datax(六)源码阅读之外部插件加载机制(reader、writer)
目录
一、插件使用方法
二、插件机制原理
三、源码走读
四、QA
一、插件使用方法
众所周知,datax通过插件机制,动态的在运行时载入reader和writer进行数据同步的执行。
站在用户侧,用户只需要做下列步骤就可以实现插件执行
1、按datax的约定实现自己的插件,并放在${DATAX_HOME}/plugin/reader/或者${DATAX_HOME}/plugin/writer/目录下,以mysqlreader为例
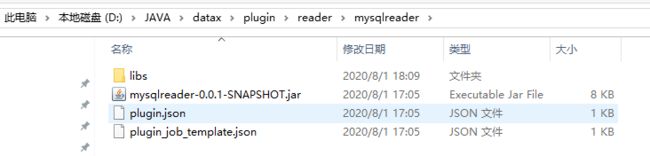
jar包就是用户实现的mysqlreader插件,libs是中放的是依赖的jar,plugin.json的话重点需要定义插件名和插件对应的全限定名,如下
{
"name": "mysqlreader",
"class": "com.alibaba.datax.plugin.reader.mysqlreader.MysqlReader",
"description": "useScene: prod. mechanism: Jdbc connection using the database, execute select sql, retrieve data from the ResultSet. warn: The more you know about the database, the less problems you encounter.",
"developer": "alibaba"
}2、编写自己要实现的datax同步json文件,引用实现的插件,如下
{
"job": {
"setting": {
"speed": {
"byte": 204800
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "remote",
"password": "hangzhoumeiri",
"column": ["`execution_push_id`", "`task_exec_id`", "`push_id`", "`create_time`", "`update_time`"],
"splitPk": "execution_push_id",
"connection": [{
"table": ["execution_push"],
"jdbcUrl": ["jdbc:mysql://xxxx:3306/gdmodeling"]
}]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print":true
}
}
}]
}
}
二、插件机制原理
这边需要知道的前置知识是jvm类加载的双亲委派模型,可以参考我的这篇文章:https://blog.csdn.net/qq_31957747/article/details/73699730
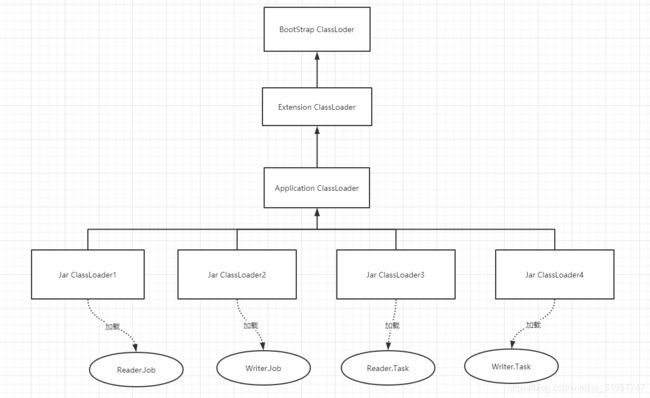
datax通过自定义类加载器JarLoader,提供Jar隔离的加载机制。
如图,JarLoader是Application ClassLoader的子类,datax通过Thread.currentThread().setContextClassLoader在每次对插件调用前后的进行classLoader的切换实现jar隔离的加载机制,具体的我们后面结合源码进行分析。
三、源码走读
下面我们把目光聚焦到JobContainer.initJobReader()方法,这个方法的作用是加载用户的Reader.Job类型,并执行Reader.Job的init()方法,如下
private Reader.Job initJobReader(
JobPluginCollector jobPluginCollector) {
// 这边获取到的就是reader的name,比如上面说的mysqlreader
this.readerPluginName = this.configuration.getString(
CoreConstant.DATAX_JOB_CONTENT_READER_NAME);
// 设置ContextClassLoader进行类加载器的切换,切换成jarLoader
classLoaderSwapper.setCurrentThreadClassLoader(LoadUtil.getJarLoader(
PluginType.READER, this.readerPluginName));
// 加载并实例化Reader.Job对象
Reader.Job jobReader = (Reader.Job) LoadUtil.loadJobPlugin(
PluginType.READER, this.readerPluginName);
// 进行jobReader需要的一些属性的赋值,并执行init()方法
jobReader.setPluginJobConf(this.configuration.getConfiguration(
CoreConstant.DATAX_JOB_CONTENT_READER_PARAMETER));
jobReader.setPeerPluginJobConf(this.configuration.getConfiguration(
CoreConstant.DATAX_JOB_CONTENT_WRITER_PARAMETER));
jobReader.setJobPluginCollector(jobPluginCollector);
jobReader.init();
// 执行完毕,将classLoader复原成Application ClassLoader
classLoaderSwapper.restoreCurrentThreadClassLoader();
return jobReader;
}我们主要关注下面几个核心方法:
1、classLoaderSwapper的setCurrentThreadClassLoader()方法和restoreCurrentThreadClassLoader()方法
2、LoadUtil的getJarLoader()方法和loadJobPlugin()方法
我们先看一下对线程的类加载器的切换的classLoaderSwapper做了哪些事情
public final class ClassLoaderSwapper {
private ClassLoader storeClassLoader = null;
