机器学习中的随机过程
If you would like to get a general introduction to Machine Learning before this, check out this article:
如果您想在此之前获得机器学习的一般介绍,请查看本文:
Now that we understand what Machine Learning is, let us now learn about how Machine Learning is applied to solve any problem.
现在我们了解了什么是机器学习,现在让我们了解如何将机器学习应用于解决任何问题。
This is the basic process which is used to apply machine learning to any problem :-
这是将机器学习应用于任何问题的基本过程:
资料收集 (Data Gathering)
The first step to solving any machine learning problem is to gather relevant data. It could be from different sources and in different formats like plain text, categorical or numerical. Data Gathering is important as the outcome of this step directly affects the nature of our problem.
解决任何机器学习问题的第一步是收集相关数据。 它可能来自不同的来源,并且格式不同,例如纯文本,分类或数字。 数据收集非常重要,因为此步骤的结果直接影响我们问题的性质。
In most cases, data is not handed to us on a silver platter all ready-made, that is, it is not usually the case that the data we have decided is relevant may be available right away. It is very much possible that we may have to perform some sort of an exercise or a controlled experiment to gather data that we can work with. We must also keep in mind that the data we are collecting is from legitimate and legal processes such that all the parties involved are well aware of what is being collected.
在大多数情况下,数据并没有全部准备就绪地交给我们,也就是说,通常我们不会立即获得我们认为相关的数据。 我们很有可能必须执行某种练习或受控实验来收集可以使用的数据。 我们还必须记住,我们正在收集的数据来自合法和合法的流程,因此所有相关方都非常了解所收集的内容。
Let us, for the purpose of this article, assume that we have gathered data about cars and that we are trying to predict the price of a new car with the help of machine learning.
出于本文的目的,让我们假设我们已经收集了有关汽车的数据,并且我们正在尝试借助机器学习来预测新车的价格。
数据预处理 (Data Preprocessing)
Now that we have gathered data that is relevant to the problem in hand, we must bring it to a homogeneous state. The present form of our data could include datasets of various types, maybe a table made up of a thousand rows and multiple columns of car data, or maybe pictures of cars from different angles. It is always advisable to keep thing simple and work with data of one particular type, that is, we should decide before we start working on our algorithm whether we want to work with image data, text data, or video data if we are feeling a little too adventurous!
现在,我们已经收集了与手头问题相关的数据,我们必须将其置于同类状态。 我们数据的当前形式可能包括各种类型的数据集,可能是由一千行和多列汽车数据组成的表格,也可能是来自不同角度的汽车图片。 始终建议保持简单并使用一种特定类型的数据,也就是说,如果我们感觉要使用图像数据,文本数据或视频数据,则应该在开始算法之前就决定要使用图像数据,文本数据还是视频数据。有点冒险!

Like every computer program, Machine Learning algorithms also only understand 1s and 0s. So in order to run any such algorithm, we have to first convert the data into a machine-readable format. It simply won’t understand if we put on a slideshow of our pictures!We can go with any type of data -numerical, image, video or text- but we will have to configure it such that it is machine understandable. We make sure this happens by Encoding the data — a process in which we take all the types of data and represent them numerically.
像每个计算机程序一样,机器学习算法也只能理解1和0。 因此,为了运行任何此类算法,我们必须首先将数据转换为机器可读格式。 它根本无法理解是否要对图片进行幻灯片放映!我们可以处理任何类型的数据-数字,图像,视频或文本-但我们必须对其进行配置,以使机器可以理解。 我们通过对数据进行编码来确保做到这一点-在此过程中,我们将获取所有类型的数据并以数字形式表示它们。
For a simple and comprehensible introduction to Data Preprocessing and all the steps involved, check out this article :
有关数据预处理及其涉及的所有步骤的简单而易懂的介绍,请查看本文:
训练和测试数据 (Train and Test Data)
Before we start building a Machine Learning model, we have to first identify our features and decide on our goal. Features are the attributes of our data which tell us about the different entities in the data. For instance, we could be having a huge dataset about cars to predict the price of a new car using machine learning. With these cars being the entities, features, in this case, might be the engine power, mileage, top speed, color, seating capacity, type of car etc. etc..The goal or the Target variable, in this case, would be the price of the car.
