使用scrapy爬取前程无忧所有大数据岗位并做出数据可视化
项目目录
- 项目要求
- 工具
-
-
- 软件
- 具体知识点
-
- 具体要求
-
-
- 数据源
- 爬取字段
- 数据存储
- 数据分析与可视化
-
- 具体步骤
-
-
- 分析网页
- 实现代码
-
-
- 抓取全部岗位的网址
- 字段提取
-
- 可视化
-
-
- 分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资,并作条形图将结果展示出来
- 分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数,并做条形图将结果展示出来
- 分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资),并做出条形图展示出来
- 将数据采集岗位要求的技能做出词云图
-
-
- 总结经验
项目要求
利用python编写爬虫程序,从招聘网上爬取数据,将数据存入到MongoDB中,将存入的数据作一定的数据清洗后分析数据,最后做数据可视化。
工具
软件
python 3.7
pycharm 2020.1.2
具体知识点
python基础知识
scrapy框架知识点
pyecharts 1.5
MongoDB
具体要求
数据源
前程无忧
爬取字段
职位名称、薪资水平、招聘单位、工作地点、工作经验、学历要求、工作内容(岗位职责)、任职要求(技能要求)
数据存储
将爬取到的数据保存在MongoDB中
数据分析与可视化
具体要求
(1) 分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资,并作条形图将结果展示出来。
(2)分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数,并做条形图将结果展示出来。
(3)分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资),并做出条形图展示出来;
(4)将数据采集岗位要求的技能做出词云图
具体步骤
分析网页
点击进入网页
我们先来看看网页构造。再来分析思路:
由于我们需要的大数据岗位的分布数据,所以我们就直接搜索条件,分析大数据岗位在全国的一个分布情况。
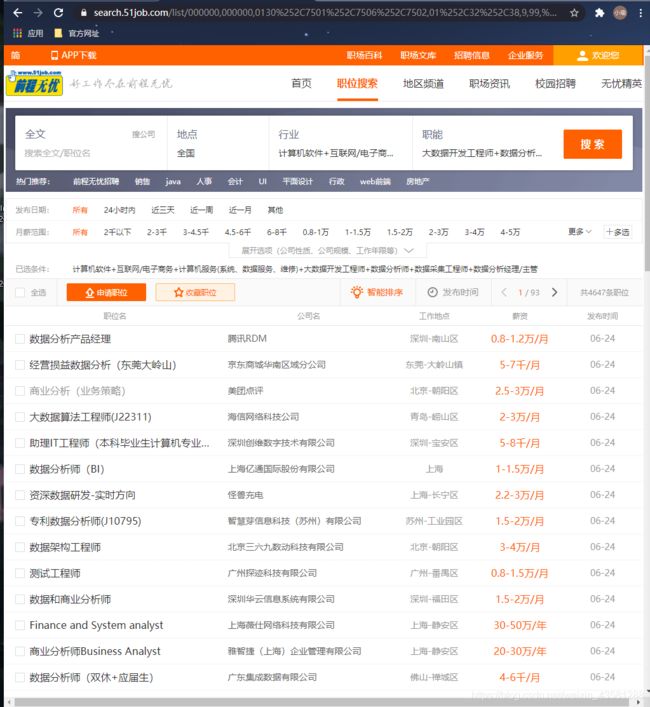
我的思路是,既然需要字段,而且这个页面上的所有字段并没有我们需要的全部,那我们就需要进入到每一个网址里面去分析我们的字段。先来看看进去后是什么样子。
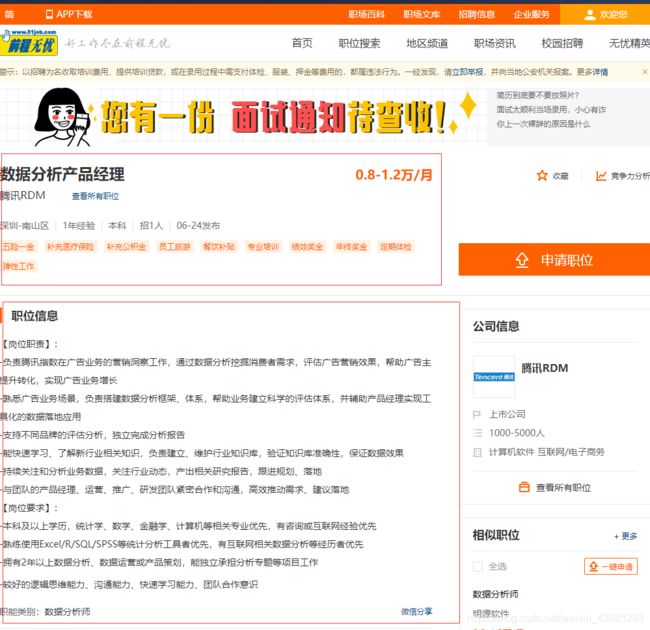
我们需要的字段都在这里面了,所以,我们就可以开始动手写代码了。
实现代码
抓取全部岗位的网址
我们之前说过,要进入到每一个网址去,那么就必然需要每一个进去的入口,而这个入口就是这个:
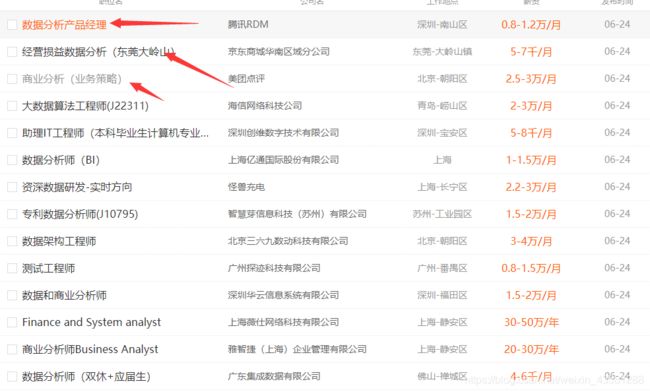
新建一个爬虫项目:
scrapy startproject qianchengwuyou
然后打开我们的项目,进入瞅瞅会发现啥都没有,我们再cd到我们的项目里面去开始一个爬虫项目
scrapy genspider qcwy https://search.51job.com/
当然,这后边的网址就是你要爬取的网址。
首先在开始敲代码之前,还是要设置一下我们的配置文件settings.py中写上我们的配置信息:
# 关闭网页机器人协议
ROBOTSTXT_OBEY = False
# mongodb地址
MONGODB_HOST='127.0.0.1'
# mongodb端口号
MONGODB_PORT = 27017
# 设置数据库名称
MONGODB_DBNAME = '51job'
# 存放本数据的表名称
MONGODB_DOCNAME = 'jobTable'
# 请求头信息
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User_Agent' :'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'
