第22章 对象共享,避免创建多对象——享元模式
第22章 对象共享,避免创建多对象——享元模式
- 22.1 享元模式介绍
- 22.2 享元模式的定义
- 22.3 享元模式的使用场景
- 22.4 享元模式的UML类图
- 22.5 享元模式的简单示例
- 22.6 Android源码中的享元模式
- 22.7 深度拓展
-
- 22.7.2 子线程中创建Handler为何会抛出异常
- 22.8 小结
22.1 享元模式介绍
享元模式是对象池的一种实现,它的英文名称叫做Flyweight,代表轻量级的意思。享元模式用来尽可能减少内存使用量,它适合用于可能存在大量重复对象的场景,来缓存可共享的对象,达到对象共享、避免创建过多对象的效果,这样一来就可以提升性能、避免内存移除等。
享元对象中的部分状态是可以共享,可以共享的状态成为内部状态,内部状态不会随着环境变化;不可共享的状态则称为外部状态,它们会随着环境的改变而改变。在享元模式中会建立一个对象容器,在经典的享元模式中该容器为一个Map,它的键是享元对象的内部状态,它的值就是享元对象本身。客户端程序通过这个内部状态从享元工厂中获取享元对象,如果有缓存则使用缓存对象,否则创建一个享元对象并且存入容器中,这样一来就避免了创建过多对象的问题。
22.2 享元模式的定义
使用共享对象可有效地支持大量的细粒度的对象。
22.3 享元模式的使用场景
- 系统中存在大量的相似对象。
- 细粒度的对象都具备较接近的外部状态,而且内部状态与环境无关,也就是说对象没有特定身份。
- 需要缓冲池的场景。
22.4 享元模式的UML类图
UML类图如图22-1所示。
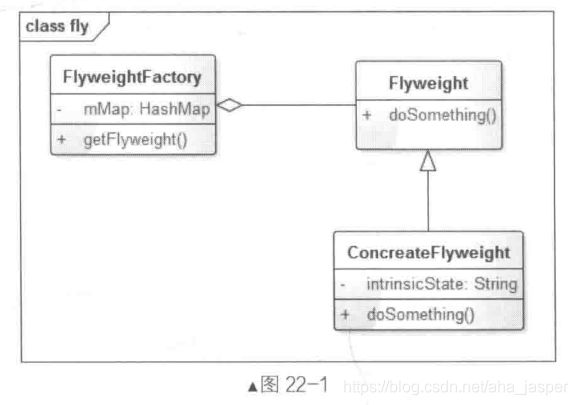
角色介绍
- Flyweight:享元对象抽象基类或者接口。
- ConcreateFlyweight:具体的享元对象。
- FlyweightFactory:享元工厂,负责管理享元对象池和创建享元对象。
22.5 享元模式的简单示例
过年回家买火车票是一件很困难的事,无数人用刷票软件向服务端发出请求,对于每一个请求服务器都必须做出应答。在用户设置好出发地和目的地之后,每次请求都返回一个查询的车票结果。为了便于理解,我们假设每次返回的只有一躺列车的车票。那么当数以万计的人不间断在请求数据时,如果每次都重新创建一个查询的车票结果,那么必然会造成大量重复对象的创建、销毁,使得GC任务繁重、内存占用率高居不下。而这类问题通过享元模式就能够得到很好地改善,从城市A到城市B的车辆是有限的,车上的铺位也就是软卧、硬卧、坐票3种。我们将这些可以公用的对象缓存起来,在用户查询时优先使用缓存,如果没有缓存则重新创建。这样就将成千上万的对象变为了可选择的有限数量。
首先我们创建一个Ticket接口,该接口定义展示车票信息的函数,具体代码如下。

它的一个具体的实现类是TrainTicket类,具体代码如下。


数据库中表示火车票的信息有出发地、目的地、铺位、价格等字段,在购票用户每次查询时如果没有用某种缓存模式,那么返回车票数据的接口实现如下。

在TicketFactory的getTicket函数中每次会new一个TrainTicket对象,也就是说如果在短时间内有10000万用户求购北京到青岛的车票,那么北京到青岛的车票对象就会被创建10000次,当数据返回之后这些对象变得无用了又会被虚拟机回收。此时就会造成大量的重复对象存在内存中,GC对这些对象的回收也会非常消耗资源。如果用户的请求量很大可能导致系统变得极其缓慢,甚至可能导致OOM。
正如上文所说,享元模式通过消息池的形式有效地减少了重复对象的存在。它通过内部状态标识某个种类的对象,外部程序根据这个不会变化的内部状态从消息池中取出对象。使得同一类对象可以被复用,避免大量重复对象。
使用享元模式很简单,只需要简单地改造一下TicketFactory,具体代码如下。