在开始构建机器学习模型之前,我们必须首先确定我们的功能并确定我们的目标 。 特征是数据的属性,可告诉我们数据中的不同实体。 例如,我们可能拥有大量有关汽车的数据集,以便使用机器学习来预测新车的价格。 以这些汽车为实体,在这种情况下,功能可能是发动机功率,里程,最高速度,颜色,座位容量,汽车类型等。在这种情况下, 目标或目标变量将是汽车的价格。
When we work on any machine learning problem, we always split the dataset that we have into a Training Set and a Test set, usually a (70/30) or (80/20) split respectively. The Training set, as the name suggests, is used to train the model. When we “train” the model, it tries to understand how all the features of the dataset form the target variable — in case of supervised learning, or the relationships and correlations between all the features — in case of unsupervised learning. After this, the Test set is then used to find out how well the model’s understanding is of the data.
当我们处理任何机器学习问题时,我们总是将拥有的数据集划分为训练集和测试集 ,通常分别是(70/30)或(80/20)划分。 顾名思义,训练集用于训练模型。 当我们“训练”模型时,它试图了解数据集的所有特征如何形成目标变量(如果是监督学习的话),或者所有特征之间的关系和相关性(如果是无监督学习的话)。 此后,然后使用测试集找出模型对数据的理解程度。
机器学习算法选择 (Machine Learning Algorithm Selection)
After transforming data such that it is clean and workable, we get a better idea of the solution we will try and implement to solve the problem. This is because it is actually the data that decides what we can and cannot use.
在对数据进行了整洁和可操作的转换之后,我们对解决方案有了一个更好的了解,我们将尝试并实现该解决方案。 这是因为实际上是数据决定了我们可以使用和不能使用的内容。
Say we want to build a chatbot. The chatbot will answer as per the user queries. So, we can say that the first step to any conversation will be the chatbot trying to identify the intent of the user, and there is our first machine learning problem — Intent Classification.
假设我们要构建一个聊天机器人。 聊天机器人将根据用户查询进行回答。 因此,可以说,任何对话的第一步都是聊天机器人试图识别用户的意图,这是我们的第一个机器学习问题-意图分类。
This problem requires us to use a particular type of data — Text based data. The machine learning algorithm we choose must be a classification algorithm, that is, it classifies the new input data to a certain label class as per the data which it has already seen. Before this step, of course, the text from the user will get encoded and go through all the data preprocessing steps necessary and then it will be fed into the machine learning algorithm. Although we have to be careful in selecting our machine learning algorithm, it is good to explore all the available options and working out with various appropriate machine learning algorithms before selecting the final one — it is considered as a best practice anyway.
这个问题要求我们使用一种特定类型的数据-基于文本的数据。 我们选择的机器学习算法必须是分类算法,也就是说,它将新输入数据根据已经看到的数据分类为某个标签类。 当然,在此步骤之前,来自用户的文本将被编码并经过所有必要的数据预处理步骤,然后将其输入到机器学习算法中。 尽管我们在选择机器学习算法时必须谨慎,但是在选择最后一种算法之前,最好先探究所有可用的选项,并尝试各种合适的机器学习算法-仍然被认为是最佳实践。
成本函数 (Cost Function)
A Cost Function, in a nutshell, is a mathematical function which gives out cost as a metric; And as you may have heard — there is a cost associated with every decision that we take.
简而言之,成本函数是一种数学函数,它给出了成本作为度量标准。 如您所知,我们做出的每项决定都会产生一定的成本。
“A Cost function or a Loss function is a function that maps an event or values of one or more variables onto a real number intuitively representing some “cost” associated with the event.” — Wikipedia
“成本函数或损失函数是将一个事件或一个或多个变量的值映射到一个实数上的函数,该函数直观地表示与该事件相关的某些”成本”。” — 维基百科
This function is used to quantify the penalty correspondent to every step in any procedure. In terms of an optimization problem, we must work on minimizing this cost value.
此功能用于量化与任何过程中每个步骤相对应的惩罚 。 就优化问题而言,我们必须努力使该成本值最小化。
Let us go through an example -Suppose you are climbing down a cliff. At any point, you have several paths to take to eventually reach the bottom, but you will :
让我们来看一个例子-假设您正在攀登悬崖。 在任何时候,您都可以采取几种方法最终达到最低点,但是您将:
- Look for the best path from that point 从那一点寻找最佳路径
- Reject all the paths taking you any higher than you already are 拒绝所有使您比以前更高的路径
If we associate going up with a penalty or a cost, we will be increasing the total cost (in terms of time and effort) if we go up. So we can potentially keep time and effort as factors if we were to design a mathematical function to quantify this cost metric.
