全网最详细解释mAP(Mean Average Precision)----利用Tensorflow Object Detection API中的PASCAL VOC的mAP计算做逐步细节解释!!
1. mAP(Mean Average Precision)
首先,VOC数据集对mAP的定义:
(1) True positives(TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数(样本数);
(2) False positives(FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
(3) False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
(4) True negatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数;
(5) P代表precision,即精确率,精确率表示预测样本中实际正样本数占所有正样本数的比例,计算公式为:精确率 = 正确预测样本中实际正样本数 / 所有的正样本数,即precision = TP/(TP+FP);
(6) R代表recall,即召回率,召回率表示预测样本中实际正样本数占所有预测的样本的比例,计算公式为:召回率 = 正确预测样本中实际正样本数 /实际的正样本数,即Recall = TP/(TP+FN) ;
(7) AP代表Average Precision,即一个类别的平均精确度。等价于P-R曲线下的面积;
(8) mAP是 Mean Average Precision的缩写,即均值平均精度。作为 object dection 中衡量检测精度的指标。计算公式为:mAP = 所有类别的平均精度求和/所有类别。
2. Tensorflow Object Detection API中的PASCAL VOC的mAP计算
(1)代码详解和参考:tensorflow的object detection api中的evaluation简介
(2)因此如果想要了解PASCAL VOC的mAP计算过程中的TP、FP、TP+FN、precision、recall和AP值,需要修改utils/metrics.py文件如下:
# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Functions for computing metrics like precision, recall, CorLoc and etc."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np
from six.moves import range
def compute_precision_recall(scores, labels, num_gt):
"""Compute precision and recall.
Args:
scores: A float numpy array representing detection score
labels: A float numpy array representing weighted true/false positive labels
num_gt: Number of ground truth instances
Raises:
ValueError: if the input is not of the correct format
Returns:
precision: Fraction of positive instances over detected ones. This value is
None if no ground truth labels are present.
recall: Fraction of detected positive instance over all positive instances.
This value is None if no ground truth labels are present.
"""
if not isinstance(labels, np.ndarray) or len(labels.shape) != 1:
raise ValueError("labels must be single dimension numpy array")
if labels.dtype != np.float and labels.dtype != np.bool:
raise ValueError("labels type must be either bool or float")
if not isinstance(scores, np.ndarray) or len(scores.shape) != 1:
raise ValueError("scores must be single dimension numpy array")
if num_gt < np.sum(labels):
raise ValueError("Number of true positives must be smaller than num_gt.")
if len(scores) != len(labels):
raise ValueError("scores and labels must be of the same size.")
if num_gt == 0:
return None, None
sorted_indices = np.argsort(scores)
sorted_indices = sorted_indices[::-1]
true_positive_labels = labels[sorted_indices]
false_positive_labels = (true_positive_labels <= 0).astype(float)
cum_true_positives = np.cumsum(true_positive_labels)
cum_false_positives = np.cumsum(false_positive_labels)
precision = cum_true_positives.astype(float) / (
cum_true_positives + cum_false_positives)
recall = cum_true_positives.astype(float) / num_gt
print("**********************************************")
# np.set_printoptions(threshold=np.inf)
print("True positives(TP): " + str(cum_true_positives.astype(float)))
print("False positives(FP): " + str(cum_false_positives.astype(float)))
print("TP+FN: " + str(num_gt.astype(float)))
return precision, recall
def compute_average_precision(precision, recall):
"""Compute Average Precision according to the definition in VOCdevkit.
Precision is modified to ensure that it does not decrease as recall
decrease.
Args:
precision: A float [N, 1] numpy array of precisions
recall: A float [N, 1] numpy array of recalls
Raises:
ValueError: if the input is not of the correct format
Returns:
average_precison: The area under the precision recall curve. NaN if
precision and recall are None.
"""
if precision is None:
if recall is not None:
raise ValueError("If precision is None, recall must also be None")
return np.NAN
if not isinstance(precision, np.ndarray) or not isinstance(
recall, np.ndarray):
raise ValueError("precision and recall must be numpy array")
if precision.dtype != np.float or recall.dtype != np.float:
raise ValueError("input must be float numpy array.")
if len(precision) != len(recall):
raise ValueError("precision and recall must be of the same size.")
if not precision.size:
return 0.0
if np.amin(precision) < 0 or np.amax(precision) > 1:
raise ValueError("Precision must be in the range of [0, 1].")
if np.amin(recall) < 0 or np.amax(recall) > 1:
raise ValueError("recall must be in the range of [0, 1].")
