【Task06】Pandas之连接
前言
在上一章,我们主要学习了pandas中的 变形 内容:
- 长表和宽表的概念及相互转化方法
- 行列索引交换
- 一些其他变形方法
利用变形方便后续进一步的数据操作。
在实际场景中不大可能只操作一张数据表,往往是将多个数据表连接后再进行下一步操作,所以在本章中,我们将要学习 连接 ,我们主要以 DataFrame数据 对方法进行举例说明,本章内容有:
- 关系型连接:按 值 or 索引 连接
- 按 方向 连接
- 类连接操作
一、关系型连接
1.连接的基本概念
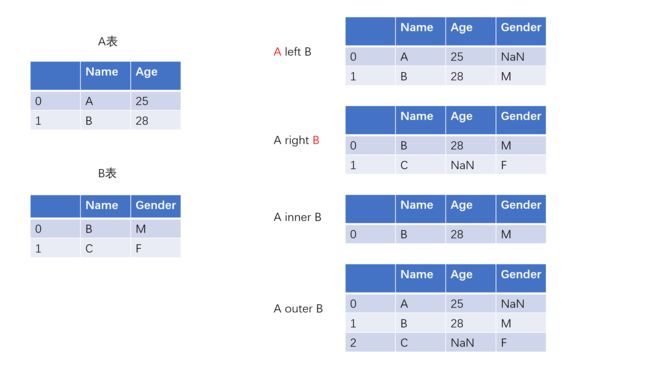
四种连接关系如上图所示,其中主键列为‘Name’:
- left:以左侧的表主键为主进行连接
- right:以右侧的表主键为主进行连接
- inner:取两表主键列的交集
- outer:取两表主键列的并集
这里可以把B right A看做B left A然后调换A和B的列索引位置。
若主键列某值X在A重复a次,在B重复b次,那么无论进行哪种表连接,连接后的表中X重复次数为a*b次,每次出现的属性值为之前两表属性值的 交叉相乘 。
2.值连接
1)按相同列进行连接
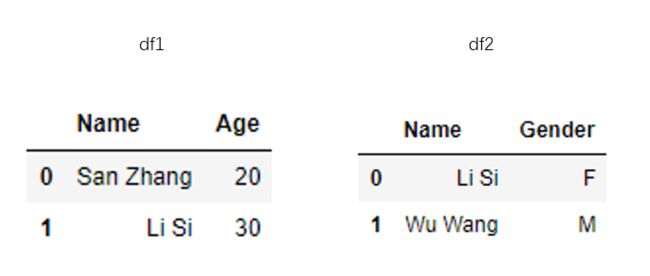
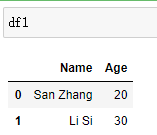
df1 = pd.DataFrame([['San Zhang',20],['Li Si',30]],columns=['Name','Age'])
df2 = pd.DataFrame([['Li Si','F'],['Wu Wang','M']],columns=['Name','Gender'])
两张表的直观展示如下:
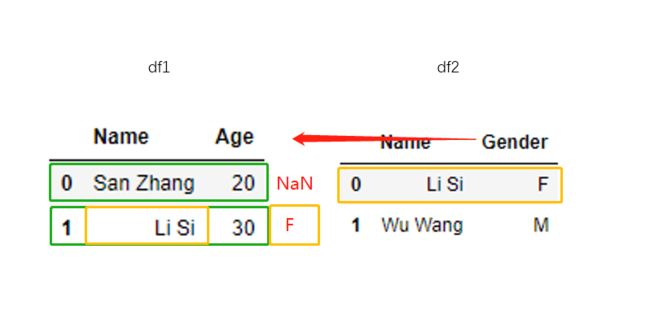
然后利用merge方法进行left连接:
df1.merge(df2, on='Name', how='left')
连接步骤如下:
结果:
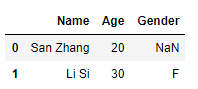
注意这里并不会改变原来的df1和df2:
2)按不同列进行连接
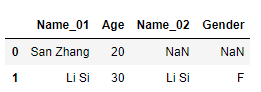
df1 = pd.DataFrame([['San Zhang',20],['Li Si',30]],columns=['Name_01','Age'])
df2 = pd.DataFrame([['Li Si','F'],['Wu Wang','M']],columns=['Name_02','Gender'])
两张表的直观展示如下:

