选项, 判断不是就退出程序
#!/bin/sh read -p "请输入用户名:" username read -p '请输入密码' pwd if [ $username = '1' ];then echo "登录" elif [ $username = '2' ];then echo "注册" elif [ $username = '3' ];then echo "退出" else echo "没有这个选项" fi -
案例: 2. 提示用户输入用户名判断是否为空
#!/bin/sh read -p "请输入用户名:" username read -p '请输入密码' pwd if [ -z $username ];then echo "您的账号为空" else echo "你的账号没用问题" fi
31.7 数值比较
| -eq | = [ $a -eq $2 ] |
|---|---|
| -gt | > |
| -lt | < |
| -ge | >= (( $a >= $b )) |
| -le | <= |
| -ne | != |
-
案例:
#!/bin/sh if [ 1 -eq 1];then echo "ok" fi if ((1 == 1));then echo 'ok' fi if ((1 > 2));then echo "ok" fi
31.8 逻辑判断
| && | 并且关系 and [[]] |
|---|---|
| -a | 并且关系 [] |
| || | 或者关系 or |
| -o | 或者关系 |
| ! | 取反 |
-
案例: 判断用户名和密码是否正确
#!/bin/sh read -p "请输入账号" username read -s -p "请输入密码" pwd if [ $username = "zs" -a $pwd = 'admin' ];then echo "账号密码正确" fi if [[ $username = "zs" && $pwd = 'admin' ]];then echo 'ok' fi
31.9 case 分支语句
-
基本语法格式
case 变量 in 值1|值2) 要执行的代码 ;; 值3|值4) 只要执行的代码 ;; *) 上面的条件都不成立的时候执行 esac -
案例
#!/bin/bash read -p "请选择您的选项1)登录.2)注册" msg case $msg in 1) echo "登录" ;; 2) echo "注册" ;; *) echo "您输入的选项不存在" esac
31.10 循环语句
-
for循环格式
for 临时变量 in 数据 do 循环体 done- 案例:
#!/bin/sh ips='127.0.0.1 192.168.48.1 10.10.123.137' for i in $ips do echo $i sleep 1 done -
while循环格式
while 条件 do 循环体 done
31.11 数字运算
- 整数运算
- expr 运算表达式: sum=`expr 1 + 1`
- $(())运算符 : res=$(( 1 + 2 ))
- $[]运算符: res=$[ 1 + 2 ]
31.12 数组
存储一组数据的容器
- names=(‘a’ ‘b’ ‘c’)
- 直接echo names 只返回第一个数据
- echo ${names[@]} 获取所有的值 ‘a’ ‘b’ ‘c’
- echo ${names[*]} 获取所有’abc’
- echo ${names[1]} 通过索引获取指定的值
- echo ${#names[@]} 获取数组的长度
31.13 shell函数
-
格式
# 方式一 function 函数名(){ 代码段 } # 方式二 函数名(){ 函数中的代码段 } 函数的调用 函数名 -
函数执行需要传参,不要在函数的后面的括号中,添加形参,shell中函数的参数有自己的传递方式
-
# 函数的传参 函数名 参数1 参数2 参数3 # 接受参数的方式 $0 接受当前文件名称 $1 接受到的第一个参数 $2 接受到的第二个参数 ${10} 10以上的参数需要加{} $@ 表示接受到的所有参数 “1” “2” $* 接受到的所有参数 “1 2 ..” $# 表示接受的参数个数 -
案例:
#!/bin/sh function test(){ echo -n $1 echo -n $2 echo ${10} } test 你好 啊 a d f g h j o p # 结果是 你好啊p
