Android回炉系列之Surfaceflinger
Android回炉系列之Surfaceflinger
文章目录
- Android回炉系列之Surfaceflinger
-
- 前言
- 1. Surfaceflinger是什么?
- 2. Surfaceflinger
-
- 2.1 特点一
- 2.2 特点二
- 2.3 特点三
- 2.4 特点四
- 2.5 特点五
- 3. 小结
- 4. Surfaceflinger初始化
-
- 4.1 初始化涉及文件
- 4.2 Android.bp浏览
- 4.3 Surfaceflinger.rc
- 4.4 main_surfaceflinger.cpp
- 4.5 Surfaceflinger实例化
-
- 4.5.1 DispSync初始化
- 4.5.2 图元队列调度
- 4.6 Surfaceflinger初始化
-
- 4.6.1 EventThread|DispSyncSource的初始化
- 4.6.2 EventThread实例化
- 4.6.3 Surfaceflinger的EventThread初始化
- 4.6.4 监听
- 4.6.5 BitTube
- 4.6.6 事件监听过程
- 4.7 RenderEngine初始化
- 4.8 HWComposer初始化
-
- 4.8.1 HWComposer初始化
- 4.8.2 HWComposer监听
- 4.8 Surfaceflinger的run
前言
很早开始就有想写写博客的想法,毕竟好记心不如烂笔头,这段时间公司业务要求,对音视频、渲染等要有深度理解,突然之间发现自己脑袋是空空的,没办法就只有系统性的回炉一遍,同时也做好存档,以便于后期的复习、升华做铺垫!好了废话不多说了。我们首先从界面绘制渲染开始,竟然是绘制那么针对我们Android系统而言我们是怎么把视图呈现给用户的呢?带着这个疑惑,我们就从surfaceflinger开始一一解析。
1. Surfaceflinger是什么?
通过查阅源码发现surfaceflinger几乎贯通了Android所有领域的知识,从硬件抽象层到framework层,CPU响应处理到OpenGL等等硬件绘制,复杂~。。。所以本文不针对细则逻辑做描述,我们从架构解析开始,来了解它的设计思想。
surfaceflinger是整个Android系统渲染的核心进程,所有的应用的渲染逻辑最后都会来到surfaceflinger进行处理,最有在把处理后的图像数据交给CPU/GPU绘制在屏幕上。
2. Surfaceflinger
在学习之前给出其总结的五个特点。以便后面的细则理解和设计结构的理解。
2.1 特点一
surfaceflinger在Android系统中并不是担当渲染角色,而是一个工具(“传输机器”),把每个应用传输过来的图元数据处理后交给CPU||GPU做绘制处理。
2.2 特点二
由于针对每个应用而言都是以Surface做为一个图元为传输单位,向surfaceflinger传输图元数据。如下图:
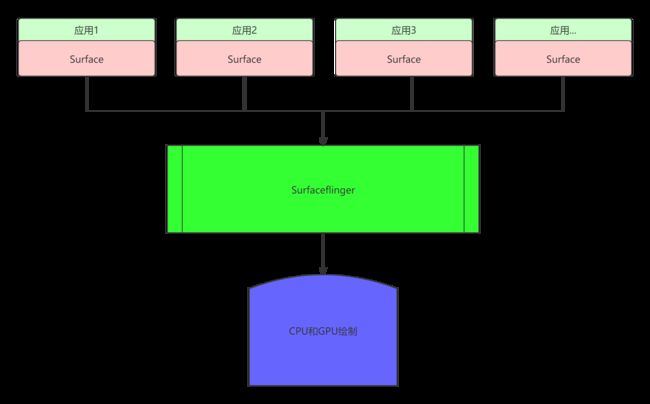
2.3 特点三
通过阅读发现Surfaceflinger设计核心思想就是以生产者和消费者的模式,会把每一个应用的Surface图元保存到SufaceflingerQueue队列中,Surfaceflinger作为消费者会根据一定的逻辑规则把生产者放入Surface一一处理。如下图:
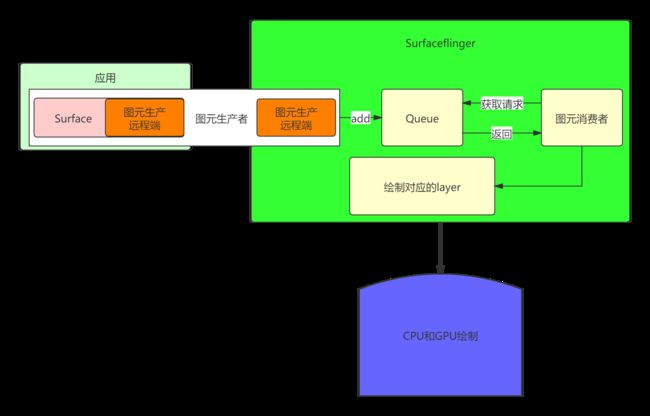
2.4 特点四
由于应用进程和Surfaceflinger是两个独立的进程,那么图元数据是怎么实现传输的呢?这里就需要跨进程通信,这里就会连锁反应想到socket和binder但是由于socket需要拷贝两次在效率上不可取,binder又有大小限制好像是1M不到还要包括其它的通信也不可取,所以为了解决这个问题,Android系统使用了共享内存(匿名共享内存ion),匿名共享内存也只需要拷贝一次的进程通信方式,听大神说比较接近Linux共享内存。具体实现方式后期在学习~如下图:
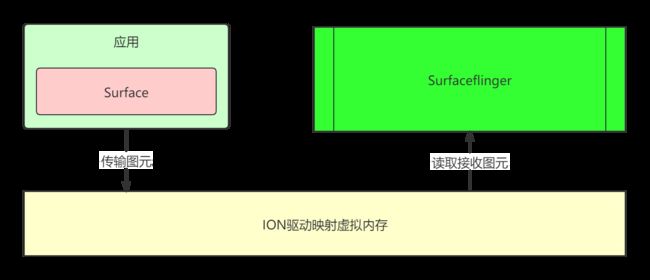
2.5 特点五
Surfaceflinger底层有一个时间钟在不断循环,从硬件中发出或者从软件模拟发出记时唤起,每个一段时间(16ms)都会获取Surfaceflinger中的图元队列通过CPU/GPU绘制到屏幕上。这个特点有点绕,因为此特点应用有办法通知Surfaceflinger渲染模式,Surfaceflinger绘制屏幕有自身回调自身特点等。如下图:

PS:对于相位和Vsync(垂直信号)的介绍我们会在后续同步。
3. 小结
上述五点就是Surfaceflinger的设计核心特点,按照这五个特点阅读可以降低其复杂性。那么Surfaceflinger和skia有什么关系呢?和顶层View的绘制又有什么关系呢?
