pandas task6
第六章 连接
一、关系型连接
1.连接的基本概念
左连接,右连接,内连接,外连接。
左连接就是以左边表里的键为准,如果右边表里出现左表利的键,就添加到左表里,否则就不添加。
内连接:只合并两个表里同时出现的键。
!如果 出现重复的键怎么处理?
原则:只要两边同时出现的键,就以笛卡尔积的方式加入,如果单边出现则根据连接的形式加入。
小结:
left:参与合并的左侧DataFrame
right:参与合并的右侧DataFrame
how:inner、outer、left、right其中之一
2. 值连接
两张表根据某一列的值来连接,事实上还可以通过几列值的组合进行连接,这种基于值的连接在pandas中可以由merge函数实现,例如:
df1 = pd.DataFrame({
'Name':['San Zhang','Si Li'], 'Age':[20,30]})
df2 = pd.DataFrame({
'Name':['Si Li','Wu Wang'], 'Gender':['F','M']})
df1.merge(df2, on='Name', how='left')
output:
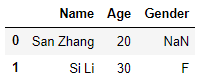
这里的合并都是用merge,以前都是用join。感觉merge更方便一些~
“merge包含了join操作,支持两个df间行方向或列方向的拼接操作,默认列拼接,取交集,而join只是简化了merge的行拼接的操作”
如果两个表中想要连接的列不具备相同的列名,可以通过left_on和right_on指定:
df1 = pd.DataFrame({
'df1_name':['San Zhang','Si Li'], 'Age':[20,30]})
df2 = pd.DataFrame({
'df2_name':['Si Li','Wu Wang'], 'Gender':['F','M']})
df1.merge(df2, left_on='df1_name', right_on='df2_name', how='left')
output:
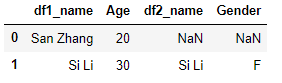
如果两个表中的列出现了重复的列名,那么可以通过suffixes参数指定。例如:
df1 = pd.DataFrame({
'Name':['San Zhang'],'Grade':[70]})
df2 = pd.DataFrame({
'Name':['San Zhang'],'Grade':[80]})
df1.merge(df2, on='Name', how='left', suffixes=['_Chinese','_Math'])
合并张三的语文成绩和数学成绩。
出现重复元素:例如两位同学来自不同的班级,但是姓名相同,这种时候就要指定on参数为多个列使得正确连接:
df1 = pd.DataFrame({
'Name':['San Zhang', 'San Zhang'],
'Age':[20, 21],
'Class':['one', 'two']})
df2 = pd.DataFrame({
'Name':['San Zhang', 'San Zhang'],
'Gender':['F', 'M'],
'Class':['two', 'one']})
df1.merge(df2, on=['Name', 'Class'], how='left') # 正确的结果
在进行基于唯一性的连接下,如果键不是唯一的,那么结果就会产生问题。如果想要保证唯一性,除了用duplicated检查是否重复外,merge中也提供了validate参数来检查连接的唯一性模式。这里共有三种模式,即一对一连接1:1,一对多连接1:m,多对一连接m:1连接,第一个是指左右表的键都是唯一的,后面两个分别指左表键唯一和右表键唯一。
3.索引连接
小结:
left_index:将左侧的行索引用作其连接键的列
right_index:类似于left_index
sort:根据连接键对合并后的数据进行排序,默认为True。有时在处理大数据集时,禁用该选项可获得更好的性能
suffixes:字符串值元组,用于追加到重叠列名,默认为(’_x’,’_y’)
copy:设置为False,可以在某些我死情况下避免将数据复制到结果数据结构中,默认总是复制