InfluxDB基础操作
一、InfluxDB简介
时序数据库InfluxDB版是一款专门处理高写入和查询负载的时序数据库,用于存储大规模的时序数据并进行实时分析,包括来自DevOps监控、应用指标和IoT传感器上的数据
主要特点:
- 专为时间序列数据量身订造高性能数据存储。TSM引擎提供数据高速读写和压缩等功能
- 简单高效的HTTP API写入和查询接口
- 针对时序数据,量身订造类似SQL的查询语言,轻松查询聚合数据
- 允许对tag建索引,实现快速有效的查询
- 数据保留策略(Retention policies)能够有效地使旧数据自动失效
二、安装并配置远程访问
使用Docker进行安装
docker run -d -p 8083:8083 -p 8086:8086 --name my_influxdb influxdb
进入InfluxDB容器
hanxiantao$ docker exec -it my_influxdb bash
打开InfluxDB控制台
root@31f5ad31806f:/# cd /usr/bin/
root@31f5ad31806f:/usr/bin# ./influx
三、时序数据模型
下面我们通过一个例子来看下InfluxDB的数据模型
> show databases
name: databases
name
----
_internal
通过show databases命令查看当前所有的数据库信息,因为是新安装的,所以输出结果中只看到_internal数据库
> create database devops_idc_sz
> show databases
name: databases
name
----
_internal
devops_idc_sz
> use devops_idc_sz
Using database devops_idc_sz
创建并选定数据库devops_idc_sz
> insert cpu_usage,host=server01,location=cn-sz user=23.0,system=57.0
> show measurements
name: measurements
name
----
cpu_usage
> select * from cpu_usage
name: cpu_usage
time host location system user
---- ---- -------- ------ ----
1607760206416219500 server01 cn-sz 57 23
通过insert命令向表cpu_usage中插入一条记录,通过show measurements命令查看数据库devops_idc_sz中当前所有的表信息,再通过select命令查询表cpu_usage中的记录
与传统数据库不同,InfluxDB不需要显示地创建新表,当使用insert语句插入数据时,InfluxDB会自动根据insert数据的格式和指定的表名自动创建新表
时序数据模型:
- 时间(Time):案例中的1607760206416219500,表示数据生成时的时间戳
- 表(Measurement):案例中的cpu_usage,表示一组有关联的时序数据
- 标签(Tag):案例中的host=server01和location=cn-sz,用于创建索引,提升查询性能
- 指标(Field):案例中的user=23.0和system=57.0,一般存放的是具体的时序数据,不会对指标数据创建索引
- 时序数据记录(Point):表示一条具体的时序数据记录,由时间线和时间戳唯一标识
- 保留策略(Retention Policy):定义InfluxDB的数据保留时长和数据存储的副本数
- 时间线(Series):表示表名、保留策略、标签集都相同的一组数据
三、写入和查询
1、InfuxDB API写入和导入数据
1)写入数据
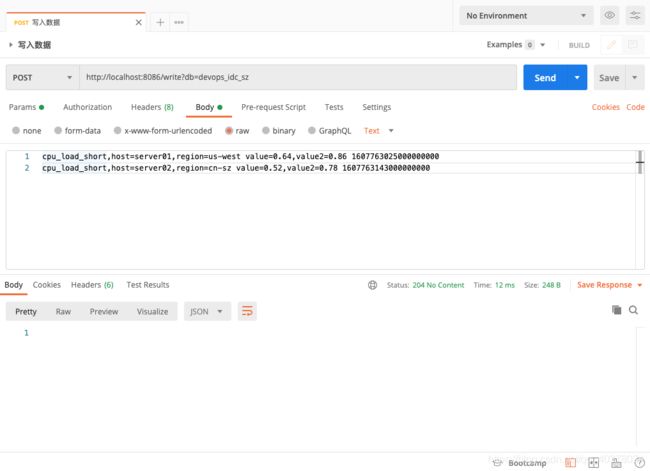
curl -g http://localhost:8086/write?db=devops_idc_sz -d "cpu_load_short,host=server01,region=us-west value=0.64,value2=0.86 1607763025000000000
> cpu_load_short,host=server02,region=cn-sz value=0.52,value2=0.78 1607763143000000000"
查询写入结果:
> select * from cpu_load_short
name: cpu_load_short
time host region value value2
---- ---- ------ ----- ------
1607763025000000000 server01 us-west 0.64 0.86
1607763143000000000 server02 cn-sz 0.52 0.78
如果写入数据时没带上时间戳,InfluxDB会默认使用本地UTC纳秒时间作为写入数据的时间,当需要同时向同一个数据库同一个时间序列线写入多条数据时,每条数据都需要带时间戳,否则后写的数据会覆盖前面的数据
2)导入数据
文件内容如下:
mem_usage,host_name=server1,region=us-west precent=26.79,value=2151672 1607764824000000000
