Pytorch动态神经网络(莫烦Python视频教学)
视频地址: https://www.bilibili.com/video/av15997678?p=1.
目录
- 1 科普:人工神经网络VS生物神经网络
- 2 什么是神经网络(机器学习)
- 3 神经网络:梯度下降(Gradient Descent)
- 4 神经网络的黑盒不断
- 5 Why pytorch?
- 6 安装
- 7 Numpy Torch的对比
- 8 Variable变量
- 9 什么是激励函数(深度学习)?
- 10 Activation Function 激励函数
- 11 Regression 回归
- 12 Classification 分类
- 13 快速搭建法
- 14 批数据训练
- 15 保存提取
- 16 优化器 Optimizer 加速神经网络训练
- 17 Optimizer 优化器
- 18 什么是卷积神经网络 CNN(深度学习)?
- 19 CNN 卷积神经网络
- 20 什么是循环神经网络 RNN(深度学习)?
- 21 什么是LSTM RNN 循环神经网络 ?
- 22 RNN 循环神经网络 分类
- 23 RNN 循环神经网络 回归
- 24 什么是自编码Autoencoder(深度学习)?
- 30 为什么Pytorch是动态Dynamic?
1 科普:人工神经网络VS生物神经网络
- 人工神经网络没有产生新连接
- 人工神经网络通过正向和反向传播来更新神经元,从而形成一个更好的神经系统,本质上这是一个能让计算机处理和优化的数学模型;生物神经网络是通过刺激产生新的连接,通过新的连接传递能够形成反馈
2 什么是神经网络(机器学习)
- 计算机神经网络是一种模仿生物神经网络或者是动物的神经中枢,特别是大脑的结构和功能。它是一种数学模型或者计算机模型。
- 神经网络由大量的人工神经元连接进行计算,大多数情况下人工神经网络能够在外界信息的基础上改变内部结构,是一种自己适应的逐渐的过程
- 现代神经网络是一种基于传统统计学建模的工具,常用来对输入与输出间复杂的关系进行建模。
3 神经网络:梯度下降(Gradient Descent)
- Optimization
4 神经网络的黑盒不断
5 Why pytorch?
- 为什么用PyTorch?
Pytorch是Torch在Python上的衍生。因为Torch是一个使用Lua语言的神经网络库,Torch很好用,但是Lua又不是很流行,所以开发团队讲Lua的Torch移植到了更流行的语言Python上。 - 谁在用Pytorch?

可见,著名的Facebook,teitter等都在使用它,这就说明PyTorch的确是好用的,而且值得推广。 - PyTorch说他就是在神经网络领域可以用来替换numpy模块。
6 安装
PyTorch官网:https://pytorch.org/.
进入官网,找到下面的页面,选择要安装的版本,根据给出的command来进行安装,eg:pip install torch torchvision

- torch:PyTorch的主模块,用来搭建神经网络
- torchvision:有数据库,各种图片的数据库,或者其它各种图片(eg:VGG);还包含很多训练好的model(eg:VGG、Resnet),它可以直接被下载使用进行再一次的训练
7 Numpy Torch的对比
- 用Numpy还是Torch?
Numpy是一个处理数据的模块,处理各种矩阵的形式,使用多核加速运算快速运算我们的矩阵
Torch自称为神经网络界的Numpy,因为他能将torch产生的tensor放在GPU中加速运算(前提是你有合适的GPU),就像Numpy会把array放在GPU中加速运算,所以神经网络的话当然使用Torch的tensor的形式数据最好。就像Tensorflow当中的tensoryiyang。
我们对Numpy也是爱不释手的,因为我们太习惯numpy的形式了。不过torch看出来我们的喜爱,他把torch做的和numpy能很好的兼容。这样就能够自由的转换numpy array和torch tensor了。
Numpy和Torch的转换:
import torch
import numpy as np
#对比两个模块的功能
#创建np数据
np_data=np.arange(6).reshape((2,3))
#np数据转换成torch.tensor形式
torch_data=torch.from_numpy(np_data)
print("\nnumpy",np_data,"\ntorch",torch_data)

import torch
import numpy as np
#对比两个模块的功能
#创建np数据
np_data=np.arange(6).reshape((2,3))
#np数据转换成torch.tensor形式
torch_data=torch.from_numpy(np_data)
#torch数据转换成numpy的数据
tensor2array=torch_data.numpy()
print("\nnumpy",np_data,"\ntorch",torch_data,"\ntensor2array",tensor2array)