如果我们将涨价与罚款或成本联系起来,那么如果涨价 ,我们将增加总成本(在时间和精力方面)。 因此,如果我们要设计数学函数来量化此成本指标,则可以将时间和精力作为因素。
Another example -Suppose you are driving down on a road trip from Place A to Place B. Again, we have several paths to reach B but we :
另一个示例-假设您正在开车从A地点到B地点。同样,我们有几种到达B的路径,但我们:
- Look for the shortest path 寻找最短的路径
- Reject all the paths which take us somewhere else (obviously!) 拒绝所有带我们到其他地方的路径(显然!)
If we associate this situation with cost, we will have a high cost if we neglect the two points mentioned above. Here we can keep time and gas money as the factors making up our cost function and judge the path taken henceforth.
如果我们把这种情况与成本联系起来 ,那么如果我们忽略上述两点,我们将付出高昂的代价。 在这里,我们可以将时间和汽油费作为构成成本函数的因素,并判断今后的路径。

机器学习中的成本函数 (Cost Function in Machine Learning)
Any machine learning algorithm must reach an optimal state for it to function properly. A Cost Function helps us in determining whether or not our model is at that optimal state. That optimal state is found out by the model by continuously comparing the model hypothesis value to the original value in the training set. Woah…back up! What!? Don’t worry we will go through all the concepts carefully!
任何机器学习算法都必须达到最佳状态才能正常运行。 成本函数可帮助我们确定模型是否处于最佳状态。 通过不断将模型假设值与训练集中的原始值进行比较, 模型可以找到最佳状态。 哇...备份! 什么!? 不用担心,我们将仔细研究所有概念!
Hypothesis Function
假设函数
Behind any machine learning model is essentially a mathematical function which explains the role of various features in the data to either form the target variable or to form correlations between different features.
任何机器学习模型的背后都实质上是一个数学函数,该函数解释了数据中各种特征在形成目标变量或形成不同特征之间的相关性方面的作用。
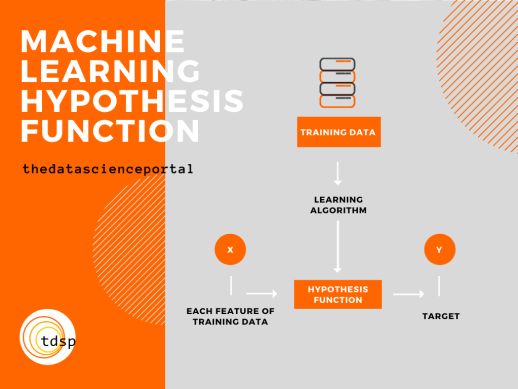
As mentioned before, during training the machine learning model tries to understand how different combinations of values of the training data features form the corresponding target variables. To understand better let us take one training record, training essentially means taking all the features of this record and somehow mapping it to this training record’s target value. A brilliant example would be the cars dataset we were talking about earlier. Notation-wise, the features are taken as X and the Target variable is taken as Y. During this process, training data is fed into a learning algorithm which is chosen based on the problem we are trying to solve. It could be a classification problem, a regression problem or maybe something else entirely. It is the job of this learning algorithm to output this Hypothesis Function.
如前所述,在训练期间,机器学习模型试图了解训练数据特征值的不同组合如何形成相应的目标变量。 为了更好地理解,让我们记录一个训练记录,训练本质上是指利用该记录的所有功能,并以某种方式将其映射到该训练记录的目标值。 一个很好的例子是我们之前讨论的汽车数据集。 从符号上来说,特征取为X,目标变量取为Y。在此过程中,训练数据被馈送到根据我们要解决的问题选择的学习算法中。 这可能是分类问题,回归问题或其他完全问题。 输出此假设函数是该学习算法的工作。
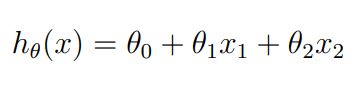
For a two-variable problem, this could be our Hypothesis function. All the θ values are parameters, or weights, which are chosen such that we get an estimate value closest to the corresponding Target value for each record.