mem_usage,host_name=server1,region=us-west precent=38.21,value=3068883 1607764905000000000
mem_usage,host_name=server1,region=us-west precent=42.66,value=3426290 1607764977000000000
mem_usage,host_name=server2,region=cn-sz precent=6.9,value=554182 1607764983000000000
mem_usage,host_name=server2,region=cn-sz precent=8.1,value=630561 1607765069000000000
mem_usage,host_name=server2,region=cn-sz precent=4.6,value=369454 1607765075000000000
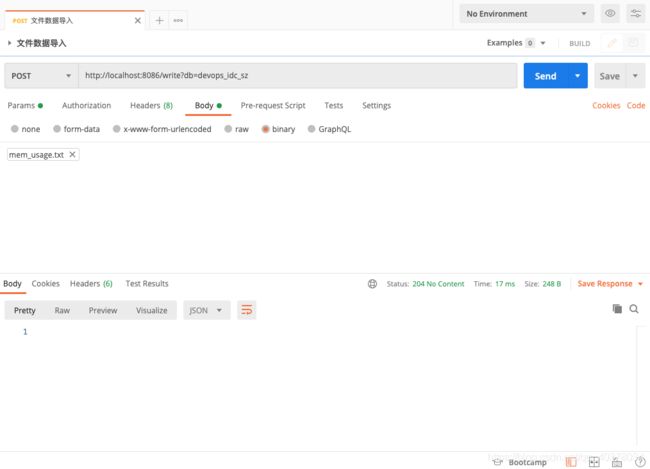
curl -g http://localhost:8086/write?db=devops_idc_sz --data-binary @./mem_usage.txt
查询导入结果:
> select * from mem_usage
name: mem_usage
time host_name precent region value
---- --------- ------- ------ -----
1607764824000000000 server1 26.79 us-west 2151672
1607764905000000000 server1 38.21 us-west 3068883
1607764977000000000 server1 42.66 us-west 3426290
1607764983000000000 server2 6.9 cn-sz 554182
1607765069000000000 server2 8.1 cn-sz 630561
1607765075000000000 server2 4.6 cn-sz 369454
- 默认情况下,InfluxDB API的超时时间为5秒,超时之后InfluxDB仍然会继续将数据写完,但请求方由于已经超时无法知道数据最终是否写入成功
- 当写入数据超过5000个的时候,应使用多次HTTP请求分批写入数据
2、InfluxQL查询
InfluxQL支持使用类SQL的语法进行数据查询,很多用法和MySQL差不多
1)SELECT语句
> select * from mem_usage
name: mem_usage
time host_name precent region value
---- --------- ------- ------ -----
1607764824000000000 server1 26.79 us-west 2151672
1607764905000000000 server1 38.21 us-west 3068883
1607764977000000000 server1 42.66 us-west 3426290
1607764983000000000 server2 6.9 cn-sz 554182
1607765069000000000 server2 8.1 cn-sz 630561
1607765075000000000 server2 4.6 cn-sz 369454
> select precent from mem_usage
name: mem_usage
time precent
---- -------
1607764824000000000 26.79
1607764905000000000 38.21
1607764977000000000 42.66
1607764983000000000 6.9
1607765069000000000 8.1
1607765075000000000 4.6
> select * from mem_usage,cpu_usage
name: cpu_usage
time host host_name location precent region system user value
---- ---- --------- -------- ------- ------ ------ ---- -----
1607760206416219500 server01 cn-sz 57 23
name: mem_usage
time host host_name location precent region system user value
---- ---- --------- -------- ------- ------ ------ ---- -----
1607764824000000000 server1 26.79 us-west 2151672
1607764905000000000 server1 38.21 us-west 3068883
1607764977000000000 server1 42.66 us-west 3426290
1607764983000000000 server2 6.9 cn-sz 554182
1607765069000000000 server2 8.1 cn-sz 630561