这里采用指定不同列去进行left连接:
df1.merge(df2,left_on='Name_01',right_on='Name_02', how='left')
可以发现除了多了一列之外与上个例子基本一样:
3)处理含义不同的重复非主键列
df1 = pd.DataFrame([['San Zhang',88],['Li Si',75]],columns=['Name','Grade'])
df2 = pd.DataFrame([['San Zhang',75],['Wu Wang',90]],columns=['Name','Grade'])
两张表的直观展示如下:

可以看到这张表的‘Grade’的含义是不相同的,我们直接采用之前的left连接
df1.merge(df2,on='Name',how='left')
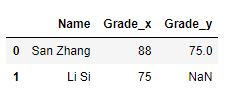
连接后发现有两列带有后缀的‘Grade’数据
查看官方API发现,这里是显示地将suffixes参数指定为[’_x’,’_y’]:

我们可以改成自己想要的列名:
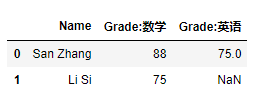
df1 = pd.DataFrame([['San Zhang',88],['Li Si',75]],columns=['Name','Grade'])
df2 = pd.DataFrame([['San Zhang',75],['Wu Wang',90]],columns=['Name','Grade'])
df1.merge(df2,on='Name',suffixes=[':数学',':英语'],how='left')
4)处理含义相同的重复非主键列
在上面的例子中,两张表的‘Grade’代表不同科目的成绩,那么如果两张表的非主键列表示是同一个含义,那么显然这种默认方式是不合理,如:
df1 = pd.DataFrame([['San Zhang',1,20],['San Zhang',2,30]],columns=['Name','Class','Age'])
df2 = pd.DataFrame([['San Zhang',1,'F'],['San Zhang',2,'M']],columns=['Name','Class','Gender'])
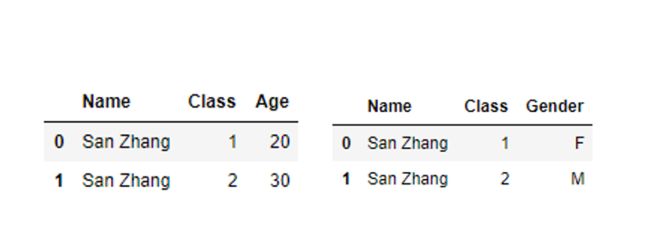
df1.merge(df2, on='Name', how='left')
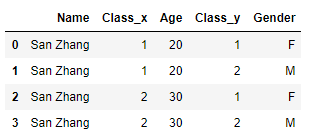
这里两张表的'Class'明显指的都是班级,所以这里需要显示地将它也指定为主键列:
df1.merge(df2, on=['Name','Class'], how='left')
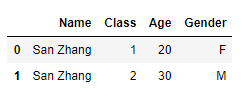
练一练01
题目:上面以多列为键的例子中,错误写法显然是一种多对多连接,而正确写法是一对一连接,请修改原表,使得以多列为键的正确写法能够通过validate='1:m’的检验,但不能通过validate='m:1’的检验。
考虑将df1的Name进行缩减。
df1 = pd.DataFrame([['San Zhang',1,20],['Wang Wu',2,30]],columns=['Name','Class','Age'])
df2 = pd.DataFrame([['San Zhang',1,'F'],['San Zhang',2,'M'],['Wang Wu',2,30]],columns=['Name','Class','Gender'])
df1.merge(df2, on='Name', how='left',validate='1:m')
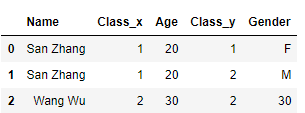
df1.merge(df2, on='Name', how='left',validate='m:1')