31.14 案例
-
使用shell脚本备份指定目录下的所有日志文件
用户要指定一个路径
判断用户输入的路径存在不存在
将当前路径下的要备份的日志 打成tar包, tar包名字以当前的日期命名
判断一下当前路径中是与有 back目录
如果目录存在 我们将tar包移动到back目录下
如果目录不存在创建目录
#!/bin/sh
# 检测用户输入的参数
if [ $# -ne 1 ];then
echo "您的参数不合法,需要传递一个参数(备份的路径)"
exit
fi
# 判断用户输入的地址存是否是文件夹
if [ ! -e $1 ];then
echo "您输入的路径不存在"
exit
fi
if [ ! -d $1 ];then
echo "您输入的不是一个目录"
exit
fi
# 可以打tar包
bname=back_`date +%Y_%m_%d`.tar
# 打包
cd $1
tar -cf $bname ./*.log
# 判断当前路径下有没有back目录
#if [ -d ./back ];then
# mv $bname ./back/
#else
# mkdir ./back
# mv $bname ./back/
#fi
if [ ! -d ./back ];then
mkdir ./back
fi
mv $bname ./back
三十二. git版本控制器
32.1 概述
- git版本控制器就是一个版本控制软件
- 能够将多个开发人员按照版本的形式进行登记
- 方便多人开发代码的合并, 方便问题的排查
- 主流的版本控制软件
- SVN: 集中式的版本控制软件
- 开发中如果是离线状态,SVN不能支持离线版本管理,导致离线状态下不能正常开发
- GIT: 分布式版本控制软件
- 每个人都有一个独立的版本库, 即使在离线状态下, 也可以完成版本管理
- 特点:
- 集中式: 只有一台服务器是版本服务器
- 分布式: 每个人的电脑都是一个版本服务器
- SVN: 集中式的版本控制软件
32.2 git的工作流程
- 本地
- 工作区: 文件的 增删改查
- 暂存区: 记录小节内容
- 版本库: 将暂存区的内容提交到版本库生成新的版本
- 开发完成后将本地的版本库提交到远程服务器
- 服务器:
- 代码托管
- 代码托管平台
- github: 全球最大的开源社区网站
- gitlab: 企业使用较多
- 码云: 国内开源社区
32.3 创建远程创库
- 在以上平台上创建账号,并创建仓库
32.4 连接远程仓库
-
使用ssh连接, 需要配置密钥
-
在本地生成密钥对
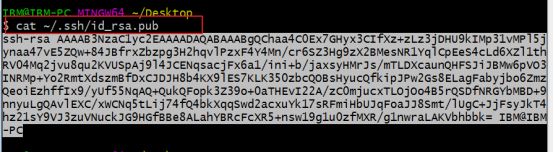
ssh-keygen -t rsa -
将本地的公钥配置到远程服务器, 将生成的公钥配置到远程,以github为例



-
使用ssh连接将远程仓库下载到本地, 在本地的git客户端执行
git clone ssh创库地址

-
32.5 版本管理
-
本地用户配置
git config -global user.name '自己的名字' git config -global user.name '自己的邮箱' -
进入到版本仓库目录
-
创建1.py文件并编写内容
-
执行git status 查看当前版本库中所有文件的状态

-
git add 添加文件到暂存区
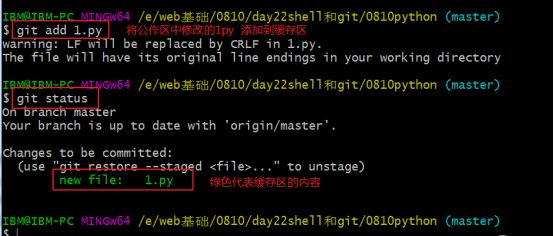
- git commit -m “描述” 文件名,提交指定的数据,生成新的版本


-
git push 将代码推送到远程仓库, 方便其他开发人员下载开发
-
git diff 查看新增的代码对于那些文件做了修改
-
git log/reflog 查看提交李四信息
-
代码回滚
git reset --hard 版本号
- 代码一旦回滚,理论上新提交的版本会被删除, 理论上是找不回来的,但是如果知道版本号,是可以找回来的
- 工作区修改代码回退

- 将暂存区的文件撤销到工作区

32.6 分支管理
-
git提供了分支操作,通过不同的分支,完成不同的功能,将不同的分支可以合并到一个完成的产品中
-
master分支:比较完整的随时可发布,注意永远不要在 master 分支上直接开发和提交代码,确保 master 上的代码一直可用
-
develop分支:平时开发的主分支,功能最新最全的分支
-
feature分支:主要是用来开发新的功能
-
release分支:发布准备的专门分支
-
hotfix分支:修复线上代码的bug
-
-
分支的操作
-
查看当前版本库所有的分支
git branch -
添加一个新的分支
git branch -
切换分支
git checkout -
删除一个分支
git branch -d -
合并分支
git merge 分支名
-
-
分支冲突
- 合并分支,两个认知同时修改了同一文件的同一行内容,合并时会出现冲突
- 出现这种问题需要手动解决,解决方法:
- 把它删掉
- 把自己的删掉
- 两个内容都保留
32.7 本地仓库关联远程创库
-
创建本地仓库
git init -
本地仓库关联远程仓库
git remote add origin 仓库地址 -
同步仓库信息
git remote --rebase origin master -
移除指定连接
git remote remove origin
三十三. mysql数据库
33.1 数据库概述
- 数据库就是一个存放应用软件数据的仓库,这个仓库是按照一定的数据结构来对数据进行组织和存储的,并给用户提供了新增、查询、更新、删除等操作,更方便我们对数据进管理
- 持久化存储: 只要是数据库必须可以持久化存储数据
33.2 数据库专业术语
- DBMS(DataBase Managerment System): 数据库管理系统,安装在数据库服务器上的应用软件,主要用于管理服务器上的数据库和数据的增删改查
- DBA(DataBase Administrator): 数据库管理员,可以使用自己的账号登录DBMS,通过人工干预的方式完成数据库的维护工作
- DB(DataBase): 数据库,负责具体存储和管理应用程序中的数据的实体对象。
- SQL(Standand Query Language):结构化查询语言.标准查询语句,是一种语法结构,专门用于操作数据库而定义的一种语言,包含以下几个内容
- 结构化查询语句主要用于关系型数据库的数据操作
- 数据定义语句(DDL:data definition language)主要用于创建/删除 库和表的操作
- 数据操作语句(DML:data manipulation language)主要用于增删改查具体数据
- 数据库控制语言DCL(data control language)主要是用来设置或更改数据库用户或角色权限的语句
33.3 数据库分类
- 关系型数据库
- 关系型数据库采用了关系模型来组织数据的数据库, 其以行和列的形式存储数据
- 关系型数据库这一系列的行和列被称为表,一组表组成了数据库
- 以二维表的形式存储数据
- 一个DBMS软件可以管理多个库
- 一个库中可以有多张表
- 一张表中有多条数据
- 非关系型数据库nosql , 不仅仅是sql
- 以key:value形式存储数据
- 一般用于缓存数据
- 优点
- 关系型数据库
- 易于维护,:使用表结构, 格式统一
- 使用方便: sql语言是通用的可以用于复杂查询
- 关系型数据库
- 格式灵活: 以key : value形式存储数据, 每一条数据哥还是都可以是不一样的数据
- 成本低: 部署简单, 一般都是开源的
- 关系型数据库
- 缺点
- 关系型数据库
- 读写能力差: 特别是海量数据, 数据越多读取效率越低
- 固定表结构: 灵活性差
- 高并发读写很难打破瓶颈, 硬盘限制
- 非关系型
- 不支持sql语句:学习成本高
- 数据结构复杂
- 关系型数据库
33.4 数据库的安装
- https://blog.csdn.net/lingyingdon/article/details/108475449
33.5 数据库操作
-
sql语法规则
- 每条sql语句要以
;结尾 - 在文档中一般关键字使用大写, 但是执行时不区分大小写
- 每条sql语句要以
-
连接数据库
如果需要使用mysqlDBMS软件,先连接在登陆
-
完整连接方式
mysql -uroot -P3306 -hlocalhost -p- -u 指定使用什么用户进行登录 root 默认超级管理员用户
- -P 指定链接mysqlDBMS软件服务的端口号
- -h 指定mysql软件服务器的地址 localhost 代表的是本机
- -p 指定密码
- 链接本地的mysql服务可以省略 -h 如果本地服务使用的是默认端口号-P也可以省略
-
本机连接登录
mysql -uroot -p
-
-
操作库
-
查看当前mysql中所有的数据库
SHOW DATABASES; -