对于两个变量的问题,这可能是我们的假设函数。 所有θ值都是参数或权重,选择这些参数或权重是为了使我们得到最接近每个记录的相应目标值的估计值。
The Hypothesis Function then takes in the features from each training record and tries to estimate the corresponding target value. This function could be a simple linear function or maybe something complex, it really depends on the data and the type of algorithm that is being used. And because it is an estimator function, the output values are not expected to be exactly equal to the target values, at least not in the first attempt. Let us take our cars dataset once more, if we put a learning algorithm to use on this dataset and try to train it using the features, we will get an estimate of the price of each car in the dataset. Now as this is a training dataset, we already have the price of each car as the Target variable.
然后,假设功能从每个训练记录中获取特征,并尝试估计相应的目标值。 此函数可以是简单的线性函数,也可以是复杂的函数,它实际上取决于数据和所使用算法的类型。 并且由于它是一个估计器函数,因此期望输出值不完全等于目标值,至少在第一次尝试中不会如此。 让我们再次获取汽车数据集,如果我们在该数据集上使用学习算法并尝试使用功能进行训练,我们将获得数据集中每辆汽车的价格估算。 现在这是一个训练数据集,我们已经将每辆车的价格作为目标变量。
Cost Function
成本函数
This is where the Cost Function comes into play. We want the difference between the estimated value and the actual Target value present in the training data to be as low as possible, only then can we call say our model is a strong one, meaning that it will give out the correct value of the Target value or at least return a value which is very very close to this Target value for a particular training record. So, this becomes a minimization problem. The difference is what is called the cost and the minimization function is what is called the cost function. There are several ways to achieve a state of minima. We could simply minimize the difference between the estimated value and the target value over the whole training set, or we could take the squared difference, or maybe some other variation to achieve the same thing. One of the most widely accepted and quite a reasonable cost function is this one which you will stumble upon very easily if you are reading up on machine learning algorithms :
这就是成本函数发挥作用的地方。 我们希望训练数据中的估计值与实际目标值之间的差异尽可能小,只有这样我们才能称模型为强模型,这意味着它将给出目标的正确值值或至少返回非常非常接近于特定训练记录的目标值的值。 因此,这成为最小化的问题。 差异就是所谓的成本,而最小化函数就是所谓的成本函数。 有几种方法可以达到最低状态。 我们可以简单地将整个训练集上的估计值和目标值之间的差异最小化,或者可以采用平方差或其他一些变化来实现同一目的。 这个功能是最广泛接受且相当合理的成本函数之一,如果您正在学习机器学习算法,那么您将很容易发现它:

This function works well for most of the regression problems. Yeah, I know, I know I said I will keep it simple and not scare you with weird equations. Worry not, we are not going to fill up a giant chalkboard with formulas or formulae if you were to be so formal. Let me give you a quick explanation and make everything crystal clear.
此函数对大多数回归问题都适用。 是的,我知道,我知道我说过我会保持简单,不要用怪异的方程式吓到你。 别担心,我们不会,如果你要这么正式填补了公式或公式一个巨大的黑板。 让我给您一个简短的解释,让一切变得清晰。
J(θ) — Cost Function Notationm — Number of training recordshθ — Hypothesis Functionx(ᶦ)- iᵗʰ training data recordhθ(x(ᶦ)) — Hypothesis Function value for iᵗʰ training recordy(ᶦ)- iᵗʰ target value
J(θ)—成本函数符号m —训练记录数hθ—假设函数x(ᶦ)-iᵗʰ训练数据记录hθ(x(ᶦ))—iᵗʰ训练记录(ᶦ)-iᵗʰ目标值的假设函数值
- As I mentioned before we denote the cost as the difference between the hypothesis function value and the target values 如前所述,我们将成本表示为假设函数值和目标值之间的差
- We have to eventually sum up all the squared differences we get from each training record to get the total cost over the complete training data 我们最终必须总结从每个培训记录中获得的所有平方差,以获取完整培训数据上的总成本
- We perform a squaring of the difference in each case, which has two significant advantages 我们对每种情况的差异进行平方,这有两个明显的优点
The difference between the estimated value from Hypothesis function and the Target value might be negative, squaring it eliminates the possibility of us decreasing the total cost value while summing the differences we get from each training record simply because a few of them turned up to be negative.