1607765075000000000 server2 4.6 cn-sz 369454
2)WHERE语句
> select * from mem_usage where precent > 30
name: mem_usage
time host_name precent region value
---- --------- ------- ------ -----
1607764905000000000 server1 38.21 us-west 3068883
1607764977000000000 server1 42.66 us-west 3426290
> select * from mem_usage where host_name = 'server1'
name: mem_usage
time host_name precent region value
---- --------- ------- ------ -----
1607764824000000000 server1 26.79 us-west 2151672
1607764905000000000 server1 38.21 us-west 3068883
1607764977000000000 server1 42.66 us-west 3426290
时间戳的WHERE子句支持绝对时间和相对时间
> select * from mem_usage where host_name = 'server1' and time > now() - 1d
name: mem_usage
time host_name precent region value
---- --------- ------- ------ -----
1607764824000000000 server1 26.79 us-west 2151672
1607764905000000000 server1 38.21 us-west 3068883
1607764977000000000 server1 42.66 us-west 3426290
3)GROUP BY
GROUP BY子句根据用户指定的标签或者时间间隔对查询结果数据进行分组
> select * from mem_usage where time > '2020-12-12 00:00:00' and time < '2020-12-12 23:59:59' group by host_name
name: mem_usage
tags: host_name=server1
time precent region value
---- ------- ------ -----
1607764824000000000 26.79 us-west 2151672
1607764905000000000 38.21 us-west 3068883
1607764977000000000 42.66 us-west 3426290
name: mem_usage
tags: host_name=server2
time precent region value
---- ------- ------ -----
1607764983000000000 6.9 cn-sz 554182
1607765069000000000 8.1 cn-sz 630561
1607765075000000000 4.6 cn-sz 369454
4)ORDER BY
> select * from mem_usage where time > '2020-12-12 00:00:00' and time < '2020-12-12 23:59:59' group by host_name order by time desc
name: mem_usage
tags: host_name=server2
time precent region value
---- ------- ------ -----
1607765075000000000 4.6 cn-sz 369454
1607765069000000000 8.1 cn-sz 630561
1607764983000000000 6.9 cn-sz 554182
name: mem_usage
tags: host_name=server1
time precent region value
---- ------- ------ -----
1607764977000000000 42.66 us-west 3426290
1607764905000000000 38.21 us-west 3068883
1607764824000000000 26.79 us-west 2151672
5)LIMIT
LIMIT子句用于从指定的查询中返回前N条时序数据记录
> select * from mem_usage where host_name = 'server1' order by time desc limit 3
name: mem_usage
time host_name precent region value
---- --------- ------- ------ -----
1607764977000000000 server1 42.66 us-west 3426290
1607764905000000000 server1 38.21 us-west 3068883