创建数据库
CREATE DATABASE 库名 CHARSET=utf8; -
切换数据库
USE 库名;- MYSQL结构,数据存在表中,表在库中,所以如果要操作数据,必须进入数据库
-
查看当前所在的库
SELECT DATABASE() -
删除数据库
DROP DATABASE 库名;
-
-
表操作
-
查看当前库中所有的表
SHOW TABLES; -
创建表
CREATE TABLE 表名(字段1 类型,字段2 字段类型...)CHARSET=UTF8MB4; -
查看建表语句
SHOW CREATE TABLE 表名; -
查看表结构
DESC 表名; -
删除表
DROP TABLE 表名;
-
-
表结构操作
-
添加字段
ALTER TABLE 表名 ADD 字段名 类型 [约束]; ALTER ABLE 表名 ADD 字段名 类型 [约束] FIRST; # 在最前面添加 ALTER TABLE 表名 ADD 字段名 类型 [约束] AFTER 指定字段名; # 在指定字段名后添加 -
修改字段
-
modify: 只能修改字段类型和约束
ALTER TABLE 表名 MODIFY 字段名 类型 约束; -
change : 既可以修改字段名也可以修改字段类型和约束
ALTER TABLE 表名 change 字段名 新字段名 类型 约束只改名字类型和约束要原样写
若果改类型字段名和新字段名一样
-
-
删除字段
ALTER TABLE 表名 DROP 字段名 -
重命名数据表
ALTER TABLE 表名 RENAME AS 新表明;
-
33.6 数据类型
-
数值类型
int 4字节 TINYINT 1字节 FLOAT 4字节 float(6,2) DECIMAL decimal(6,2) -
字符串类型
CHAR 定长字符串 VARCHAR 变长字符串 TEXT 文本 # 不能设置默认值- 在使用字符串类型的时候必须制定字符串的个数
-
时间日期
DATE 年-月-日 TIME 时:分:秒 datetime: 年-月-日 时:分:秒
33.7 约束
not null 非空约束
default 设置默认值
unsigned 无符号(只能存正数)
primary key 主键约束 唯一且不能为空
auto_increment 自增约束 一般配合主键使用
unique 唯一约束 数据唯一 可以为空
foreign key 外键约束,用来描述一对多关系的,保证两张表的统一性
33.8 数据的增删改查
-
增加数据
-
单条数据
INSERT INTO 表名(字段名1,字段2...) VALUES(值1,值2....); -
多条数据
INSERT INTO 表名(字段名1,字段2...) VALUES(值1,值2....),(),()...;
-
-
删除数据
-
全表删除
TRUNCATE 表名 # 删除表中所有数据,并重置自增 -
指定条件删除
DELETE FROM 表名 WHERE 条件; -
注意: 删除时必须添加where条件,如果不加就会被全部删除
-
-
修改数据
-
格式
UPDATE 表名 set 字段名=值 where 条件; -
注意: update 更新数据必须添加where条件,如果不添加所有的数据都被修改
-
-
查询数据
-
查询全表数据
SELECT * from 表名; -
where条件查询
SELECT * from 表名 WHRER 条件; -
多条件查询
select * from 表名 where 条件1 and 条件2 ; select * from 表名 where 条件1 or 条件2; -
空值查询
select * from 表名 where 字段名 is null; select * from 表名 where 字段名 is not null; -
范围查询
select * from 表名 where 字段名 between 开始值 and 结束值; -
in查询
select * from 表名 where 字段名 in (值1,值2,值3....); -
模糊查询
-
_ : 1位任意字符
-
%: 任意位的任意字符
select * from 表名 where 字段名 like ‘%/_’; -
聚合查询
-
count()用于计数
-
sum() 求和
-
avg() 求平均值
-
max()求最大值
-
min()求最小值
-
分组查询
select * from 表名 [where] group by 字段名 having 条件; -
