Yolov5 系列1--- Yolo发展史以及Yolov5模型详解
最近在做检测相关的工作,几年前分析过faster-rcnn的代码和论文。现在,把yolov5这个最新且快的模型进行梳理。本系列会从Yolo的发展历程开始,到损失函数,mAP的概念,最后到如何在代码层面训练你的定制化数据集。好了,让我们开始吧~
1. YOLO (You Only Look Once) 的发展历史
这部分内容主要借鉴自 科技猛兽@知乎 在知乎的发文,我这里会做一下简化,具体细节请去看这位大佬的文章
[1-3]。
1.1 YOLO v0
YOLO v0的思路起源于将基本的CNN思路从分类任务扩展到检测中,那么,首先来看看检测任务和分类任务的区别:
- 检测: 网络的输出应该是bounding box (矩形框) 的坐标 (最少用4个数表示,常见的有2种: (x1, y1, x2, y2), (x1, y1, w, h)) 。至于为什么用矩形框,因为相比圆和其他形式的多边形,矩形框的几何性质使其更适合以最小的额外冗余代价来框住目标物体。

- 分类: 以最基础的单分类任务为例,单分类是指物体只属于一种类别,这个任务的特点是输入一张图片,输出是它的类别。对于输入图片,我们一般用一个Tensor表示,其shape为[N, C, H, W]。 对于输出结果,我们一般用一个one-hot vector表示: [ 0 , 0 , 0 , 1 ] [0, 0, 0, 1] [0,0,0,1],哪一维是1,就代表图片属于哪一类。
好了,在知道了分类和检测的基本区别后,我们可以将检测任务当做是遍历性的分类任务(即多目标检测; 如果确定一张图片至多只有1个目标的单目标检测,那么跟分类任务的网络设计和输出都是差不多的,只是最后的全连接层的激活函数不同而已)。
那么怎么遍历呢?RCNN类的方法是通过滑动窗口的方式遍历图片的所有位置,并对每个框进行分类。
但是这个方法的问题随之而来,遍历的彻不彻底非常影响精度。遍历得越精确,检测器的精度就越高,但是同时代价就越高,因为需要考虑不同尺度的bbox都对全图进行遍历,这个成本相当高。。。
举个例子:比如输入图片大小是 ( 320 , 320 ) (320, 320) (320,320)也就意味着有 320 × 320 = 102 , 400 320 \times 320 = 102, 400 320×320=102,400个位置。窗口最小为 ( 1 , 1 ) (1, 1) (1,1) ,最大 ( 320 × 320 ) (320 \times 320) (320×320),所以这个遍历的次数是无限次。我们看下伪代码:
即本质上,我们是在训练一个二分类器。这个二分类器的输入是一个框的内容,输出是(前景/背景)。
而这,又带来2个问题:
- ① 框有不同的大小,对于不同大小的框,输入到同一个二分类器中吗?
我们需要对这种情况进行处理,通常的方式是resize成相同固定的尺寸输入这个二分类器,这显然会导致很大的问题,比如一个二分类器的固定输入的Tensor的高和宽为 64 × 64 64 \times 64 64×64, 经过滑动取框,有的框的大小为 200 × 200 200 \times 200 200×200, 有的是 10 × 10 10 \times 10 10×10,我们都需要将这些bbox进行resize,resize到 64 × 64 64 \times 64 64×64的bbox才可以输入二分类器。
- ② 背景图片很多,前景图片很少:二分类样本不均衡。
这种滑动窗口的分类方法会非常慢,而且类别不均衡问题严重。
到现在为止,用分类的算法设计了一个检测器,它存在着各种各样的问题,现在是优化的时候了(接下来正式进入YOLO系列方法了):
YOLO的作者当时是这么想的:对分类器来讲,其最后的全连接层会输出一个one-hot vector,那把它换成(x,y,w,h,c),c表示confidence置信度,把问题转化成一个回归问题,直接回归出Bounding Box的位置不就好了吗?
好,现在模型是:
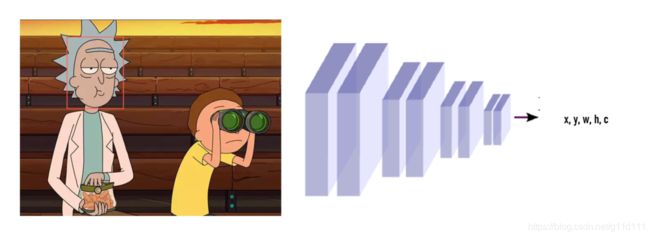
那如何组织训练呢?自己标注点数据,把label设置为 ( 1 , x ∗ , y ∗ , w ∗ , h ∗ ) (1, x^*, y^*, w^*, h^*) (1,x∗,y∗,w∗,h∗) 。这里 ∗ * ∗代表ground truth (即实际标签)。有了数据和标签,就可以进行训练。
我们会发现,这种方法比刚才的滑动窗口分类方法简单太多了。这一版的思路叫做YOLO v0,因为它是You Only Look Once最简单的版本。
1.2 YOLO v1
YOLO v1是在YOLO v0的基础上解决几个问题:
- ① YOLO v0只能做单目标检测,急需扩展
YOLO v1的解决思路是: 用一个(c,x,y,w,h)去负责输入image某个子区域的目标。
即相比YOLO v0的一张图只得到一个(x, y, h, w, c), YOLO v1得到n个(x, y, h, w, c)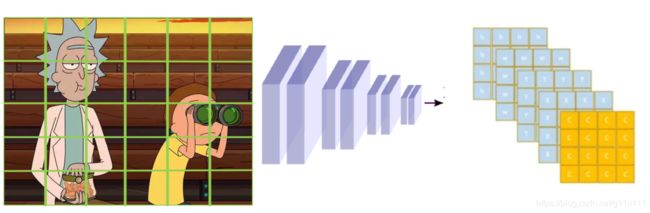
那么,如何从n个(x, y, h, w, c)得到我们想要的rick和morty的脸呢?这里, YOLO v1的作者用NMS(非最大值抑制)来筛选bbox,具体算法是[1]:
NMS自动解决了不知道图中有几个目标的问题。
- ② YOLO v0只能做单分类检测,急需扩展
一般的检测任务需要检测很多内容,比如既要检测Rick和Morty的脸,又要检测望远镜,那么这该怎么办呢?