}
# 下载管道
ITEM_PIPELINES = {
'qianchengwuyou.pipelines.QianchengwuyouPipeline': 300,
}
# 下载延时
DOWNLOAD_DELAY = 1
然后再去我们的pipelines.py中开启我们的爬虫保存工作
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
import pymongo
class QianchengwuyouPipeline:
def __init__(self):
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
self.client = pymongo.MongoClient(host=host,port=port)
self.db = self.client[settings['MONGODB_DBNAME']]
self.coll = self.db[settings['MONGODB_DOCNAME']]
def process_item(self, item, spider):
data = dict(item)
self.coll.insert(data)
return item
def close(self):
self.client.close()
定义好pipelines.py之后,我们还需要去items.py中去定义好我们需要爬取的字段,用来向pipelines.py中传输数据
import scrapy
class QianchengwuyouItem(scrapy.Item):
zhiweimingcheng = scrapy.Field()
xinzishuipin = scrapy.Field()
zhaopindanwei = scrapy.Field()
gongzuodidian = scrapy.Field()
gongzuojingyan = scrapy.Field()
xueli = scrapy.Field()
yaoqiu = scrapy.Field()
jineng = scrapy.Field()
然后就可以在我们的qcwy.py中开始敲我们的代码了;
在敲代码之前,还是要先分析一下网页结构。打开审查工具,看看我们需要的网址用xpath语法该怎么写:

我们需要拿到的是这个超链接,然后才能用框架去自动进入这个超链接提取超链接里面的内容。
再来分析分析他的文档树结构是什么样子的:
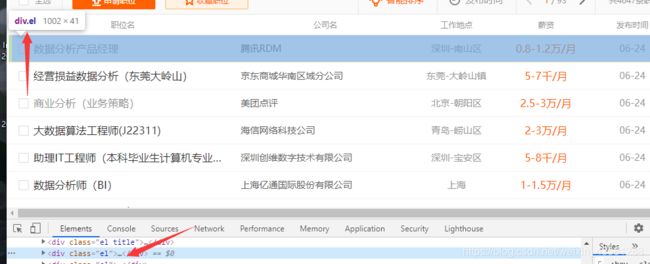
可以很清晰的看到,这个整个栏目都在div class='el'下,而且所有的招聘岗位都在这下面,所以,我们为了能够拿到所有的url,就可以去定位他的上一级标签,然后拿到所有子标签。再通过子标签去拿里面的href属性。
所以,xpath语法就可以这样写:
//*[@id='resultList']/div[@class='el']/p/span/a/@href
我们来打印一下试试:
import scrapy
from qianchengwuyou.items import QianchengwuyouItem
class QcwySpider(scrapy.Spider):
name = 'qcwy'
allowed_domains = ['https://www.51job.com/']
start_urls = ['https://search.51job.com/list/000000,000000,0130%252C7501%252C7506%252C7502,01%252C32%252C38,9,99,%2520,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=']
def parse(self, response):
all_urls = response.xpath("//*[@id='resultList']/div[@class='el']/p/span/a/@href").getall()