我们在TicketFactory中添加了一个map容器,并且以出发地+“-”+目的地为键、以车票对象作为值存储车票对象。这个map的键就是我们说的内部状态,在这里就是出发地、横杠、目的地拼接起来的字符串,如果没有缓存则创建一个对象,并且将这个对象缓存到map中,下次再有这类请求时则直接从缓存中获取。这样即使有10000个请求北京到青岛的车票信息,那么出发地是北京、目的地是青岛的车票对象只有一个。这样就从这个对象从10000减到了1个,避免了大量的内存占用及频繁的GC操作。简单实现代码如下。
![]()

运行结果:

从输出结果可以看到,只有第一次查询车票时创建了一次对象,后续的查询都使用的是消息池中的对象。这其实就是相当于一个对象缓存,避免了对象的重复创建与回收。在这个例子中,内部状态就是出发地和目的地,内部状态不会发生变化;外部状态就是铺位和价格,价格会随着铺位的变化而变化。
在JDK中String也是类似消息池,我们知道在Java中String是存在于常量池中。也就是说一个String被定义之后它就被缓存到了常量池中,当其他地方要使用同样的字符串时,则直接使用的是缓存,而不会重复创建。例如下面这段代码。

输出如下:

在前3个通过equals函数判定中,由于它们的字符值都相等,因此3个判等都为true,因此,String的equals 只根据字符值进行判断。而在后4个判断中则使用的是两个等号判断,两个等号判断代表的意思是判定这两个对象是否相等,也就是两个对象指向的内存地址是否相等。由于str1和str3都是通过new构建的,而str2则是通过字面值赋值的,因此这3个判定都为false,因为它们并不是同一个对象。而str2和str4都是通过字面值赋值的,也就是直接通过双引号设置的字符串值,因此,最后一个通过“=”判定的值为true,也就是说str2和str4是同一个字符串对象。因为str4使用了缓存在常量池中的str2对象。这就是享元模式在我们开发中的一个重要案例。
22.6 Android源码中的享元模式
在用Android开发了一段时间之后,很多读者就应该知道了一个知识点:UI不能够在子线程中更新。这原本就是一个伪命题,因为并不是UI不可以在子线程更新,而是UI不可以在不是它的创建线程里进行更新。只是绝大多数情况下UI都是从UI线程中创建的,因此,在其他线程更新时会抛出异常。在这种情况下,当我们在子线程完成了耗时操作之后,通常会通过一个Handler将结果传递给UI线程,然后在UI线程中更新相关的视图。代码大致如下。

在MainActivity中首先创建了一个Handler对象,它的Looper就是UI线程的Looper。在子线程执行完耗时操作之后,则通过Handler向UI线程传递一个Runnable,即这个Runnable执行在UI线程中,然后在这个Runnable中更新UI即可。
那么Handler、Looper的工作原理又是什么呢?它们之间是如何协作的?
在讲此之前我们还需要了解两个概念,即Message和MessageQueue。其实Android应用是事件驱动的,每个事件都会转化为一个系统消息,即Message。消息中包含了事件相关的信息以及这个消息的处理人 Handler。每个进程中都有一个默认的消息队列,也就是我们的MessageQueue,这个消息队列维护了一个待处理的消息列表,有一个消息循环不断地从这个队列中取出消息、处理消息,这样就使得应用动态地运作起来。它们的运作原理就像工厂的生产线一样,待加工的产品就是Message,"传送带”就是MessageQueue,工人们就对应处理事件的Handler。这么一来Message就必然会产生很多对象,因为整个应用都是由事件,也就是Message来驱动的,系统需要不断地产生Message、处理Message、销毁Message,难道Android没有iOS流畅就是这个原因吗?答案显然没有那么简单,重复构建大量的Message也不是Android的实现方式。那么我们先从Handler发送消息开始一步一步学习它的原理。
就用上面的例子来说,我们通过Handler传递了一个Runnable给UI线程。实际上Runnable会被包装到一个Message对象中,然后再投递到UI线程的消息队列。我们看看Handler的post(Runnable run)函数。

