无需聚类,杭电学者提出基于软化相似度学习的无监督行人再识别


Unsupervised Person Re-identification via Softened Similarity Learning:
基于软化相似度学习的无监督行人再识别
论文链接:https://arxiv.org/abs/2004.03547
代码链接:https://github.com/ryanaleksander/softened-similarity-learning(非官方)
第一作者:Yutian Lin(现在在武汉大学任副研究员)
合作作者单位:杭州电子科技大学(第一作者),华为技术有限公司,百度研究院,悉尼科技大学 ReLER 实验室
01
看点
图像数据采用完全无标签化;
放弃聚类方法,采用软标签来解决硬量化损失(hard quantization);
图像切片信息和跨摄像机标识信息在无监督领域中的应用;
在采用无监督方法的行人重识别领域中实现了SOTA。
其主要亮点如下:
1.放弃聚类方法,采用软化分类(softened classification)

聚类的缺点:基于聚类的方法将图像粗略地划分为聚类进行训练,使得模型高度依赖于聚类结果。如图1 (b)所示,同一个人的图像可以被分成不同的聚类,这些聚类使用错误分配的伪标签被进一步训练。由于无监督聚类的错误是不可避免的,具有硬量化损失的学习可能倾向于拟合由聚类产生的噪声标签。
软化标签分类:与聚类方法中图像属于一个精确类别的原始 one-hot 标签不同,文中是挖掘未标记图像之间的关系作为温和的约束。作者会对与 target 相似度较高的前 k 个图像都分配软标签,将标签视为一个分布,鼓励图像与几个相关类别相关联。下图中紫色的为 target,黄色为与 target 相近的 k 个可依赖图像。

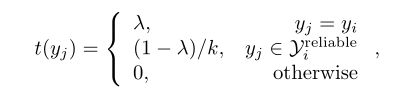
2. 引入了一些辅助信息来帮助找到相似的图像

软标签的约束相对较弱,但是相比较于硬分类,这也给算法提供了更多的空间。所以当测量图像之间的相似性时,每个行人图像的全局和部分特征和摄像机标识信息也会被考虑在内。
02
提出的方法

框架可以分为三个子组件(显示在三个彩色矩形中):
采用基线分类网络将每个图像分类为不同的类别并生成特征表示;
基于特征嵌入和辅助信息探索未标记图像之间的相似性,为每个训练数据选择k个可靠(reliable)图像;
根据生成的k个可靠图像对目标标签分布进行软化,用软化后的标签对网络进行微调,使得选中的k个可靠图像更近,排斥其他图像。
下面我将介绍每个组件的具体实现步骤。
一、Baseline:Initialization with Hard Labels
总体模型框架图中红色框和红色箭头属于此baseline步骤
目的:
最大化图像特征![]() 和查找表中
和查找表中![]() 中的余弦距离,同时最小化每个图像特征
中的余弦距离,同时最小化每个图像特征![]() 和对应的质心特征
和对应的质心特征![]() 之间的余弦距离。初始化的基线网络通过学习识别每个未标记的图像,并获得初始的辨别能力。
之间的余弦距离。初始化的基线网络通过学习识别每个未标记的图像,并获得初始的辨别能力。
步骤:
1. 标签初始化:因为我们并没有每个行人的ground-truth标签,所以对于每个行人![]() ,根据其索引来定义它的标签,同时每个行人也被认为是独立的类。
,根据其索引来定义它的标签,同时每个行人也被认为是独立的类。
![]()
2. 无参数分类器:
非参数分类器的分类模型:我的理解是直接用标准化后的图像特征来进行分类,无需经过其它层,则称为非参数分类器。
其中作者使用查找表![]() 来存储所有训练图像的特征,并将每个图像的特征当作每个类别的权重向量。最后使用softmax来实现多分类。
来存储所有训练图像的特征,并将每个图像的特征当作每个类别的权重向量。最后使用softmax来实现多分类。
①数据预处理:通过标准化![]() 来实现
来实现![]()
②分类:一个图像x属于i-th类的可能性通过softmax定义

