Datawhale组队学习(Pandas) task4-分组
Joyful Pandas 第四章 分组

练一练
请根据上下四分位数分割,将体重分为high、normal、low三组,统计身高的均值。
q1 = df['Weight'].quantile(0.25)
q2 = df['Weight'].quantile(0.75)
df['Weight'] = df['Weight'].mask(df['Weight']<q1, 'low').mask((q1<=df['Weight'])&(df['Weight']<q2), 'normal').mask(df['Weight']>=q2, 'high')
df.groupby('Weight')['Height'].mean()
请查阅文档,明确 all/any/mad/skew/sem/prod 函数的含义
gb.all() # 返回是否所有元素都为真
gb.any() # 一个序列中满足一个True,则返回True
gb.mad() # 根据平均值计算平均绝对距离差
gb.skew() # 返回峰度
gb.sem() # 返回所请求轴上的平均值的无偏标准误差
gb.prod() # 返回乘积
请使用【b 对特定的列使用特定的聚合函数】中的传入字典的方法完成【a 使用多个函数】中等价的聚合任务
agg_list = ['sum','idxmax','skew']
gb.agg({
'Height':agg_list, 'Weight':agg_list})
在 groupby 对象中可以使用 describe 方法进行统计信息汇总,请同时使用多个聚合函数,完成与该方法相同的功能。
gb.agg(['count','mean','std','min',('25%',lambda x:x.quantile(0.25)),('50%','quantile'),('75%',lambda x:x.quantile(0.75)),'max'])
# 也参考了群内小伙伴(@天国之影)的答案,法2:
def quantile(n):
def quantile_(x):
return x.quantile(n/100)
quantile_.__name__ = '{0}%'.format(n)
return quantile_
describe_list = ['count','mean','std','min','max',quantile(25), quantile(50), quantile(75)]
gb.agg(describe_list)
在 groupby 对象中, rank 方法也是一个实用的变换函数,请查阅它的功能并给出一个使用的例子。
.groupby().rank() 是对dataframe某列的数据进行聚类,然后对其他列的属于同类数据进行数值大小排序
df.groupby('Gender')['Weight'].rank(method='min')
对于 transform 方法无法像 agg 一样,通过传入字典来对指定列使用特定的变换,如果需要在一次 transform 的调用中实现这种功能,请给出解决方案。
# 我好废.../(ㄒoㄒ)/ 没有想到怎么解决这道题
# 参考了@Gocara
gb.transform(lambda x:{
'Height':eval('x.cummin()'),'Weight':eval('x.rank()')}[x.name]).head()
# eval() 函数用来执行一个字符串表达式,并返回表达式的值。
从概念上说,索引功能是组过滤功能的子集,请使用 filter 函数完成 loc[.] 的功能,这里假设 ” . “是元素列表。
# df.loc[0:4]
df.groupby(df.index.isin([i for i in range(5)])).filter(lambda x:x.name)