private ClassLoaderSwapper() {
}
public static ClassLoaderSwapper newCurrentThreadClassLoaderSwapper() {
return new ClassLoaderSwapper();
}
/**
* 保存当前classLoader,并将当前线程的classLoader设置为所给classLoader
*
* @param
* @return
*/
public ClassLoader setCurrentThreadClassLoader(ClassLoader classLoader) {
this.storeClassLoader = Thread.currentThread().getContextClassLoader();
Thread.currentThread().setContextClassLoader(classLoader);
return this.storeClassLoader;
}
/**
* 将当前线程的类加载器设置为保存的类加载
* @return
*/
public ClassLoader restoreCurrentThreadClassLoader() {
ClassLoader classLoader = Thread.currentThread()
.getContextClassLoader();
Thread.currentThread().setContextClassLoader(this.storeClassLoader);
return classLoader;
}
}
结合上前面的代码,就很清晰了,先保存当前的classLoader也就是Application ClassLoader,然后将当前线程的classLoader切换成JarLoader,等插件加载实例化完毕,执行完对应的操作后,再切换成Application ClassLoader。
那么JarLoader是怎么获取到的呢,我们再看一下LoadUtil.getJarLoader()
// key为plugin.${pluginType}.${pluginName},比如plugin.reader.mysqlreader , value是为当前插件新创建的jarLoader
private static Map jarLoaderCenter = new HashMap();
public static synchronized JarLoader getJarLoader(PluginType pluginType,
String pluginName) {
Configuration pluginConf = getPluginConf(pluginType, pluginName);
JarLoader jarLoader = jarLoaderCenter.get(generatePluginKey(pluginType,
pluginName));
if (null == jarLoader) {
String pluginPath = pluginConf.getString("path");
if (StringUtils.isBlank(pluginPath)) {
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR,
String.format(
"%s插件[%s]路径非法!",
pluginType, pluginName));
}
jarLoader = new JarLoader(new String[]{pluginPath});
jarLoaderCenter.put(generatePluginKey(pluginType, pluginName),
jarLoader);
}
return jarLoader;
} 获取JarLoader的核心逻辑如下:
1、从本地缓存中以plugin.${pluginType}.${pluginName}为key获取JarLoader,如果获取到了就返回,获取不到就执行第二步
2、获取插件的路径,并新建一个JarLoader实例,再加入缓存
JarLoader其实就是一个继承来URLClassLoader的类,如下
public class JarLoader extends URLClassLoader {
public JarLoader(String[] paths) {
this(paths, JarLoader.class.getClassLoader());
}
public JarLoader(String[] paths, ClassLoader parent) {
super(getURLs(paths), parent);
}
private static URL[] getURLs(String[] paths) {
Validate.isTrue(null != paths && 0 != paths.length,
"jar包路径不能为空.");
List dirs = new ArrayList();
for (String path : paths) {
dirs.add(path);
JarLoader.collectDirs(path, dirs);
}
List urls = new ArrayList();
for (String path : dirs) {
urls.addAll(doGetURLs(path));
}
return urls.toArray(new URL[0]);
}
private static void collectDirs(String path, List collector) {
if (null == path || StringUtils.isBlank(path)) {
return;
}
File current = new File(path);
if (!current.exists() || !current.isDirectory()) {
return;
}
for (File child : current.listFiles()) {
if (!child.isDirectory()) {
continue;
}
collector.add(child.getAbsolutePath());
collectDirs(child.getAbsolutePath(), collector);
}
}