3.索引连接
如果说值连接是按主列进行连接,那么索引连接就是按照行索引去连接:
df1 = pd.DataFrame([[20],[30]], index=pd.Series(['San Zhang','Si Li'],name='Name'),columns=['Age'])
df2 = pd.DataFrame([['F'],['M']], index=pd.Series(['Si Li','Wu Wang'],name='Name'),columns=['Gender'])
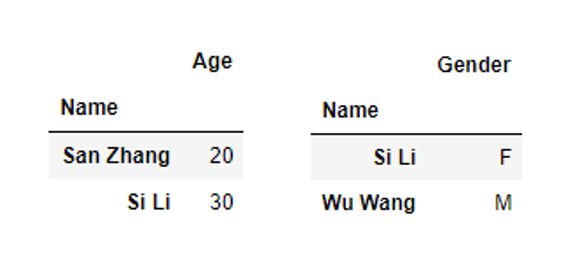
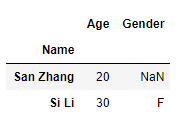
我们可以利用join方法进行索引连接:
df1.join(df2, how='left')
对于两张表的同一列属性,可以显式地指定额外后缀:
df1 = pd.DataFrame([70], index=pd.Series(['San Zhang'], name='Name'),columns=['Grade'])
df2 = pd.DataFrame([80], index=pd.Series(['San Zhang'], name='Name'),columns=['Grade'])
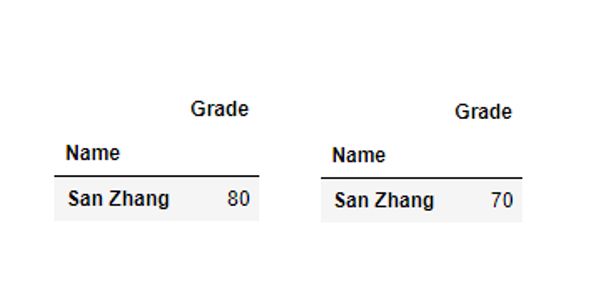
df1.join(df2, how='left', lsuffix=':语文', rsuffix=':数学')

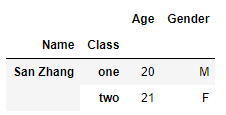
对于主键列存在相同值的情况,利用join方法也很好解决,要将最小能区分相同值的所有主键列都放在多级行索引中:
df1 = pd.DataFrame([[20],[21]], index=pd.MultiIndex.from_arrays([['San Zhang', 'San Zhang'],['one', 'two']], names=('Name','Class')),columns=['Age'])
df2 = pd.DataFrame([['F'], ['M']], index=pd.MultiIndex.from_arrays([['San Zhang', 'San Zhang'],['two', 'one']], names=('Name','Class')),columns=['Gender'])

df1.join(df2, how='left')
二、方向连接
1.concat方法
一共存在2大类(横向和纵向),每大类五种情况,以列连接为例,假设df1的列为a,df2的列为b:
- a等于b
- b包含于a
- a包含于b
- b有一部分属于a,另外不属于
- a有一部分属于b,另外不属于
在concat方法中,默认使用的是outer连接,即合并后的列取a和b的并集,缺省值为NaN。
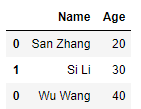
1)普通纵向连接
df1 = pd.DataFrame({
'Name':['San Zhang','Si Li'], 'Age':[20,30]})
df2 = pd.DataFrame({
'Name':['Wu Wang'], 'Age':[40]})
pd.concat([df1, df2])
2)普通横向连接
df1 = pd.DataFrame({
'Name':['San Zhang','Si Li'], 'Age':[20,30]})
df2 = pd.DataFrame({
'Grade':[80, 90]})
df3 = pd.DataFrame({
'Gender':['M', 'F']})
pd.concat([df1, df2, df3], 1)

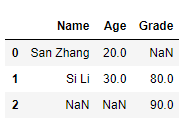
3)部分交叉横向合并
df2 = pd.DataFrame({
'Grade':[80, 90]}, index=[1, 2])
pd.concat([df1, df2], 1)
4)内部交集横向合并
pd.concat([df1, df2], axis=1, join='inner')

