Python文件运行说明书以及解决的过程_一蓑烟雨任平生
文章目录
- 前言
- 一、安装Python环境
-
- 1-安装Python解析器
- 2-安装所需要的包
- 第一步:
- 第二步
- 二、运行Python文件
-
- 1.修改数据库连接
- 2.舆情和特色
- 添加定时器方法如下
-
- 第一:
- 第二:
- 3.供需和价格
-
- 价格遇到的难点1
- 价格遇到的难点2
- 4.文章爬取
- 总结
前言
这篇文章主要是讲解下,爬虫爬取数据的使用方法,针对于有点点电脑基础的人,比如说会开机,会使用鼠标,会打字这些基本方法
一、安装Python环境
1-安装Python解析器
如果你的电脑没有Python环境,是无法运行脚本的,这里有下载好的Python解释器,直接下载即可
链接:Python解析器3.8
提取码:3456
2-安装所需要的包
安装完成后如果想在cmd中运行Python文件,那么就要引入必要的包
在黑窗口中命令如下
pip install 包名
什么时候需要这样子用呢?
例如:
当你使用cmd进行py 文件名.py的时候报错’‘No model request find’’
那这时候就可以pip install request,就可以安装包了
当然国外镜像下载太慢,你可以选择使用国内镜像,这里也给您提供了使用国内镜像的方法
第一步:

在你的用户目录下面创建pip文件夹,名字必须是pip
第二步
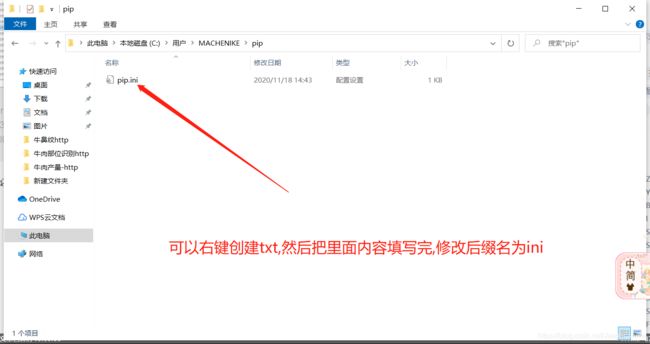
这里给大家粘贴上ini中的配置
[global]
index-url = https://pypi.doubanio.com/simple/
[install]
trusted-host=pypi.doubanio.com
然后你再进行pip的时候就会感觉速度起飞
二、运行Python文件
1.修改数据库连接
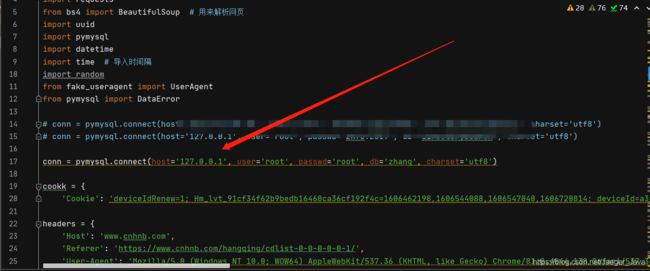
这里修改为你的数据库
2.舆情和特色
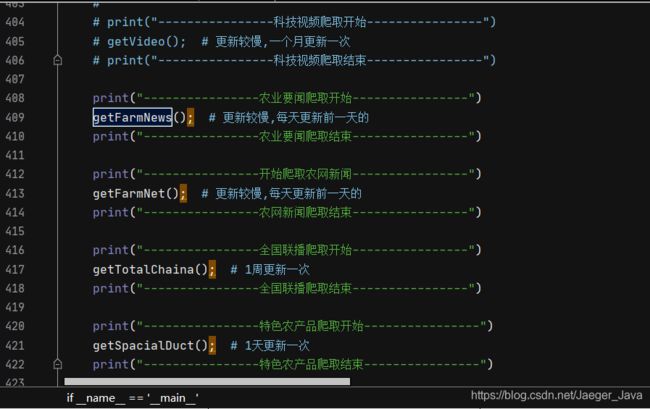
这个文件里面没有添加定时器,每天都要手动运行一次,当然如果在服务器上可以运行的话,可以添加定时器
添加定时器方法如下
第一:
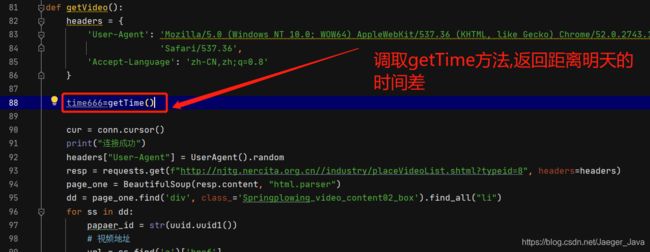
第二:
timer = threading.Timer(timer_start_time, getXuQiuByZhongZi)
timer.start()
创建线程,多久执行此方法
上面是代码下面是截图,方便粘贴