private static List doGetURLs(final String path) {
Validate.isTrue(!StringUtils.isBlank(path), "jar包路径不能为空.");
File jarPath = new File(path);
Validate.isTrue(jarPath.exists() && jarPath.isDirectory(),
"jar包路径必须存在且为目录.");
/* set filter */
FileFilter jarFilter = new FileFilter() {
@Override
public boolean accept(File pathname) {
return pathname.getName().endsWith(".jar");
}
};
/* iterate all jar */
File[] allJars = new File(path).listFiles(jarFilter);
List jarURLs = new ArrayList(allJars.length);
for (int i = 0; i < allJars.length; i++) {
try {
jarURLs.add(allJars[i].toURI().toURL());
} catch (Exception e) {
throw DataXException.asDataXException(
FrameworkErrorCode.PLUGIN_INIT_ERROR,
"系统加载jar包出错", e);
}
}
return jarURLs;
}
} JarLoader实现自己定制化的jar包url的搜索,而具体的类加载的能力由父类URLClassLoader提供
我们再看一下LoadUtil.loadJobPlugin()方法,他实例化了Reader.Job对象
public static AbstractJobPlugin loadJobPlugin(PluginType pluginType,
String pluginName) {
Class clazz = LoadUtil.loadPluginClass(
pluginType, pluginName, ContainerType.Job);
try {
AbstractJobPlugin jobPlugin = (AbstractJobPlugin) clazz
.newInstance();
jobPlugin.setPluginConf(getPluginConf(pluginType, pluginName));
return jobPlugin;
} catch (Exception e) {
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR,
String.format("DataX找到plugin[%s]的Job配置.",
pluginName), e);
}
}核心在于loadPluginClass()方法
private static synchronized Class loadPluginClass(
PluginType pluginType, String pluginName,
ContainerType pluginRunType) {
Configuration pluginConf = getPluginConf(pluginType, pluginName);
JarLoader jarLoader = LoadUtil.getJarLoader(pluginType, pluginName);
try {
return (Class) jarLoader
.loadClass(pluginConf.getString("class") + "$"
+ pluginRunType.value());
} catch (Exception e) {
throw DataXException.asDataXException(FrameworkErrorCode.RUNTIME_ERROR, e);
}
}可以看到通过jarLoader.loadClass()对Reader.Job的全限定名,比如com.alibaba.datax.plugin.reader.mysqlreader.MysqlReader$Job进行了加载。
我们再对插件的加载机制进行个总结:
1、获取自定义类加载器JarLoader的实例,保存当前线程的Application ClassLoader并将classLoader修改为这个JarLoader实例。
2、加载并实例化插件对象。
3、执行插件对象业务方法。
4、将当前线程的classLoader重新切换为Application ClassLoader,继续执行后续的框架逻辑。
四、QA
1、为什么每个插件需要有自己的JarLoader,通过key为plugin.${pluginType}.${pluginName}进行缓存?
答:因为要实现jar包的隔离,试想一个场景,如果我要从一个hbase集群读取数据到另一个hbase集群,而这两个hbase集群的版本号不一样,也不一定兼容,那么同一个classLoader进行加载势必会冲突。
2、为什么在加载插件类的前后需要用Thread.currentThread().setContextClassLoader()进行类加载器的切换,不做这一步会怎么样?
答:这个涉及到java的类加载机制,jvm的类加载需要遵循双亲委派模型,我们默认的应用里定义的类是由Application ClassLoader进行加载,而我们自定义实现的JarLoader是Application ClassLoader的子加载器,根据双亲委派模型,如果由Application ClassLoader进行加载的话,他会委托Extension ClassLoader进行加载,而Extension ClassLoader也会委托给BootStrap ClassLoader进行加载,最后他们都加载不到这个类又层层还给子加载器Application ClassLoader进行加载,而Application ClassLoader加载不到我们的外部插件类,又不能委派给他的子类JarLoader进行加载,因为这样会打破默认的双亲委派机制。而Thread.currentThread().setContextClassLoader()其实就是jvm为了这种场景定义的一个不是特别优雅的打破双亲委派机制的一个方式,需要用户手动进行当前线程的classLoader切换。