以2个类别: 人脸和望远镜为例,我们让网络预测的内容从 N * (c, x, y, w, h) 变为 N * (c, x, y, w, h, one-hot). 2个类,one-hot就是[0,1],[1,0]这样子,如下图所示: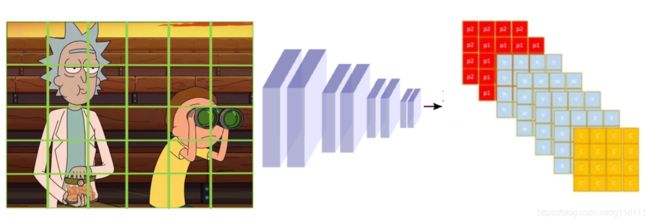
- ③ 小目标检测
小目标总是检测不佳,所以YOLO v1专门设计神经元去拟合小目标。
实际代码种,YOLO v1对于每个区域,用2个五元组(c,x,y,w,h),一个负责回归大目标,一个负责回归小目标,同样添加one-hot vector,one-hot就是[0,1],[1,0]这样子,来表示属于哪一类(人脸or望远镜)。
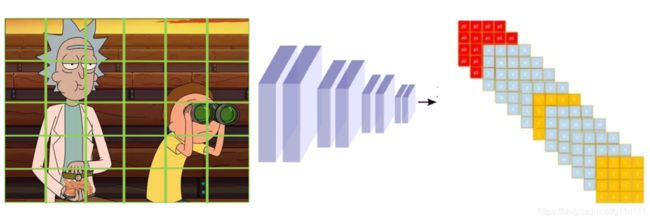
YOLO v1的核心就是相比v0,解决了这3个问题,其架构图如下(grid表示对图片划分区域的情况,上面的例子是4x4,实际在YOLO v1中是7x7. 类别为20类):
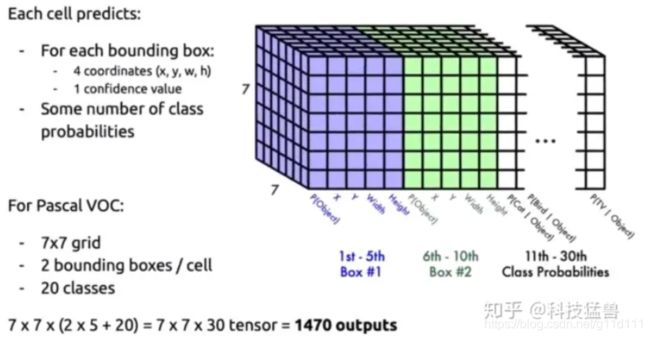
1.3 YOLO v2
YOLO v1虽然相较于RCNN类的检测算法快很多,但是还是有问题, 比如: 预测的框不准确,很多目标找不到:
- ① YOLO v1预测的框不准确
这个问题的原因主要是因为YOLO v1直接预测是的bbox的(x, y, w, h), 而这个值得范围很大,所以会有不准的问题。想想我们在做CV任务的时候,对图像处理通过会进行规则化(normalization), 将常见的8bit图像(0-255)缩放到[0, 1]或者[-1, 1]内。
而YOLO v1这种直接预测位置的策略会导致神经网络在一开始训练时不稳定,而使用偏移量会使得训练过程更加稳定,性能指标提升了5%左右。
所以,借鉴这个思路以及RCNN类的思路。YOLO v2提出一种并非直接预测bbox坐标的方法,而是改为预测基于grid的偏移量和基于anchor的偏移量。
作者管这个叫做location prediction,
-
基于grid的偏移量的意思是,anchor的位置是固定的(anchor是做数据集的时候对整个数据集进行聚类,得到的一些固定的anchor),偏移量=目标位置-anchor的位置。
-
基于anchor的偏移量的意思是,grid的位置是固定的(grid就是上面的rick and morty的一个个绿色格子),偏移量=目标位置-grid的位置。
关于location prediction的图解,来自科技猛兽的知乎文章[2],
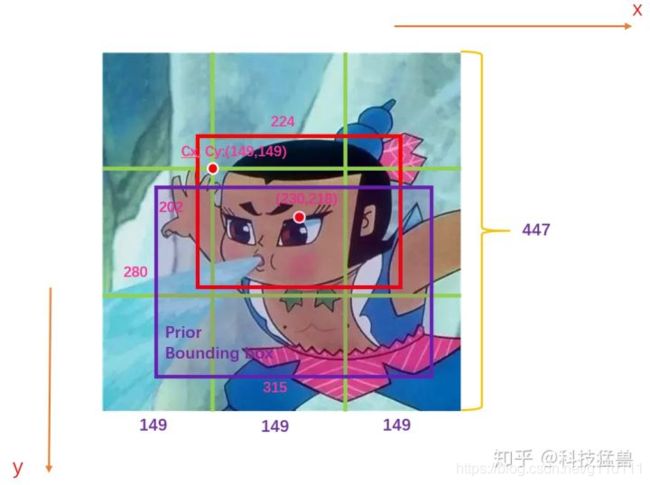
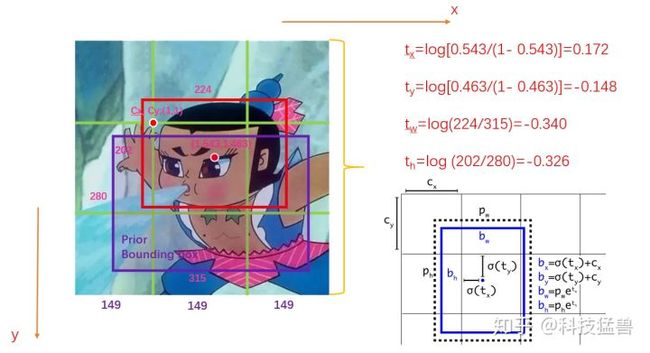
如上图所示,假设此图分为9个grid,GT(ground truth)如红色的框所示,Anchor如紫色的框所示 (该Anchor是根据数据集的GT计算产生的,与目标GT的IoU最大的那个Anchor)。图中的数字为image的真实信息。