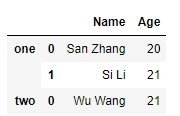
5)合并后标注行或列的来源:
df1 = pd.DataFrame({
'Name':['San Zhang','Si Li'], 'Age':[20,21]})
df2 = pd.DataFrame({
'Name':['Wu Wang'],'Age':[21]})
pd.concat([df1, df2], keys=['one', 'two'])
2.Series与DataFrame的合并
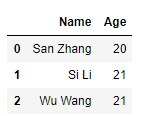
1)append方法
s = pd.Series(['Wu Wang', 21], index = df1.columns)
df1.append(s, ignore_index=True)
2)assign方法
s = pd.Series([80, 90])
df1.assign(Grade=s)
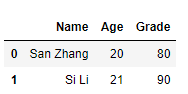
相比于 df['列名']=Series这种方式,采用assign方法不用改变原始数据。
3)另一种思路
换一种思路,可以把Series用to_frame()方法转成DataFrame再利用concat()方法进行合并,但要注意Series的index和name要与DataFrame保持一致。
三、类连接操作
1.比较
采用compare方法进行比较:
df1 = pd.DataFrame({
'Name':['San Zhang', 'Si Li', 'Wu Wang'],
'Age':[20, 21 ,21],
'Class':['one', 'two', 'three']})
df2 = pd.DataFrame({
'Name':['San Zhang', 'Li Si', 'Wu Wang'],
'Age':[20, 21 ,21],
'Class':['one', 'two', 'Three']})
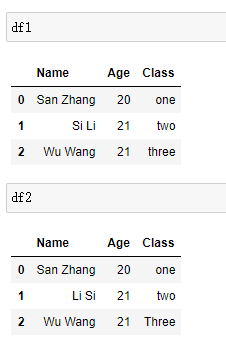

设置keep_shape参数可以显示两张表所有位置的比较结果:
df1.compare(df2, keep_shape=True)

2.组合
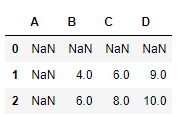
使用combine方法进行组合:
def choose_min(s1, s2):
res = s1.where(s1<s2, s2)
res = res.mask(s1.isna()) # isna表示是否为缺失值,返回布尔序列
return res
df1 = pd.DataFrame({
'A':[1,2], 'B':[3,4], 'C':[5,6]})
df2 = pd.DataFrame({
'B':[5,6], 'C':[7,8], 'D':[9,10]}, index=[1,2])
df1.combine(df2, choose_min)

练一练02
题目:请在上述代码的基础上修改,保留df2中4个未被df1替换的相应位置原始值。
df1.combine(df2, lambda s1,s2:s1.where(s1<s2, s2))
思路:只需要把res = res.mask(s1.isna())这句代码去掉即可,它的作用是严格小于而不是NaN和一个值去比较,而且在s1列不存在时,不展示s2列。
保留原表独有的列:
def choose_min(s1, s2):
res = s1.where(s1<s2, s2)
res = res.mask(s1.isna())
return res
df1.combine(df2, choose_min,overwrite=False)
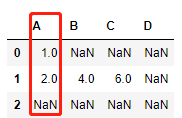
练一练03
题目:除了combine之外,pandas中还有一个combine_first方法,其功能是在对两张表组合时,若第二张表中的值在第一张表中对应索引位置的值不是缺失状态,那么就使用第一张表的值填充。下面给出一个例子,请用combine函数完成相同的功能。
df1 = pd.DataFrame({
'A':[1,2], 'B':[3,np.nan]})
df2 = pd.DataFrame({
'A':[5,6], 'B':[7,8]}, index=[1,2])
df1.combine_first(df2)
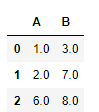
df1.combine(df2,lambda s1,s2:s1.where(~s1.isna(),s2))
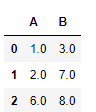
思路:~s1.isna()判断S1不为NaN的位置,然后利用where方法判别,如果为True就保留,如果为False则用s2去替换。
练习
Ex-1 美国疫情数据集