各种运算符号
import torch
import numpy as np
#abs(绝对值)
data=[-1,-2,1,2]
#转换成32bit的浮点数形式
tensor=torch.FloatTensor(data)#32bit
#打印abs值
print("\nabs","\nnumpy:",np.abs(data),"\ntorch:",torch.abs(tensor))
#打印sin值sin
print("\nsin","\nnumpy:",np.sin(data),"\ntorch:",torch.sin(tensor))
#打印mean值
print("\nmean","\nnumpy:",np.mean(data),"\ntorch:",torch.mean(tensor))

import torch
import numpy as np
data=[[1,2],[3,4]]
#转换成32bit的浮点数形式
tensor=torch.FloatTensor(data)#32bit floating point
#矩阵运算
print("\nnumpy:",np.matmul(data,data),#矩阵相乘,自己✖自己
"\ntorch:",torch.mm(tensor,tensor))

import torch
import numpy as np
data=[[1,2],[3,4]]
#转换成numpy形式
data=np.array(data)
#转换成32bit的浮点数形式
tensor=torch.FloatTensor(data.flatten())#32bit floating point 即数据直接转变成tensor数据
#矩阵运算
print("\nnumpy:",data.dot(data),
"\ntorch:",tensor.dot(tensor))

如果不是data.tensor,会报如下错误:
![]()
8 Variable变量
神经网络中的参数都是Variable的形式,tensor的数据信息都是放在这个Variable中,然后用Variable来慢慢的更新神经网络的参数。
import torch
from torch.autograd import Variable
tensor=torch.FloatTensor([[1,2],[3,4]])
variable=Variable(tensor,requires_grad=True) #requires_grad这个参数只是为了确定这个变量是否可以反向传播,是Ture的话就会用到,来计算它的梯度
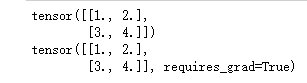
print(tensor)
print(variable)
import torch
from torch.autograd import Variable
tensor=torch.FloatTensor([[1,2],[3,4]])
variable=Variable(tensor,requires_grad=True) #requires_grad这个参数只是为了确定这个变量是否可以反向传播,是Ture的话就会用到,来计算它的梯度
t_out=torch.mean(tensor*tensor)#tensor不能进行反向传播,variable可以
v_out=torch.mean(variable*variable)
print(t_out)
print(v_out)
![]()
import torch
from torch.autograd import Variable
tensor=torch.FloatTensor([[1,2],[3,4]])
variable=Variable(tensor,requires_grad=True) #requires_grad这个参数只是为了确定这个变量是否可以反向传播,是Ture的话就会用到,来计算它的梯度
t_out=torch.mean(tensor*tensor)#tensor不能进行反向传播,variable可以
v_out=torch.mean(variable*variable)
v_out.backward()#进行反向传播
print(variable)
print(variable.grad)
print(variable.data)
print(variable.data.numpy())