YOLO v2的预测值从(x, y, h, w), x , y , h , w ∈ [ 0 , 447 ] x , y, h, w \in [0,447] x,y,h,w∈[0,447];变为 t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th, 如下所示, 这些值的范围很小,非常有利于检测网络收敛。
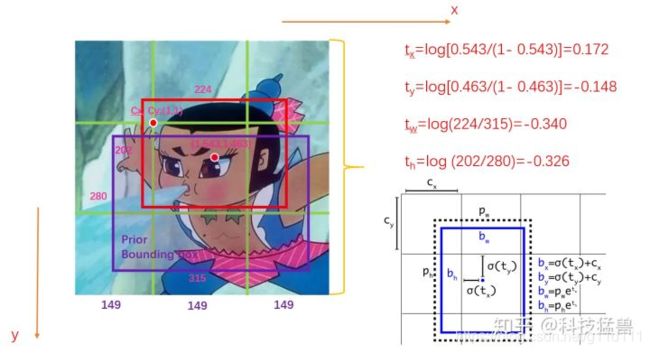
可以看出, Ground Truth的红色bbox中心位置相较于其所在的grid左上角(1, 1)的坐标为(1.543, 1.463). 计算公式:
t x = l o g ( ( b b o x x − c x ) / ( 1 − ( b b o x x − c x ) ) ) t_x = log((bbox_x - c_x) / (1 - (bbox_x - c_x))) tx=log((bboxx−cx)/(1−(bboxx−cx)))
t y = l o g ( ( b b o x y − c y ) / ( 1 − ( b b o x y − c y ) ) ) t_y = log((bbox_y - c_y) / (1 - (bbox_y - c_y))) ty=log((bboxy−cy)/(1−(bboxy−cy)))
t w = l o g ( g t w / p w ) t_w = log(gt_w / p_w) tw=log(gtw/pw)
t h = l o g ( g t h / p h ) t_h = log(gt_h / p_h) th=log(gth/ph)
其中右下角是YOLO v2的改进的具体图示,其中的参数含义如下[2]:

-
② YOLO v1会miss掉很多目标,即漏检现象明显
这个是因为在多目标多类别检测中,目标物体的大小,高宽比都不同。比如行人就是窄长型的bbox,而汽车则是偏向正方形的bbox。
YOLO v2的作者根据这一点,从数据集中预先准备几个出现几率比较大的bounding box,再以它们为基准进行预测呢,这就是Anchor的初衷。
具体的做法是,YOLO v2将图像划分为 13 × 13 13 \times 13 13×13个区域,每个区域有5个Anchor,且每个anchor对应着1个类别,还以2分类为例,如下公式算出来的一样,网络预测的Tensor的最后一维是35.
35 = 5 × ( 5 ( c , t x , t y , t w , t h ) + 2 c l a s s e s ) 35 = 5 \times (5 (c, t_x, t_y, t_w, t_h) + 2 classes) 35=5×(5(c,tx,ty,tw,th)+2classes)- 每个区域的5个anchor是如何得到的?
如下图,对于任意一个数据集,就比如说COCO吧(紫色的anchor),先对训练集的GT(ground truth)的bounding box进行聚类,聚成几类呢?作者进行了实验之后发现5类的recall vs. complexity比较好,现在聚成了5类,当然对复杂的任务,越多的类别,mAP会越高,预测的最全面,但是在复杂度上升很多的同时对模型的准确度提升不大,所以采用了一个比较折中的办法选取了5个聚类簇,即使用5个先验框。
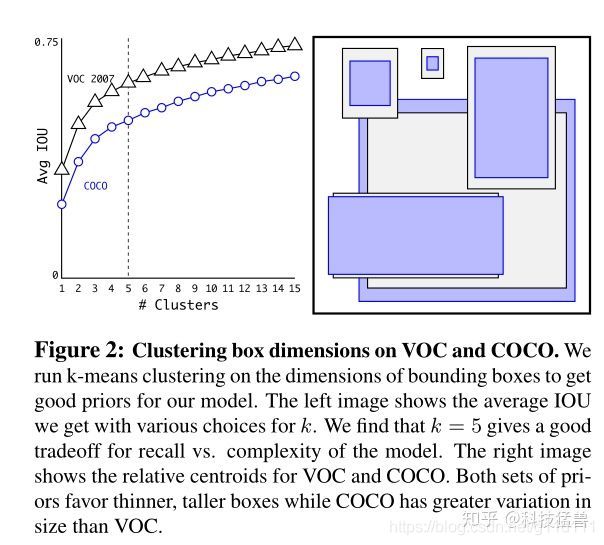
- 注意: YOLO v2的Anchor是从数据集中统计得到的,(而Faster-RCNN中的Anchor的宽高和大小是手动挑选的)。
- 每个区域的5个anchor是如何得到的?
1.4 YOLO v3
到这里,YOLO的基本思路就确定了,但是到YOLO v2这里,对小目标检测的效果还是不够好(resnet还没出来呢…, 提特征的网络不够好~)。
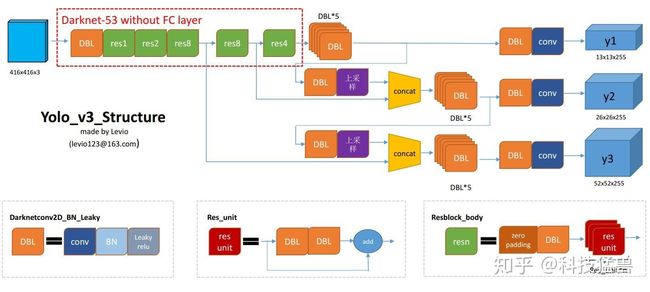
到了YOLO v3,这里主要的改进是增加了多尺度预测, 并把YOLO v2的Backbone从19层的Darknet变为了53层的Darknet[4]。
- ① 多尺度预测
[2]
YOLO v3检测头分叉了,分成了3部分, 每个维度都有3个anchor:
YOLO v3, in total uses 9 anchor boxes. Three for each scale (3个大的,3个中的,3个小的). If you’re training YOLO on your own dataset, you should go about using K-Means clustering to generate 9 anchors.
[4]
- 13 ∗ 13 ∗ 3 ∗ ( 4 + 1 + 2 ) 13*13*3*(4+1 + 2) 13∗13∗3∗(4+1+2)
- 26 ∗ 26 ∗ 3 ∗ ( 4 + 1 + 2 ) 26*26*3*(4+1 + 2) 26∗26∗3∗(4+1+2)
- 52 ∗ 52 ∗ 3 ∗ ( 4 + 1 + 2 ) 52*52*3*(4+1 + 2) 52∗52∗3∗(4+1+2)
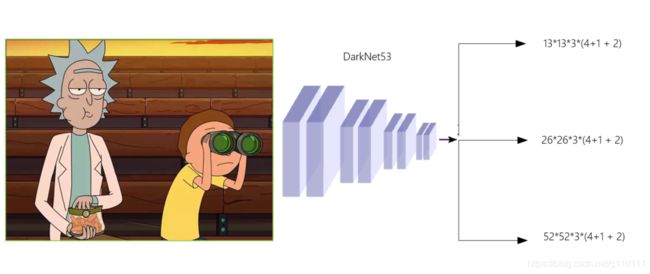
相较于YOLO v2, YOLO v3的预测bbox数量为:
( 13 × 13 + 26 × 26 + 52 × 52 ) × 3 = 10467 ( V 3 ) ≫ 845 ( V 2 ) ( 13 × 13 × 5 ) (13 \times 13 + 26 \times 26 + 52 \times 52) \times 3 = 10467(V3) \gg 845(V2) (13 \times 13 \times 5) (13×13+26×26+52×52)×3=10467(V3)≫845(V2)(13×13×5)
多了这么多可以预测的bounding box,模型的能力显然增强了。
官方的YOLO v3模型如下图所示:
1.5 YOLO v4
Yolo v4在v3的基础上加了一些特点,主要是3个特点:
-