我们通过层级区分如下:
- framework面向应用开发者的View是便于开发的控件,里面提供了当前控制的属性以及功能。
- Skia是Android对于屏幕的画笔,经过View的onDraw方法回调,把需要绘制的东西通过Skia绘制成像素图元保存起来。
- Surfaceflinger是最后接收Skia的绘制结果,最后同步到屏幕上。
所以,Skia是Android渲染的核心,最终Skia和系统结合起来才是一个完整的渲染体系。如下图:
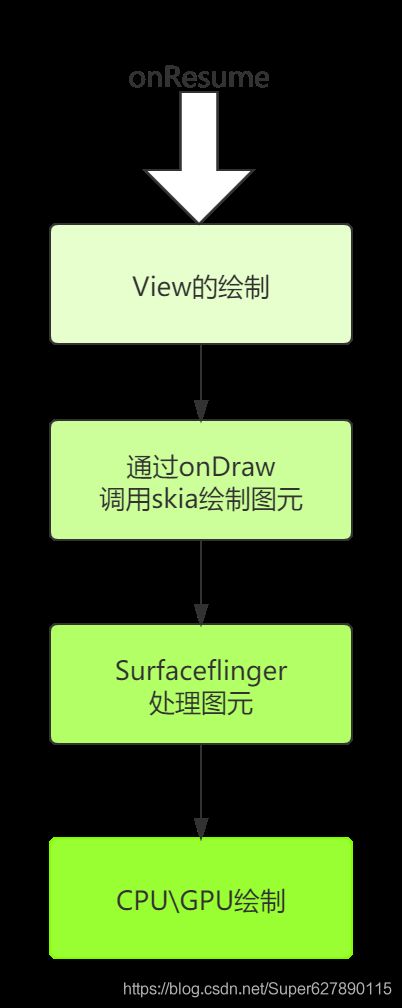
4. Surfaceflinger初始化
针对初始化我们通过代码结合形式来分析代码来至版本9.0。在阅读源码做下铺垫,首先我们先弄清楚EGL/OPENGL ES,Displayhardware,Gralloc,FramcbuffernativeWindow等等之间的关系。如下图:
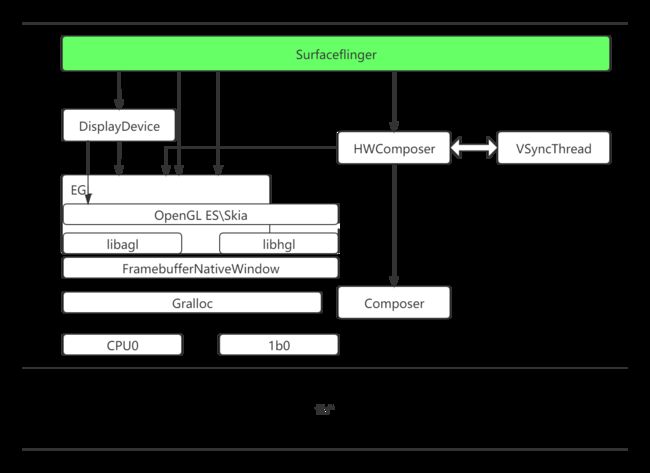
- Android HAL层提供了Gralloc,包括fb和gralloc两个设备。前者负责打开内核中的framebuffer、初始化配置,提供Post,setSwapInsterval等操作接口;后者者管理针缓冲区的分配和释放。这就意味着上层元素只能通过Gralloc来访问帧缓冲区,从而保证系统对framebuffer的有序使用和统一管理。
- 另外HAL层的另一个重要模块Conposer它是为厂商自制UI合成提供接口,它的直接使用者是surfaceflinger中的HWConposer,同时还负责VSync信号的产生和控制。VSync是一种同步机制,可以是硬件产生,也可以通过软件来模拟Thread。
- 由于OpenGL ES是一个通用的函数库,在不同的平台系统上需要被本地化及就是把它具体的平台窗口系统联系起来。FramebufferNativeWindow主要就是负责OpenGL ES在Android平台上本地化的中介之一。还有一个本地窗口Surface。为OpenGL ES配置本地窗口的是EGL。
- OpenGL ES 只是一个接口协议,具体实现既可以采用软件,也可以依托于硬件。那么OpenGLES 动态运行时是如何取舍的?这个就是EGL的作用之一,它回去读取egl.cfg这个配置文件,然后根据设定动态加赞libagl||libhgl。
- surfaceflinger中持有一个数组mDisplays来描述系统中支持的显示设备及Display,它是由surfaceflinger在readyToRun中判断并赋值,并且在DisplayDevice在初始化时还将调用eglgetDisplay,eglcreateWindowSurface等,并利用EGL来完成OpenGLES的环境搭建。。。
4.1 初始化涉及文件
- /frameworks/native/services/surfaceflinger/Android.bp
- /frameworks/native/services/surfaceflinger/surfaceflinger.rc
- /frameworks/native/services/surfaceflinger/main_surfaceflinger.cpp
- /frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
- /frameworks/native/services/surfaceflinger/DispSync.cpp
- /frameworks/native/services/surfaceflinger/MessageQueue.cpp
- /frameworks/native/services/surfaceflinger/EventThread.cpp
- /frameworks/native/services/surfaceflinger/MessageQueue.cpp
- /frameworks/native/libs/gui/BitTube.cpp
- /frameworks/native/services/surfaceflinger/EventThread.cpp
- /frameworks/native/libs/gui/DisplayEventReceiver.cpp
- /frameworks/native/services/surfaceflinger/MessageQueue.cpp
- /frameworks/native/services/surfaceflinger/DisplayHardware/ComposerHal.cpp
- /frameworks/native/services/surfaceflinger/DisplayHardware/HWComposer.cpp
- /frameworks/native/services/surfaceflinger/DisplayHardware/HWComposer.cpp
- /frameworks/native/services/surfaceflinger/DisplayHardware/HWC2.cpp
- /frameworks/native/services/surfaceflinger/EventControlThread.cpp
- /frameworks/native/services/surfaceflinger/MessageQueue.cpp
4.2 Android.bp浏览
需要明白Surfaceflinger的启动需要先了解其涉及的模块,bp文件路径: /frameworks/native/services/surfaceflinger/Android.bp
对应代码如下:
cc_defaults {
name: "libsurfaceflinger_defaults",
defaults: ["surfaceflinger_defaults"],
cflags: [
"-DGL_GLEXT_PROTOTYPES",
"-DEGL_EGLEXT_PROTOTYPES",
],
shared_libs: [
"[email protected]",
"android.hardware.configstore-utils",
"[email protected]",
"[email protected]",
"[email protected]",
"[email protected]",
"[email protected]",
"[email protected]",
"libbase",
"libbinder",
"libbufferhubqueue",
"libcutils",
"libdl",
"libEGL",
"libfmq",
"libGLESv1_CM",
"libGLESv2",
"libgui",
"libhardware",
"libhidlbase",
"libhidltransport",
"libhwbinder",
"liblayers_proto",
"liblog",
"libpdx_default_transport",
"libprotobuf-cpp-lite",
"libsync",
"libtimestats_proto",
"libui",
"libutils",
"libvulkan",
],
static_libs: [
"libserviceutils",
"libtrace_proto",
"libvkjson",
"libvr_manager",
"libvrflinger",
],
header_libs: [
"[email protected]",
"[email protected]",
],
export_static_lib_headers: [
"libserviceutils",
],
export_shared_lib_headers: [
"[email protected]",
"[email protected]",
"[email protected]",
"libhidlbase",
"libhidltransport",
"libhwbinder",
],
}
cc_library_headers {
...
}
filegroup {
name: "libsurfaceflinger_sources",
srcs: [
...
],
}
cc_library_shared {
name: "libsurfaceflinger",
defaults: ["libsurfaceflinger_defaults"],
...
}
cc_binary {
name: "surfaceflinger",
defaults: ["surfaceflinger_defaults"],
init_rc: ["surfaceflinger.rc"],
srcs: ["main_surfaceflinger.cpp"],
...
}
...
Surfaceflinger中涉及的几个核心:
- [email protected] (图元生成器抽象硬件层的实现)
- [email protected](hwc图层合成抽象硬件层实现)
- binder,OpenGL es,hwbinder(抽象硬件层的binder)等等
- 设定了SurfaceFlinger的在Android启动初期需要加载的init.rc文件:surfaceflinger.rc
- SurfaceFlinger的主函数入口main_surfaceflinger.cpp
PS:针对硬件抽象层不好理解,我们先把这个疑问预留这里,后期在学习总结。
4.3 Surfaceflinger.rc
文件路径: /frameworks/native/services/surfaceflinger/surfaceflinger.rc
对应代码如下:
service surfaceflinger /system/bin/surfaceflinger
class core animation
user system
group graphics drmrpc readproc
onrestart restart zygote
writepid /dev/stune/foreground/tasks
socket pdx/system/vr/display/client stream 0666 system graphics u:object_r:pdx_display_client_endpoint_socket:s0
socket pdx/system/vr/display/manager stream 0666 system graphics u:object_r:pdx_display_manager_endpoint_socket:s0
socket pdx/system/vr/display/vsync stream 0666 system graphics u:object_r:pdx_disp
上面代码在启动surfaceflinger服务、系统之外,同步还启动了三个socket-跨进程通信的。具体作用不是当前重点后续在做研究。
4.4 main_surfaceflinger.cpp
Surfaceflinger启动入口其文件路径:
/frameworks/native/services/surfaceflinger/main_surfaceflinger.cpp
int main(int, char**) {
//忽略了SIGPIPE信号,因为在SurfaceFlinger的Client-Server模型中,或者说IPC机制中,很可能会触发SIGPIPE信号,而这个信号的默认动作是终止进程
//当客户端/服务端的socket关闭时,防止进程退出
signal(SIGPIPE, SIG_IGN);
hardware::configureRpcThreadpool(1 /* maxThreads */,
false /* callerWillJoin */);
startGraphicsAllocatorService();//初始化Hal层的图元生成器服务
//设定surfaceflinger进程的binder线程池个数上限为4,并启动binder线程池;
ProcessState::self()->setThreadPoolMaxThreadCount(4);
//开启线程
//大多数程序都是需要IPC的,这里也需要,但是使用Binder机制是很繁琐的,所以Android为程序进程使用Binder机制封装了两个实现类:ProcessState、IPCThreadState
//其中ProcessState负责打开Binder驱动,进行mmap等准备工作;IPCThreadState负责具体线程跟Binder驱动进行命令交互。
sp<ProcessState> ps(ProcessState::self());
ps->startThreadPool();
// 实例化
sp<SurfaceFlinger> flinger = new SurfaceFlinger();
//设置surfaceflinger进程为高优先级以及前台调度策略;
setpriority(PRIO_PROCESS, 0, PRIORITY_URGENT_DISPLAY);
set_sched_policy(0, SP_FOREGROUND);
// Put most SurfaceFlinger threads in the system-background cpuset
// Keeps us from unnecessarily using big cores
// Do this after the binder thread pool init
if (cpusets_enabled()) set_cpuset_policy(0, SP_SYSTEM);
// 执行surfaceflinger初始化方法
flinger->init();
//将surfaceflinger添加到ServiceManager
//sp是strongponiter强指针(sp对象的析构函数调用RefBase的decStrong来减少强弱引用指针计数)
sp<IServiceManager> sm(defaultServiceManager());
sm->addService(String16(SurfaceFlinger::getServiceName()), flinger, false,
IServiceManager::DUMP_FLAG_PRIORITY_CRITICAL);
// 注册GPU
sp<GpuService> gpuservice = new GpuService();
sm->addService(String16(GpuService::SERVICE_NAME), gpuservice, false);
startDisplayService(); // 启动图形处理相关服务
struct sched_param param = {
0};
param.sched_priority = 2;
if (sched_setscheduler(0, SCHED_FIFO, ¶m) != 0) {
ALOGE("Couldn't set SCHED_FIFO");
}
// 运行当前线程
flinger->run();
return 0;
}
在上面方法中我们抽离几个核心方法解读:
- startGraphicsAllocatorService初始化hal层的图元生成器
- 初始化ProcessState,把该进程映射到Binder驱动程序
- Surfaceflinger实例化
- set_sched_policy设置前台进程
- Surfaceflinger初始化
- 由于Surfaceflinger本质是Binder服务,所以需要添加到ServiceManager进程中
- 初始化GpuService,添加到ServiveManager进程中
- 启动图形处理相关服务DisplayService
- sched_setscheduler把进程调度模式设置为实时进程的FIFO
- 调用Surfaceflinger的run方法
PS:由于Surfaceflinger不像应用进程一样是前台应用,它是运行云后台的为了保证它不被干掉,为了CPU不断的优先把资源传递给Surfaceflinger,为了让得到的渲染机会在16ms完成。
这里有一个FIFO就是实时调度策略,细则感兴趣的桐学可以学习下linux的进程调度。
Surfaceflinger被设置为SP_FOREGROUND,设置为前台进程,加入到前台进程数组中。接着SCHED_FIFO优先级策略。这样就能保证Surfaceflinger是在较高优先级下运行,同时保证只要每一次遍历进程调度类的时候,必定会先让渡给Surfaceflinger,接着让调渡给Ap应用。
4.5 Surfaceflinger实例化
创建SurfaceFlinger对象,在其构造函数中,主要是一些成员变量的初始化工作核心是提供的surfaceflinger的binder能力,提供layer创建等能力,系统提供的监听Binder进程死亡的事件回调,HWComper提供的监听显示器变化事件回调以及Hwcomposer中的Vsync信号。
代码路径:/frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
SurfaceFlinger::SurfaceFlinger(SurfaceFlinger::SkipInitializationTag)
: BnSurfaceComposer(),
mTransactionFlags(0),
mTransactionPending(false),
mAnimTransactionPending(false),
mLayersRemoved(false),
mLayersAdded(false),
mRepaintEverything(0),
mBootTime(systemTime()),
mBuiltinDisplays(),
mVisibleRegionsDirty(false),
mGeometryInvalid(false),
mAnimCompositionPending(false),
mDebugRegion(0),
mDebugDDMS(0),
mDebugDisableHWC(0),
mDebugDisableTransformHint(0),
mDebugInSwapBuffers(0),
mLastSwapBufferTime(0),
mDebugInTransaction(0),
mLastTransactionTime(0),
mBootFinished(false),
mForceFullDamage(false),
mPrimaryDispSync("PrimaryDispSync"),
mPrimaryHWVsyncEnabled(false),
mHWVsyncAvailable(false),
mHasPoweredOff(false),
mNumLayers(0),
mVrFlingerRequestsDisplay(false),
mMainThreadId(std::this_thread::get_id()),
mCreateBufferQueue(&BufferQueue::createBufferQueue),
mCreateNativeWindowSurface(&impl::NativeWindowSurface::create) {
}
- BnSurfaceComposer,IBinder::DeathRecipient,HWComposer::EventHandler SurfaceFlinger的父类
- mPrimaryDispSync 主要的信号同步处理器
- BufferQueue 图元消费队列
SurfaceFlinger::SurfaceFlinger() : SurfaceFlinger(SkipInitialization) {
ALOGI("SurfaceFlinger is starting");
vsyncPhaseOffsetNs = getInt64< ISurfaceFlingerConfigs,
&ISurfaceFlingerConfigs::vsyncEventPhaseOffsetNs>(1000000);
sfVsyncPhaseOffsetNs = getInt64< ISurfaceFlingerConfigs,
&ISurfaceFlingerConfigs::vsyncSfEventPhaseOffsetNs>(1000000);
hasSyncFramework = getBool< ISurfaceFlingerConfigs,
&ISurfaceFlingerConfigs::hasSyncFramework>(true);
dispSyncPresentTimeOffset = getInt64< ISurfaceFlingerConfigs,
&ISurfaceFlingerConfigs::presentTimeOffsetFromVSyncNs>(0);
useHwcForRgbToYuv = getBool< ISurfaceFlingerConfigs,
&ISurfaceFlingerConfigs::useHwcForRGBtoYUV>(false);
maxVirtualDisplaySize = getUInt64<ISurfaceFlingerConfigs,
&ISurfaceFlingerConfigs::maxVirtualDisplaySize>(0);
// Vr flinger is only enabled on Daydream ready devices.
useVrFlinger = getBool< ISurfaceFlingerConfigs,
&ISurfaceFlingerConfigs::useVrFlinger>(false);
maxFrameBufferAcquiredBuffers = getInt64< ISurfaceFlingerConfigs,
&ISurfaceFlingerConfigs::maxFrameBufferAcquiredBuffers>(2);
hasWideColorDisplay =
getBool<ISurfaceFlingerConfigs, &ISurfaceFlingerConfigs::hasWideColorDisplay>(false);
V1_1::DisplayOrientation primaryDisplayOrientation =
getDisplayOrientation< V1_1::ISurfaceFlingerConfigs, &V1_1::ISurfaceFlingerConfigs::primaryDisplayOrientation>(
V1_1::DisplayOrientation::ORIENTATION_0);
switch (primaryDisplayOrientation) {
case V1_1::DisplayOrientation::ORIENTATION_90:
mPrimaryDisplayOrientation = DisplayState::eOrientation90;
break;
case V1_1::DisplayOrientation::ORIENTATION_180:
mPrimaryDisplayOrientation = DisplayState::eOrientation180;
break;
case V1_1::DisplayOrientation::ORIENTATION_270:
mPrimaryDisplayOrientation = DisplayState::eOrientation270;
break;
default:
mPrimaryDisplayOrientation = DisplayState::eOrientationDefault;
break;
}
ALOGV("Primary Display Orientation is set to %2d.", mPrimaryDisplayOrientation);
mPrimaryDispSync.init(SurfaceFlinger::hasSyncFramework, SurfaceFlinger::dispSyncPresentTimeOffset);
// debugging stuff...
char value[PROPERTY_VALUE_MAX];
property_get("ro.bq.gpu_to_cpu_unsupported", value, "0");
mGpuToCpuSupported = !atoi(value);
property_get("debug.sf.showupdates", value, "0");
mDebugRegion = atoi(value);
property_get("debug.sf.ddms", value, "0");
mDebugDDMS = atoi(value);
if (mDebugDDMS) {
if (!startDdmConnection()) {
// start failed, and DDMS debugging not enabled
mDebugDDMS = 0;
}
}
ALOGI_IF(mDebugRegion, "showupdates enabled");
ALOGI_IF(mDebugDDMS, "DDMS debugging enabled");
property_get("debug.sf.disable_backpressure", value, "0");
mPropagateBackpressure = !atoi(value);
ALOGI_IF(!mPropagateBackpressure, "Disabling backpressure propagation");
property_get("debug.sf.enable_hwc_vds", value, "0");
mUseHwcVirtualDisplays = atoi(value);
ALOGI_IF(!mUseHwcVirtualDisplays, "Enabling HWC virtual displays");
property_get("ro.sf.disable_triple_buffer", value, "1");
mLayerTripleBufferingDisabled = atoi(value);
ALOGI_IF(mLayerTripleBufferingDisabled, "Disabling Triple Buffering");
const size_t defaultListSize = MAX_LAYERS;
auto listSize = property_get_int32("debug.sf.max_igbp_list_size", int32_t(defaultListSize));
mMaxGraphicBufferProducerListSize = (listSize > 0) ? size_t(listSize) : defaultListSize;
property_get("debug.sf.early_phase_offset_ns", value, "0");
const int earlyWakeupOffsetOffsetNs = atoi(value);
ALOGI_IF(earlyWakeupOffsetOffsetNs != 0, "Enabling separate early offset");
mVsyncModulator.setPhaseOffsets(sfVsyncPhaseOffsetNs - earlyWakeupOffsetOffsetNs,
sfVsyncPhaseOffsetNs);
//我们应该读取'persist.sys.sf '。color_saturation‘这
//但是由于/data可能被加密,我们需要等到vold之后
//读取属性属性是
//在启动动画之后读取
if (useTrebleTestingOverride()) {
//如果没有覆盖SurfaceFlinger就不能连接到HIDL
//舱单上没有列出的服务。被认为是
//从set服务名派生设置,但是它
//如果使用的名称不是'default',则是易碎的
//用于以后的生产目的。
setenv("TREBLE_TESTING_OVERRIDE", "true", true);
}
}
Surfaceflinger实例化实现如下特点:
- 初始化了vsyncPhaseOffsetNs,sfVsyncPhaseOffsetNs两个相位差,分别是指app的以及sf的相位差。关于相位差后面在学习
- 设置Surfaceflinger的渲染方向,是哪一个角度
- mPrimaryDispSync 主显示屏信号同步器初始化
- 根据Android的全局配置,判断是否需要打开三重缓冲,HWC合成机制
4.5.1 DispSync初始化
void DispSync::init(bool hasSyncFramework, int64_t dispSyncPresentTimeOffset) {
mIgnorePresentFences = !hasSyncFramework;
mPresentTimeOffset = dispSyncPresentTimeOffset;
mThread->run("DispSync", PRIORITY_URGENT_DISPLAY + PRIORITY_MORE_FAVORABLE);
// set DispSync to SCHED_FIFO to minimize jitter
struct sched_param param = {
0};
param.sched_priority = 2;
if (sched_setscheduler(mThread->getTid(), SCHED_FIFO, ¶m) != 0) {
ALOGE("Couldn't set SCHED_FIFO for DispSyncThread");
}
reset();
beginResync();
if (kTraceDetailedInfo) {
//如果我们没有得到现在的栅栏,那么零相位示踪剂
//将阻止HW垂直同步事件被关闭。
//即使我们只是忽略了栅栏,零相位跟踪也是
//不需要,因为任何时候有一个事件注册我们将
//打开HW垂直同步事件。
if (!mIgnorePresentFences && kEnableZeroPhaseTracer) {
mZeroPhaseTracer = std::make_unique<ZeroPhaseTracer>();
addEventListener("ZeroPhaseTracer", 0, mZeroPhaseTracer.get());
}
}
}
在这个过程中初始化了DispSyncThread这个线程并且运行起来,并且初始化一些简单的数据。同时设置这个线程调度的优先类为FIFO。相位计算?
4.5.2 图元队列调度
因为这里的SurfaceFlinger对象是一个StrongPointer强指针,所以首先会走到RefBase的onFirstRef方法。故
void SurfaceFlinger::onFirstRef()
{
mEventQueue->init(this);
}
查看surfaceFlinger.h,发现mEventQueue是MessqgeQueue创建的对象。
// these are thread safe
mutable std::unique_ptr<MessageQueue> mEventQueue{
std::make_unique<impl::MessageQueue>()};
文件路劲/frameworks/native/services/surfaceflinger/MessageQueue.cpp
所以初始化会创建消息队列需要的Handler、Looper。
void MessageQueue::init(const sp<SurfaceFlinger>& flinger) {
mFlinger = flinger;
mLooper = new Looper(true);
mHandler = new Handler(*this);
}
此处MessageQueue不是常见的消息队列,在SurfaceFlinger目录单独编写,mEventQueue更像是消息循环机制的管理者,其中包含了一个looper,在looper中的mMessageEnvelopes这个容器才是真正存储消息的地方。
waitMessage主要通过调用mLooper的pollOnce方法来监听消息
void MessageQueue::waitMessage() {
do {
IPCThreadState::self()->flushCommands();
int32_t ret = mLooper->pollOnce(-1);
switch (ret) {
case Looper::POLL_WAKE:
case Looper::POLL_CALLBACK:
continue;
case Looper::POLL_ERROR:
ALOGE("Looper::POLL_ERROR");
continue;
case Looper::POLL_TIMEOUT:
// timeout (should not happen)
continue;
default:
// should not happen
ALOGE("Looper::pollOnce() returned unknown status %d", ret);
continue;
}
} while (true);
}
handler也不是常见的那个Handler,而是Messagequeue中自定义的一个事件处理器,是专门为Surfaceflinger设计的,handler收到消息,进一步回调Surfaceflinger中的onMessageReceived。
void MessageQueue::Handler::handleMessage(const Message& message) {
switch (message.what) {
case INVALIDATE:
android_atomic_and(~eventMaskInvalidate, &mEventMask);
mQueue.mFlinger->onMessageReceived(message.what);
break;
case REFRESH:
android_atomic_and(~eventMaskRefresh, &mEventMask);
mQueue.mFlinger->onMessageReceived(message.what);
break;
}
}
上面代码注册了两种不同的图元刷新监听,一个是invalidate局部刷新,一个是refresh重新刷新。最后都会回调到Surfaceflinger的onMessageReceived中。换句话说,每当我们需要图元刷新的时候,就会通过mEventQueue的post方法,把数据异步加载到Handler中进行刷新。

4.6 Surfaceflinger初始化
void SurfaceFlinger::init() {
ALOGI( "SurfaceFlinger's main thread ready to run. "
"Initializing graphics H/W...");
ALOGI("Phase offest NS: %" PRId64 "", vsyncPhaseOffsetNs);
Mutex::Autolock _l(mStateLock);
// start the EventThread当应用和sf的vsync偏移量一致时,则只创建一个EventThread线程
// std::make_unique比较新,它是在c++14里加入标准库的。
//template make_unique(Ts&&... params)
//{
//return std::unique_ptr(new T(std::forward(params)...));
//}
//make_unique只是把参数完美转发给,要创建对象的构造函数,再从new出来的原生指针,构造std::unique_ptr。
//这种形式的函数,不支持数组和自定义删除器。
//make_unique函数:把任意集合的参数,完美转发给动态分配对象的构造函数,
//然后返回一个指向那对象的智能指针。
mEventThreadSource =
std::make_unique<DispSyncSource>(&mPrimaryDispSync, SurfaceFlinger::vsyncPhaseOffsetNs,
true, "app");
mEventThread = std::make_unique<impl::EventThread>(mEventThreadSource.get(),
[this]() {
resyncWithRateLimit(); },
impl::EventThread::InterceptVSyncsCallback(),
"appEventThread");
mSfEventThreadSource =
std::make_unique<DispSyncSource>(&mPrimaryDispSync,
SurfaceFlinger::sfVsyncPhaseOffsetNs, true, "sf");
mSFEventThread =
std::make_unique<impl::EventThread>(mSfEventThreadSource.get(),
[this]() {
resyncWithRateLimit(); },
[this](nsecs_t timestamp) {
mInterceptor->saveVSyncEvent(timestamp);
},
"sfEventThread");
//设置EventThread
mEventQueue->setEventThread(mSFEventThread.get());
mVsyncModulator.setEventThread(mSFEventThread.get());
//获取RenderEngine引擎,渲染引擎,通过工厂模式实现对于不同版本的OpenGL分装. 详细实现下面接下来再进行分析
getBE().mRenderEngine =
RE::impl::RenderEngine::create(HAL_PIXEL_FORMAT_RGBA_8888,
hasWideColorDisplay
? RE::RenderEngine::WIDE_COLOR_SUPPORT
: 0);
LOG_ALWAYS_FATAL_IF(getBE().mRenderEngine == nullptr, "couldn't create RenderEngine");
LOG_ALWAYS_FATAL_IF(mVrFlingerRequestsDisplay,
"Starting with vr flinger active is not currently supported.");
getBE().mHwc.reset(//初始化硬件composer对象, hwcomposer实例化,主要是监听显示器硬件变化, hard抽象层。
new HWComposer(std::make_unique<Hwc2::impl::Composer>(getBE().mHwcServiceName)));
//监听
getBE().mHwc->registerCallback(this, getBE().mComposerSequenceId);
//处理任何初始热插拔和结果显示更改。
//该方法第一次进来无效,这是SF重启发现有屏幕插进来,一般不会走进来
processDisplayHotplugEventsLocked();
LOG_ALWAYS_FATAL_IF(!getBE().mHwc->isConnected(HWC_DISPLAY_PRIMARY),
"Registered composer callback but didn't create the default primary display");
//将默认的显示GLContext设置为当前,这样我们就可以创建纹理
//当我们创建图层时(可能会在渲染之前发生)
//第一次进来还没有链接进来的Display的Binder对象,跳过
getDefaultDisplayDeviceLocked()->makeCurrent();
//打开vr功能相关模块
if (useVrFlinger) {
auto vrFlingerRequestDisplayCallback = [this] (bool requestDisplay) {
//这个回调函数被vr flinger分派线程调用。我们
//需要调用signalTransaction(),它需要持有
//当我们不在主线程时mStateLock。收购
// mStateLock从vr flinger分派线程可能触发一个
//surface flinger中的死锁(见b/66916578),因此发布一个消息
//改为在主线程上处理。
sp<LambdaMessage> message = new LambdaMessage([=]() {
ALOGI("VR request display mode: requestDisplay=%d", requestDisplay);
mVrFlingerRequestsDisplay = requestDisplay;
signalTransaction();
});
postMessageAsync(message);
};
mVrFlinger = dvr::VrFlinger::Create(getBE().mHwc->getComposer(),
getBE().mHwc->getHwcDisplayId(HWC_DISPLAY_PRIMARY).value_or(0),
vrFlingerRequestDisplayCallback);
if (!mVrFlinger) {
ALOGE("Failed to start vrflinger");
}
}
mEventControlThread = std::make_unique<impl::EventControlThread>(
[this](bool enabled) {
setVsyncEnabled(HWC_DISPLAY_PRIMARY, enabled); });
// //初始化绘图状态
mDrawingState = mCurrentState;
//初始化显示设备,以Event事件形式发送
initializeDisplays();
getBE().mRenderEngine->primeCache();
//通知本地图形api是否支持当前的时间戳:
if (getHwComposer().hasCapability(
HWC2::Capability::PresentFenceIsNotReliable)) {
mStartPropertySetThread = new StartPropertySetThread(false);
} else {
mStartPropertySetThread = new StartPropertySetThread(true);
}
if (mStartPropertySetThread->Start() != NO_ERROR) {
ALOGE("Run StartPropertySetThread failed!");
}
mLegacySrgbSaturationMatrix = getBE().mHwc->getDataspaceSaturationMatrix(HWC_DISPLAY_PRIMARY,
Dataspace::SRGB_LINEAR);
ALOGV("Done initializing");
}
在init过程中初始化不少重要的对象:
- DispSyncSource 的初始化
- EventThread 的初始化
- EventQueue 监听初始化
- RenderEngine渲染引擎的初始化
- 初始化HWComposer监听显示器硬件变化
- EventControlThread初始化
- 初始化和链接DisplayService
4.6.1 EventThread|DispSyncSource的初始化
文件路径:/frameworks/native/services/surfaceflinger/EventThread.cpp
mEventThreadSource =std::make_unique<DispSyncSource>(&mPrimaryDispSync, SurfaceFlinger::vsyncPhaseOffsetNs,true, "app");
mEventThread = std::make_unique<impl::EventThread>(mEventThreadSource.get(),[this]() {
resyncWithRateLimit(); },impl::EventThread::InterceptVSyncsCallback(),"appEventThread");
能看到实际上mEventThread本质上就是一个DisSyncSource对象,我们看看他的构造函数:
class DispSyncSource final : public VSyncSource, private DispSync::Callback {
public:
DispSyncSource(DispSync* dispSync, nsecs_t phaseOffset, bool traceVsync,
const char* name) :
mName(name),
mValue(0),
mTraceVsync(traceVsync),
mVsyncOnLabel(String8::format("VsyncOn-%s", name)),
mVsyncEventLabel(String8::format("VSYNC-%s", name)),
mDispSync(dispSync),
mCallbackMutex(),
mVsyncMutex(),
mPhaseOffset(phaseOffset),
mEnabled(false) {
}
~DispSyncSource() override = default;
...
