CRF条件随机场----原理讲解和代码实现(命名实体识别--序列标注问题)
1、CRF条件随机场引入
几个概念介绍:
- 随机场:由若干个位置组成的整体,当给每一个位置中按照某种分布随机赋予一个值之后,其全体就叫做随机场
- 马尔科夫随机场:马尔科夫随机场是随机场的特例,它及假设随机场中某个位置的赋值仅仅与和它相邻的位置的赋值有关,与其不相邻的位置的值无关
- 条件随机场:CRF是马尔科夫随机场的特例,它假设马尔科夫随机场中只有X和Y两种变量,且X一般是给定的输入变量,而Y是我们需要输出的变量(在给定X的条件下)。这样一个马尔科夫随机长就形成了CRF
- 线性条件随机场:
几个理论介绍:
- 概率图模型:由图表示的概率分布,记G=(V,E)是由结点集合V和边集合E组成的图。
- 成对马尔科夫性是指图G中任意两个没有边连接的结点所对应的的两个随机变量是条件独立的。
- 给定一个联合概率分布P(Y),若该分布满足成对、局部或全局马尔科夫性,就称此联合概率分布为概率无向图模型或马尔科夫随机场。
2、条件随机场一般定义


3、线性条件随机场
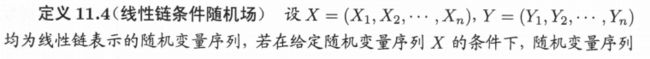

4、线性条件随机场的参数化

5、线性条件随机场参数化的简化



6、线性条件随机场的矩阵形式


7、条件随机场的预测问题
给定:条件随机场P(Y|X) 和 输入观测序列 x,求条件概率最大的输出序列(标注序列) y,即对观测序列进行标注
解算方法:维特比算法