① Using multi-anchors for single ground truth
之前的YOLO v3是1个anchor负责一个GT,YOLO v4中用多个anchor去负责一个GT。方法是:对于 G T j GT_j GTj来说,只要 I o U ( a n c h o r i , G T j ) > t h r e s h o l d IoU(anchor_i, GT_j) > threshold IoU(anchori,GTj)>threshold ,就让 a n c h o r i anchor_i anchori去负责 G T j GT_j GTj。
这就相当于你anchor框的数量没变,但是选择的正样本的比例增加了,就缓解了正负样本不均衡 (一般情况下,背景数量太多) 的问题。 -
② Eliminate_grid sensitivity
还记得之前的YOLO v2的这幅图吗?YOLO v2,YOLO v3都是预测 t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th这4个偏移量。
这里其实还隐藏着一个问题:

-
③ CIoU Loss
这块暂时不介绍了,详情参见科技猛兽大佬的知乎文章[2]。
1.6 YOLO v5
YOLO v5基本上在YOLO v3的结构上进行修改。下面的介绍分几个模块:
1.6.1 网络模块
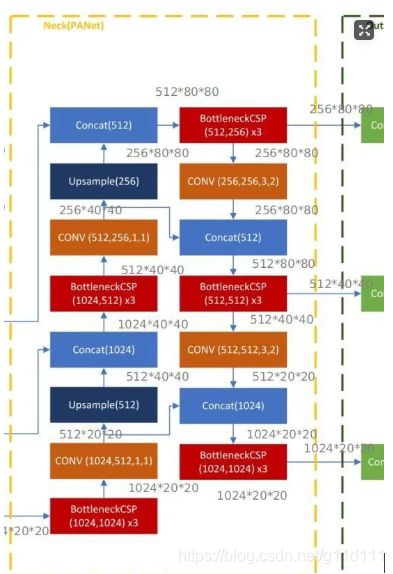
以 ( N , 3 , 640 , 640 ) (N, 3, 640, 640) (N,3,640,640)的输入为例,以最轻量级的Yolov5s为例,其结构如下
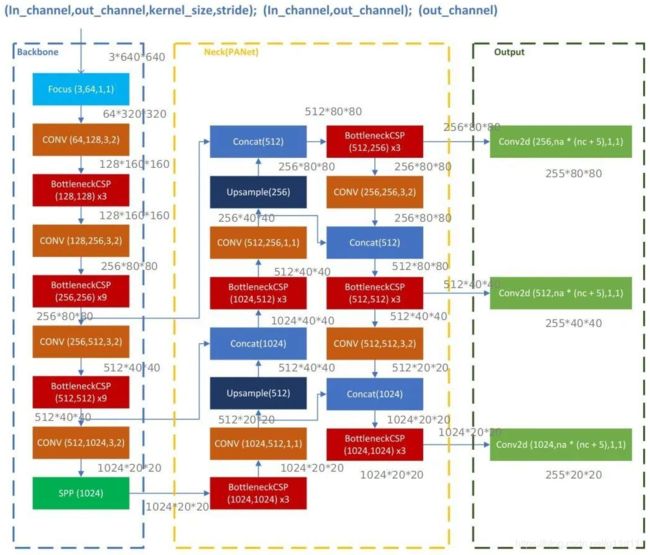
下文我将详细讲述Focus,BottleneckCSP,SPP,PANET这几个重要模块,由于本项目使用YOLO v5s网络结构训练模型,因此下文中的网络图及实例都基于YOLO v5s,并且输入图像为3x640x640。
YOLO网络由三个主要组件组成:
1)Backbone:在不同图像细粒度上聚合并形成图像特征的卷积神经网络。
2)Neck:一系列混合和组合图像特征的网络层,并将图像特征传递到预测层。(一般是FPN或者PANET)
3)Head:对图像特征进行预测,生成边界框和并预测类别。
YOLO V5 1.0中用到的重要的模块包括Focus,BottleneckCSP,SPP,PANET。模型的上采样Upsample是采用nearest两倍上采样插值nn.Upsample(mode="nearest")。
值得注意的是YOLO V5 1.0最初为COCO数据集训练的Pretrained_model 使用的是FPN作为Neck,在6月22日后,Ultralytics已经更新模型的Neck为PANET。网上很多的YOLO V5网络结构介绍都是基于FPN-NECK,本文的模型训练是基于PANET-NECK,下文中只介绍PANET-NECK。
对于YOLO V5,无论是V5s,V5m,V5l还是V5x其Backbone,Neck和Head一致。唯一的区别在与模型的深度和宽度设置,只需要修改这两个参数就可以调整模型的网络结构。V5l 的参数是默认参数。
• depth multiple 是用来控制模型的深度,例如V5s的深度是0.33,而V5l的深度是1,也就是说V5l的Bottleneck个数是V5s的3倍。
• width_multiple 是用来控制卷积核的个数,V5s的宽度是0.5,而V5l的宽度是1,表示V5s的卷积核数量是默认设置的一半,当然你也可以设置到1.25倍,即V5x。例如下面YOLO V5的yaml文件中的backbone的第一层是 [[-1, 1, Focus, [64, 3]],而V5s的宽度是0.5,因此这一层实际上是[[-1, 1, Focus, [32, 3]]。
因为我的目标是非常轻量级的检测模型, 因此目前只考虑yolov5s
其对于的模型定义文件如下: yolov5s.yaml (对COCO数据集),可以看出,其和上面的图可以很好的对应上。
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
Focus
下图为YOLO V5s的Focus 隔行采样拼接结构。
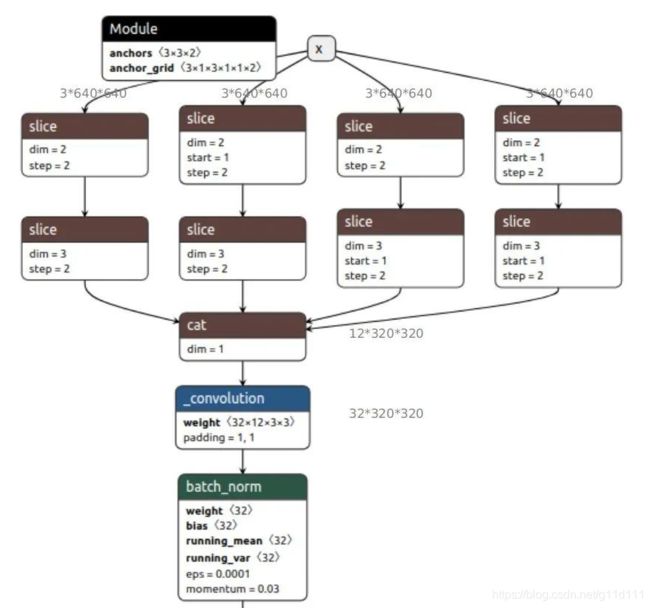
YOLO V5默认3x640x640的输入,Focus层的作用是将其复制四份,然后通过切片操作将这个四个图片切成了四个3x320x320的切片,接下来使用concat从深度上连接这四个切片,输出为12x320x320,之后再通过卷积核数为32的卷积层,生成32x320x320的输出,最后经过batch_norm 和leaky_relu将结果输入到下一个卷积层。
Focus层的效果如下: 以 4 × 4 4 \times 4 4×4的图片为例,左边是输入的原图,右图是Focus处理后的特征图。
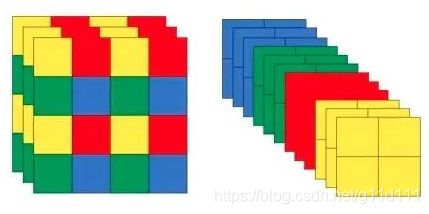
截至目前(2020.09.28),其实现是这样的[5],与YOLO v2的passthrough是一样的。

核心为这段代码self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)) 。x[..., ::2, ::2]是黄色部分,x[..., 1::2, ::2]是红色部分,x[..., ::2, 1::2]为绿色部分, 以此类推。
-
BottleneckCSP
下图为YOLO V5s的第一个BottlenneckCSP结构:可见BottlenneckCSP分为两部分,Bottlenneck以及CSP。
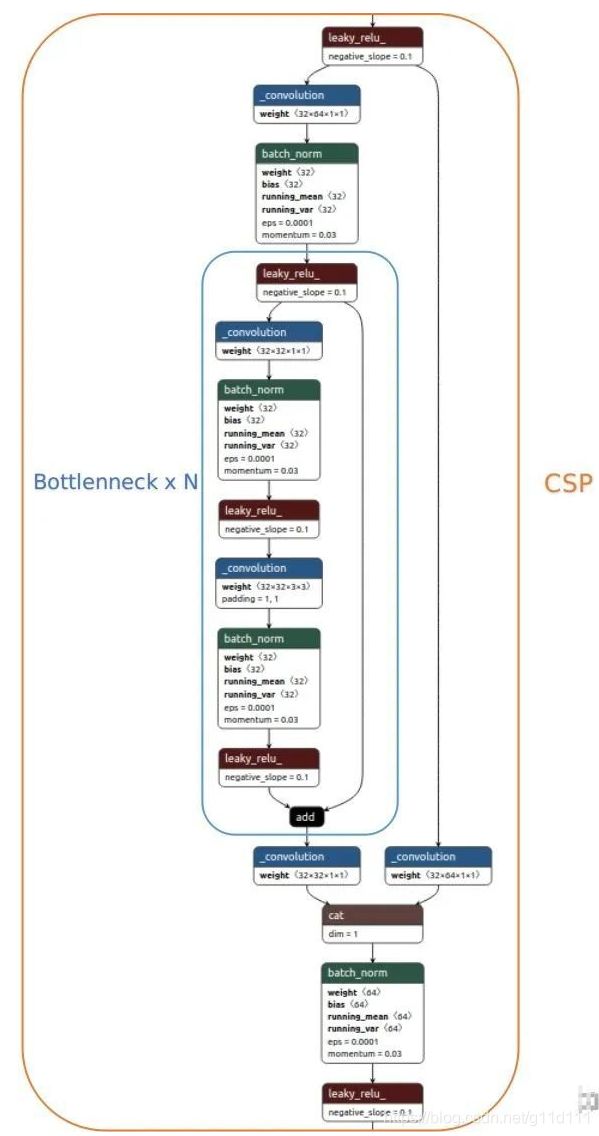
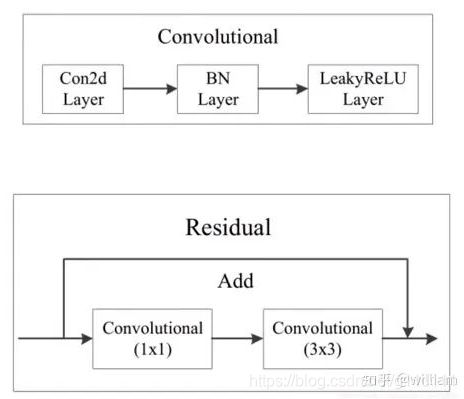
其中,Bottleneck就是经典的残差结构: 先是1x1的卷积层(conv+batch_norm+leaky relu),然后再是3x3的卷积层,最后通过残差结构与初始输入相加[6]。
值得注意的是YOLO V5通过depth multiple控制模型的深度,例如V5s的深度是0.33,而V5l的深度是1,也就是说V5l的BottlenneckCSP中Bottleneck个数是V5s的3倍,模型中第一个BottlenneckCSP默认Bottleneck个数x3,对于V5s只有上图中的一个Bottleneck。作者的代码如下,值得注意的是e就是width_multiple,表示当前操作卷积核个数占默认个数的比例