datas = []
col_names = ['Confirmed','Deaths','Recovered','Active']
for x in date:
#转换路径
single_path = 'data/us_report/'+x+'.csv'
#将文件内容读取到df中
df = pd.read_csv(single_path)
#提取目标行和列
temp = df[df.Province_State=='New York'][col_names]
#修改行索引的值
temp.rename(index={
temp.index[0]:x},inplace=True)
#放入列表中
datas.append(temp)
#拼接
res = pd.concat(datas)
res
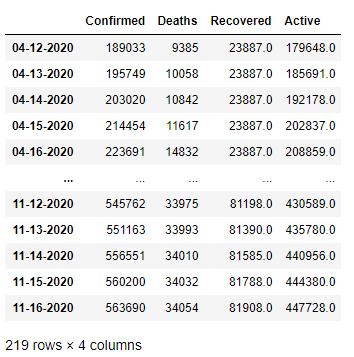
思路:遍历符合条件的每日数据,然后将指定行和列存入到Series中,同时改变它的index值。遍历结束之后利用concat方法直接合并。
Ex-2 实现join函数

单列数据采用:
df1 = pd.DataFrame({
'col1':list('01234')}, index=list('AABCD'))
df2 = pd.DataFrame({
'col2':list('opqrst')}, index=list('ABBCEE'))
版本01:
def my_join(df1,df2,how):
#将pandas.core.frame.Pandas与Series或DataFrame合并
def s_sord(a,b):
index = a.Index
data_a = a.col1
#将str和s合并 返回df
if isinstance(b,pd.Series):
b.index = [index]
b.name = df2_columns
s_a = pd.Series([data_a],index=[index],name=df1_columns)
return pd.concat([s_a.to_frame(),b.to_frame()],axis=1)
else:
#长度
size = b.shape[0]
s_a = pd.Series([data_a]*size,index=[index]*size,name=df1_columns)
return pd.concat([s_a.to_frame(),b],axis=1)
df1_columns = df1.columns[0]
df2_columns = df2.columns[0]
if how == 'left':
res = []
#循环变量是df1的每一行
for row in df1.itertuples():
index = row.Index
if index in df2.index:
res.append(s_sord(row,df2.loc[index]))
else:
res.append(s_sord(row,pd.Series([np.NaN],index=[index],name=df2_columns)))
return pd.concat(res)
my_join(df1,df2,how="left")
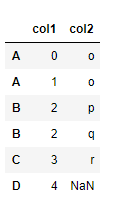
思路:遍历左侧表的行,然后根据此行的index,对应右侧表的三种情况(0、1、多)分别进行处理,然后进行不同维度的拼接,整体返回后再次进行拼接。
版本02:
def my_join(df1,df2,how):
#将Series与Series或DataFrame进行合并
def s_sord(a,b):
index = df1.index[a]
s_a = df1.iloc[a]
#将s和s合并 返回df
if isinstance(b,pd.Series):
b.index,s_a.index = [index],[index]
s_a.name,b.name = df1_columns,df2_columns
return pd.concat([s_a.to_frame(),b.to_frame()],axis=1)
#将s和df合并 返回df
else:
#长度
size = b.shape[0]
s_a = pd.Series([s_a[0]]*size,index=[index]*size,name=df1_columns)
return pd.concat([s_a.to_frame(),b],axis=1)
#获取单列
df1_columns = df1.columns[0]
df2_columns = df2.columns[0]
if how == 'left':
res = []
#循环变量是df1的每一行
for i in range(df1.shape[0]):
index = df1.index[i]
if index in df2.index:
res.append(s_sord(i,df2.loc[index]))
else:
res.append(s_sord(i,pd.Series([np.NaN],index=[index],name=df2_columns)))
return pd.concat(res)
my_join(df1,df2,how="left")