if not all(recall[i] <= recall[i + 1] for i in range(len(recall) - 1)):
raise ValueError("recall must be a non-decreasing array")
recall = np.concatenate([[0], recall, [1]])
precision = np.concatenate([[0], precision, [0]])
# Preprocess precision to be a non-decreasing array
for i in range(len(precision) - 2, -1, -1):
precision[i] = np.maximum(precision[i], precision[i + 1])
indices = np.where(recall[1:] != recall[:-1])[0] + 1
average_precision = np.sum(
(recall[indices] - recall[indices - 1]) * precision[indices])
print("precision: " + str(precision[indices]))
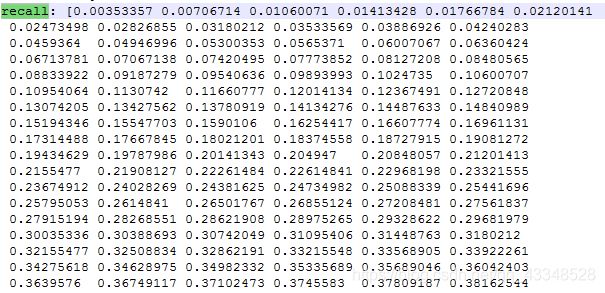
print("recall: " + str(recall[indices]))
print("Average_presicion(AP): " + str(average_precision))
print("==================================================")
return average_precision
def compute_cor_loc(num_gt_imgs_per_class,
num_images_correctly_detected_per_class):
"""Compute CorLoc according to the definition in the following paper.
https://www.robots.ox.ac.uk/~vgg/rg/papers/deselaers-eccv10.pdf
Returns nans if there are no ground truth images for a class.
Args:
num_gt_imgs_per_class: 1D array, representing number of images containing
at least one object instance of a particular class
num_images_correctly_detected_per_class: 1D array, representing number of
images that are correctly detected at least one object instance of a
particular class
Returns:
corloc_per_class: A float numpy array represents the corloc score of each
class
"""
return np.where(
num_gt_imgs_per_class == 0, np.nan,
num_images_correctly_detected_per_class / num_gt_imgs_per_class)
def compute_median_rank_at_k(tp_fp_list, k):
"""Computes MedianRank@k, where k is the top-scoring labels.
Args:
tp_fp_list: a list of numpy arrays; each numpy array corresponds to the all
detection on a single image, where the detections are sorted by score in
descending order. Further, each numpy array element can have boolean or
float values. True positive elements have either value >0.0 or True;
any other value is considered false positive.
k: number of top-scoring proposals to take.
Returns:
median_rank: median rank of all true positive proposals among top k by
score.
"""
ranks = []
for i in range(len(tp_fp_list)):
ranks.append(
np.where(tp_fp_list[i][0:min(k, tp_fp_list[i].shape[0])] > 0)[0])
concatenated_ranks = np.concatenate(ranks)
return np.median(concatenated_ranks)
def compute_recall_at_k(tp_fp_list, num_gt, k):
"""Computes Recall@k, MedianRank@k, where k is the top-scoring labels.
Args:
tp_fp_list: a list of numpy arrays; each numpy array corresponds to the all
detection on a single image, where the detections are sorted by score in
descending order. Further, each numpy array element can have boolean or
float values. True positive elements have either value >0.0 or True;
any other value is considered false positive.
num_gt: number of groundtruth anotations.
k: number of top-scoring proposals to take.
Returns:
recall: recall evaluated on the top k by score detections.
"""
tp_fp_eval = []
for i in range(len(tp_fp_list)):
tp_fp_eval.append(tp_fp_list[i][0:min(k, tp_fp_list[i].shape[0])])
tp_fp_eval = np.concatenate(tp_fp_eval)
return np.sum(tp_fp_eval) / num_gt
(3)最后结果可以放进一个txt文件中,文件很大,因为TP、FP的值很多:
-
TP:
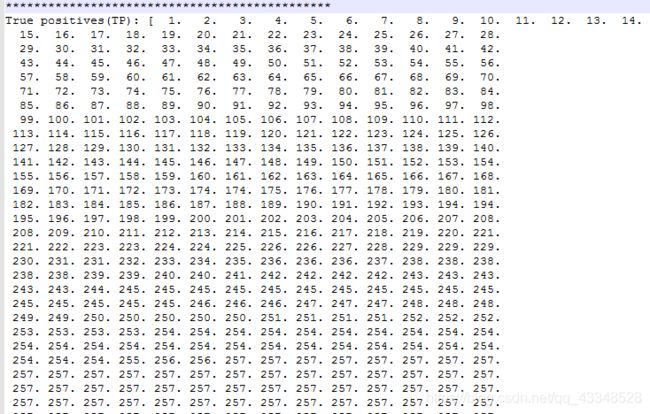
-
FP:

-
precision:
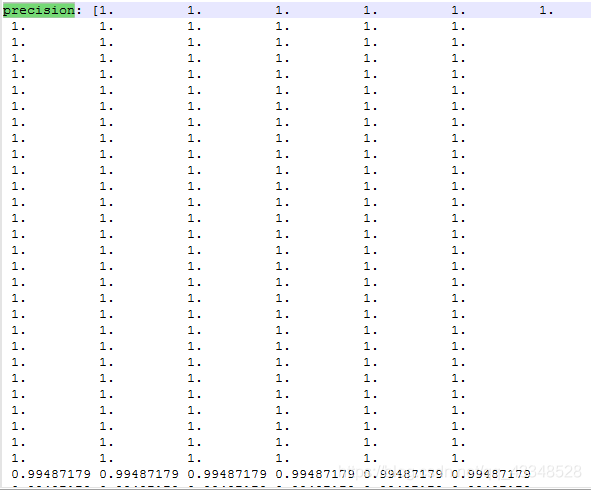
-
recall: