zookeeper集群搭建(详细步骤)
zookeeper集群搭建
一、集群规划
安装三台虚拟机,IP地址、主机名设置如下
| IP | 主机名 | 软件 |
|---|---|---|
| 192.168.1.66 | SQG | JDK\zookeeper |
| 192.168.1.2 | hadoop1 | JDK\zookeeper |
| 192.168.1.3 | hadoop2 | JDK\zookeeper |
二、环境准备(以下是三台虚拟机都需操作)
1、 关闭防火墙
[root@localhost ~]# systemctl stop firewalld //停止firewalld防火墙
[root@localhost ~]# systemctl disable firewalld //disable防火墙,让它开机不自启
[root@localhost ~]# systemctl status firewalld //查看firewalld是否已经关闭(active(running))显示防火墙处于激活状态(inactive(dead))防火墙进程处于未激活状态
2、 配置操作系统
关闭seLinux防火墙
[root@localhost ~]# vi /etc/sysconfig/selinux
SELINUX=disabled //修改成disabled
设置本机IP地址
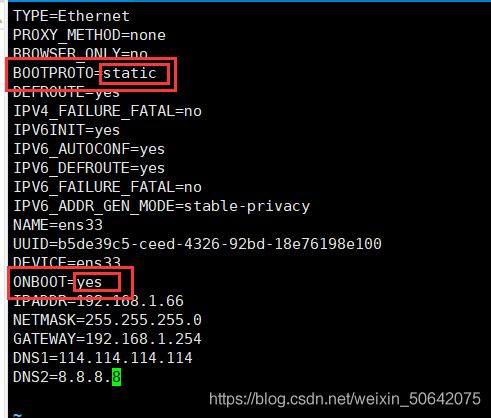
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33 (ens33是网卡名,不懂自己网卡名的tab键补齐即可)
IPADDR=192.168.1.66 //IP地址 第二台修改成192.168.1.2 第三台192.168.1.3
NETMASK=255.255.255.0 //子网掩码
GATEWAY=192.168.1.254 //网关
DNS1=8.8.8.8
DNS2=114.114.114.114
还要参数修改成静态配置static,然后把另外一个把no改成yes
设置的IP地址必须符合自己虚拟机的模式子网IP,不然会ping不通。查看方式:打开VMware,左上角有个编辑点击弹出虚拟网络编辑器,点进去弹出下图,找到自己所用的桥接还是net模式,我这里是net模式,然后子网IP是192.168.1.0,所以我可以设置IP为192.168.1.N,N可以是1-254

配完IP重启网络:service network restart
配完IP重启网络:nmcli c reload ens33 (centos8 专用)
设置主机名
[root@localhost ~]# hostnamectl set-hostname SQG 另外两台同理操作,把SQG分别改成hadoop1、hadoop2即可
[root@localhost ~]# hostname (查看主机名是否修改成功)
SQG
设置主机名与IP映射关系
三台都需操作,为了主机之间能够互通
[root@localhost ~]# vi /etc/hosts (末行添加下面内容)
192.168.1.66 SQG
192.168.1.2 hadoop1
192.168.1.3 hadoop2
三、jdk安装
1、下载jdk
可以去官网下载;也可以百度网盘下载我的这个jdk(百度网盘链接:https://pan.baidu.com/s/1a9kWhykm8Nbfy11hTrFtRQ 提取码:wko3 )
2、上传至虚拟机
去xshell官网可以免费下载xftp和xshell,别下载到付费的

用XFTP软件进行上传至虚拟机(从左边选中文件,右键点击传输即可)
3、解压安装jdk
在/usr/local/java/目录下创建java目录用于存放jdk
[root@SQG local]# mkdir java
[root@SQG ~]# tar -zxvf jdk-8u65-linux-x64.tar.gz -C /usr/local/java/ (解压在这个Java目录)
解压完成后可查看到这个

4、添加配置环境变量
[root@SQG ~]# vi /etc/profile (添加下面内容,也是jdk的路径)
#java
JAVA_HOME=/usr/local/java/jdk1.8.0_65
export PATH=$PATH:$JAVA_HOME/bin
[root@SQG ~]# source /etc/profile (使环境变量生效)
四、安装zookeeper集群
1、下载zookeeper
可以去官网下载;也可以百度网盘下载我的这个zookeeper(百度网盘链接:https://pan.baidu.com/s/1a9kWhykm8Nbfy11hTrFtRQ 提取码:wko3 )
2、上传虚拟机
跟jdk上传同理,自己有其他方法也都可以,方法不是固定的
3、解压安装zookeeper
新建一个存放的目录,我这边是/SQG_L,然后解压即可
[root@SQG ~]# tar -zxvf zookeeper-3.4.5.tar.gz -C /SQG_L/
4、添加zookeeper环境变量
[root@SQG ~]# vim /etc/profile
#zookeeper
export ZK_HOME=/SQG_L/zookeeper-3.4.5
export PATH=$PATH:$ZK_HOME/bin
[root@SQG ~]# source /etc/profile (使环境变量生效)
5、zookeeper集群配置
(1)重命名zoo_sample.cfg
[root@SQG ~]# cd /SQG_L/zookeeper-3.4.5/conf (进入conf目录)
[root@SQG conf]# cp zoo_sample.cfg zoo.cfg (将zoo_sample.cfg重命名为zoo.cfg)
(2)修改zoo.cfg文件参数
[root@SQG conf]# vim zoo.cfg
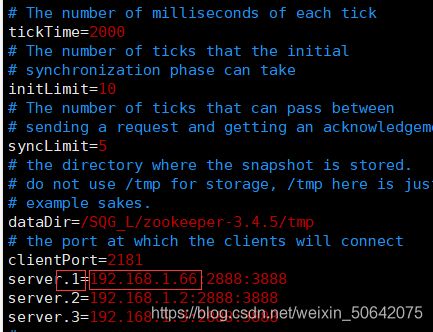
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/SQG_L/zookeeper-3.4.5/tmp
clientPort=2181
server.1=192.168.1.66:2888:3888
server.2=192.168.1.2:2888:3888
server.3=192.168.1.3:2888:3888
注:
dataDir=/SQG_L/zookeeper-3.4.5/tmp是缓存数据路径
2888为组成zookeeper服务器之间的通信端口,3888为用来选举leader的端口
三台虚拟机都需操作
(3)新建zookeeper缓存数据目录
[root@SQG zookeeper-3.4.5]# mkdir tmp (在zookeeper文件目录下新建tmp)
(4)在tmp目录下创建myid文件
[root@SQG tmp]# touch myid (新建myid文件)
[root@SQG tmp]# echo 1 > myid (文件写入数字1,也可以vim进去写入1保存退出)
后面两台同理操作
注:
这个数据必须对应zoo.cfg的配置文件,1对应的是192.168.1.66这台主机
要是数字2的话,就是要在192.168.1.2这台主机上编辑myid文件,代码为
[root@hadoop1 tmp]# echo 2 > myid
要是数字3的话,就是要在192.168.1.3这台主机上编辑myid文件,代码为
[root@hadoop2 tmp]# echo 3 > myid
五、测试zookeeper集群
1、启动zookeeper集群
[root@hadoop2 bin]# ./zkServer.sh start (在/SQG_L/zookeeper-3.4.5/bin目录下操作)

2、查看集群节点状态
[root@SQG bin]# ./zkServer.sh status



从上面的执行结果可以看出,zookeeper集群已经启动成功了。
六、出现的问题

出现这种问题的时候,
1、多检查三台虚拟机zoo.cfg配置文件是否有问题
2、检查自己myid是否写对
3、防火墙是否已关闭
4、确定是否都三台虚拟机都启动了集群
七、理论性说明
1、zookeeper原理
主要功能
协调服务,实现集群的高可用。实际生产环境的集群搭建,需要我们使用Zookeeper的协调服务(如心跳机制)来保证集群节点的高可用,并实现故障节点自动切换、数据自动迁移。
工作原理
zookeeper是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。通过选举机制来确保服务的状态的稳定性和可靠性。zookeeper集群的选举机制要求集群的节点数量为奇数个,在集群启动的时候,集群中大多数的机器得到像应开始选举,并最终选出一个节点为leader,其他节点都是follwer,然后进行数据同步。
(1)zookeeper为什么总是奇数个?
zookeeper有这样一个特性:集群中只要有超过过半的机器是正常工作的,那么整个集群对外就是可用的。
也就是说如果有2个zookeeper,那么只要有1个死了,zookeeper就不能用了,因为1没有过半,所以2个zookeeper的死亡容忍度为0;
同理,要是有3个zookeeper,一个死了,还剩2个正常的,过半了,所以3个zookeeper的容忍度为1;
同理你多列举几个:2->0 ; 3->1 ; 4->1 ; 5->2 ; 6->2。。。会发现一个规律,2n个2n-1的容忍度都是一样的,既然一样,为了更加高效何必增加那一个不必要的zookeeper呢。