在post函数中会调用sendMessageDelayed函数,但在此之前调用了getPostMessage将Runnable包装到一个Message对象中。然后再将这个Message对象传递给sendMessageDelayed函数,具体代码如下。

sendMessageDelayed函数最终又调用了sendMessageAtTime函数,我们知道,post消息时是可以延时发布的,因此,有一个delay的时间参数。在sendMessageAtTime函数中会判断当前Handler的消息队列是否为空,如果不为空那么就会将该消息追加到消息队列中。又因为我们的Handler在创建时就关联了UI线程的Looper(如果不手动传递Looper那么Handler持有的Looper就是当前线程的Looper,也就是说在哪个线程创建的Handler,就是哪个线程的Looper),Handler从这个Looper中获取消息队列,这样一来Runnable就会被放到UI线程的消息队列了,因此,我们的Runnable在后续的某个时刻就会被执行在UI线程中。
这里我们不需要再深究Handler、Looper等角色的运作细节,我们这里关注的是享元模式的运用。在上面的getPostMessage中会将Runnable包装为一个Message,在前文没有说过,系统并不会构建大量的Message对象,那么它是如何处理的呢?
我们看到在getPostMessage中的Message对象是从一个Message.obtain()函数返回的,并不是使用new来实现,如果使用new那么就是我们起初猜测的会构建大量的Message对象,当然到目前还不能下结论,我们看看Message.obtain()的实现。

实现很简单,但是有一个很引人注意的关键词——Pool,它的中文意思称为池,难道是我们前文所说的共享对象池?目前我们依然不能确定,但是,此时已经看到了一些重要线索。现在就来看看obtain中的sPoolSync、sPool里是些什么程序。

首先Message文档第一段的意思就是介绍了一下这个Message类的字段,以及说明Message对象是被发送到Handler的,对于我们来说作用不大。第二段的意思是建议我们使用Message的obtain方法获取Message对象,而不是通过Message的构造函数,因为obtain方法会从被回收的对象池中获取Message对象。然后再看看关键的字段,sPoolSync是一个普通的Object对象,它的作用就是用于在获取Message对象时进行同步锁。再看sPool居然是一个Message对象,居然不是我们上面说的消息池之类的东西,既然它命名为sPool不可能是有名无实吧,我们再仔细看,发现了这个字段。
![]()
这个字段就在sPoolSync上面,“山重水复疑无路,柳暗花明又一村”。一看上面的注释我们就明白了,原来Message消息池没有使用map这样的容器,使用的是链表!这个next就是指向下一个Message的。Message的链表如图22-2所示。
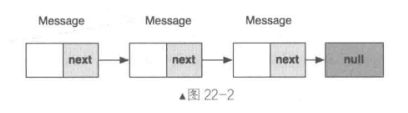
每个Message对象都有一个同类型的next字段,这个next指向的就是下一个可用的Message,最后一个可用的Message的next则为空。这样一来,所有可用的Message对象就通过next串连成一个可用的Message池。
那么这些Message对象什么时候会被放到链表中呢?我们在obtain函数中只看到了从链表中获取,并且看到存储。如果消息池链表中没有可用对象的时候,obtain中则是直接返回一个通过new创建的Message对象,而且并没有存储到链表中。此时,我们再次遇到了难点,暂时找不到相关线索了。
此时我们只好回过头再看看Message类的说明,发现一个重要的句子。
"which will pull them from a pool of recycled objects.”,噢,原来在创建的时候不会把 Message对象放到池中,在回收(这里的回收并不是指虚拟机回收Message对象)该对象时才会将该对象添加到链表中。
我们搜索一番之后果然发现了Message类中有类似Bitmap那样的recycle函数。具体代码如下。