for url in all_urls:
print(url)
接着我们再写一个启动函数:
在当前项目的任何位置新建一个main.py(名字随便你起,体现出启动俩字就行),然后写上这两行代码:
from scrapy.cmdline import execute
execute("scrapy crawl qcwy".split())
这个意思就是从scrapy包的cmdline下导入execute模块,然后,用这个模块去运行当前项目;
运行结果:
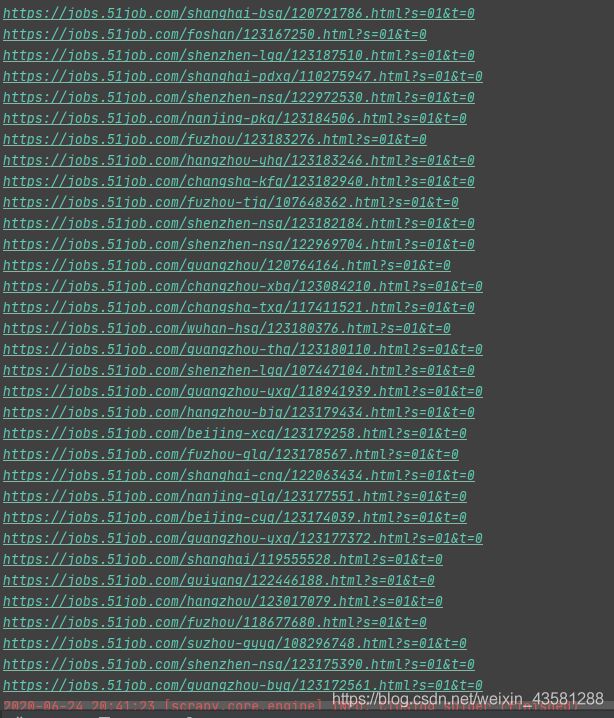
我们拿到所有超链接之后,还不够。要记住,我们需要的所有页面的超链接。所以,我们再来分析分析每一页之间的规律。注意看最上方的url:
https://search.51job.com/list/000000,000000,0130%252C7501%252C7506%252C7502,01%252C32%252C38,9,99,%2B,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
当我们点击下一页的时候,看看url发生了哪些变化:
https://search.51job.com/list/000000,000000,0130%252C7501%252C7506%252C7502,01%252C32%252C38,9,99,%2B,2,2.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
有没有发现,中间的1.html变成了2.html;
我们再来看看,一共有多少页:
![]()
93页。那我们直接把93输入进去替换掉会怎么样:
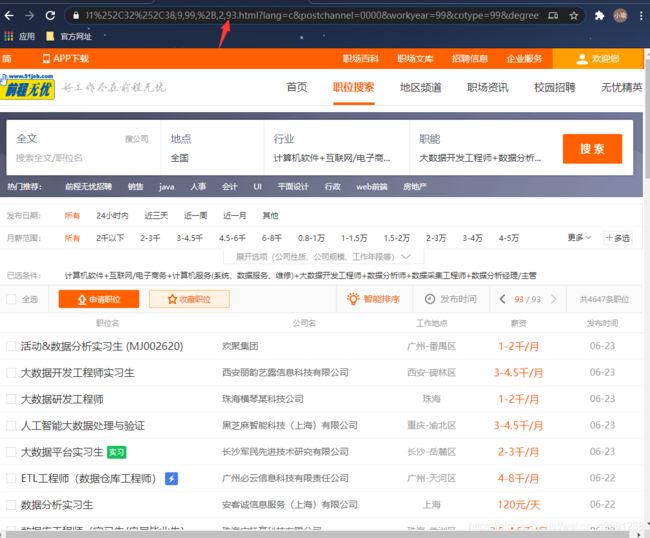
果不其然,规律就是这个样子的。那你知道怎么去获取全部网页的xpath了吧
但是
我跳转下一页不喜欢这样跳,这样跳,每一次我还得去找规律,一大串网址麻烦的不要不要的,所以,给你们说一种新方法;
我们来看看下一页的url,用xpath该怎么去获取:
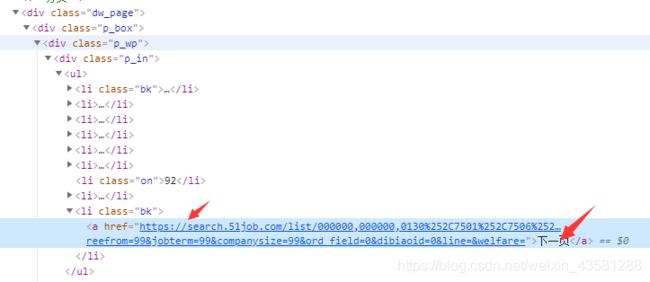
看到这个标签之后,再看看我打的箭头,知道我要干什么了吧。我们可以直接写xpath语法去获取这个url,如果有,就交给解析函数去解析当前页的网址,没有的话就结束函数的运行:
看看xpath语法该咋写:
//div[@class='p_in']//li[last()]/a/@href
所以我们只需要做如下判断:
next_page = response.xpath("//div[@class='p_in']//li[last()]/a/@href").get()
if next_page:
yield scrapy.Request(next_page,callback=self.parse,dont_filter=True)
如果有下一页,就继续交给parse()函数去解析网址;
我们再回到之前的问题,我们拿到当前页的招聘网址之后,就要进入到这个网址里面;所以,我们就需要一个解析页面的函数去解析我们的字段;
所以我们全部的代码如下:
import scrapy
from qianchengwuyou.items import QianchengwuyouItem
class QcwySpider(scrapy.Spider):
name = 'qcwy'
allowed_domains = ['https://www.51job.com/']
start_urls = ['https://search.51job.com/list/000000,000000,0130%252C7501%252C7506%252C7502,01%252C32%252C38,9,99,%2520,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=']
def parse(self, response):
all_urls = response.xpath("//*[@id='resultList']/div[@class='el']/p/span/a/@href").getall()