练习1:汽车数据集
1-1:先过滤出所属 Country 数超过2个的汽车,即若该汽车的 Country 在总体数据集中出现次数不超过2则剔除,再按 Country 分组计算价格均值、价格变异系数、该 Country 的汽车数量,其中变异系数的计算方法是标准差除以均值,并在结果中把变异系数重命名为 CoV 。
我的答案
gb = df.groupby('Country')
index_list = gb.filter(lambda x:x.shape[0]<=2).index
df_drop = df.drop(index_list) # 删掉小于2的
gb = df_drop.groupby('Country')['Price']
gb.agg(['mean',(lambda x:x.shape[0]), ('CoV',lambda x:x.std()/x.mean())])
参考答案
df.groupby('Country').filter(lambda x:x.shape[0]>2).groupby('Country')['Price'].agg([('CoV', lambda x:x.std()/x.mean()), 'mean','count'])
心得
- 过滤掉≤2的,没必要先找出≤2再删除,可以直接选>2的
- 不用分开写,直接继续
groupby → agg就好了 - 统计个数使用内置的
count即可
1-2:按照表中位置的前三分之一、中间三分之一和后三分之一分组,统计 Price 的均值。
我的答案
# 先将三个区间标记出来
df.loc[:df.shape[0]/3-1,'label']='a'
df.loc[df.shape[0]/3:df.shape[0]/3*2-1,'label']='b'
df.loc[df.shape[0]/3*2:,'label']='c'
df.groupby('label')['Price'].mean() # 根据标记分组,再求均值
>>>
label
a 9069.95
b 13356.40
c 15420.65
Name: Price, dtype: float64
参考答案
condition = ['Head']*20+['Mid']*20+['Tail']*20
df.groupby(condition)['Price'].mean()
心得
- 先赋值的方法太笨啦,
condition的构造方法学到啦 - 主要考察按照条件列表中的元素值来分组的知识点
1-3:对类型 Type 分组,对 Price 和 HP 分别计算最大值和最小值,结果会产生多级索引,请用下划线把多级列索引合并为单层索引。
我的答案
gb_type = df.groupby('Type')['Price','HP']
agg_result = gb_type.agg(['min','max'])
agg_result.columns = agg_result.columns.map(lambda x:(x[0]+'_'+x[1]))
参考答案
res = df.groupby('Type').agg({
'Price': ['max'], 'HP': ['min']})
res.columns = res.columns.map(lambda x:'_'.join(x))
心得
- 没审题,实际考察了对特定列使用特定聚合函数的知识点
- 回忆了上一节的知识点 反向展开
.map()
1-4:对类型 Type 分组,对 HP 进行组内的 min-max 归一化。
我的答案
df.groupby('Type')['HP'].transform(lambda x:(x-x.min())/(x.max()-x.min()))
参考答案
def normalize(s):
s_min, s_max = s.min(), s.max()
res = (s - s_min)/(s_max - s_min)
return res
df.groupby('Type')['HP'].transform(normalize).head()
1-5:对类型 Type 分组,计算 Disp. 与 HP 的相关系数。
我的答案
df.groupby('Type')['Disp.','HP'].corr()
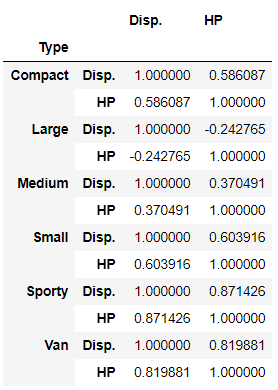
参考答案
df.groupby('Type')[['HP', 'Disp.']].apply(lambda x:np.corrcoef(x['HP'].values, x['Disp.'].values)[0,1])

心得
- 本题是计算计算
Disp.与HP的相关系数,而我算的是两两之间的相关系数矩阵,不符题意 - 答案思路是用
apply(),然后用[0,1]取出了相关系数
练习2:实现transform函数
class my_groupby:
def __init__(self, my_df, group_cols):
self.my_df = my_df.copy()
self.groups = my_df[group_cols].drop_duplicates()
# isinstance() 函数来判断一个对象是否是一个已知的类型
# 判断传入的是不是Series
if isinstance(self.groups, pd.Series):
self.groups = self.groups.to_frame()
self.group_cols = self.groups.columns.tolist() # 组列名
self.groups = {
i:self.groups[i].values.tolist() for i in self.groups.columns} # 组
self.transform_col = None
def __getitem__(self, col):
self.pr_col = [col] if isinstance(col, str) else list(col)
return self
def transform(self, my_func):
self.num = len(self.groups[self.group_cols[0]])
L_order, L_value = np.array([]), np.array([])
for i in range(self.num):
group_df = self.my_df.reset_index().copy()
for col in self.group_cols:
group_df = group_df[group_df[col]==self.groups[col][i]]
group_df = group_df[self.pr_col]
if group_df.shape[1]==1:
group_df = group_df.iloc[:,0]
groups_res = my_func(group_df)
if not isinstance(groups_res, pd.Series):
groups_res = pd.Series(groups_res, index=group_df.name, name=group_df.name)
L_order = np.r_[L_order, groups_res.index] # 按列连接两个矩阵
L_value = np.r_[L_value, groups_res.values]
self.res = pd.Series(pd.Series(L_value, index=L_order).sort_index().values, index=self.my_df.reset_index().index, name=my_func.__name__)
return self.res
好难…看了答案和其他同学的分析,发现还是不理解。坐等B站的讲解视频。真的不会…/(ㄒoㄒ)/
本来感觉这章内容不是太多,学起来应该会比较快,没想到有好多练一练,练习题2还是大魔王。很多不会的东西也参考了这位同学的笔记,好强好厉害。