在这个中设置两个关键参数,一个是上面初始化好的DispSync显示同步信号,一个是app的DispSyncSource(相位差)
4.6.2 EventThread实例化
其逻辑流程大概如下:
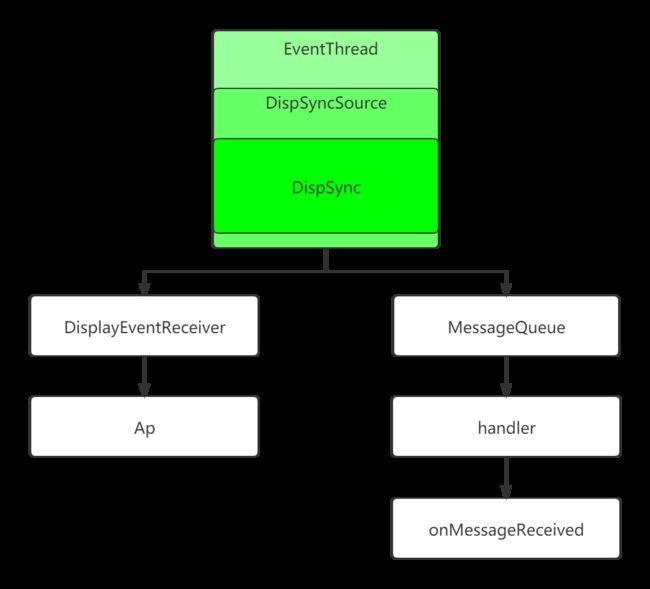
把app的DispSyncSource作为参数,进行实例化
EventThread::EventThread(VSyncSource* src, ResyncWithRateLimitCallback resyncWithRateLimitCallback,
InterceptVSyncsCallback interceptVSyncsCallback, const char* threadName)
: mVSyncSource(src),
mResyncWithRateLimitCallback(resyncWithRateLimitCallback),
mInterceptVSyncsCallback(interceptVSyncsCallback) {
for (auto& event : mVSyncEvent) {
event.header.type = DisplayEventReceiver::DISPLAY_EVENT_VSYNC;
event.header.id = 0;
event.header.timestamp = 0;
event.vsync.count = 0;
}
mThread = std::thread(&EventThread::threadMain, this);
pthread_setname_np(mThread.native_handle(), threadName);
pid_t tid = pthread_gettid_np(mThread.native_handle());
// Use SCHED_FIFO to minimize jitter
constexpr int EVENT_THREAD_PRIORITY = 2;
struct sched_param param = {
0};
param.sched_priority = EVENT_THREAD_PRIORITY;
if (pthread_setschedparam(mThread.native_handle(), SCHED_FIFO, ¶m) != 0) {
ALOGE("Couldn't set SCHED_FIFO for EventThread");
}
set_sched_policy(tid, SP_FOREGROUND);
}
能够看到在这个过程中做的事情和DispSync的方法很相似。首先实例化一个内部线程,并且设置这个线程的启动后的方法,以及设置该线程为FIFO策略并且设置为前台线程,使用更高的优先级。
void EventThread::threadMain() NO_THREAD_SAFETY_ANALYSIS {
std::unique_lock<std::mutex> lock(mMutex);
while (mKeepRunning) {
DisplayEventReceiver::Event event;
Vector<sp<EventThread::Connection> > signalConnections;
signalConnections = waitForEventLocked(&lock, &event);
// dispatch events to listeners...
const size_t count = signalConnections.size();
for (size_t i = 0; i < count; i++) {
const sp<Connection>& conn(signalConnections[i]);
// now see if we still need to report this event
status_t err = conn->postEvent(event);
if (err == -EAGAIN || err == -EWOULDBLOCK) {
// The destination doesn't accept events anymore, it's probably
// full. For now, we just drop the events on the floor.
// FIXME: Note that some events cannot be dropped and would have
// to be re-sent later.
// Right-now we don't have the ability to do this.
ALOGW("EventThread: dropping event (%08x) for connection %p", event.header.type,
conn.get());
} else if (err < 0) {
// handle any other error on the pipe as fatal. the only
// reasonable thing to do is to clean-up this connection.
// The most common error we'll get here is -EPIPE.