for url in all_urls:
yield scrapy.Request(url,callback=self.parse_html,dont_filter=True)
next_page = response.xpath("//div[@class='p_in']//li[last()]/a/@href").get()
if next_page:
yield scrapy.Request(next_page,callback=self.parse,dont_filter=True)
我们就单独再写一个parse_html()函数去解析页面就行了;
这样就能抓取到93页全部招聘网址;
字段提取
我们随便点进去一个招聘信息瞅一瞅;
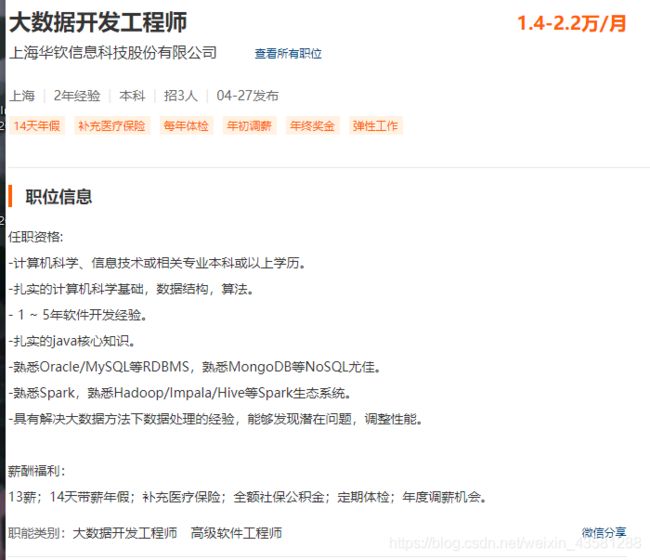
我们需要的是这里面的字段信息;
还是老样子,打开审查工具看看构造是什么样的;

我们很大一部分的信息都在这个标签里面,所以,我们就可以单独在这个标签中拿到我们需要的信息。所以,我这儿就直接把xpath语法贴出来,至于怎么分析怎么写,上面讲过了;
zhiweimingcheng = response.xpath("//div[@class='cn']/h1/text()").getall()[0]
xinzishuipin = response.xpath("//div[@class='cn']//strong/text()").get()
zhaopindanwei = response.xpath("//div[@class='cn']//p[@class='cname']/a[1]/@title").get()
gongzuodidian = response.xpath("//div[@class='cn']//p[@class='msg ltype']/text()").getall()[0]
gongzuojingyan = response.xpath("//div[@class='cn']//p[@class='msg ltype']/text()").getall()[1]
xueli = response.xpath("//div[@class='cn']//p[@class='msg ltype']/text()").getall()[2]
我们除了这些字段,还需要任职要求和技能要求。我们再看看,下面的职位信息这个标签中的内容;
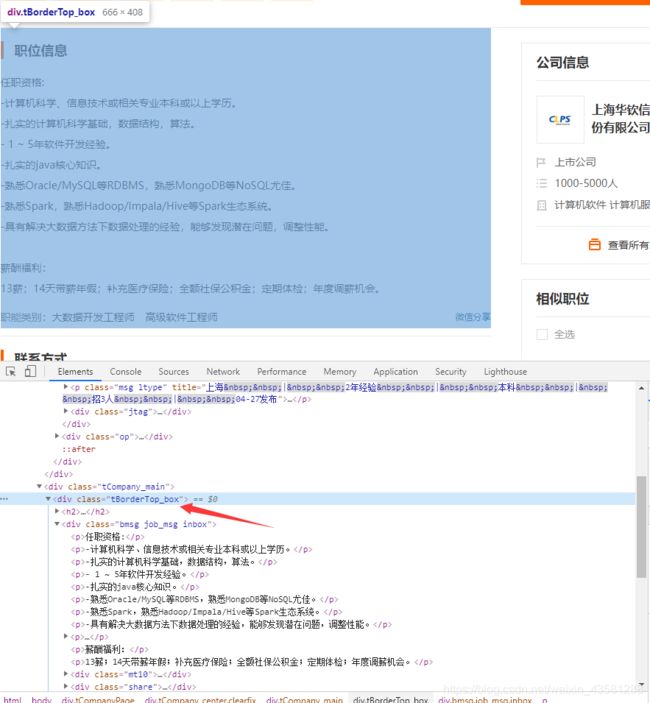
我们需要的内容都在这个标签里面。但是,这些技能标签我们该怎么去提取呢。我也没想到办法,所以我干脆就不提取这里面的技能,我们重新打开一个招聘信息看看;

看见没有,有关键字。所以我们就可以把这个关键字拿来当我们需要的技能标签。
但是又有细心的小伙伴发问了,有的没有关键字这一栏咋办,那岂不是找不到标签会报语法错误。
so,你是忘了你学过的try except语法了吗。
所以,我们抓取全部的字段,就可以这样来写:
def parse_html(self,response):
item = QianchengwuyouItem()
try:
zhiweimingcheng = response.xpath("//div[@class='cn']/h1/text()").getall()[0]
xinzishuipin = response.xpath("//div[@class='cn']//strong/text()").get()
zhaopindanwei = response.xpath("//div[@class='cn']//p[@class='cname']/a[1]/@title").get()
gongzuodidian = response.xpath("//div[@class='cn']//p[@class='msg ltype']/text()").getall()[0]
gongzuojingyan = response.xpath("//div[@class='cn']//p[@class='msg ltype']/text()").getall()[1]