having类似于where, 但是where不能写在分组后面
-
having专门是用于筛选/过滤分组后的数据
-
分组查询可能会遇到错误,需要在配置文件中添加
```
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGIN
```
-
配置完成后重启服务
-
排序查询
select * from 表名 [where 条件 group by 字段名] order by 字段名 asc/desc; -
asc 升序
-
desc 降序
-
分页查询
select * from 表名 [where 条件 group by 字段名 order by 字段名 asc/desc] limit 跳过前几条数据,取多少条数据 -
查询语句执行流

-
数据去重
select distinct 字段名 from 表名 [where ];
33.9 表关系
-
一对一: 一张表的一条数据,对应另一张表的一条数据
-
例如:
用户表: create table user( id int unsigned auto_increment primary key, name varchar(10) )charset=utf8; 用户详情表: create table user_info( id int unsigned auto_increment primary key, gender int, phone char(13), length varchar(10), u_id int unsigned, foreign key(u_id) references user(id) )charset=utf8;
-
-
一对多: 一张表的一条数据,对应另一张表的多条数据
-
例如:
父亲表: create table parent( id int unsigned auto_increment primary key, name varchar(10) )charset=utf8; 孩子表: create table child( id int unsigned auto_increment primary key, name varchar(10), gender int, p_id int unsigned, foreign key(p_id) references parent(id) )charset=utf8;
-
-
多对多: 一张表的多条数据, 对应另一张表的多条数据
-
例如:
学生: create table students( id int unsigned auto_increment primary key, name varchar(10) )charset=utf8; 老师: create table teacher( id int unsigned auto_increment primary key, name varchar(10) )charset=utf8; 关系表: create table stu_tea( s_id int unsigned, t_id int unsigned, foreign key(s_id) references students(id), foreign key(t_id) references teacher(id) )charset=utf8;
-
33.10 多表查询
-
嵌套查询: 将一个查询语句作为另一个查询语句条件去使用
-
格式:
select * from 表名 where 字段名 in (select 字段 from 表名);
-
-
关联查询
-
where关联查询, 通过where去关联外键
-
只能关联两张有关联的数据
-
格式:
select * from 表1,表2 where 关联条件
-
-
链接查询
-
内连接
select * from 表1 inner join 表2 on 关联条件 where 条件;- 内连接查询只能查询出有关联的数据
-
左外连接查询
select * from 左表 left join 右表 on 关联条件 where 条件;- 以左表为主表,将左表中的所有数据查询出来向右表进行匹配,如果右表没有对应的数据,以null填充
-
右外连接
select * from 右表 left join 左表 on 关联条件 where 条件;- 以右表为主表, 将右表所有的数据查询出来,向左表匹配,如果左表没有对象应的数据,以null占位