1607764824000000000 server1 26.79 us-west 2151672
6)SLIMIT
GROUP BY SLIMIT
N参数表示返回前N个时间序列线,即GROUP BY分组的前N个
GROUP BY LIMIT SLIMIT
SLIMIT和LIMIT一起使用时,表示从查询结果中返回前N个时间序列线分组,每个分组返回前M条时序数据记录
> select * from mem_usage group by * limit 3
name: mem_usage
tags: host_name=server1, region=us-west
time precent value
---- ------- -----
1607764824000000000 26.79 2151672
1607764905000000000 38.21 3068883
1607764977000000000 42.66 3426290
name: mem_usage
tags: host_name=server2, region=cn-sz
time precent value
---- ------- -----
1607764983000000000 6.9 554182
1607765069000000000 8.1 630561
1607765075000000000 4.6 369454
> select * from mem_usage group by * limit 3 slimit 1
name: mem_usage
tags: host_name=server1, region=us-west
time precent value
---- ------- -----
1607764824000000000 26.79 2151672
1607764905000000000 38.21 3068883
1607764977000000000 42.66 3426290
7)OFFSET
LIMIT OFFSET
OFFSET子句需要结合LIMIT子句使用,表示从查询结果中返回第N条时序数据记录开始的前M条时序数据记录
> select * from mem_usage group by * limit 3
name: mem_usage
tags: host_name=server1, region=us-west
time precent value
---- ------- -----
1607764824000000000 26.79 2151672
1607764905000000000 38.21 3068883
1607764977000000000 42.66 3426290
name: mem_usage
tags: host_name=server2, region=cn-sz
time precent value
---- ------- -----
1607764983000000000 6.9 554182
1607765069000000000 8.1 630561
1607765075000000000 4.6 369454
> select * from mem_usage group by * limit 3 offset 1
name: mem_usage
tags: host_name=server1, region=us-west
time precent value
---- ------- -----
1607764905000000000 38.21 3068883
1607764977000000000 42.66 3426290
name: mem_usage
tags: host_name=server2, region=cn-sz
time precent value
---- ------- -----
1607765069000000000 8.1 630561
1607765075000000000 4.6 369454
8)SOFFSET
GROUP BY SLIMIT SOFFSET
SOFFSET子句需要结合SLIMIT子句使用,表示从查询结果的时间序列线分组中,返回第N个分组开始的前M个时间序列线分组
> select * from mem_usage group by * limit 3 offset 1
name: mem_usage
tags: host_name=server1, region=us-west
time precent value
---- ------- -----
1607764905000000000 38.21 3068883
1607764977000000000 42.66 3426290
name: mem_usage
tags: host_name=server2, region=cn-sz
time precent value
---- ------- -----
1607765069000000000 8.1 630561
1607765075000000000 4.6 369454
> select * from mem_usage group by * limit 3 offset 1 slimit 1
name: mem_usage
tags: host_name=server1, region=us-west
time precent value
---- ------- -----
1607764905000000000 38.21 3068883