9 什么是激励函数(深度学习)?
- 激励函数是为了解决我们日常生活中不能用线性方程解决的问题
- y=Wx变成y=AF(Wx),AF这里是指激活函数,即非线性方程,比如relu、sigmoid、tanh、等
- 激活函数是可微分的·
- CNN种一般选择relu;RCN种一般选择relu或tanh
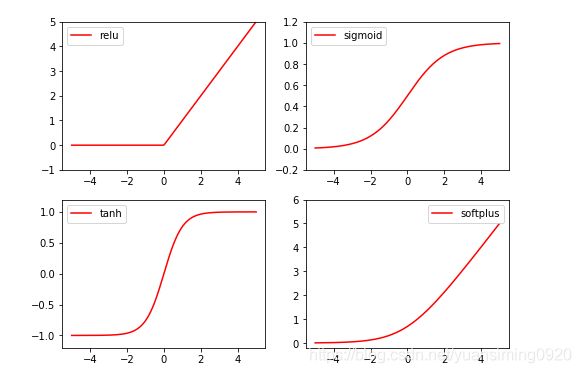
10 Activation Function 激励函数
import torch
import torch.nn.functional as F #神经网络模块中的激励函数
from torch.autograd import Variable #把激励函数包装成变量
import matplotlib.pyplot as plt #python中的画图软件
x=torch.linspace(-5,5,200)#numpy中Linsapce函数,画出-5到5之间总共200个点的一些小线段数据
x=Variable(x)
x_np=x.data.numpy()#torch的数据格式是不能被matplotlib画图的,所以现在需要转成numpy的数据,x现在是variable中的,variable中的tensor是放在data中的,因此需要x.data
#激活函数的激励值
y_relu=F.relu(x).data.numpy()#转换成numpy的数据
y_sigmoid=F.sigmoid(x).data.numpy()
y_tanh=F.tanh(x).data.numpy()
y_softplus=F.softplus(x).data.numpy()#softmax也是激励函数,但不是用来做线图的,而来做概率图的(分类)
#画图
plt.figure(1,figsize=(8,6))#图像编号为1,图片宽和高为8和6
plt.subplot(221)
plt.plot(x_np,y_relu,c="red",label="relu")
plt.ylim((-1,5))
plt.legend(loc="best")
plt.subplot(222)
plt.plot(x_np,y_sigmoid,c="red",label="sigmoid")
plt.ylim((-0.2,1.2))
plt.legend(loc="best")
plt.subplot(223)
plt.plot(x_np,y_tanh,c="red",label="tanh")
plt.ylim((-1.2,1.2))
plt.legend(loc="best")#用于给图像加图例。参数代表图例的位置
plt.subplot(224)
plt.plot(x_np,y_softplus,c="red",label="softplus")
plt.ylim((-0.2,6))
plt.legend(loc="best")
11 Regression 回归
- 神经网络包含(1)回归问题(2)分类问题
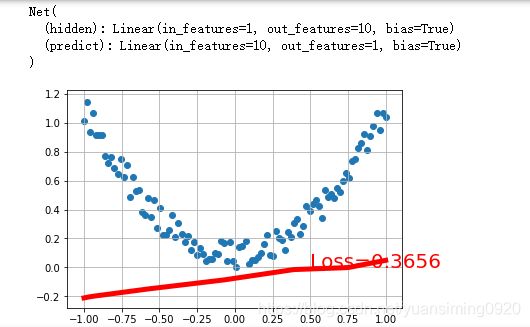
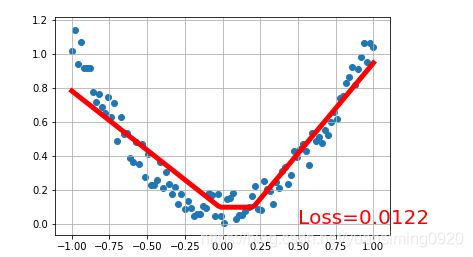
创建一个简单的回归神经网络:
#regression回归
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
#伪数据
x=torch.unsqueeze(torch.linspace(-1,1,100),dim=1)#torch中数据是有维度的,torch只能处理二维数据,unsqueeze负责把一维数据变成二维数据
y=x.pow(2)+0.2*torch.rand(x.size())#y是x的平方加上一些噪点的影响
x,y=Variable(x),Variable(y) #x,y变成Variable的形式,因为神经网路只能输入Variable
# plt.scatter(x.data.numpy(),y.data.numpy())#打印散点图
# plt.show()
class Net(torch.nn.Module):
#n_features,n_hidden,n_output分别表示多少个输入,多少个神经元个数,多少个输出
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__()
#定义一些层
self.hidden=torch.nn.Linear(n_feature,n_hidden) #命名为隐藏层,一层隐藏层,输入为n_features,输出为n_hidden
self.predict=torch.nn.Linear(n_hidden,n_output) #预测的神经层,输出只是一个y的值,因此为1,输入为n_hidden,输出为n_output
#x为输入信息,开始搭建神经网络
def forward(self,x):
x=F.relu(self.hidden(x)) #激励函数激活一下参数
x=self.predict(x)
return x
#定义net
net=Net(1,10,1)
print(net)
plt.ion()
plt.show()
#搭完之后化神经网络的参数,lr为学习率
optimizer=torch.optim.SGD(net.parameters(),lr=0.5)
#定义loss function,MSEloss均方差,用于回归问题;分类问题用另一个训练误差
loss_func=torch.nn.MSELoss()
#开始训练,训练200步
for t in range(200):
prediction=net(x) #网路预测值
loss=loss_func(prediction,y) #计算预测和y的误差
optimizer.zero_grad() #所有参数梯度降为0
loss.backward() #反向传播
optimizer.step()#优化反向传播的梯度
#每5次看一下结果
if t % 5 == 0:
# plot and show learning process
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.grid()
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={
'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
运行出来很多结果,挑选了四个结果:

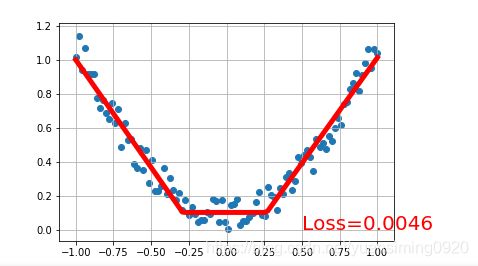
12 Classification 分类
散点图可视化效果:
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
n_data = torch.ones(100, 2)
x0 = torch.normal(2*n_data, 1) # class0 x data (tensor), shape=(100, 2)
y0 = torch.zeros(100) # class0 y data (tensor), shape=(100, 1)
x1 = torch.normal(-2*n_data, 1) # class1 x data (tensor), shape=(100, 2)
y1 = torch.ones(100) # class1 y data (tensor), shape=(100, 1)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # shape (200, 2) FloatTensor = 32-bit floating
y = torch.cat((y0, y1), ).type(torch.LongTensor) # shape (200,) LongTensor = 64-bit integer
x,y=Variable(x),Variable(y)
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')#打印散点图
plt.show()

