年轻人不讲武德,一起聊聊List集合(二)
文章目录
- 前言
- 一、List类图
- 二、源码剖析
-
- 1. LinkedList(此篇详解)
- 2. ArrayList
- 3. Vector
- 4. CopyOnWriteArrayList
- ~~ 码上福利
前言
业精于勤荒于嬉,行成于思毁于随;
在码农的大道上,唯有自己强才是真正的强者,求人不如求己,静下心来,开始思考…
今天一起来聊一聊 List集合,看到这里,笔者懂,大家莫慌,先来宝图镇楼 ~

蓝白黑相间的格子衫,正酝酿着闪电鞭法之五连鞭,说时迟,那时快,敢偷袭我老同志,大意了,没有闪,耗子尾汁…
咳咳… 相信大家满脑子的LinkedList早已被保国大爷经典的画面以及台词冲淡了,那么,目的已达到,那我们言归正传,对于屏幕前帅气的猿友们来说,ArrayList,LinkedList,Vector,CopyOnWriteArrayList… 张口就来,闭眼能写,但是呢,我相信大部分的猿友们并没有刨根问底真正去看过其源码,此时,笔者帅气的脸庞似有似无洋溢起一抹微笑,毕竟是查看过源码的猿,就是那么的不讲武德,吃我一记闪电五连鞭,话不多说,来吧,展示…
一、List类图

二、源码剖析
1. LinkedList(此篇详解)
大家都知道,LinkedList底层为链表(双向链表),结合笔者的经验之谈,我觉得在分析LinkedList集合具体操作源码前,有必要先了解下其底层链表结构,上源码…
- 链表结构
/**
* LinkedList源码定义-双向链表
*/
private static class Node<E> {
// 当前节点值
E item;
// 下一个节点
Node<E> next;
// 上一个节点
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
如此如此,这般这般… 然而…这就是传说中的链表结构之双向链表…
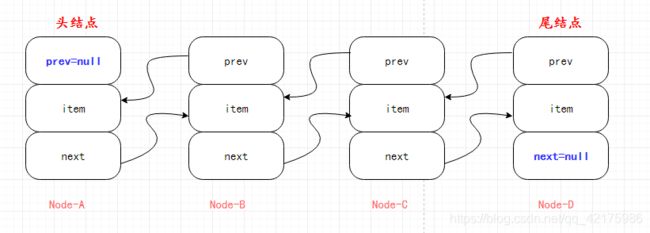
每一个Node节点包含三个属性:item表示当前Node节点值;prev节点表示上一个节点,如当前节点为第一个节点,则当前节点的prev节点为null;next节点表示下一个节点,如当前节点为最后一个节点,则当前节点的next为null;
不过,在LinkedList中另外还定义了first头结点、last尾节点,以方便查询;
看到这里,是不是觉得,就这?是的,就这,多个节点从而构成链表;
抽象图解如下(其实笔者并不是很认同此图能形象的代表链表结构,但抽象理解还是可以的):
单个Node节点:
双向链表图解:
- 构造函数
/**
* 无参构造
*/
public LinkedList() {
}
/**
* 有参构造
* @param c
*/
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
从源码中可以看出,无参构造并没有任何实现,而有参构造可传入已有集合,通过addAll()进行添加;
- add(E e) - 添加元素方法
// 链表节点个数
transient int size = 0;
// 记录对LinkedList操作次数
protected transient int modCount = 0;
/**
* 入口
*/
public boolean add(E e) {
linkLast(e);
return true;
}
// 添加元素
void linkLast(E e) {
// 获取链表中最后一个Node节点
final Node<E> l = last;
// 创建当前当前元素对应Node节点
final Node<E> newNode = new Node<>(l, e, null);
// 将新创建的Node节点赋值给last节点
last = newNode;
// 判断是否为第一次添加
if (l == null)
// 是:新创建的节点既是last节点又是first节点
first = newNode;
else
// 否:将新创建的节点赋值给上个节点的next,依次往后添加
l.next = newNode;
// Node节点个数++
size++;
// 操作次数++
modCount++;
}
从源码中可以看出,添加元素时会在上个节点的next节点后追加;
知识点:
第一次add时,当前Node节点既是first节点又是last节点;
之后每次add,将当前Node节点赋值给上个节点的next节点,依次往后添加,并设置为Last节点;
结论:
为什么链表新增效率高?