[7]:
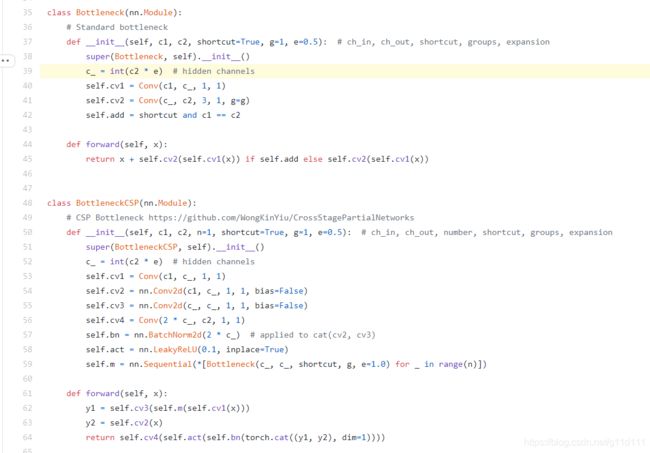
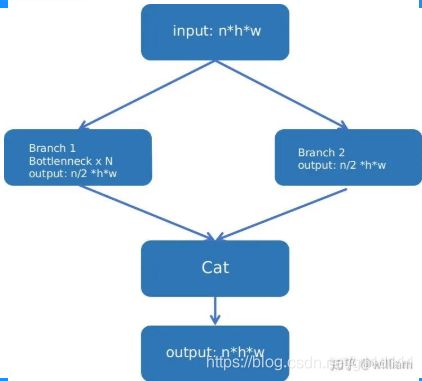
由上面的BottleneckCSP代码可以看出, 其将分支分为2块, 分为分支y1和y2,
其中分支1(y1)进行Bottleneck * N的操作, 分支2(y2)进行通道缩减.
最后将2个分支concat, 再过bn, act, Conv的系列操作即可(下图来自William在知乎发的文章[6]).
-
SPP
SPP是空间金字塔层(Spatial pooling layer), 输入是512x20x20,经过1x1的卷积层后输出256x20x20,然后经过并列的三个不同kernel_size的Maxpool进行下采样(5, 9, 13), 注意, 所有的max_pool的padding都是same的,所以可以将将其结果拼接后与其初始特征相加,输出1024x20x20,最后用512的卷积核将其恢复到512x20x20(下图来自科技猛兽的知乎文章[3])。
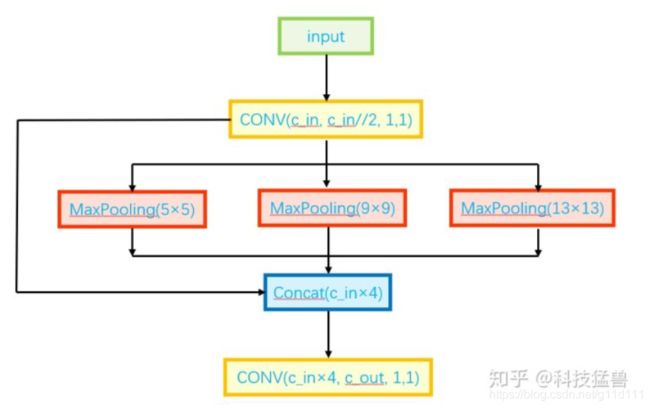
-
PANet
PAN结构来自论文Path Aggregation Network[8],其本意是用于实例分割任务中的(Instance Segmentation),其模型结构如下图:
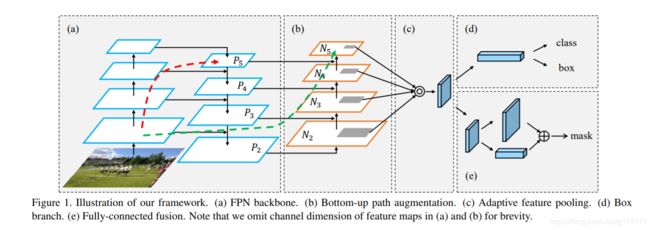
该网络的特征提取器采用了一种新的增强自下向上(Bottom Up)路径的 FPN 结构,改善了低层特征的传播(a部分)。第三条通路的每个阶段都将前一阶段的特征映射作为输入,并用3x3卷积层处理它们。输出通过横向连接被添加到自上而下通路的同一阶段特征图中,这些特征图为下一阶段提供信息(b部分)。同时使用自适应特征池化(Adaptive feature pooling) 恢复每个候选区域和所有特征层次之间被破坏的信息路径,聚合每个特征层次上的每个候选区域,避免被任意分配(c部分)。
YOLO V5借鉴了YOLO V4的修改版PANET结构: PANET通常使用自适应特征池将相邻层加在一起,以进行掩模预测。但是,当在YOLO v4中使用PANET时,此方法略麻烦,因此,YOLO v4的作者没有使用自适应特征池添加相邻层,而是对其进行Concat操作,从而提高了预测的准确性。
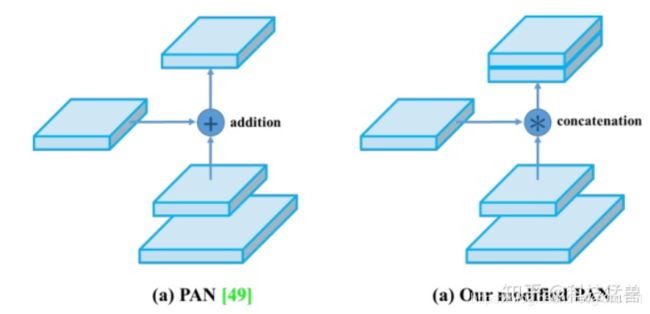
YOLO V5同样采用了级联操作。详情可以参看模型大图及Netron网络图中对应的Concat操作。
1.6.2 数据处理改进
以下内容转载自科技猛兽
[3]的知乎文章
- Mosaic数据增强
[3]

CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。
其主要优点为:
① 丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
② 减少GPU使用:可能会有人说,随机缩放,普通的数据增强也可以做,但作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
