python BeautifulSoup 实现网页的爬取
from bs4 import BeautifulSoup
import requests
if __name__ == '__main__':
session = requests.Session()
page_url = "https://search.bilibili.com/all?keyword=CNN"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.66"
}
res = session.get(page_url,headers=headers)
soup = BeautifulSoup(res.text)
a = soup.find_all('a',class_='title')
span = soup.find_all('span',class_='so-icon time')
title = a[0].get('title')
href = a[0].get('href')
time = span[0].contents[1][9:19]
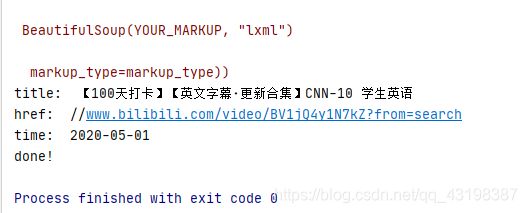
print("title: "+ title)
print("href: "+href)
print("time: " + time)
print("done!")