思路:考虑放弃pandas类型的数据遍历,转而采用range()方法,并且直接获取df1的行数据作为Series进行合并,而不是提取数据后再进行Series拼接。
版本03
def my_join(df1,df2,how):
#将Series与Series或DataFrame进行合并
def s_sord(s_a,b,index):
#利用.T倒置结果
if isinstance(b,pd.Series):
return pd.concat([s_a,b]).to_frame().T
#将a扩展成df
else:
#长度
size = b.shape[0]
s_a = pd.Series([s_a[0]]*size,index=[index]*size,name=df1_columns)
return pd.concat([s_a.to_frame(),b],axis=1)
#获取单列
df1_columns = df1.columns[0]
df2_columns = df2.columns[0]
#采用最开始第一节的思想,更换连接主体
if how == 'right':
return my_join(df2,df1,'left')[[df1_columns]+[df2_columns]]
#另外三种情况:
else:
res = []
#循环变量是df1的每一行
for i in range(df1.shape[0]):
index = df1.index[i]
if index in df2.index:
res.append(s_sord(df1.iloc[i],df2.loc[index],index))
else:
if how != 'inner':
res.append(s_sord(df1.iloc[i],pd.Series([np.NaN],index=[df2_columns],name=index),index))
if how == 'outer':
for i in range(df2.shape[0]):
index = df2.index[i]
if index not in df1.index:
res.append(s_sord(pd.Series([np.NaN],index=[df1_columns],name=index),df2.iloc[i],index))
return pd.concat(res)
>>> for x in ['left','right','inner','outer']:
>>> print(my_join(df1,df2,how=x).equals(df1.join(df2,how=x)))
True
True
True
True
思路:扩充到四种情况,仍以两张单列df为例进行测试,考虑到right与left实现思路一致,只需更换连接主体。如下图不同颜色代表以行索引为标志的划分区域,区域一代表两表共有,区域二表示表1独有,区域三表示表2独有。那么问题就转换成了:
- inner = 区域一
- left = 区域一+区域二
- right = 区域一+区域三
- outer = 区域一+区域二+区域三
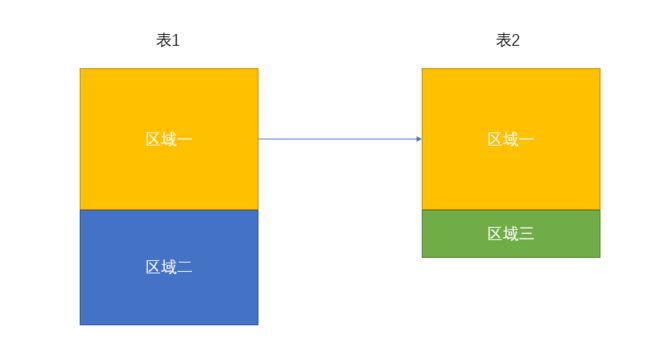
相应地,在实际代码中可以利用单过程实现inner-left-outer,只需额外在区域间的操作加上流程控制语句即可。
版本04(实现多列合并)
def my_join(df1,df2,how):
#将Series与Series或DataFrame进行合并
def s_sord(s_a,b,index):
#利用.T倒置结果
if isinstance(b,pd.Series):
return pd.concat([s_a,b]).to_frame().T
else:
return pd.concat([pd.DataFrame([s_a]*b.shape[0]),b],axis=1)
#创建指定index和name的值为NaN的Series 需要判断长度
def produceNanSer(index,name):
return pd.Series([np.NaN]*index.shape[0],index=index,name=name)
#采用最开始第一节个人的想法,更换连接主体,递归调用自己的left方法
if how == 'right':
return my_join(df2,df1,'left')[list(df1.columns)+list(df2.columns)]
#另外三种情况:
else:
res = []
#遍历df1的每一行 根据index右表对应行数有三种情况 分别为0,1,n
for i in range(df1.shape[0]):
index = df1.index[i]
#1,n的情况
if index in df2.index:
res.append(s_sord(df1.iloc[i],df2.loc[index],index))
#0的情况
else:
#此时how为inner时已经完成操作 不是则还须将左表独有的行加入
if how != 'inner':
res.append(s_sord(df1.iloc[i],produceNanSer(df2.columns,index),index))
#此时how为left时已经完成操作 outer则还须将右表独有的行加入
if how == 'outer':
for i in range(df2.shape[0]):
index = df2.index[i]
if index not in df1.index:
res.append(s_sord(produceNanSer(df1.columns,index),df2.iloc[i],index))
return pd.concat(res).reset_index().sort_values('index').set_index('index')
测试:
>>> df3 = pd.DataFrame({
'col1':list('01234'),'col3':list('一二三四五')}, index=list('AABCD'))
>>> df4 = pd.DataFrame({
'col2':list('43210'),'col4':list('五四三二一')}, index=list('AABCD'))
>>> for x in ['left','right','inner','outer']:
>>> print(my_join(df1,df2,how=x).equals(df1.join(df2,how=x)))