recycle函数会将一个Message对象回收到一个全局的池中,这个池也就是我们上文说的链表。recycle函数首先判断该消息是否还在使用,如果还在使用则抛出异常,否则调用recycleUnchecked函数处理该消息。recycleUnchecked函数中先清空该消息的各字段,并且将flags设置为FLAG_IN_USE,表明该消息已被使用,这个flag在obtain函数中会被置为0,这样根据这个flag就能够追踪该消息的状态。然后判断是否要将该消息回收到消息池中,如果池的大小小于MAX_POOL_SIZE时,将自身添加到链表的表头。例如,当链表中还没有元素时,将第一个Message对象添加到链表中,此时sPool为null,next指向了sPool,因此,next也为null然后sPool又指向了this,因此,sPool就指向了当前这个被回收的对象,并且sPoolSize加1。我们把这个被回收的Message对象命名为m1,此时结构图如图22-3所示。
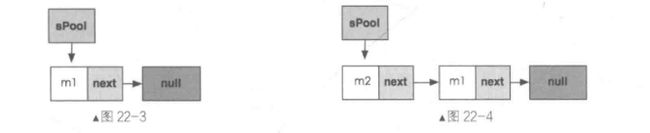
此时如果再插入一个名称为m2的Message对象,那么m2将会被插到表头中,此时sPool指向的就是m2,结构如图22-4所示。
这个对象池的大小默认为50,因此,如果池大小在小于50的情况下,被回收的Message就会被插到链表头部。
此时如果池中有元素,当我们调用obtain函数时,如果池中有元素就会从池中获取,实际上获取的也是表头元素,也就是这里的sPool。然后再将sPool这个指针后移到下一个元素。具体代码如下。

在obtain函数中,首先会声明一个Message对象m,并且让m指向sPool。sPool实际上指向了m2,因此,m实际上指向的也是m2,这里相当于保存了m2这个元素。下一步是sPool指向m2的下一个元素,也就是m1。sPool也完成后移之后此时把m.next置空,也就相当于m2.next变成了null。最后就是m指向了m2元素,m2的next为空,sPool从原来的表头m2指向了下一个元素m1,最后将对象池的元素减1,这样m2就顺利地脱离了消息池队伍,返回给了调用obtain函数的客户端程序。此时结构如图22-5所示。
现在己经很明朗了,Message通过在内部构建一个链表来维护一个被回收的Message对象的对象池,当用户调用obtain函数时会优先从池中取,如果池中没有可以复用的对象则创建这个新的Message对象。这些新创建的Message对象在被使用完之后会被回收到这个对象池中,当下次再调用obtain函数时,它们就会被复用。这里的Message相当于承担了享元模式中3个元素的职责,即是Flyweight抽象,又是ConcreteFlyweight角色,同时又承担了FlyweightFactory管理对象池的职责。因为Android应用是事件驱动的,因此,如果通过new创建Message就会创建大量重复的Message对象,导致内存占用率高、频繁GC等问题,通过享元模式创建一个大小为50的消息池,避免了上述问题的产生,使得这些问题迎刃而解。当然,这里的享元模式并不是经典的实现方式,它没有内部、外部状态,集各个职责于一身,甚至它更像是一个对象池,但这些都是很细节问题,我们关注的是灵活运用模式本身来解决问题。至于Message对象是否职责过多,既是实体类又是工厂类, 这些问题每个人见仁见智,也许你觉得增加一个MessagePool来管理Message对象的回收、获取工作不会更好,这样也满足了单一职责原则;或者你觉得就这样用就挺好,没有必要增加管理类。这些我们不过多评论,原则上只是提供了一个可借鉴的规则,这个规则很多时候并不是一成不变的, 可以根据实际场景进行取舍。规则是使读者避免走向软件大泥潭,灵活运用才是最终的目的所在。
22.7 深度拓展
上文我们说到,Message、MessageQueue、Looper、Handler的工作原理像是工厂的生产线,Looper就是发动机,MessageQueue就是传送带,Handler就是工人,Message则是待处理的产品。它们的结构图如图22-6所示。

前面的章节中我们多次提到Android应用程序的入口实际上是ActivityThread.main方法,在该方法中首先会创建Application和默认启动的Activity,并且将它们关联在一起。而该应用的UI线程的消息循环也是在这个方法中创建的,具体源码如下。


执行ActivityThread.main方法后,应用程序就启动了,UI线程的消息循环也在Looper.loop()函数中启动。此后Looper会一直从消息队列中取消息,然后处理消息。用户或者系统通过Handler不断地往消息队列中添加消息,这些消息不断地被取出、处理、回收,使得应用迅速地运转起来。
例如,我们在子线程中执行完耗时操作后通常需要更新UI,但我们都“知道”不能在子线程中更新UI。此时最常用的手段就是通过Handler将一个消息post到UI线程中,然后再在Handler的handleMessage方法中进行处理。但是有一点要注意,如果用在不传递UI线程所属的Looper的情况下,那么该Handler必须在主线程中创建!正确地使用示例如下。