#分类
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
n_data = torch.ones(100, 2)
x0 = torch.normal(2*n_data, 1) # class0 x data (tensor), shape=(100, 2)
y0 = torch.zeros(100) # class0 y data (tensor), shape=(100, 1)
x1 = torch.normal(-2*n_data, 1) # class1 x data (tensor), shape=(100, 2)
y1 = torch.ones(100) # class1 y data (tensor), shape=(100, 1)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # shape (200, 2) FloatTensor = 32-bit floating
y = torch.cat((y0, y1), ).type(torch.LongTensor) # shape (200,) LongTensor = 64-bit integer
x,y=Variable(x),Variable(y)
# plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')#打印散点图
# plt.show()
class Net(torch.nn.Module):
#n_features,n_hidden,n_output分别表示多少个输入,多少个神经元个数,多少个输出
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__()
#定义一些层
self.hidden=torch.nn.Linear(n_feature,n_hidden) #命名为隐藏层,一层隐藏层,输入为n_features,输出为n_hidden
self.predict=torch.nn.Linear(n_hidden,n_output) #预测的神经层,输出只是一个y的值,因此为1,输入为n_hidden,输出为n_output
#x为输入信息,开始搭建神经网络
def forward(self,x):
x=F.relu(self.hidden(x)) #激励函数激活一下参数
x=self.predict(x)
return x
#定义net
net=Net(2,10,2)#输出0和1两个特征,因为又两个类型
print(net)
plt.ion()
plt.show()
#搭完之后化神经网络的参数,lr为学习率
optimizer=torch.optim.SGD(net.parameters(),lr=0.5)
#定义loss function,CrossEntropyLoss标签误差,用于回归问题;分类问题用另一个训练误差
loss_func=torch.nn.CrossEntropyLoss()
#开始训练,训练200步
for t in range(200):
out=net(x) #网路预测值
loss=loss_func(out,y) #计算预测和y的误差
optimizer.zero_grad() #所有参数梯度降为0
loss.backward() #反向传播
optimizer.step()#优化反向传播的梯度
#每2次看一下结果
if t % 2 == 0:
# plot and show learning process
plt.cla()
prediction = torch.max(out, 1)[1] # 每个输出有两维,max 按 dimension=1 计算。[0]是两个中较大的输出,[1]是索引
pred_y = prediction.data.numpy()
target_y = y.data.numpy()
plt.grid(ls='--')
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn')
accuracy = float((pred_y == target_y).astype(int).sum()) / float(target_y.size)
plt.text(1.5, -4, 'Accuracy=%.2f' % accuracy, fontdict={
'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
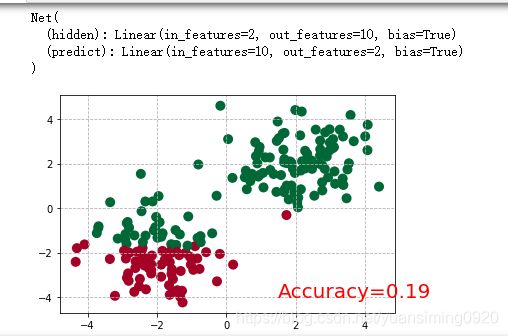

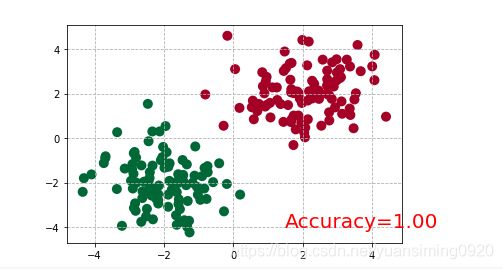
13 快速搭建法
Torch中提供了很多方便的途径,同样是神经网络,能快则快。
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
n_data = torch.ones(100, 2)
x0 = torch.normal(2*n_data, 1) # class0 x data (tensor), shape=(100, 2)
y0 = torch.zeros(100) # class0 y data (tensor), shape=(100, 1)
x1 = torch.normal(-2*n_data, 1) # class1 x data (tensor), shape=(100, 2)
y1 = torch.ones(100) # class1 y data (tensor), shape=(100, 1)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # shape (200, 2) FloatTensor = 32-bit floating
y = torch.cat((y0, y1), ).type(torch.LongTensor) # shape (200,) LongTensor = 64-bit integer
x,y=Variable(x),Variable(y)
# plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')#打印散点图
# plt.show()
#method1
class Net(torch.nn.Module):
#n_features,n_hidden,n_output分别表示多少个输入,多少个神经元个数,多少个输出
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__()
#定义一些层
self.hidden=torch.nn.Linear(n_feature,n_hidden) #命名为隐藏层,一层隐藏层,输入为n_features,输出为n_hidden
self.predict=torch.nn.Linear(n_hidden,n_output) #预测的神经层,输出只是一个y的值,因此为1,输入为n_hidden,输出为n_output
#x为输入信息,开始搭建神经网络
def forward(self,x):
x=F.relu(self.hidden(x)) #激励函数激活一下参数
x=self.predict(x)
return x
#定义net
net1=Net(2,10,2)#输出0和1两个特征,因为又两个类型
#print(net1)
#method2
net2=torch.nn.Sequential(
torch.nn.Linear(2,10),
torch.nn.ReLU(),
torch.nn.Linear(10,2),
)#Sequential的意思就是在括号里一层一层累计神经层就可以
print(net1)
print(net2)
# plt.ion()
# plt.show()
# #搭完之后化神经网络的参数,lr为学习率
# optimizer=torch.optim.SGD(net.parameters(),lr=0.5)
# #定义loss function,CrossEntropyLoss标签误差,用于回归问题;分类问题用另一个训练误差
# loss_func=torch.nn.CrossEntropyLoss()
# #开始训练,训练200步
# for t in range(200):
# out=net(x) #网路预测值
# loss=loss_func(out,y) #计算预测和y的误差
# optimizer.zero_grad() #所有参数梯度降为0
# loss.backward() #反向传播
# optimizer.step()#优化反向传播的梯度
# #每2次看一下结果
# if t % 2 == 0:
# # plot and show learning process
# plt.cla()
# prediction = torch.max(out, 1)[1] # 每个输出有两维,max 按 dimension=1 计算。[0]是两个中较大的输出,[1]是索引
# pred_y = prediction.data.numpy()
# target_y = y.data.numpy()
# plt.grid(ls='--')
# plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn')
# accuracy = float((pred_y == target_y).astype(int).sum()) / float(target_y.size)
# plt.text(1.5, -4, 'Accuracy=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'})
# plt.pause(0.1)
# plt.ioff()
# plt.show()