假设函数的估计值与目标值之间的差异可能为负,对它进行平方可以消除我们减少总成本值的可能性,同时将我们从每条训练记录中获得的差异相加,只是因为其中一些变成负数。
| Note that we can also take absolute values, but that leads to an issue — absolute value function is much harder to analyse mathematically than a squared function — let me know in the comments if you need further explanation on this — basically the absolute function is not differentiable at all points, something necessary to find the point at which the cost function is at a minima |
| 请注意,我们也可以采用绝对值,但这会导致一个问题-绝对值函数比平方函数难于数学分析-如果需要进一步说明,请在评论中告知我-基本上,绝对函数不是在所有点上都是可微的,这是找到成本函数为最小值的点所必需的。
- Squaring also puts more emphasis on larger differences as the effect of these differences is squared as well. Thus, the contribution of these larger differences increases and stands out. 平方也更加强调较大的差异,因为这些差异的影响也是平方的。 因此,这些较大差异的贡献增加并脱颖而出。
- Performing minimization by differentiating the function over θ values will remove the 1/2 which is present in the formula 通过对θ值求微分来执行最小化将删除公式中存在的1/2
机器学习模型 (Machine Learning Model)
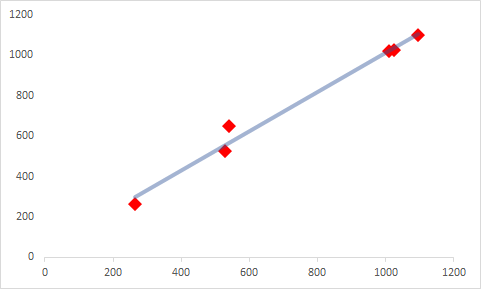
As shown in the Hypothesis trendline graph above, the main objective of minimizing the cost function is to get a straight trendline which covers most of the Target values, or at least is as close to the points as possible. This is why we calculate the differences and write a cost function to reduce them.
如上面的假设趋势线图所示,最小化成本函数的主要目标是要获得一条直线的趋势线,该趋势线可以覆盖大多数目标值,或者至少尽可能接近这些点。 这就是为什么我们计算差异并编写成本函数以减少差异的原因。
And this is not a one-time process, it is more of an iterative process in which we choose our parameters for the Hypothesis function, calculate the estimated values, then use the cost function to find out the cost. After that we minimize this cost and perform the whole activity again. In this way we re-do the whole calculation to get to the point where we think we have the most optimized function. We can check the state of the current result at any time by just plotting the function against the Target values. However, this whole iterative process is what is at the heart of all optimizing algorithms in place today, so you don’t have to perform this activity repeatedly. The most popular one, and you might even have heard about it, is Gradient Descent.
这不是一个一次性的过程,而是一个反复的过程,在该过程中,我们为假设函数选择参数,计算估计值,然后使用成本函数来找出成本。 之后,我们将成本降到最低,然后再次执行整个活动。 这样,我们重新进行了整个计算,以至于认为我们拥有最优化的功能。 只需将函数相对于目标值作图,就可以随时检查当前结果的状态。 但是,整个迭代过程是当今所有优化算法的核心,因此您不必重复执行此活动。 梯度下降是最受欢迎的一种,您甚至可能已经听说过。
And when we do have that Hypothesis function which has the estimated values closest to the Target values, we can take that function and claim it as the function which fit the data in the best possible manner. And there we have our model!
并且当我们的假设函数的估计值最接近目标值时,我们可以采用该函数并将其声明为以最佳方式拟合数据的函数。 在那里,我们有了我们的模型!
In this article, I wanted to write about the general process which is followed when solving any machine learning problem and building a machine learning model. This was more of a theoretical explanation, but I do have more technical guides lines up.
在本文中,我想写一些解决任何机器学习问题并建立机器学习模型时遵循的一般过程。 这更多是理论上的解释,但是我确实有更多的技术指南。
I hope you liked this article. If you have any concerns/questions regarding the content, let me know in the comments!Thanks for reading!
希望您喜欢这篇文章。 如果您对内容有任何疑问/疑问,请在评论中告诉我!谢谢阅读!
Originally published at https://thedatascienceportal.com on August 7, 2020. For more such content head over to thedatascienceportal.
最初于 2020年8月7日 在 https://thedatascienceportal.com 上 发布。 有关更多此类内容,请转到datascienceportal。
翻译自: https://towardsdatascience.com/machine-learning-process-7beab5c4f31b
机器学习中的随机过程