为什么必须要这么做呢?
其实每个Handler都会关联一个消息队列,消息队列被封装在Lopper中,而每个Looper又是ThreadLocal的,也就是说每个消息队列只会属于一个线程。因此,如果一个Looper在线程A中创建,那么该Looper只能够被线程A访问。而Handler则是一个消息投递、处理器,它将消息投递给消息队列,然后这些消息在消息队列中被取出,并且执行在关联了该消息队列的线程中。
默认情况下,消息队列只有一个,即主线程的消息队列,这个消息队列是在ActivityThread.main方法中创建的,也就调用了Lopper.prepareMainLooper方法,创建Looper之后,最后会执行Looper.loop()来启动消息循环。
那么Handler是如何关联消息队列以及线程呢?我们还是深入源码来分析,首先看看Handler的构造函数。

从Handler默认的构造函数中我们可以看到,Handler会在内部通过Looper.getLooper()来获取Looper对象,并且与之关联,最重要的就是获取到Looper持有的消息队列mQueue。那么Looper.getLooper()又是如何工作的呢?我们继续往下看。

我们看到myLooper方法是通过sThreadLocal.get()来获取的,关于ThreadLocal的资料请参考Java相关的书籍。那么Looper对象又是什么时候存储在sThreadLocal中的呢?有些读者可能看到 了,上面给出的代码中给出了一个熟悉的方法prepareMainLooper,在这个方法中调用了prepare()方法,在prepare()方法中创建了一个Looper对象,并且将该对象设置给了sThreadLocal。这样,队列就与线程关联上了。
我们再回到Handler中来,Looper属于某个线程,消息队列存储在Looper中,因此,消息队列就通过Looper与特定的线程关联上。而Handler又与Looper、消息队列关联,因此,Handler最终就和线程、线程的消息队列关联上了,通过该Handler发送的消息最终就会被执行在这个线程上。这就能解释上面提到的问题了,“在不传递Looper参数给Handler构造函数的情况下,用更新UI的Handler为什么必须在UI线程中创建?”。就是因为Handler要与主线程的消息队列关联上,这样handleMessage才会执行在UI线程中,更新UI才是被允许的。
创建了Looper后,会调用Looper的loop函数,在这个函数中会不断地从消息队列中取出、处理消息,具体源码如下。

从上述程序可以看到,loop方法中实质上就是建立一个死循环,然后通过从消息队列中逐个取出消息,最后就是处理消息、回收消息的过程。
在注释3处,调用了MessageQueue的next函数来获取下一条要处理的消息。这个MessageQueue在Looper的构造函数中构建,我们看看next函数的核心代码。


完整的next函数稍微有些复杂,但这里只分析核心的程序。next函数的基本思路就是从消息队列中依次取出消息,如果这个消息到了执行时间,那么就将这条消息返回给Looper,并且将消息队列链表的指针后移。这个消息队列链表结构与Message中的消息池结构一致,也是通过Message的next字段将多个Message对象串连在一起。但是在从消息队列获取消息之前,还有一个nativePollOnce函数的调用,第一个参数为mPtr,第二个参数为超时时间。
这与Native层有什么关系?mPtr又是什么?
其实这个mPtr可是大有来头,它存储了Native层的消息队列对象,也就是说Native层还有一个MessageQueue类型。mPtr的初始化是在MessageQueue的构造函数中,具体代码如下。

可以看到,mPtr的值是nativelnit函数返回的,该函数在android_os_MessageQueue.cpp类中,我们继续跟踪代码。

我们看到,在nativelnit函数中会构造一个NativeMessageQueue对象,然后将该对象转为个整型值,并且返回给Java层中,而当Java层需要与Native层的MessageQueue通信时只要把这个int值传递给Native层,然后Native通过reinterpret_cast将传递进来的int转换为NativeMessageQueue指针即可得到这个NativeMessageQueue对象指针。首先看看NativeMessageQueue类的构造函数。