-
33.11 事务
-
概述
将一组有序的增删改操作,当做一个独立的执行单元,如果这一组操作中有一个执行失败,整个事务则失败,自动执行回滚操作,当这一组操作都执行成功的情况下,事务则成功
-
数据库引擎
数据库引擎是数据库底层构架的核心负责底层数据持久化和软件交互的序列化操作, 核验过程以及交互过程,通过数据库的存储引擎完成创建,查询,更新和删除操作,当我们访问和数据库数据是都是通过数据库引擎去访问数据文件
- InnoDB引擎
- 优点: 支持事务, 支持外键, 支持行级锁, 主要应用于数据安全
- 缺点: 相对效率低
- MyISAM
- 优点: 拥有较高的插入,查询速度
- 缺点: 不支持事务和外键
- InnoDB引擎
-
事务的特性
事务在操作过程中,为了保证数据的批量操作过程中数据的安全性, 指定了一些事务本身必备的特性
- 原子性: 一个事务是不可分割的,事务中有一个操作失败,整个事务执行失败,自动回滚
- 一致性: 主要描述事务的状态, 事务执行前和执行后的状态保持一致
- 隔离性: 当多个用户并发访问时,系统会给每一个线程开启一个事务,事务与事务之间相互隔离互不影响
- 持久性: 一旦事务提交,事务对数据的操作,将会永久性的存储在数据库中
-
事务并发问题: 在不考虑隔离性的情况下,可能会出现以下三种情况
- 脏读
- A事务读取了B操作的数据中未提交的数据, B事务完成操作之后没有提交,执行力回滚,A读取到的数据就是脏数据
- 不可重复读
- A重复读取一条数据,B事务更新了这条数据, 并提交了事务,导致A两次读取的数据不一样
- 幻读
- 有两个事物A和B, A读取了一张表的数据之后, B插入了一些数据,A再次读取就会出现一些数据
- 不可重复读和幻读的区别
- 不可重复读是更改,幻读是添加数据
- 脏读
-
事务的隔离级别
-
Read Uncommitted(读未提交)
-
只对修改数据的并发操作做限制, 一个事务不能修改其他事物正在修改的数据,但可以读取其他事物中尚未提交的修改,这些修改如果未被提交,将成为脏数据
-
解决的问题: 可能会出现 脏读 不可重复读 幻读
-
案例:
A开启事务 B开启事务 A更新数据,不提交 B查看数据,发现A未提交的数据 此时如果A回滚事务,B在查看B,B数据发生了变化,这种就是脏读
-
-
Read committed(读已提交)
-
只允许读取已经被提交的数据,如果一个事务修改了某行数据且尚未提交,而第二个事务要读取这行数据的话,那么是不允许的,读取的是未提交前的数据,防止脏读的出现,但是可能会出现不可重复读问题
-
解决问题: 避免脏读
-
案例:
A开启事务 B开启事务 A更新数据,未提交 B查看数据并查询不到A事务更新的数据,解决了脏读问题 A提交事务 B在查看,发现两次查询到的数据不一样,出现了不可重复读
-
-
repeatable read(可重复读)
-
读取期间其他事物不允许更新,就是在开始读取数据时,不在允许修改操作,那么在此事务提交前,其他任何事务的修改都会被阻塞
-
解决问题: 可以避免 脏读 和 不可重复读
-
案例:
A开启事务 B开启事务 A更新数据,未提交 B查看不到A更新的数据 A提交事务 B再次查看,和上次产看到的数据一样 避免的不可重复读
-
-
Serializable(可串行化)
-
所有事务必须串行化执行,只要事务在对表进行查询,那么在此事务提交前,任何其他事务的修改都会被阻塞
-
最高隔离级别
-
案例:
A开启事务 B开始事务 A更新数据 B查看数据时会 阻塞
-
-
隔离级别越高,效率越低
-
-
事务操作
-
设置事务隔离级别
set session transaction isolation level 隔开级别(上面四个) -
开启一个事务
begin; -
提交一个事务
commit; -
回滚一个事务
rollback;
-
33.12 索引
-
定义
- 索引是一种提升查询速度的特殊的存储结构
-
种类
- 普通索引 index: 就是一个普通的索引,可以为空,可以重复
- 唯一索引 unique: 可以为空,不可重复
- 主键索引 primary key: 不可以为空, 不可以重复
- 多列索引: 就是给多个字段添加一个索引
-
优缺点
- 优点
- 提升查询速度
- 通过建立唯一索引保证数据的唯一性
- 缺点
- 索引需要占用更多的物理空间
- 增加了后期的维护成本
- 降低增删改操作的效率
- 索引可以提升查询速度, 是不是添加的索引越多越好?