xueli = response.xpath("//div[@class='cn']//p[@class='msg ltype']/text()").getall()[2]
yaoqius = response.xpath("//div[@class='bmsg job_msg inbox']//text()").getall()
yaoqiu_str = ""
for yaoqiu in yaoqius:
yaoqiu_str+=yaoqiu.strip()
jineng = ""
guanjianzi = response.xpath("//p[@class='fp'][2]/a/text()").getall()
for i in guanjianzi:
jineng+=i+" "
except:
zhiweimingcheng=""
xinzishuipin=""
zhaopindanwei = ""
gongzuodidian = ""
gongzuojingyan =""
xueli = ""
yaoqiu_str = ""
jineng = ""
当然,这些字段抓取到了然后呢,总得需要去想个办法保存到MongoDB中吧,所以,我们就可以通过之前定义好的items来保存数据;
so,你看了这么久,终于等到主页的全部代码了,我也废话讲了这么一大片了:
# -*- coding: utf-8 -*-
import scrapy
from qianchengwuyou.items import QianchengwuyouItem
class QcwySpider(scrapy.Spider):
name = 'qcwy'
allowed_domains = ['https://www.51job.com/']
start_urls = ['https://search.51job.com/list/000000,000000,0130%252C7501%252C7506%252C7502,01%252C32%252C38,9,99,%2520,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=']
def parse(self, response):
all_urls = response.xpath("//*[@id='resultList']/div[@class='el']/p/span/a/@href").getall()
for url in all_urls:
yield scrapy.Request(url,callback=self.parse_html,dont_filter=True)
next_page = response.xpath("//div[@class='p_in']//li[last()]/a/@href").get()
if next_page:
yield scrapy.Request(next_page,callback=self.parse,dont_filter=True)
def parse_html(self,response):
item = QianchengwuyouItem()
try:
zhiweimingcheng = response.xpath("//div[@class='cn']/h1/text()").getall()[0]
xinzishuipin = response.xpath("//div[@class='cn']//strong/text()").get()
zhaopindanwei = response.xpath("//div[@class='cn']//p[@class='cname']/a[1]/@title").get()
gongzuodidian = response.xpath("//div[@class='cn']//p[@class='msg ltype']/text()").getall()[0]
gongzuojingyan = response.xpath("//div[@class='cn']//p[@class='msg ltype']/text()").getall()[1]