其中![]() 表示的是查找表V的第i行,存储的是这个类的权重参数(也就是图像特征)。
表示的是查找表V的第i行,存储的是这个类的权重参数(也就是图像特征)。![]() 是一个温度参数,即表示控制不同类别上的概率分布的软化程度(也就是标签的硬化度)。
是一个温度参数,即表示控制不同类别上的概率分布的软化程度(也就是标签的硬化度)。
③ 损失和优化器
损失:交叉熵损失

其中t(yj)是类别标签上的条件经验分布。对于ground-truth类,我们将分布的概率设置为1,对于所有其他类,设置为0。
二、Model Learning with Softened Similarity
总体模型框架图中绿色和蓝色属于此步骤
目的:
不仅最小化每个图像特征与查找表中的ground-truth特征之间的余弦距离,而且最小化每个图像的特征与其可靠图像之间的距离。同时,每个图像特征和其他类别的特征之间的余弦距离被最大化。
强迫同一个人的特征属于不同的类,会对网络产生负面影响。因此作者提出了为被估计为相同行人的图像分配一个类似的表示的方法,也就是软标签方法。
步骤:
1.相似度计算:对于两幅图像![]() 和
和![]() ,我们将两幅图像之间的距离定义为两幅图像之间的的差异度。(图像距离计算可以参考下一节)
,我们将两幅图像之间的距离定义为两幅图像之间的的差异度。(图像距离计算可以参考下一节)
2.定义标签:对于![]() 而言,它的距离最近的k个图像,被称为是可依赖的图像。并把这些图像定义为
而言,它的距离最近的k个图像,被称为是可依赖的图像。并把这些图像定义为![]() ,它们的标签被设为
,它们的标签被设为![]() 。
。![]() 被称为是和
被称为是和![]() 相同的人,而
相同的人,而![]() 则是可依赖的类。而不是相同的类。
则是可依赖的类。而不是相同的类。
3.重定义目标标签:我们提出了一个软化分类网络,它以更平滑的方式(非硬标签)学习身份之间的相似性,而不是将k个可靠的图像作为同一类进行训练。在训练过程中,我们希望网络不仅能够将每个图像预测到ground-truth类中,而且能够将训练图像预测到可靠类中。因此,我们为目标标签中的可靠类重新分配一个非零值。数据![]() 的目标标签分布写为:
的目标标签分布写为:
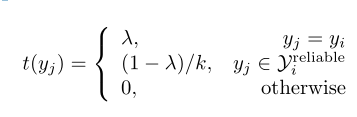
其中λ是一个超参数,它平衡ground-truth类和reliable类之间的关系。当λ为1时,基线网络中简化为只有0和1标签的函数,即模型学习识别出每幅图像的ground-truth标签,但无法学习同一个人的图像之间的相似性和一致性。另一方面,当λ太小时,模型可能无法预测ground-truth标签。
4.损失:交叉熵损失
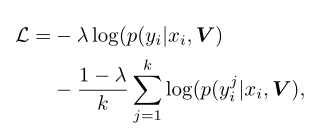
总结:
图像用软标签分布(表示概率)而不是one-hot标签来标记。标签不再是ground-truth类,而是k个可能可靠类的概率。通过考虑可靠类,降低了ground-truth类的可信度,增加了可靠类的可信度,从而引导网络平滑地学习行人图像之间的相似性。
三、Similarity Estimation with Auxiliary Information
为了达到更好的效果,作者还加入了其他方法来帮助估计相似性。
Part similarity exploration
作者在提取CNN特征图后将其水平划分成p份。每个分区特征被平均池化成一个部分级特征表示。我们把两个图像对应部分的平均距离作为两幅图像之间的部分距离