- 数据量比较大时可以使用索引
- 给经常用于where查询条件的字段添加索引
- 还要考虑当前数据的重复量,如果当前字段数据的重复量大于30%不建议使用
- 数据重复量过大添加索引反而会降低查询速度
- 在使用索引查询数据时,一定遵循最左原则
- 多列索引查询时,要注意字段顺序
- 优点
-
索引的操作
-
添加索引
alter table 表名 add 索引类型 [索引名](字段名) # 用于表建好之后添加 -
查看索引
show index from 表名 -
删除索引
drop index 索引名 on 表名- 删除索引必须先删除主键索引的自增属性
-
-
索引的实现
BTree 索引(B-Tree 或 B+Tree 索引),Hash 索引,full-index 全文索引,R-Tree 索引,但是 MySQL 的 InnoDB 数据库引擎,只支持 B+Tree 索引。
-
HASH索引:
基于哈希表实现,只有精确匹配索引所有的列查询才有效,对于每一行数据,存储引擎会对于所有的索引类列计算一个哈希码,并且hash索引将所有的哈希码存储在索引中,同时索引表中保存指向每个数据的指针
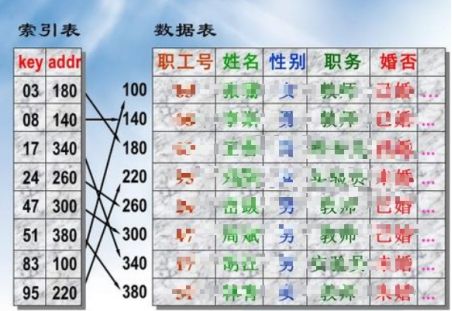
哈希索引能够最快的进行数据定位,对于固定的数据查询效率很高,对于范围性的查询,因为HASH索引的不连续性,查询性能会下降.
-
B-Tree索引:
B-Tree能加快数据的访问速度,存储引擎不在需要全表扫描,数据分布在各个节点之中

B+Trree
-
33.13 视图
-
定义
- 视图是一个虚拟的表,从一个或者多个表中导出来的数据组成的虚拟的表,并不真正存在于库中,作用和真的表是一样的
-
视图操作
-
创建视图
create view 视图名 as sql查询语句 -
使用视图
select * from 视图名; -
查看视图
show table status where comment='view'; -
删除视图
drop view 视图名;
-
-
视图中的数据依赖源表当源表中的数据发生变化时,视图中的数据也会发生变化.
如果源表中的数据删除了,视图中的数据也没了
-
视图的优缺点
- 优点
- 简单: 使用视图的用户完全不同关心后面对应的表结构,关联条件是什么和筛选条件是什么, 对于用户来说,已经是过滤好的符合条件的结构.
- 安全: 使用视图的用户只能访问被允许的查询结构集,数据库提供权限管理并不能限制某一列,通过视图可以简单的实现.
- 数据独立: 一旦视图被创建了,视图的结构不会受到原表结构的变化而变化,当视图创建了,如果在给原表添加字段,也不会对视图造成影响.
- 缺点:
- 性能: 通过视图查询数据速度会很慢,特别是基于视图创建的视图,简单查询存入视图,利用视图查询数据,会变成复杂查询
- 优点
33.14 触发器
也称为触发程序,它的执行不是由程序调用,也不是手工启动,而是****由事件来触发****
当对一个表进行操作(****insert,delete, update****)时就会激活它执行
-
创建触发器
CREATE TRIGGER 触发器的名字 触发时机 事件 ON 表名 FOR EACH ROW BEGIN 要执行的SQL语句 END; -
应用:数据备份,当我们去uname中删除数据时,将删除的数据备份.
1.创建用于备份数据的表 表结构和uname表一样 create table 表名 as select * from 表名 where 1=2; 添加数据: insert into 表名 as select * from 表名; 2.创建触发器 create trigger t_del_uname before delete on uname for each row begin insert into uname_ack values(old.id,old.name,old.age,old.gender,old.phone); end; -
查看触发器
SELECT * FROM INFORMATION_SCHEMA.TRIGGERS; -
删除触发器
DROP TRIGGER 触发器名字 -
在删除事件触发器内部使用 old 可以获取,要删除数据的值
在添加事件触发器内使用new 可以获取我们新添加数据的值
33.15 用户权限管理
-
添加用户
create user '用户名'@'来源地' identified by '密码';-
案例: 创建一个用户ls可以在任意来源地登录
create user 'ls'@'%' identified by '密码'; -
创建一个用户在指定地址登录
create user 'ls'@'IP地址' identified by '密码'; -
创建一个用户在指定ip段登录
create user 'ls'@'10.10.123.%' identified by '密码'
-
-
删除用户
drop user '用户名'@'来源地'; -
授权操作
GRANT 权限 ON 库名.表名 TO ‘用户名’@’来源地’ -
权限回收
REVOKE UPDATE ON *.* FROM ‘用户名’@’密码’ -
修改密码
-
先查看mysql库中的user表中 ,用户是否有密码
select * from user where user="用户名"\G; -
如果有密码需要先将密码重置为空
update user set authentication_string="" where user="用户名" and host=”来源地”; -
重新设置新的密码
alter user "用户名"@"来源地" identified by '新密码';
-
-
密码丢失处理
-
停止mysql服务, 管理员权限打开命令行窗口输入
net stop mysql -
创建一个SQL文件,将修改的密码命令添加到.txt文件中
alter user 'root'@"密码" identified by '新的密码'; -
启动服务器,使用mysqld命令附带 --init-file参数执行命令
mysqld --init-file="创建.txt文件的绝对路劲" --console
-
33.16.存储过程
-
一组完成特定功能的SQL语句集,存储过程在数据库中,经过一次编译后调用时不需要再次编译, 将业务逻辑存储到数据库中
-
业务流程直接封装保存到存储过程中并不友好,业务分布在数据库和代码两个地方后期维护很麻烦,所以目前我们的数据库只用来做存储数据, 业务都放在代码中去处理.