xueli = response.xpath("//div[@class='cn']//p[@class='msg ltype']/text()").getall()[2]
yaoqius = response.xpath("//div[@class='bmsg job_msg inbox']//text()").getall()
yaoqiu_str = ""
for yaoqiu in yaoqius:
yaoqiu_str+=yaoqiu.strip()
jineng = ""
guanjianzi = response.xpath("//p[@class='fp'][2]/a/text()").getall()
for i in guanjianzi:
jineng+=i+" "
except:
zhiweimingcheng=""
xinzishuipin=""
zhaopindanwei = ""
gongzuodidian = ""
gongzuojingyan =""
xueli = ""
yaoqiu_str = ""
jineng = ""
finally:
item["zhiweimingcheng"] = zhiweimingcheng
item["xinzishuipin"] = xinzishuipin
item["zhaopindanwei"] = zhaopindanwei
item["gongzuodidian"] = gongzuodidian
item["gongzuojingyan"] = gongzuojingyan
item["xueli"] = xueli
item["yaoqiu"] = yaoqiu_str
item["jineng"] = jineng
yield item
然后,保存数据就简单了,我们去pipelines.py中连接到我们的MongoDB,然后保存数据进去;由于保存数据太简单,百度上一搜就能搜到,我就直接贴代码出来了:
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
import pymongo
class QianchengwuyouPipeline:
def __init__(self):
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
self.client = pymongo.MongoClient(host=host,port=port)
self.db = self.client[settings['MONGODB_DBNAME']]
self.coll = self.db[settings['MONGODB_DOCNAME']]
def process_item(self, item, spider):
data = dict(item)
self.coll.insert(data)
return item
def close(self):
self.client.close()
然后,开始我们的爬虫启动;
由于这个爬虫不是分布式,所以,要一条一条的请求,会很慢很慢,你可以在这个时间去吃个饭,看个电影都行;
最后看看我们拿到的数据是什么样子的;
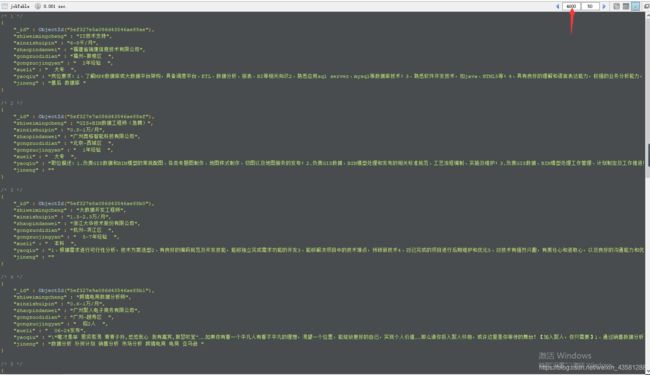
一共有4600条数据;整整爬了一个多小时,后期改进;
可视化
分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资,并作条形图将结果展示出来
新建一个文件,名字自己起,我的叫数据可视化.py
然后需要连接mongodb和做条形图,就导入下面的这些库,re用来提取一些不方便取出来的数据
import pymongo
import re
from pyecharts.charts import Bar
from pyecharts import options as opts
myclient = pymongo.MongoClient("127.0.0.1",port=27017)