- 自适应锚框计算
[3]
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。
在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框ground truth进行比对,计算两者差距,再反向更新,迭代网络参数。
因此初始锚框也是比较重要的一部分,比如Yolov5在Coco数据集上初始设定的锚框:

在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。
但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭[9]。
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
- 自适应图片缩放
[3]
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。
比如Yolo算法中常用416 × \times × 416,608 × \times × 608等尺寸,比如对下面800*600的图像进行缩放:,如图所示:

但Yolov5代码中对此进行了改进,也是Yolov5推理速度能够很快的一个不错的trick。
作者认为,在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。
因此在Yolov5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边,如图所示:

图像高度上两端的黑边变少了,在推理时,计算量也会减少,即目标检测速度会得到提升。
通过这种简单的改进,推理速度得到了37%的提升,可以说效果很明显。
Yolov5中填充的是灰色,即(114,114,114),都是一样的效果,且训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到416*416大小。只是在测试,使用模型推理时,才采用缩减黑边的方式,提高目标检测,推理的速度。
- 正样本增加
[3]
这块同YOLO v4的Using multi-anchors for single ground truth一样.

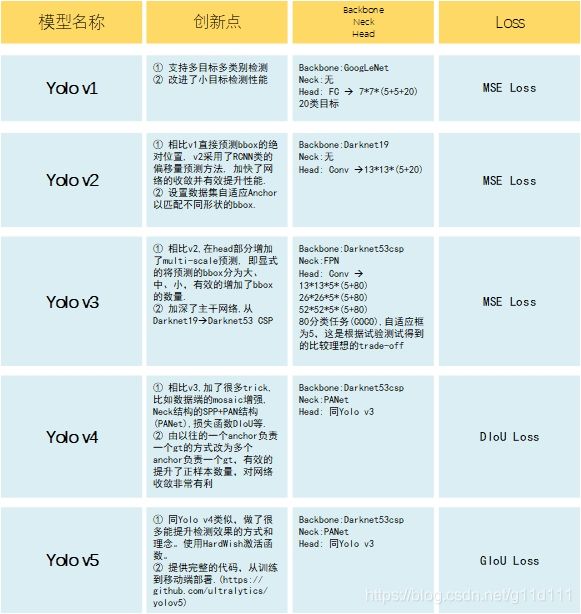
2. 总结
下图是笔者总结的YOLO系列的每一代的特点,其中,Loss部分会在系列3讲。
参考文章
[1] 你一定从未看过如此通俗易懂的YOLO系列(从v1到v5)模型解读 (上)
[2] 你一定从未看过如此通俗易懂的YOLO系列(从v1到v5)模型解读 (中)
[3] 你一定从未看过如此通俗易懂的YOLO系列(从v1到v5)模型解读 (下)
[4] What’s new in YOLO v3?
[5] YOLO v5的Focus层
[6] 使用YOLO V5训练自动驾驶目标检测网络
[7] YOLO v5的Bottleneck层
[8] Path Aggregation Network for Instance Segmentation: CVPR2018
[9] YOLO v5 代码的train.py