方法一定义层的时候定义了hideen和predict属性,因此它就会把这些属性加入到这些层的名字之中。方法一中的relu()是小写,它类似于python中定义的函数,比如def relu(),它是一个功能,没有名字;而方法二中的ReLU()是大写,它类似于一个类,它有名字。
14 批数据训练
假设极已经搭好并且训练好一个神经网络,如何进行保存并下次使用的时候提取?
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1) #reproducible
#伪造一些数据
x=torch.unsqueeze(torch.linspace(-1,1,100),dim=1) #data(tensor),shape=(100,1)
y=x.pow(2)+0.2*torch.rand(x.size()) #noisy y data(tensor),shape(100,1)
x,y=Variable(x,requires_grad=False),Variable(y,requires_grad=False)
#保存以及两种方法的提取
def save():
#save net1
#快速搭建一个神经网络
net1 =torch.nn.Sequential(
torch.nn.Linear(1,10),
torch.nn.ReLU(),
torch.nn.Linear(10,1)
)
optimizer=torch.optim.SGD(net1.parameters(),lr=0.2)
loss_func=torch.nn.MSELoss()
for t in range(200):
prediction=net1(x) #网路预测值
loss=loss_func(prediction,y) #计算预测和y的误差
optimizer.zero_grad() #所有参数梯度降为0
loss.backward() #反向传播
optimizer.step()#优化反向传播的梯度
#保存net1
torch.save(net1,"net.pkl")#保存整个神经网络,保存的名字为net.pkl,保存形式为pkl文件
torch.save(net1.state_dict(),"net_params.pkl") #保存神经网络中节点的参数,state_dict,神经网络状态有很多,比如神经网络中节点参数、droput参数
#plot result(输出图)
plt.figure(1,figsize=(10,3))
plt.subplot(131)
plt.title("Net1")
plt.scatter(x.data.numpy(),y.data.numpy())
plt.plot(x.data.numpy(),prediction.data.numpy(),"r-",lw=5)
def restore_net():
net2=torch.load("net.pkl")
prediction=net2(x)
#net2的出图方式
plt.subplot(132)
plt.title("Net2")
plt.scatter(x.data.numpy(),y.data.numpy())
plt.plot(x.data.numpy(),prediction.data.numpy(),"r-",lw=5)
#另一种方法保存
def restore_params():
#首先创建一个net3和net1一摸一样的神经网络,然后再把net1的参数赋值给net3
net3=torch.nn.Sequential(
torch.nn.Linear(1,10),
torch.nn.ReLU(),
torch.nn.Linear(10,1)
)
net3.load_state_dict(torch.load("net_params.pkl"))#这种方法比第一种方法要好,比较推荐
prediction=net3(x)
#net3的出图方式
plt.subplot(133)
plt.title("Net3")
plt.scatter(x.data.numpy(),y.data.numpy())
plt.plot(x.data.numpy(),prediction.data.numpy(),"r-",lw=5)
#save net1
save()
#restore entire net
restore_net()
#restore only thr net parmeters
restore_params()
结果展示:
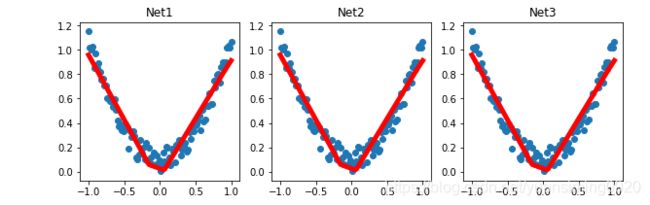
15 保存提取
- Torch中提供了一种帮你整理你的数据结构的好东西,叫做DataLoader,我们能用它来包装自己的数据,进行批训练。
- 批训练有很多种途径
import torch
import torch.utils.data as Data #Data就是进行小批训练的一种途径
#定义批训练大小
BATCH_SIZE=5
#定义一些数据
x=torch.linspace(1,10,10) #this is x data(torch tensor)
y=torch.linspace(10,1,10) #this is x data(torch tensor)
#定义一个torch的数据库,把x和y放入到定义的torch的数据库中
torch_dataset=Data.TensorDataset(x,y)
#使训练变成一小批一小批的,shuffle要把数据打乱顺序训练(下面循环种的loader的数据),num_workers=2表示下面的循环中,从loader种提取batch_x和batch_y都是使用两个线程来提取的
loader=Data.DataLoader(dataset=torch_dataset,batch_size=BATCH_SIZE,shuffle=True, num_workers=0, )
#数据整体训练3次
for epoch in range(3):
for step,(batch_x,batch_y)in enumerate(loader): #x可以分成几个5,step就是几
#print(step,(batch_x,batch_y))
#training....
print("Eepoch:",epoch,"|Step:",step,"|batch x:",batch_x.numpy(),"|batch y:",batch_y.numpy())
结果展示:

当batch_size设置为8的时候:
import torch
import torch.utils.data as Data #Data就是进行小批训练的一种途径
#定义批训练大小
BATCH_SIZE=8
#定义一些数据
x=torch.linspace(1,10,10) #this is x data(torch tensor)
y=torch.linspace(10,1,10) #this is x data(torch tensor)
#定义一个torch的数据库,把x和y放入到定义的torch的数据库中
torch_dataset=Data.TensorDataset(x,y)
#使训练变成一小批一小批的,shuffle要把数据打乱顺序训练(下面循环种的loader的数据),num_workers=2表示下面的循环中,从loader种提取batch_x和batch_y都是使用两个线程来提取的
loader=Data.DataLoader(dataset=torch_dataset,batch_size=BATCH_SIZE,shuffle=True, num_workers=0, )
#数据整体训练3次
for epoch in range(3):
for step,(batch_x,batch_y)in enumerate(loader): #x可以分成几个5,step就是几
#print(step,(batch_x,batch_y))
#training....
print("Eepoch:",epoch,"|Step:",step,"|batch x:",batch_x.numpy(),"|batch y:",batch_y.numpy())
结果展示:

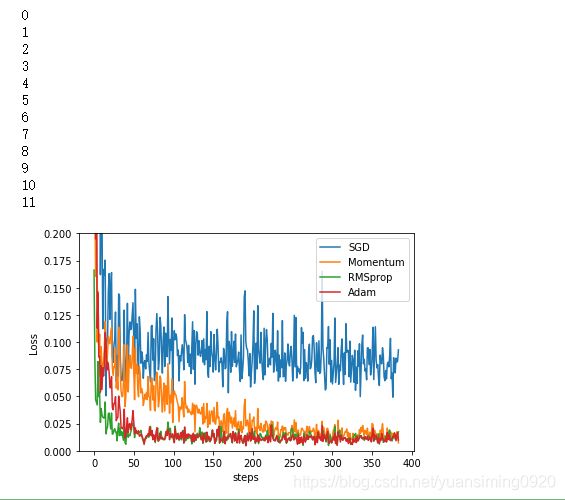
16 优化器 Optimizer 加速神经网络训练
- 越复杂的神经网络,所需要的数据越多,我们所需要的训练时花费的时间就越多,因为计算量太大;但是有的时候需要得到一些较好的结果也必须需要大量的数据。
- SGD:每次使用批量数据放入nn种进行训练(比较基础的优化器)
- Momentum更新法:类似于把喝醉的人从平地上放到一个向下的斜坡上(在平地上学习率下降老是摇摇晃晃走了很多弯路),由于惯性会不自觉的会向下走,走的弯路也会变少
- AdaGrad:在学习率上做的改变,类似于给了喝醉酒的人一双不好走路的鞋子,鞋子是阻力,以便喝醉的人在平地上走的弯路会少了很多,逼着他直路行走。
- RMSProp:结合Momentum惯性原则和AdaGrad不好走路的鞋子,同时具备它们两个的优势,但是也少了Momentum一部分
- Adam:在RMSProp上加上了缺少的Momentum的那一部分。大部分训练会使用它来进行加速训练。
17 Optimizer 优化器
- 优化器的作用就是把我们神经网络的参数优化掉
使用以下数据来训练:
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
#hyper parameters
LR=0.01
BATCH_SIZE=32
EPOCH=12
#数据
x=torch.unsqueeze(torch.linspace(-1,1,1000),dim=1) #torch中数据是有维度的,torch只能处理二维数据,unsqueeze负责把一维数据变成二维数据
y=x.pow(2)+0.1*torch.normal(torch.zeros(*x.size()))
#plt data
plt.scatter(x.numpy(),y.numpy())
plt.show()
使用不同的优化器的优化效果:
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
#hyper parameters
LR=0.01
BATCH_SIZE=32
EPOCH=12
#数据
x=torch.unsqueeze(torch.linspace(-1,1,1000),dim=1) #torch中数据是有维度的,torch只能处理二维数据,unsqueeze负责把一维数据变成二维数据
y=x.pow(2)+0.1*torch.normal(torch.zeros(*x.size()))
#plt data
# plt.scatter(x.numpy(),y.numpy())
# plt.show()
#进行mini-batch的一个途径
torch_dataset=Data.TensorDataset(x,y)
loader=Data.DataLoader(dataset=torch_dataset,batch_size=BATCH_SIZE,shuffle=True,num_workers=2)
#建立神经网络
class Net(torch.nn.Module):
#n_features,n_hidden,n_output分别表示多少个输入,多少个神经元个数,多少个输出
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__()
#定义一些层
self.hidden=torch.nn.Linear(1,20) #命名为隐藏层,一层隐藏层,输入为n_features,输出为n_hidden
self.predict=torch.nn.Linear(20,1) #预测的神经层,输出只是一个y的值,因此为1,输入为n_hidden,输出为n_output
#x为输入信息,开始搭建神经网络
def forward(self,x):
x=F.relu(self.hidden(x)) #激励函数激活一下参数
x=self.predict(x)
return x
#建立四个不同的神经网络,四个神经网络使用四个不同的神经网络优化器
net_SGD=Net(1,20,1)
net_Momentum=Net(1,20,1)
net_RMSprop=Net(1,20,1)
net_Adam=Net(1,20,1)
#四个神经网路都放到一个list种
nets=[net_SGD,net_Momentum,net_RMSprop,net_Adam]
#建立不同的优化器
opt_SGD=torch.optim.SGD(net_SGD.parameters(),lr=LR)
opt_Momentum=torch.optim.SGD(net_Momentum.parameters(),lr=LR,momentum=0.8) #Momentum优化器就是在SGD上添加一个动量
opt_RMSprop=torch.optim.RMSprop(net_RMSprop.parameters(),lr=LR,alpha=0.9)
opt_Adam=torch.optim.Adam(net_Adam.parameters(),lr=LR,betas=(0.9,0.99))
optimizers=[opt_SGD,opt_Momentum,opt_RMSprop,opt_Adam]
#开始创建loss_function来进行训练
loss_func=torch.nn.MSELoss()
losses_his=[[],[],[],[]]#记录上边四种不同网络的误差曲线
for epoch in range(EPOCH):
print(epoch)
for step,(batch_x,batch_y)in enumerate(loader):
#开始训练
b_x=Variable(batch_x)#数据打包成变量
b_y=Variable(batch_y)
for net,opt,l_his in zip (nets,optimizers,losses_his):
#对每一个进行训练
output=net(b_x) #get output for every net
loss=loss_func(output,b_y) #compute loss for every net
opt.zero_grad() #clear gradients for next train
loss.backward() #compute gradients
opt.step() #apply gradients
l_his.append(loss.item()) #loss recoder
#打印
labels=["SGD","Momentum","RMSprop","Adam"]
for i ,l_his in enumerate(losses_his):
plt.plot(l_his,label=labels[i])
plt.legend(loc="best")
plt.xlabel("steps")
plt.ylabel("Loss")
plt.ylim((0,0.2))
plt.show()
结果展示:
18 什么是卷积神经网络 CNN(深度学习)?