其中![]() 是两个图像第i部分特征嵌入函数。
是两个图像第i部分特征嵌入函数。
The cross-camera encouragement(CCE)
目的:
使用CCE项,具有相同摄像机标识的图像之间的差异会增加。因此,CCE有助于纳入更多的在不同相机下但是可以reliable的图像,并减少一些相同摄像头下的负面图像。
行人重识别的实现效果会受到不同摄像头属性的影响。相同摄像头拍摄的图像“天然地”会有一些相似性。因此文中同时提出了一个跨摄像机鼓励术语(CCE),经过训练,以促进不同摄像头下拍摄的图像被视为可靠的图像。
经过训练后,第一,网络通过学习跨摄像机信息,可以预测一个人在不同摄像机视图下的相似特征,这有利于重新识别任务。第二,有许多穿着相似衣服的不同行人出现在同一个镜头下,CCE可以帮助找到跨摄像机的ground truth,而不是这些负面样本。
如下图所示,在没有CCE的情况下,虽然查询图像和Cam3捕获的图像属于同一个人,但是由于摄像机间隙,它们的差异很大。即使是一个负面的样本(红色的例子),因为它们来自同一个摄像机。所以查询的距离也较小,

作者将训练样本的摄像机标识表示为 ![]() 。除此之外,两幅图像
。除此之外,两幅图像![]() 和
和 ![]() 之间的 CCE 公式为:
之间的 CCE 公式为:

![]() 是控制 CCE 影响力度的参数。
是控制 CCE 影响力度的参数。
Overall dissimilarity
加入上述 CCE 和图像切片相似性后,整体的距离被定义为:

总结:
其中 λ 平衡了整体和部分相似性的贡献。如总体框架的绿色部分所示,两幅图像之间的不同之处包括全局距离、局部距离和跨摄像机鼓励项。通过计算全局和局部距离,度量全局外观和局部细节的相似性,保证了可靠图像选择的准确性。
通过添加 CCE 项,来自不同摄像机的图像往往被选为可靠的图像,这使得网络能够从不同的图像中学习。两者都有利于训练模型的分辨能力。
03
Experiments
Comparison with the State-of-the-Arts
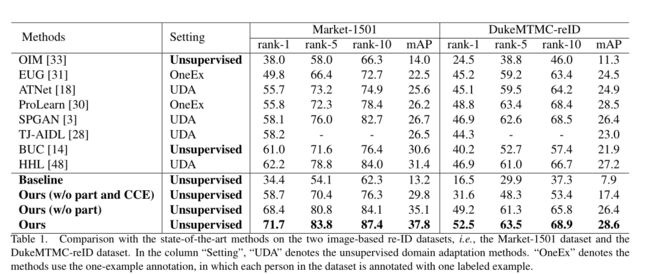
与所有的无监督方法比较,作者的方法在两个图像数据集Market-1501和DukeMTMC-reID 中达到了 SOTA。

与所有的无监督方法比较,作者的方法在两个视频数据集 MARS 和 DukeMTMC-VideoReID 中达到了 SOTA。
Diagnostic Studies
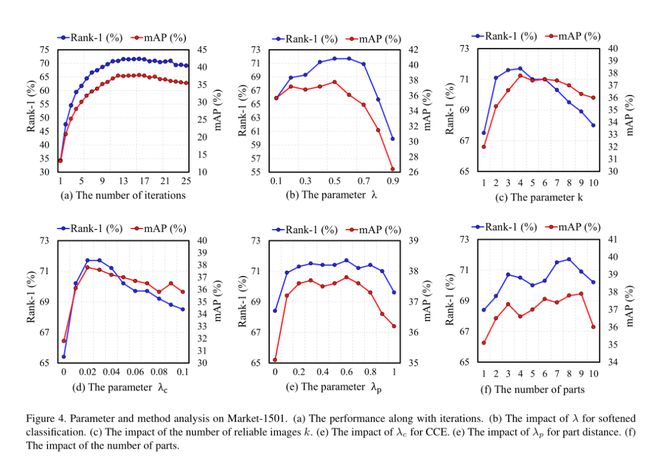
作者在 Market-1501 实验了超参数 λ、可靠图像的数量 k 等等参数的影响。

最后在 Market-1501 和 DukeMTMC 两个数据集中做了关于图像切片信息和 CCE 信息的消融实验,证明了两者的必要性。

备注:reid

行人-ReID-步态交流群
行人检测、行人重识别、步态识别等技术,
若已为CV君其他账号好友请直接私信。
OpenCV中文网
微信号 : iopencv
QQ群:805388940
微博/知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 