1607764977000000000 42.66 3426290
> select * from mem_usage group by * limit 3 offset 1 slimit 1 soffset 1
name: mem_usage
tags: host_name=server2, region=cn-sz
time precent value
---- ------- -----
1607765069000000000 8.1 630561
1607765075000000000 4.6 369454
9)时间语法
绝对时间:
> select * from mem_usage where time = '2020-12-12T09:23:03Z'
name: mem_usage
time host_name precent region value
---- --------- ------- ------ -----
1607764983000000000 server2 6.9 cn-sz 554182
> select * from mem_usage where time = 1607764983000000000
name: mem_usage
time host_name precent region value
---- --------- ------- ------ -----
1607764983000000000 server2 6.9 cn-sz 554182
> select * from mem_usage where time = 1607764983s
name: mem_usage
time host_name precent region value
---- --------- ------- ------ -----
1607764983000000000 server2 6.9 cn-sz 554182
UTC时间 = 北京时间 - 8小时
相对时间:
> select * from mem_usage where time > now() - 12h
name: mem_usage
time host_name precent region value
---- --------- ------- ------ -----
1607817064475612800 server3 7.2 cn-sz 585271
10)函数
聚合函数:
COUNT():返回非空指标值的数量,支持嵌套DISTINCT()子句DISTINCT():对指定指标值进行去重,并返回去重后的指标值数量INTEGRAL():返回指标值去线下的面积,即积分MEAN():返回指标值的平均值MEDIAN():返回排好序的指标值的中位数MODE():返回出现频率最高的指标值。如果有两个或多个值出现次数最多,则返回具有最早时间戳的指标值SPREAD():返回最大指标值和最小指标值的差值STDDEV():返回指标值的标准差SUM():返回指标值的和
查看每台机器每小时内存使用率的波动值:
> select SPREAD(precent) from mem_usage group by host_name , time(1h) limit 1
name: mem_usage
tags: host_name=server1
time spread
---- ------
1607763600000000000 15.869999999999997
name: mem_usage
tags: host_name=server2
time spread
---- ------
1607763600000000000 3.5
name: mem_usage
tags: host_name=server3
time spread
---- ------
1607814000000000000 0
选择函数:
BOTTOM():返回最小的N个指标值FIRST():返回时间戳最早的指标值LAST():返回时间戳最新的指标值MAX():返回最大的指标值MIN():返回最小的指标值PERCENTILE():返回百分位数为N的指标值SAMPLE():返回N个随机抽样的指标值TOP():返回最大的N个field值
查看每台机器每小时最高的内存使用率:
> select max(precent) from mem_usage group by host_name , time(1h) limit 1
name: mem_usage
tags: host_name=server1
time max
---- ---
1607763600000000000 42.66
name: mem_usage
tags: host_name=server2
time max
---- ---
1607763600000000000 8.1
name: mem_usage
tags: host_name=server3
time max
---- ---
1607814000000000000 7.2
3、InfuxDB API查询数据
查看每台机器每小时最高的内存使用率:
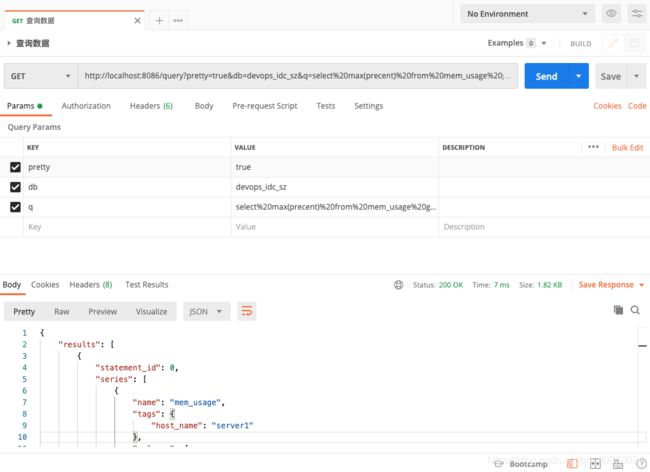
InfluxQL需要进行URLEncode编码
curl -G http://localhost:8086/query?db=devops_idc_sz --data-urlencode "q=select max(precent) from mem_usage group by host_name , time(1h) limit 1"