8、计算例题




9、代码实现命名实体识别
BIOES标注集 :是目前最通用的命名实体标注方法,B表示这个词处于一个实体的开始(Begin), I 表示内部(inside), O 表示外部(outside), E 表示这个词处于一个实体的结束为止, S 表示,这个词是自己就可以组成一个实体(Single)。
不同于CRF++,这里使用slearn_crfsuite完成模型的训练
import re
import sklearn_crfsuite
from sklearn_crfsuite import metrics
from sklearn.externals import joblib
dir = "C:/Users/Administrator/Desktop/codes/Python_02/basic/codes/机器学习和深度学习基础/nlp自然语言处理/基于CRF的中文命名实体识别模型实现/"
# 语料处理
class CorpusProcess(object):
"""
将语料全角字符统一转为半角;
合并语料库分开标注的姓和名,例如:温/nr 家宝/nr;
合并语料库中括号中的大粒度词,例如:[国家/n 环保局/n]nt;
合并语料库分开标注的时间,例如:(/w 一九九七年/t 十二月/t 三十一日/t )/w。
"""
# 初始化
def __init__(self):
"""初始化"""
self.train_corpus_path = dir+ "1980_01rmrb.txt"
self.process_corpus_path = dir + "result-rmrb.txt"
self._maps = {u't': u'T',u'nr': u'PER', u'ns': u'ORG',u'nt': u'LOC'}
# 读取语料
def read_corpus_from_file(self, file_path):
"""读取语料"""
f = open(file_path, 'r',encoding='utf-8')
lines = f.readlines()
f.close()
return lines
# 写入语料
def write_corpus_to_file(self, data, file_path):
"""写语料"""
f = open(file_path, 'wb')
f.write(data)
f.close()
# 全角转为半角
def q_to_b(self,q_str):
"""全角转半角"""
b_str = ""
for uchar in q_str:
inside_code = ord(uchar)
if inside_code == 12288: # 全角空格直接转换
inside_code = 32
elif 65374 >= inside_code >= 65281: # 全角字符(除空格)根据关系转化
inside_code -= 65248
b_str += chr(inside_code)
return b_str
# 半角转为全角
def b_to_q(self,b_str):
"""半角转全角"""
q_str = ""
for uchar in b_str:
inside_code = ord(uchar)
if inside_code == 32: # 半角空格直接转化
inside_code = 12288
elif 126 >= inside_code >= 32: # 半角字符(除空格)根据关系转化
inside_code += 65248
q_str += chr(inside_code)
return q_str
# 预料处理、存储处理数据
def pre_process(self):
"""语料预处理 """
lines = self.read_corpus_from_file(self.train_corpus_path)
new_lines = []
for line in lines:
words = self.q_to_b(line.strip()).split(u' ')
pro_words = self.process_t(words)
pro_words = self.process_nr(pro_words)
pro_words = self.process_k(pro_words)
new_lines.append(' '.join(pro_words[1:]))
self.write_corpus_to_file(data='\n'.join(new_lines).encode('utf-8'), file_path=self.process_corpus_path)
# 处理语料库中大粒度分词
def process_k(self, words):
"""处理大粒度分词,合并语料库中括号中的大粒度分词,类似:[国家/n 环保局/n]nt """
pro_words = []
index = 0
temp = u''
while True:
word = words[index] if index < len(words) else u''
if u'[' in word:
temp += re.sub(pattern=u'/[a-zA-Z]*', repl=u'', string=word.replace(u'[', u''))
elif u']' in word:
w = word.split(u']')
temp += re.sub(pattern=u'/[a-zA-Z]*', repl=u'', string=w[0])
pro_words.append(temp+u'/'+w[1])
temp = u''
elif temp:
temp += re.sub(pattern=u'/[a-zA-Z]*', repl=u'', string=word)
elif word:
pro_words.append(word)
else:
break
index += 1
return pro_words
# 处理人名,姓和名连接在一起
def process_nr(self, words):
""" 处理姓名,合并语料库分开标注的姓和名,类似:温/nr 家宝/nr"""
pro_words = []
index = 0
while True:
word = words[index] if index < len(words) else u''
if u'/nr' in word:
next_index = index + 1
if next_index < len(words) and u'/nr' in words[next_index]:
pro_words.append(word.replace(u'/nr', u'') + words[next_index])
index = next_index
else:
pro_words.append(word)
elif word:
pro_words.append(word)
else:
break
index += 1
return pro_words
# 连接分开的时间语料
def process_t(self, words):
"""处理时间,合并语料库分开标注的时间词,类似: (/w 一九九七年/t 十二月/t 三十一日/t )/w """
pro_words = []
index = 0
temp = u''
while True:
word = words[index] if index < len(words) else u''
if u'/t' in word:
temp = temp.replace(u'/t', u'') + word
elif temp:
pro_words.append(temp)
pro_words.append(word)
temp = u''
elif word:
pro_words.append(word)
else:
break
index += 1
return pro_words
#
def pos_to_tag(self, p):
"""由词性提取标签"""
t = self._maps.get(p, None)
return t if t else u'O'
def tag_perform(self, tag, index):
"""标签使用BIO模式"""
if index == 0 and tag != u'O':
return u'B_{}'.format(tag)
elif tag != u'O':
return u'I_{}'.format(tag)
else:
return tag
def pos_perform(self, pos):
"""去除词性携带的标签先验知识"""
if pos in self._maps.keys() and pos != u't':
return u'n'
else:
return pos
def initialize(self):
"""初始化 """
lines = self.read_corpus_from_file(self.process_corpus_path)
words_list = [line.strip().split(' ') for line in lines if line.strip()]
del lines
self.init_sequence(words_list)