因为链表新增只需:设置前节点的next、后节点的prev以及当前新增节点的item值,如插入为头结点或尾节点,需再设置 first节点 last节点,无需像数组新增需要重新copy且需要扩容;
- get() - 获取元素方法
/**
* 入口
*/
public E get(int index) {
// 判断下标越界异常 - 底层为链表 - 实则判断是否超出链表个数
if (!(index >= 0 && index <= size))
throw new IndexOutOfBoundsException("Index: "+index+", Size: "+size);
return node(index).item;
}
// 获取元素
Node<E> node(int index) {
// index < (size >> 1):表示LinkedList查询为折半查询
// 如当前查询索引 < 此链表数量中间值:从头(first)循环查找
// 如当前查询索引 >= 此链表数量中间值:从尾(last)循环查找
if (index < (size >> 1)) {
// 获取头结点
Node<E> x = first;
// 遍历链表从头开始查找
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
// 获取尾节点
Node<E> x = last;
// 遍历链表从尾开始查找
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
从源码中可以看出,获取元素时可以理解为全表扫描,但再获取前巧妙进行了范围折半(折半查询),如当前查询索引小于链表长度中间值,则从头(first节点)往后依次查找,如如当前查询索引大于或等于链表长度中间值,则从尾(last节点)往前依次查找;
- remove() - 删除元素方法
/**
* 入口
*/
public E remove(int index) {
// 判断下标越界异常 - 底层为链表 - 实则判断是否超出链表个数
if (!(index >= 0 && index <= size))
throw new IndexOutOfBoundsException("Index: "+index+", Size: "+size);
return unlink(node(index));
}
// 删除元素
E unlink(Node<E> x) {
// 获取当前节点值
final E element = x.item;
// 获取下一个节点
final Node<E> next = x.next;
// 获取上一个节点
final Node<E> prev = x.prev;
// 上一个节点为空,表示删除节点为头节点
if (prev == null) {
// 头节点变更为下一个节点
first = next;
} else {
// 删除非头结点时:
// 将上个节点的next指向当前节点的下个节点
prev.next = next;
// 当前节点的前一个节点设置为null
x.prev = null;
}
// 下一个节点为空,表示删除节点为尾节点
if (next == null) {
// 尾节点变更为上一个节点
last = prev;
} else {
// 删除非尾节点时:
// 将下个节点的prev指向当前节点的上个节点
next.prev = prev;
// 当前节点的下一个节点设置为null
x.next = null;
}
// 当前节点值设置为null
x.item = null;
// 链表Node节点--
size--;
// 操作次数++
modCount++;
// 返回删除元素节点值
return element;
}
从源码中可以看出,删除元素实则为新增元素的逆向过程,即变更前节点的next节点,变更后节点的prev节点以及将当前新增节点的item设为null,如删除为头结点或尾节点,需再变更 first节点 last节点;
- LinkedList总结:
- 底层为链表-双向链表;
- 查询效率低,增删效率高;
- 循环链表查找,其源码获取前通过折半进行查询;
- 线程不安全;
- 有modCount;
2. ArrayList
不讲武德,一起聊聊List集合之LinkedList
3. Vector
不讲武德,一起聊聊List集合之Vector
4. CopyOnWriteArrayList
不讲武德,一起聊聊List集合之CopyOnWriteArrayList
~~ 码上福利
大家好,我是猿医生:
在码农的大道上,唯有自己强才是真正的强者,求人不如求己,静下心来,扫码一起学习吧…