代码很简单,就是创建了一个Native层的Looper,然后这个Looper设置给了当前线程。也就是说Java层的MessageQueue和Looper在Native层也都有,但是,它们功能并不是一一对应的。 那么看看Looper究竟做了什么,首先看看它的构造函数,代码在system/core/libutils/Looper.cpp文件中。

首先创建了一个管道(pipe),管道本质上就是一个文件,一个管道中含有两个文件描述符,分别对应读和写。一般的使用方式是一个线程通过读文件描述符来读管道的内容,当管道没有内容时,这个线程就会进入等待状态;而另外一个线程通过写文件描述符来向管道中写入内容,写入内容的时候,如果另一端正有线程正在等待管道中的内容,那么这个线程就会被唤醒。这个等待和唤醒的操作是通过Linux系统的epoll机制。要使用Linux系统的epoll机制,首先要通过epoll create来创建一个epoll专用的文件描述符,即注释2的代码。最后通过epoll_ctl函数设置监听的事件类型为EPOLLIN。此时Native层的MessageQueue和Looper就构建完毕了,在底层也通过管道和epoll建立了一套消息机制。Native层构建完毕之后则会返回到Java层Looper的构造函数,因此,Java层的Looper和MessageQueue也构建完毕。
这个过程有点绕,我们总结一下。
- 首先构造Java层的Looper对象,Looper对象又会在构造函数中创建Java层的MessageQueue对象。
- Java层的MessageQueue的构造函数中调用nativelnit函数初始化Native层的NativeMessageQueue, NativeMessageQueue的构造函数又会创建Native层的Looper,并且通过管道和epoll建立一套消息机制。
- Native层构建完毕,将NativeMessageQueue对象转换为一个整型存储到Java层的MessageQueue的mPtr中。
- 启动Java层的消息循环,不断地读取、处理消息。
这个初始化过程都是在ActivityThread的main函数中完成的,因此,main函数运行之后,UI线程消息循环就启动了,消息循环不断地从消息队列中读取、处理消息,使得系统运转起来。
我们继续回到nativePollOnce函数本身,每次循环去读消息时都会调用这个函数,我们看看它到底做了什么?代码在android_os_MessageQueue.cpp中。

首先将传递进来的整型转换为NativeMessageQueue指针,这个整型就是在初始化时保存到mPtr的数值。然后调用了NativeMessageQueue的polIOnce函数。具体代码如下。

这里的代码很简单,调用了Native层Looper的polIOnce函数。Native层Looper类的完整路径是 system/core/libutils/Looper.cpp,polIOnce函数如下。

该函数的核心在于调用了polllnner,我们看看polllnner的相关实现。


从polllnner的核心代码中看,pollinner实际上就是从管道中读取事件,并且处理这些事件。这样一来就相当于在Native层存在一个独立的消息机制,这些事件存储在管道中,而Java层的事件则存储在消息链表中。但这两个层次的事件都在Java层的Looper消息循环中进行不断地获取、处理等操作,从而实现程序的运转。但需要注意的是,Native层的NativeMessageQueue实际上只是一个代理Native Looper的角色,它没有做什么实际工作,只是把操作转发给Looper。而Native Looper则扮演了一个Java层的Handler角色,它能够发送消息、取消息、处理消息。
那么Android为什么要有两套消息机制呢?我们知道Android是支持纯Native开发的,因此,在Native层实现一套消息机制是必须的。另外,Android系统的核心组件也都是运行在Native世界,各组件之间也需要通信,这样一来Native层的消息机制就变得很重要。
在分析了消息循环与消息队列的基本原理之后,最后看看消息处理逻辑。我们看到在Java层的MessageQueue的next函数的第4步调用了msg.target.dispatchMessage(msg)来处理消息。其中msg是Message类型,我们看看源码。

从源码中可以看到,target是Handler类型。实际上就是转了一圈,通过Handler将消息传递给消息队列,消息队列又将消息分发给Handler来处理,其实这也是一个典型的命令模式,Message就是一条命令,Handler就是处理人,通过命令模式将操作和执行者解耦。我们继续回到Handler代码中,消息处理是调用了Handler的dispatchMessage方法,相关代码如下。