def init_sequence(self, words_list):
"""初始化字序列、词性序列、标记序列 """
words_seq = [[word.split(u'/')[0] for word in words] for words in words_list]
pos_seq = [[word.split(u'/')[1] for word in words] for words in words_list]
tag_seq = [[self.pos_to_tag(p) for p in pos] for pos in pos_seq]
self.pos_seq = [[[pos_seq[index][i] for _ in range(len(words_seq[index][i]))]
for i in range(len(pos_seq[index]))] for index in range(len(pos_seq))]
self.tag_seq = [[[self.tag_perform(tag_seq[index][i], w) for w in range(len(words_seq[index][i]))]
for i in range(len(tag_seq[index]))] for index in range(len(tag_seq))]
self.pos_seq = [[u'un']+[self.pos_perform(p) for pos in pos_seq for p in pos]+[u'un'] for pos_seq in self.pos_seq]
self.tag_seq = [[t for tag in tag_seq for t in tag] for tag_seq in self.tag_seq]
self.word_seq = [[u'']+[w for word in word_seq for w in word]+[u''] for word_seq in words_seq]
def extract_feature(self, word_grams):
"""特征选取"""
features, feature_list = [], []
for index in range(len(word_grams)):
for i in range(len(word_grams[index])):
word_gram = word_grams[index][i]
feature = {u'w-1': word_gram[0], u'w': word_gram[1], u'w+1': word_gram[2],
u'w-1:w': word_gram[0]+word_gram[1], u'w:w+1': word_gram[1]+word_gram[2],
# u'p-1': self.pos_seq[index][i], u'p': self.pos_seq[index][i+1],
# u'p+1': self.pos_seq[index][i+2],
# u'p-1:p': self.pos_seq[index][i]+self.pos_seq[index][i+1],
# u'p:p+1': self.pos_seq[index][i+1]+self.pos_seq[index][i+2],
u'bias': 1.0}
feature_list.append(feature)
features.append(feature_list)
feature_list = []
return features
def segment_by_window(self, words_list=None, window=3):
"""窗口切分"""
words = []
begin, end = 0, window
for _ in range(1, len(words_list)):
if end > len(words_list): break
words.append(words_list[begin:end])
begin = begin + 1
end = end + 1
return words
def generator(self):
"""训练数据"""
word_grams = [self.segment_by_window(word_list) for word_list in self.word_seq]
features = self.extract_feature(word_grams)
return features, self.tag_seq
class CRF_NER(object):
def __init__(self):
"""初始化参数"""
self.algorithm = "lbfgs"
self.c1 ="0.1"
self.c2 = "0.1"
self.max_iterations = 100
self.model_path = dir + "model.pkl"
self.corpus = CorpusProcess() #Corpus 实例
self.corpus.pre_process() #语料预处理
self.corpus.initialize() #读取处理好的语料
self.model = None
def initialize_model(self):
"""初始化"""
algorithm = self.algorithm
c1 = float(self.c1)
c2 = float(self.c2)
max_iterations = int(self.max_iterations)
self.model = sklearn_crfsuite.CRF(algorithm=algorithm, c1=c1, c2=c2,
max_iterations=max_iterations, all_possible_transitions=True)
def train(self):
"""训练"""
self.initialize_model()
x, y = self.corpus.generator()
x_train, y_train = x[500:], y[500:]
x_test, y_test = x[:500], y[:500]
self.model.fit(x_train, y_train)
labels = list(self.model.classes_)
labels.remove('O')
y_predict = self.model.predict(x_test)
metrics.flat_f1_score(y_test, y_predict, average='weighted', labels=labels)
sorted_labels = sorted(labels, key=lambda name: (name[1:], name[0]))
print(metrics.flat_classification_report(y_test, y_predict, labels=sorted_labels, digits=3))
self.save_model()
def predict(self, sentence):
"""预测"""
self.load_model()
u_sent = self.corpus.q_to_b(sentence)
word_lists = [[u'']+[c for c in u_sent]+[u'']]
word_grams = [self.corpus.segment_by_window(word_list) for word_list in word_lists]
features = self.corpus.extract_feature(word_grams)
y_predict = self.model.predict(features)
entity = u''
for index in range(len(y_predict[0])):
if y_predict[0][index] != u'O':
if index > 0 and y_predict[0][index][-1] != y_predict[0][index-1][-1]:
entity += u' '
entity += u_sent[index]
elif entity[-1] != u' ':
entity += u' '
return entity
def load_model(self):
"""加载模型 """
self.model = joblib.load(self.model_path)
def save_model(self):
"""保存模型"""
joblib.dump(self.model, self.model_path)
ner = CRF_NER()
# model = ner.train()
print(ner.predict(u'新华社北京十二月三十一日电(中央人民广播电台记者刘振英、新华社记者张宿堂)今天是一九九七年的最后一天。'))
# '新华社 北京 十二月三十一日 中央人民广播电台 刘振英 新华社 张宿堂 今天 一九九七年 '
print(ner.predict(u'一九四九年,国庆节,毛泽东同志在天安门城楼上宣布中国共产党从此站起来了!'))
# '一九四九年 国庆节 毛泽东 天安门城 中国共产党 '