- CNN:人工神经网络结构
19 CNN 卷积神经网络
"""
View more, visit my tutorial page: https://morvanzhou.github.io/tutorials/
My Youtube Channel: https://www.youtube.com/user/MorvanZhou
Dependencies:
torch: 0.4
torchvision
matplotlib
"""
# library
# standard library
import os
# third-party library
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt
# torch.manual_seed(1) # reproducible
# Hyper Parameters
EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
BATCH_SIZE = 50
LR = 0.001 # learning rate
DOWNLOAD_MNIST = False
# Mnist digits dataset
if not(os.path.exists('./mnist/')) or not os.listdir('./mnist/'):
# not mnist dir or mnist is empyt dir
DOWNLOAD_MNIST = True
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True, # this is training data
transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST,
)
# plot one example
print(train_data.train_data.size()) # (60000, 28, 28)
print(train_data.train_labels.size()) # (60000)
plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
plt.title('%i' % train_data.train_labels[0])
plt.show()
# Data Loader for easy mini-batch return in training, the image batch shape will be (50, 1, 28, 28)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# pick 2000 samples to speed up testing
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000]/255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
test_y = test_data.test_labels[:2000]
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # input shape (1, 28, 28)
nn.Conv2d(
in_channels=1, # input height
out_channels=16, # n_filters
kernel_size=5, # filter size
stride=1, # filter movement/step
padding=2, # if want same width and length of this image after Conv2d, padding=(kernel_size-1)/2 if stride=1
), # output shape (16, 28, 28)
nn.ReLU(), # activation
nn.MaxPool2d(kernel_size=2), # choose max value in 2x2 area, output shape (16, 14, 14)
)
self.conv2 = nn.Sequential( # input shape (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 14, 14)
nn.ReLU(), # activation
nn.MaxPool2d(2), # output shape (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # flatten the output of conv2 to (batch_size, 32 * 7 * 7)
output = self.out(x)
return output, x # return x for visualization
cnn = CNN()
print(cnn) # net architecture
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
# following function (plot_with_labels) is for visualization, can be ignored if not interested
from matplotlib import cm
try: from sklearn.manifold import TSNE; HAS_SK = True
except: HAS_SK = False; print('Please install sklearn for layer visualization')
def plot_with_labels(lowDWeights, labels):
plt.cla()
X, Y = lowDWeights[:, 0], lowDWeights[:, 1]
for x, y, s in zip(X, Y, labels):
c = cm.rainbow(int(255 * s / 9)); plt.text(x, y, s, backgroundcolor=c, fontsize=9)
plt.xlim(X.min(), X.max()); plt.ylim(Y.min(), Y.max()); plt.title('Visualize last layer'); plt.show(); plt.pause(0.01)
plt.ion()
# training and testing
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # gives batch data, normalize x when iterate train_loader
output = cnn(b_x)[0] # cnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step % 50 == 0:
test_output, last_layer = cnn(test_x)
pred_y = torch.max(test_output, 1)[1].data.numpy()
accuracy = float((pred_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0))
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
if HAS_SK:
# Visualization of trained flatten layer (T-SNE)
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
plot_only = 500
low_dim_embs = tsne.fit_transform(last_layer.data.numpy()[:plot_only, :])
labels = test_y.numpy()[:plot_only]
plot_with_labels(low_dim_embs, labels)
plt.ioff()
# print 10 predictions from test data
test_output, _ = cnn(test_x[:10])
pred_y = torch.max(test_output, 1)[1].data.numpy()
print(pred_y, 'prediction number')
print(test_y[:10].numpy(), 'real number')
结果展示:

20 什么是循环神经网络 RNN(深度学习)?
- 让神经网络记住之前发生事情的能力。进行下一步的时候会将前边记住的能力累加起来
21 什么是LSTM RNN 循环神经网络 ?
- LSTM:是Long Short-Term Memory的简称,中文名字是长短期记忆。
22 RNN 循环神经网络 分类
import torch
from torch import nn
from torch.autograd import Variable
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
#Hyper Parameters
EPOCH=1
BATCH_SIZE=64
TIME_STEP=28 #run time step/image height
INPUT_SIZE=28 #
LR=0.01
DOWNLOAD_MNIST=False
train_data=dsets.Mnist(root="./mnist",train=True,transform=transforms.ToTensor(),download=DOWNLOAD_MNIST)
train_loader=torch.utils.data.DataLoader(dataset=train_data,batch_size=BATCH_SIZE,shuffle=True)
test_data=dsets.MNIST(root="./mnist",train=False,transform=transforms.ToTensor())
test_x=Variable(test_data.test_data,volatile=True).type(torch.FolatTensor)[:2000]/255
test_y=test_data.test_labels.numpy().squeeze()[:2000]
#定义RNN
class RNN(nn.Module):
def __init__(self):
super(RNN,self).__init__()
self.rnn == nn.LSTM(
input_size=INPUT_SIZE,
hidden_size=64,
num_layers=1,
batch_first=True
)
self.out=nn.Linear(64,10)
def forward(self,x):
r_out,(h_n,h_c)=self.rnn(x,None) #(batch,time_step,input_size)
out=self.out(r_out[:,-1,:])#(batch,time step,input)
return out
rnn=RNN()
print(rnn)
#training and testing
optimizer=torch.optim.Adam(rnn.parameters(),lr=LR)
loss_func=nn.CrossEntropyLoss()
for epoch in range(EPOCH):
for step ,(x,y) in enumerate(train_loader):
b_x=Variable(x.view(-1,28,28))
b_y = Variable(y)
output=rnn(b_x)
loss=loss_func(output,b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step%50==0:
test_output=rnn(test_x)
pred_y=torch.max(test_output,1)[1].data.numpy().squeeze()
accuracy=sum(pred_y==test_y)/test_y.size
print("Epoch:",epoch,"| train loss:%.4f"%loss.data[0],"| test accuracy:%.4f")
test_output=rnn(test_x[:10].view(-1,28,28))
pred_y=torch.max(test_output,1)[1].data.numpy().squeeze()
print(pred_y,"prediction number")
print(test_y[:10],"real number")
23 RNN 循环神经网络 回归
24 什么是自编码Autoencoder(深度学习)?
- 自编码是一种神经网络形式,比如一张图片,然后对图片打码,然后再根据打码的图片恢复出原图片。自编码是一种无监督学习。