返回结果:
{
"results": [
{
"statement_id": 0,
"series": [
{
"name": "mem_usage",
"tags": {
"host_name": "server1"
},
"columns": [
"time",
"max"
],
"values": [
[
"2020-12-12T09:00:00Z",
42.66
]
]
},
{
"name": "mem_usage",
"tags": {
"host_name": "server2"
},
"columns": [
"time",
"max"
],
"values": [
[
"2020-12-12T09:00:00Z",
8.1
]
]
},
{
"name": "mem_usage",
"tags": {
"host_name": "server3"
},
"columns": [
"time",
"max"
],
"values": [
[
"2020-12-12T23:00:00Z",
7.2
]
]
}
]
}
]
}
执行多个查询:查询region为us-west的时序数据记录中的指标precent对应的指标值和数量
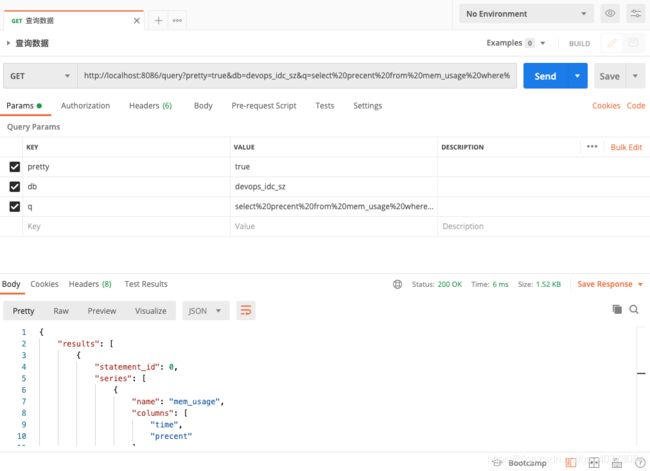
curl -G http://localhost:8086/query?db=devops_idc_sz --data-urlencode "q=select precent from mem_usage where region = 'us-west';select count(precent) from mem_usage where region = 'us-west'"
返回结果:
{
"results": [
{
"statement_id": 0,
"series": [
{
"name": "mem_usage",
"columns": [
"time",
"precent"
],
"values": [
[
"2020-12-12T09:20:24Z",
26.79
],
[
"2020-12-12T09:21:45Z",
38.21
],
[
"2020-12-12T09:22:57Z",
42.66
]
]
}
]
},
{
"statement_id": 1,
"series": [
{
"name": "mem_usage",
"columns": [
"time",
"count"
],
"values": [
[
"1970-01-01T00:00:00Z",
3
]
]
}
]
}
]
}
四、Schema设计(选择tag还是field)
tag和field对比:
- tag是有索引而field没有
- tag是字符串,field支持int、float等数据类型(数值类型使用i后缀为整型,默认float)
选择使用tag:
- 经常查询的元数据
- 需要GROUP BY
选择使用field:
- 用于函数计算
- 非字符串
五、认证
1、创建用户并开启认证
创建admin用户
> show users
user admin
---- -----
> create user "root" with password '123456' with all privileges
> show users
user admin
---- -----
root true
找到容器中InfuxDB的配置文件
root@31f5ad31806f:/# cd /etc/influxdb/
root@31f5ad31806f:/etc/influxdb# ls
influxdb.conf
安装vim
root@31f5ad31806f:/etc/influxdb# apt-get update
root@31f5ad31806f:/etc/influxdb# apt-get install vim
编辑配置文件开启认证
[http]
auth-enabled=true
重启InfluxDB
root@31f5ad31806f:/etc/influxdb# service influxdb restart
这里我重启InfluxDB的时候,显示启动失败,所以我直接重启了容器
重启后,认真功能已开启,InfuxDB将只处理通过认证的HTTP和HTTPS请求
2、认证请求
此时再调用之前的请求提示认证错误

1)通过HTTP基本认证的方式进行认证
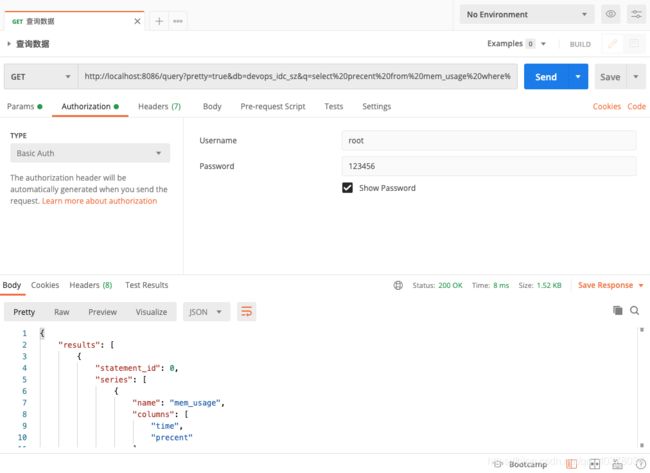
curl -G http://localhost:8086/query?db=devops_idc_sz -u root:123456 --data-urlencode "q=select precent from mem_usage where region = 'us-west';select count(precent) from mem_usage where region = 'us-west'"
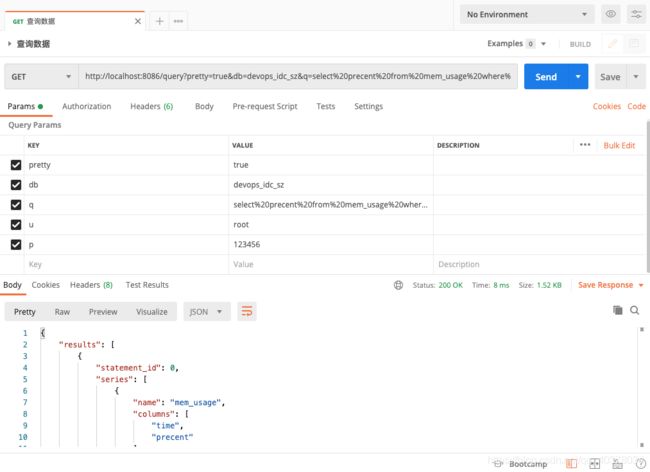
2)将用户凭证信息放在URL中进行认证
通过请求参数u指定用户名P指定密码
推荐资料:
InfluxDB中文文档:https://jasper-zhang1.gitbooks.io/influxdb/content/