mydb = myclient["51job"]
mytable = mydb["jobTable"]
先来分析分析需要哪些东西(这儿我就先分析一个,其他两个是一样的道理);
- 首先,岗位名称是数据分析
- 然后要三个变量来保存最低、最高、平均薪资。
因为岗位是数据分析,但是招聘岗位不可能就这四个字。所以我们需要用到模糊查询,类似于mysql中的like。求工资,平均工资直接就最低+最高然后除2,所以,这儿就用正则语法来提取有最低和最高工资的标签栏。
多个条件用$and连接;
看看条件怎么写吧;
shujufenxi_query = {
"$and":
[{
"zhiweimingcheng": {
"$regex": "数据分析"}},
{
"xinzishuipin": {
"$regex": "万/月"}}
]
}
然后定义三个列表,用来保存三种数据,后面用来给柱状图传参;
所以代码如下:
def shujufenxi(query):
min_salary_list = []
max_salary_list = []
average_salary_list = []
addr_list = []
for i in mytable.find(query):
min_salary = i["xinzishuipin"].split("-")[0]
# print(min_salary)
max_salary = re.findall(r'([\d+\.]+)', (i["xinzishuipin"].split("-")[1]))[0]
average_salary = "{:.1f}".format((float(min_salary) + float(max_salary)) / 2)
company = i["gongzuodidian"]
print(company)
min_salary_list.append(min_salary)
max_salary_list.append(max_salary)
average_salary_list.append(average_salary)
addr_list.append(company)
bar = Bar(
init_opts=opts.InitOpts(width="1800px", height="800px"),
)
bar.set_global_opts(
title_opts=opts.TitleOpts(title="数据分析工程师薪资", subtitle="单位 万/月"),
xaxis_opts=opts.AxisOpts(axislabel_opts={
"rotate": 45}),
)
bar.add_xaxis(addr_list)
bar.add_yaxis("最高薪资", max_salary_list)
bar.add_yaxis("最低薪资", min_salary_list)
bar.add_yaxis("平均薪资", average_salary_list)
bar.render("数据分析工程师.html")
其他两个道理是一样的道理,我就不写代码了;自己慢慢摸索吧。
我们来看看数据展示的效果图;由于数据量太大,展示出来已经面目全非了,后期改进;
分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数,并做条形图将结果展示出来
其实这个图和前面做的图步骤也差不多;
我就直接贴代码上去了;
import pymongo
import re
from pyecharts.charts import Bar
from pyecharts import options as opts
myclient = pymongo.MongoClient("127.0.0.1",port=27017)
mydb = myclient["51job"]
mytable = mydb["jobTable"]
query_chengdu = {
"$and":
[{
"gongzuodidian":{
"$regex":"成都"}},
{
"zhiweimingcheng": {
"$regex": "数据分析"}}