>>> print(my_join(df3,df4,how=x).equals(df3.join(df4,how=x)))
>>> print('-------')
True
True
-------
True
True
-------
True
True
-------
True
True
-------
思路:将s_sord方法中的条件分支进行修改,直接在b不为Series时将a重复填充为DataFrame,使其满足多列情况。
注:为了满足程序健壮性,加上了与原始join方法进行对齐的排序操作。
最终版(解决了2个健壮性的问题)
def my_join3(df1,df2,how):
#将Series与Series或DataFrame进行合并
def s_sord(s_a,b,index):
#利用.T倒置结果
if isinstance(b,pd.Series):
return pd.concat([s_a,b]).to_frame().T
else:
return pd.concat([pd.DataFrame([s_a]*b.shape[0]),b],axis=1)
#创建指定index和name的值为NaN的Series 需要判断长度
def produceNanSer(index,name):
return pd.Series([np.NaN]*index.shape[0],index=index,name=name)
def convert(df):
#存入所有列的类型
df1_dtypes = dict(df1.dtypes)
df2_dtypes = dict(df2.dtypes)
df1_dtypes.update(df2_dtypes)
#将有nan的数字列转成float64类型,将其他列与之前的列保持一致
def convertSingleCol(x):
judgeList = x.isna()
for item,judge in zip(x,judgeList):
if isinstance (item,(int,float,complex)) & ~judge & np.any(judgeList):
return x.values.astype('float64')
return x.values.astype(df1_dtypes[x.name])
return df.apply(convertSingleCol)
#采用最开始第一节个人的想法,更换连接主体,递归调用自己的left方法
if how == 'right':
return my_join(df2,df1,'left')[list(df1.columns)+list(df2.columns)]
#另外三种情况:
else:
res = []
#遍历df1的每一行 根据index右表对应行数有三种情况 分别为0,1,n
for i in range(df1.shape[0]):
index = df1.index[i]
#1,n的情况
if index in df2.index:
res.append(s_sord(df1.iloc[i],df2.loc[index],index))
#0的情况
else:
#此时how为inner时已经完成操作 不是则还须将左表独有的行加入
if how != 'inner':
res.append(s_sord(df1.iloc[i],produceNanSer(df2.columns,index),index))
#此时how为left时已经完成操作 outer则还须将右表独有的行加入
if how == 'outer':
for i in range(df2.shape[0]):
index = df2.index[i]
if index not in df1.index:
res.append(s_sord(produceNanSer(df1.columns,index),df2.iloc[i],index))
return convert(pd.concat(res).reset_index().sort_values('index').set_index('index').rename_axis(index={
'index':''}))
df1 = pd.DataFrame(columns=['Name'], data=['LiSi', 'ZhangSan', 'WangWu', 'XiaoLiu'],index=['A', 'B', 'B', 'C'])
df2 = pd.DataFrame(columns=['Grade'], data=[92, 64, 73, 80],index=['A', 'A', 'B', 'D'])
df3 = pd.DataFrame({
'col_1' : [*'123456'],
'col_2' : ['one','two','three','four','five','six']},
index = [*'abcbcd'])
df4 = pd.DataFrame({
'col_3' : [*'567890'],
'col_4' : ['いち','に','さん','よん','ご','ろく']},
index = [*'dcecfe'])
for x in ['left', 'right', 'inner', 'outer']:
print(my_join3(df1, df2, how=x).equals(df1.join(df2, how=x)))
print(my_join3(df3, df4, how=x).equals(df3.join(df4, how=x)))
print('-------')
True
True
-------
True
True
-------
True
True
-------
True
True
-------
思路:解决了两个健壮性问题,第一个是nan数量的问题,第二个是输出df列的数据类型一致问题,收获颇丰。
参考文献
1.从列表中构建DataFrame
https://www.pythonheidong.com/blog/article/338097/953a092d86a2476b7ae2/
感谢
1.大佬1指出np.NaN长度问题
https://blog.csdn.net/qq_34903176/article/details/111878670
2.大佬2指出输入输出列的数据类型要保持一致:
https://relph1119.github.io/my-team-learning/#/pandas20/task06