3.供需和价格
这里供需就不需要多说,做好判断了,都是爬取当天的数据,所以定时器也好,手动执行也罢,都可以完美爬取数据,直接执行肯定就可以拿到数据,下面重点说下价格

价格遇到的难点1
用户非登录状态的话无法抓取6页以后数据,但是我代码里有了cookie,使用这个就模拟用户登录,所以不用担心,如果抓取数据每次都到第6页停了,那么就检查下是否设置cookie了即可

价格遇到的难点2
同一IP爬取数据,数据超过10页左右就会让进行滑动验证
解决方案1:延迟爬取不可行,测试了每次抓取数据后线程沉睡5s依旧不行(如果再设置大点时间,没测试爬数据就是要的实时性,太大反而不好)
解决方案2:进行IP代理池,一开始在网上找了很多免费的ip,但是都不能用,还是那句话,免费的都不好用,都是别人用剩下的,这里给大家推荐个IP获取网站
ip获取网站
注册后每天可以领取20个免费IP,有效时间5-20mins
具体获取ip操作步骤如下:

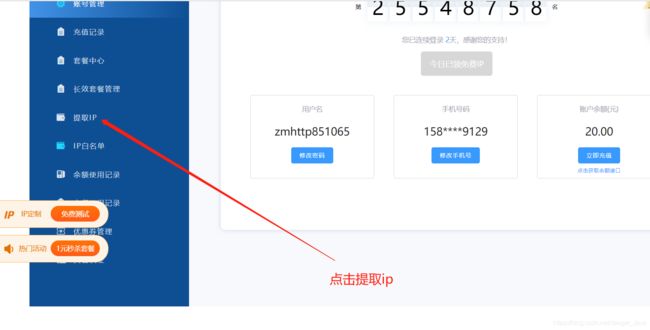

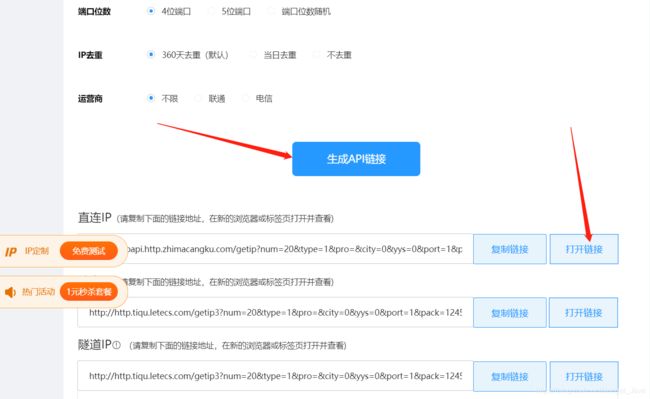
生成IP报错的话提示添加白名单什么的话,那就拉到最下方:

调取这个接口,然后再打开链接 就有IP了

把价格里面的IP都替换掉

这样就可以一页一个ip爬取,这样子就不会让你进行滑动验证了
解决方案3:你可以进行破解滑动验证,当然那属于算法类的了,每次计算图形坐标,拉动距离,填补面积,这些有点深了,我现在没研究过,但是那个领域有空了一定要深入下
4.文章爬取
文章网址更新过慢,有时候半年更新一次,也有时候一个月更新一次,这个就没数据了,运行一下,填充一下吧
总结
文章写得很详细,慢慢体会,慢慢学习,遇到困难了百度下,还解决不了,可以私信我(o)/~