removeDisplayEventConnectionLocked(signalConnections[i]);
}
}
}
}
能看到在这个过程中,会通过waitForEventLocked阻塞等待外部链接进来的EventThread的Connection,链接进来。一般是应用程序注册了Choreographer之后,就会注册DisplayEventReceiver,此时会对应DisplayEventReceiverDispatch一个Looper的callback,同时会通过Binder把当前为当前对象注册一个Connect给Surfaceflinger进程的EventThread。当唤醒之后,经过检测将会调用postEvent把同步信号同步给Ap应用。
在waitForEventLocked等待循环的过程中,每一次同步信号的发出都会调用构造函数进来的回调interceptVSyncsCallback,也就是:
resyncWithRateLimit();
同时会根据条件判断,当前是否打开同步信号。
4.6.3 Surfaceflinger的EventThread初始化
mSfEventThreadSource =
std::make_unique<DispSyncSource>(&mPrimaryDispSync,
SurfaceFlinger::sfVsyncPhaseOffsetNs, true, "sf");
mSFEventThread =
std::make_unique<impl::EventThread>(mSfEventThreadSource.get(),
[this]() {
resyncWithRateLimit(); },
[this](nsecs_t timestamp) {
mInterceptor->saveVSyncEvent(timestamp);
},
"sfEventThread");
//设置EventThread
mEventQueue->setEventThread(mSFEventThread.get());
mVsyncModulator.setEventThread(mSFEventThread.get());
Surfaceflinger的EventThread监听的是本进程的,其先去看看mEventQueue这个Surfaceflinger中的MessageQueue的setEventThread方法
void MessageQueue::setEventThread(android::EventThread* eventThread) {
if (mEventThread == eventThread) {
return;
}
if (mEventTube.getFd() >= 0) {
mLooper->removeFd(mEventTube.getFd());
}
mEventThread = eventThread;
mEvents = eventThread->createEventConnection();
mEvents->stealReceiveChannel(&mEventTube);
mLooper->addFd(mEventTube.getFd(), 0, Looper::EVENT_INPUT, MessageQueue::cb_eventReceiver,
this);
}
在这个过程中能看到和Ap应用极其相似的逻辑。首先通过eventThread的createEventConnection创建一个Connection,EventThread可以从waitForEventLocked能够监听到这个链接。
sp<BnDisplayEventConnection> EventThread::createEventConnection() const {
return new Connection(const_cast<EventThread*>(this));
}
EventThread::Connection::Connection(EventThread* eventThread)
: count(-1), mEventThread(eventThread), mChannel(gui::BitTube::DefaultSize) {
}
EventThread::Connection::~Connection() {
//这里什么都不做——清理将自动发生
//当主线程唤醒时
}
void EventThread::Connection::onFirstRef() {
//注意:mEventThread对我们没有强引用
mEventThread->registerDisplayEventConnection(this);
}
初始化了一个BitTube对象,以及把当前的Connection注册到EventThread中,让waitForEvent可以监听到新的监听进来了。
4.6.4 监听
status_t EventThread::registerDisplayEventConnection(
const sp<EventThread::Connection>& connection) {
std::lock_guard<std::mutex> lock(mMutex);
mDisplayEventConnections.add(connection);
mCondition.notify_all();
return NO_ERROR;
}
4.6.5 BitTube
封装过的socketpair。是一个全双工的通道,可以从1号写入,0号读取。也可以从0号写入,1号读取。在BitTube中设定了0是接受,1是写入其实就和管道一样的。
文件路径:/frameworks/native/libs/gui/BitTube.cpp
static const size_t DEFAULT_SOCKET_BUFFER_SIZE = 4 * 1024;
BitTube::BitTube(size_t bufsize) {
init(bufsize, bufsize);
}
BitTube::BitTube(DefaultSizeType) : BitTube(DEFAULT_SOCKET_BUFFER_SIZE) {
}
BitTube::BitTube(const Parcel& data) {
readFromParcel(&data);
}
void BitTube::init(size_t rcvbuf, size_t sndbuf) {
int sockets[2];
if (socketpair(AF_UNIX, SOCK_SEQPACKET, 0, sockets) == 0) {
size_t size = DEFAULT_SOCKET_BUFFER_SIZE;
setsockopt(sockets[0], SOL_SOCKET, SO_RCVBUF, &rcvbuf, sizeof(rcvbuf));
setsockopt(sockets[1], SOL_SOCKET, SO_SNDBUF, &sndbuf, sizeof(sndbuf));
// since we don't use the "return channel", we keep it small...
setsockopt(sockets[0], SOL_SOCKET, SO_SNDBUF, &size, sizeof(size));
setsockopt(sockets[1], SOL_SOCKET, SO_RCVBUF, &size, sizeof(size));
fcntl(sockets[0], F_SETFL, O_NONBLOCK);
fcntl(sockets[1], F_SETFL, O_NONBLOCK);
mReceiveFd.reset(sockets[0]);
mSendFd.reset(sockets[1]);
} else {
mReceiveFd.reset();
ALOGE("BitTube: pipe creation failed (%s)", strerror(errno));
}
}
4.6.6 事件监听过程
接着调用EventThread::Connection的stealReceiveChannel
status_t EventThread::Connection::stealReceiveChannel(gui::BitTube* outChannel) {
//重置这个位管的接收文件描述符为receiveFd
outChannel->setReceiveFd(mChannel.moveReceiveFd());
return NO_ERROR;
}
当waitForEvent接触等待后,将会调用Connection的postEvent方法:
文件路径:/frameworks/native/services/surfaceflinger/EventThread.cpp
status_t EventThread::Connection::postEvent(const DisplayEventReceiver::Event& event) {
ssize_t size = DisplayEventReceiver::sendEvents(&mChannel, &event, 1);
return size < 0 ? status_t(size) : status_t(NO_ERROR);
}
文件路径:/frameworks/native/libs/gui/DisplayEventReceiver.cpp
ssize_t DisplayEventReceiver::sendEvents(gui::BitTube* dataChannel,
Event const* events, size_t count)
{
return gui::BitTube::sendObjects(dataChannel, events, count);
}
这样就完成了从发送端到接收端的过程监听,当有数据唤醒时候就会进入到MessageQueue的回调中。
文件路径:/frameworks/native/services/surfaceflinger/MessageQueue.cpp
int MessageQueue::cb_eventReceiver(int fd, int events, void* data) {
MessageQueue* queue = reinterpret_cast<MessageQueue*>(data);
return queue->eventReceiver(fd, events);
}
int MessageQueue::eventReceiver(int /*fd*/, int /*events*/) {
ssize_t n;
DisplayEventReceiver::Event buffer[8];
while ((n = DisplayEventReceiver::getEvents(&mEventTube, buffer, 8)) > 0) {
for (int i = 0; i < n; i++) {
if (buffer[i].header.type == DisplayEventReceiver::DISPLAY_EVENT_VSYNC) {
mHandler->dispatchInvalidate();
break;
}
}
}
return 1;
}
此时MessageQueue就会调用Handler中的dispatchInvalidate,也就调用到了Surfaceflinger的onMessageReceived回调。
4.7 RenderEngine初始化
//获取RenderEngine引擎,渲染引擎,通过工厂模式实现对于不同版本的OpenGL分装. 详细实现下面接下来再进行分析
getBE().mRenderEngine =RE::impl::RenderEngine::create(HAL_PIXEL_FORMAT_RGBA_8888,hasWideColorDisplay?RE::RenderEngine::WIDE_COLOR_SUPPORT:0);
getBE其实是SurfaceflingerBE,它控制所有硬件接口,理解为Surfaceflinger缩影。Surfaceflinger是对整个系统的视图刷新控制。
std::unique_ptr<RenderEngine> RenderEngine::create(int hwcFormat, uint32_t featureFlags) {
//初始化EGL,作为默认的显示
EGLDisplay display = eglGetDisplay(EGL_DEFAULT_DISPLAY);
if (!eglInitialize(display, nullptr, nullptr)) {
LOG_ALWAYS_FATAL("failed to initialize EGL");
}
//初始化EGL的版本
GLExtensions& extensions = GLExtensions::getInstance();
extensions.initWithEGLStrings(eglQueryStringImplementationANDROID(display, EGL_VERSION),
eglQueryStringImplementationANDROID(display, EGL_EXTENSIONS));
// The code assumes that ES2 or later is available if this extension is
// supported.
//选择处理EGL的配置
EGLConfig config = EGL_NO_CONFIG;
if (!extensions.hasNoConfigContext()) {
config = chooseEglConfig(display, hwcFormat, /*logConfig*/ true);
}
//初始化EGL上下文
EGLint renderableType = 0;
if (config == EGL_NO_CONFIG) {
renderableType = EGL_OPENGL_ES2_BIT;
} else if (!eglGetConfigAttrib(display, config, EGL_RENDERABLE_TYPE, &renderableType)) {
LOG_ALWAYS_FATAL("can't query EGLConfig RENDERABLE_TYPE");
}
//设置GL版本号
EGLint contextClientVersion = 0;
if (renderableType & EGL_OPENGL_ES2_BIT) {
contextClientVersion = 2;
} else if (renderableType & EGL_OPENGL_ES_BIT) {
contextClientVersion = 1;
} else {
LOG_ALWAYS_FATAL("no supported EGL_RENDERABLE_TYPEs");
}
//获取属性
std::vector<EGLint> contextAttributes;
contextAttributes.reserve(6);
contextAttributes.push_back(EGL_CONTEXT_CLIENT_VERSION);
contextAttributes.push_back(contextClientVersion);
bool useContextPriority = overrideUseContextPriorityFromConfig(extensions.hasContextPriority());
if (useContextPriority) {
contextAttributes.push_back(EGL_CONTEXT_PRIORITY_LEVEL_IMG);
contextAttributes.push_back(EGL_CONTEXT_PRIORITY_HIGH_IMG);
}
contextAttributes.push_back(EGL_NONE);
//初始化EGL上下文
EGLContext ctxt = eglCreateContext(display, config, nullptr, contextAttributes.data());
// if can't create a GL context, we can only abort.