]
}
query_beijing = {
"$and":
[{
"gongzuodidian":{
"$regex":"北京"}},
{
"zhiweimingcheng": {
"$regex": "数据分析"}}
]
}
query_shanghai = {
"$and":
[{
"gongzuodidian":{
"$regex":"上海"}},
{
"zhiweimingcheng": {
"$regex": "数据分析"}}
]
}
query_guangzhou = {
"$and":
[{
"gongzuodidian":{
"$regex":"广州"}},
{
"zhiweimingcheng": {
"$regex": "数据分析"}}
]
}
query_shenzhen = {
"$and":
[{
"gongzuodidian":{
"$regex":"深圳"}},
{
"zhiweimingcheng": {
"$regex": "数据分析"}}
]
}
chengdu_num = 0
beijing_num = 0
shanghai_num = 0
guangzhou_num = 0
shenzhen_num = 0
for i in mytable.find():
if "成都" in i["gongzuodidian"]:
chengdu_num+=1
elif "北京" in i["gongzuodidian"]:
beijing_num+=1
elif "上海" in i["gongzuodidian"]:
shanghai_num+=1
elif "广州" in i["gongzuodidian"]:
guangzhou_num+=1
elif "深圳" in i["gongzuodidian"]:
shenzhen_num+=1
print(chengdu_num,beijing_num,shanghai_num,guangzhou_num,shenzhen_num)
addr = ["成都","北京","上海","广州","深圳"]
num = [chengdu_num,beijing_num,shanghai_num,guangzhou_num,shenzhen_num]
bar = Bar(init_opts=opts.InitOpts(width="1800px", height="800px"))
bar.set_global_opts(
title_opts=opts.TitleOpts(title="数据分析师地区岗位个数", subtitle="单位 个"),
xaxis_opts=opts.AxisOpts(axislabel_opts={
"rotate": 45}),
)
bar.add_xaxis(addr)
bar.add_yaxis("数据分析师地区岗位个数", num)
bar.render("数据分析师地区岗位个数.html")
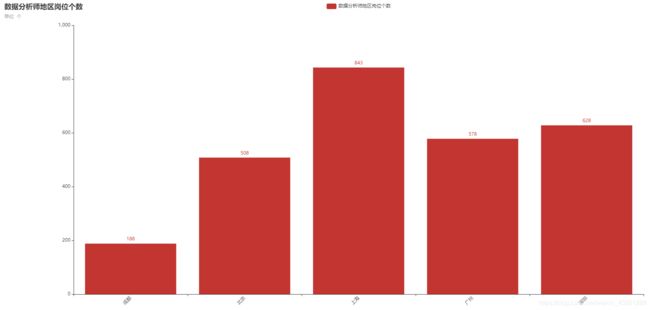
看看运行结果啥样的:
分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资),并做出条形图展示出来
这些图都没啥水平,无非就是查询条件不一样;
看看结果啥样的:

也是乱的一批,数据太多,过滤之后也是这个鬼样子;
将数据采集岗位要求的技能做出词云图
还记得我们之前写的那个关键词吗,对,没错,我们就是要用这个来做词云图。
词云图还是使用pyecharts自带的WordCloud来搞定;
因为我们拿到的所有关键字,在之前用了空白去替换,也就是说,做出来的词云图会有瑕疵,也就需要我们去想办法去过滤一遍。其中的逻辑就交给你们自己想想该怎么去过滤儿。我就负责给你们思路;
- 因为词云图会根据你元素出现的次数来判断大小,所以,我们需要统计每个元素出现的次数
- 其次,你还要过滤空白,还有一些特殊字符
最后给你们展示一下词云图的效果;

总结经验
这个项目,实用性还是很强,用到的知识点也很广泛,对巩固基础也有很好的效果。
唯一美中不足的地方就是爬行速度太慢,建议使用分布式或者多线程模式爬取。
谢谢观看 ~~~