从上述程序中可以看到,dispatchMessage只是一个分发的方法,如果Runnable类型的callback为空则执行handlerMessage来处理消息,该方法为空,我们会将更新UI的代码写在该函数中;如果callback不为空,则执行handleCallback来处理,该方法会调用callback的run方法。其实这是Handler分发的两种类型,比如我们post(Runnable callback)则callback就不为空,此时就会执行Runnable的run函数;当我们使用Handler来sendMessage时通常不会设置callback,因此,也就执行handlerMessage这个分支。下面我们看看通过Handler来post一个Runnable对象的实现代码。

从上述程序可以看到,在post(Runnable r)时,会将Runnable包装成Message对象,并且将Runnable对象设置给Message对象的callback字段,最后会将该Message对象插入消息队列。sendMessage也是类似实现。

因此不管是post一个Runnbale还是Message,都会调用sendMessageDelayed(msg,time)方法,然后该Message就会追加到消息队列中,当在消息队列中取出该消息时就会调用callback的run方法或者Handler的handleMessage来执行相应的操作。
最后总结一下就是消息通过Handler投递到消息队列,这个消息队列在Handler关联的Looper中,消息循环启动之后会不断地从队列中获取消息,其中消息的处理分为Native层和Java层,两个层次都有自己的消息机制,Native层基于管道和epoll,而Java层则是一个普通的链表。获取消息之后会调用消息的callback或者分发给对应Handler的handleMessage函数进行处理,这样就将消息、消息的分发、处理隔离开来,降低各个角色之间的耦合。消息被处理之后会被收回到消息池中便于下次利用,这样整个应用通过不断地执行这个流程就运转起来了。
22.7.2 子线程中创建Handler为何会抛出异常
先给一段程序。

上面的代码有问题吗?
如果你能够发现并且解释上述代码的问题,那么应该说您对Handler、Looper、Thread这几个概念已经很了解了。如果您还不太清楚,那么我们一起往下学习。
前面说过,Looper对象是ThreadLocal的,即每个线程都有自己的Looper,这个Looper可以为空。但是,当你要在子线程中创建Handler对象时,如果Looper为空,那么就会抛出"Can’t create handler inside thread that has not called Looper.prepare()"异常,为什么会这样呢?我们一起看源码。

从上述程序中我们可以看到,当mLooper对象为空时,抛出了该异常。这是因为该线程中的Looper对象还没有创建,因此,sThreadLocai.get()会返回null。我们知道Looper是使用ThreadLocal存储的,也就是说它是和线程关联的,在子线程中没有手动调用Looper.prepare之前该线程的Looper就为空。因此,解决方法就是在构造Handler之前为当前线程设置Looper对象,解决方法如下。

在代码中我们增加了2处,第一是通过Looper.prepare()来创建Looper,第二是通过Looper.loop()来启动消息循环。这样该线程就有了自己的Looper,也就是有了自己的消息队列。如果只创建Looper,而不启动消息循环,虽然不会抛出异常,但是你通过handler来post或者sendMessage也不会有效,因为虽然消息被追加到消息队列了,但是并没有启动消息循环,也就不会从消息队列中获取消息并且执行!
在应用启动时,会开启一个主线程(UI线程),并且启动消息循环,应用不停地从该消息队列中取出、处理消息达到程序运行的效果。Looper对象封装了消息队列,Looper对象被封装在ThreadLocal中,这使得不同线程之间的Looper不能被共享。而Handler通过与Looper对象绑定来实现与执行线程的绑定,handler会把Runnable(包装成Message)或者Message对象追加到与线程关联的消息队列中,然后在消息循环中逐个取出消息,并且处理消息。当Handler绑定的Looper是主线程的Looper,则该Handler可以在handleMessage中更新UI,否则更新UI则会抛出异常。
22.8 小结
享元模式实现比较简单,但是它的作用在某些场景确实极其重要的。它可以大大减少应用程序创建的对象,降低程序内存的占用,增强程序的性能,但它同时也提高了系统的复杂性,需要分离出外部状态和内部状态,而且外部状态具有固化特性,不应该随内部状态改变而改变,否则导致系统的逻辑混乱。
享元模式的优点在于它大幅度地降低内存中对象的数量。但是,它做到这一点所付出的代价也是很高的。
- 享元模式使得系统更加复杂。为了使对象可以共享,需要将一些状态外部化,这使得程序的逻辑复杂化。
- 享元模式将享元对象的状态外部化,而读取外部状态使得运行时间稍微变长。