-
基础语法
CREATE PROCEDURE 存储过程的名字() begin 具体的sql语句 end; call 存储过程的名字() # 调用-
基本案例:
CREATE PROCEDURE testa() begin SELECT * FROM user_back; end; -- 调用存储过程 CALL testa() -
存储过程中的变量
-- 存储过程变量 CREATE PROCEDURE testb() begin -- 声明变量 DECLARE username varchar(32) default ‘1’; DECLARE newphone varchar(32); -- 给变量赋值 set username='我是大娃'; SELECT phone into newphone FROM user_back WHERE name="大娃"; -- 查看变量中的数据 SELECT username,newphone; end; -
参数
in 输入 调用存储过程时,传递进去的参数 out 输出 out 存储过程输出给用户的参数,返回的只能是一个变量 inout 输入和输出案例:
-- 存储过程的返回值 CREATE PROCEDURE test2(out res int) BEGIN -- 获取user_back表中平均年龄 SELECT avg(age) into res FROM user_back; select res; END; CALL test2(@num); select @num; --- inout 参数 CREATE PROCEDURE test3(inout res int) BEGIN -- 获取user_back表中平均年龄 SELECT avg(age) into res FROM user_back; select res; END; CALL test3(@num); select @num; --- in 参数 CREATE PROCEDURE test4(in res int) BEGIN -- 获取user_back表中平均年龄 SELECT avg(age) into res FROM user_back; select res; END; set @num=2; CALL test4(@num); select @num;
-
-
流程处理
if 选择结构基本语法 格式: if 条件 then sql语句; end if; case when语句 格式: case 变量 when 值1 then sql语句; when 值2 then sql语句; else sql语句; end case; where循环 while 条件 do sql语句 改变初始值 end while; loop循环 不需要设置初始值 MY_LOOP:loop sql语句 leave MY_LOOP end loop; -
内置函数
concat(s1,s2...) 字符串连接 length(str) 获取字符串长度 abs(x) 绝对值 round(x,y) 四舍五入 now() 获取当前时间 unix_timestamp(date) 返回指定时间的时间戳 date_format(data,str) 将指定时间格式化 from_unixtime(时间戳) 将时间戳转换为格式化时间 datediff(date,date) 返回时间间隔天数 database() 查看当前所在的库名 version() 返回版本号 user() 返回当前登录用户名 inet_aton(ip) 返回表示ip的数字 inet_ntoa(数值) 返回数字对应的ip md5(str) 返回字符串MD5加密的结果
三十四. python连接数据库
34.1 安装第三方模块pymysql
pip install pymysql
34.2. 连接数据步骤
-
导入模
import pymysql -
连接数据库
connect = pymysql.connnect( host="数据库主机ip地址", user="数据库登录用户名", passsword="登录密码", database='要链接的库', port="数据库端口号", charset="使用指定编码链接数据库" ) -
获取游标
cursor = connect.cursor() -
执行SQL语句
ret = cursor.execute() -
获取结果
result = cursor.fetchall() -
退出
cousor.close() connet.close()