LOG_ALWAYS_FATAL_IF(ctxt == EGL_NO_CONTEXT, "EGLContext creation failed");
// now figure out what version of GL did we actually get
// NOTE: a dummy surface is not needed if KHR_create_context is supported
EGLConfig dummyConfig = config;
if (dummyConfig == EGL_NO_CONFIG) {
dummyConfig = chooseEglConfig(display, hwcFormat, /*logConfig*/ true);
}
EGLint attribs[] = {
EGL_WIDTH, 1, EGL_HEIGHT, 1, EGL_NONE, EGL_NONE};
//创建一个dump的Surface
EGLSurface dummy = eglCreatePbufferSurface(display, dummyConfig, attribs);
LOG_ALWAYS_FATAL_IF(dummy == EGL_NO_SURFACE, "can't create dummy pbuffer");
//把EGLDisplay和dump链接起来
EGLBoolean success = eglMakeCurrent(display, dummy, dummy, ctxt);
LOG_ALWAYS_FATAL_IF(!success, "can't make dummy pbuffer current");
extensions.initWithGLStrings(glGetString(GL_VENDOR), glGetString(GL_RENDERER),
glGetString(GL_VERSION), glGetString(GL_EXTENSIONS));
GlesVersion version = parseGlesVersion(extensions.getVersion());
// initialize the renderer while GL is current
std::unique_ptr<RenderEngine> engine;
switch (version) {
case GLES_VERSION_1_0:
case GLES_VERSION_1_1:
LOG_ALWAYS_FATAL("SurfaceFlinger requires OpenGL ES 2.0 minimum to run.");
break;
case GLES_VERSION_2_0:
case GLES_VERSION_3_0:
engine = std::make_unique<GLES20RenderEngine>(featureFlags);
break;
}
//设置EGLDisplay
engine->setEGLHandles(display, config, ctxt);
ALOGI("OpenGL ES informations:");
ALOGI("vendor : %s", extensions.getVendor());
ALOGI("renderer : %s", extensions.getRenderer());
ALOGI("version : %s", extensions.getVersion());
ALOGI("extensions: %s", extensions.getExtensions());
ALOGI("GL_MAX_TEXTURE_SIZE = %zu", engine->getMaxTextureSize());
ALOGI("GL_MAX_VIEWPORT_DIMS = %zu", engine->getMaxViewportDims());
//把EGLDisplay设置为当前OpenGL es的环境
eglMakeCurrent(display, EGL_NO_SURFACE, EGL_NO_SURFACE, EGL_NO_CONTEXT);
eglDestroySurface(display, dummy);
return engine;
}
- 初始化EGLDisplay ,获得当前系统默认的显示屏对象
- 初始化EGL的版本
- chooseEglConfig选择处理EGL的配置。通过eglGetConfigs查找可返回的EGL配置的数目,接着调用eglChooseConfig从所有配置项中得到最为推荐的配置数组,最后通过遍历查询,把系统中符合当前配置项中所有的配置都添加进来
- eglCreateContext 初始化EGL上下文
- 设置GL版本号
- eglCreatePbufferSurface创建一个dump的Surface,开辟一段可以缓存帧数据的空间,并用eglMakeCurrent把EGLDisplay和dump链接起来,其目的就是为了检查OpenGL es是否有问题。
- setEGLHandles 设置EGLDisplay,上下文和配置为全局配置
- eglMakeCurrent 把EGLDisplay设置为当前OpenGL es的环境,销毁dump这个Surface
4.8 HWComposer初始化
它联通的硬件抽象层Conposer,他是被HWComposer直接使用的,HWComposer除了直接管理Composer以外还负责VSync信号的生成和控制。
getBE().mHwc.reset(//初始化硬件composer对象, hwcomposer实例化,主要是监听显示器硬件变化, hard抽象层。
new HWComposer(std::make_unique<Hwc2::impl::Composer>(getBE().mHwcServiceName)));
能看到HWComposer中传入一个Hwc2::impl::Composer对象,先看看这个对象:文件路径:/frameworks/native/services/surfaceflinger/DisplayHardware/ComposerHal.cpp
Composer::Composer(const std::string& serviceName)
: mWriter(kWriterInitialSize),
mIsUsingVrComposer(serviceName == std::string("vr"))
{
mComposer = V2_1::IComposer::getService(serviceName);
if (mComposer == nullptr) {
LOG_ALWAYS_FATAL("failed to get hwcomposer service");
}
mComposer->createClient(
[&](const auto& tmpError, const auto& tmpClient)
{
if (tmpError == Error::NONE) {
mClient = tmpClient;
}
});
if (mClient == nullptr) {
LOG_ALWAYS_FATAL("failed to create composer client");
}
// 2.2 support is optional
sp<IComposer> composer_2_2 = IComposer::castFrom(mComposer);
if (composer_2_2 != nullptr) {
mClient_2_2 = IComposerClient::castFrom(mClient);
LOG_ALWAYS_FATAL_IF(mClient_2_2 == nullptr, "IComposer 2.2 did not return IComposerClient 2.2");
}
if (mIsUsingVrComposer) {
sp<IVrComposerClient> vrClient = IVrComposerClient::castFrom(mClient);
if (vrClient == nullptr) {
LOG_ALWAYS_FATAL("failed to create vr composer client");
}
}
}
能看到Composer对象中又会持有一个mComposer对象。这个对象可以暂且理解类似为Binder,从抽象层(hal)服务端传送过来的IComposer接口对象。之后所有要和硬件层进行交互,只需要操作这个IComposer对象即可。接着调用IComposer的createClient创建开一个Client对象。如果里面有2.2版本的IComposer对象则会把2.1版本的IComposer转化过去,这样软件层Composer就和硬件抽象层的Composer对应起来,等待HWComposer的操作。
4.8.1 HWComposer初始化
HWComposer::HWComposer(std::unique_ptr<android::Hwc2::Composer> composer)
: mHwcDevice(std::make_unique<HWC2::Device>(std::move(composer))) {
}
初始化一个HWC2::Device对象,hal层的对应的对象。
4.8.2 HWComposer监听
//监听
getBE().mHwc->registerCallback(this, getBE().mComposerSequenceId);
注册SF的监听到HWC中。
文件路径:/frameworks/native/services/surfaceflinger/DisplayHardware/HWComposer.cpp
void HWComposer::registerCallback(HWC2::ComposerCallback* callback,
int32_t sequenceId) {
mHwcDevice->registerCallback(callback, sequenceId);
}
继续,文件路径:/frameworks/native/services/surfaceflinger/DisplayHardware/HWC2.cpp
void Device::registerCallback(ComposerCallback* callback, int32_t sequenceId) {
if (mRegisteredCallback) {
ALOGW("Callback already registered. Ignored extra registration "
"attempt.");
return;
}
mRegisteredCallback = true;
sp<ComposerCallbackBridge> callbackBridge(
new ComposerCallbackBridge(callback, sequenceId));
mComposer->registerCallback(callbackBridge);
}
能看到HWC会借助一callbackBridge对象把对象注册到hal层中进行监听…
4.8 Surfaceflinger的run