Python爬虫——爬取Steam热销榜游戏信息
Python 爬取Steam热销榜信息
最近学习了一下爬虫,练练手,第一次写文章,请多多包涵O(∩_∩)O
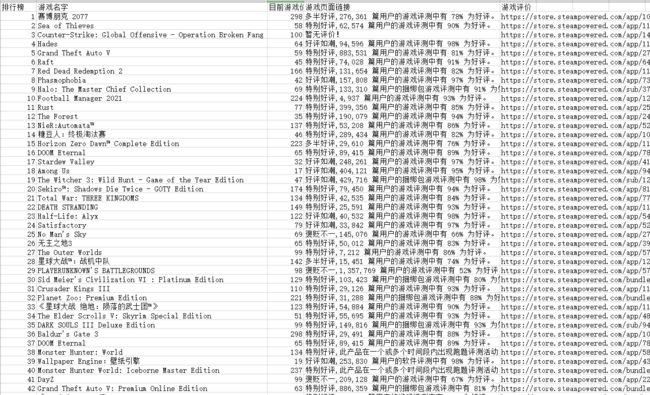
爬取Steam热销榜:游戏排名、游戏名字、价格、好评率、游戏详情页面跳转链接。
Steam热销榜爬虫
- Python 爬取Steam热销榜信息
- 一、开始爬虫前
-
- 1.引入库
- 2.读入数据
- 二、分析网页
-
- 1.首先观察价格,有两种形式,一种是原价,一种是打折后的价格
- 2.名字、游戏详情页链接
- 3.好评率
- 三、爬取信息并处理
-
- 1.游戏详情页面链接
- 2.好评率
- 3.名字、价格
- 四、信息保存
- 五、主函数
- 六、全部代码
- 七、总结
-
- 1.心情
一、开始爬虫前
1.引入库
热销榜为静态页面,所需要的库:requests,pandas,BeautifulSoup
import requests
import pandas as pd
from bs4 import BeautifulSoup
2.读入数据
headers里需要加入 ‘Accept-Language’: 'zh-CN ',不然返回来的游戏名字是英文
def get_text(url):
try:
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/85.0.4183.102 Safari/537.36', 'Accept-Language': 'zh-CN '
}
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "爬取网站失败!"
二、分析网页
热销榜链接:
https://store.steampowered.com/search/?filter=globaltopsellers&page=1&os=win
1.首先观察价格,有两种形式,一种是原价,一种是打折后的价格

(1)正常价格

(2)打折后价格,对比可发现class = “col search_discount responsive_secondrow” 是用于储存折扣的。原价为None,打折不为None,以此做为判断条件提取价格。
2.名字、游戏详情页链接
由代码可以知道:
游戏详情页链接全在 id = “search_resultsRows” 的a.href 标签里
名字在 class = “title” 里
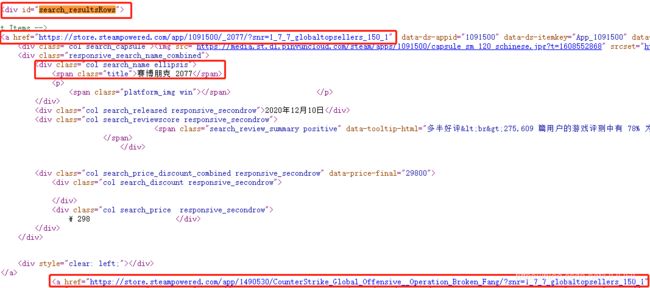
3.好评率
由图可以发现有些游戏没有评价

查看代码发现:
好评率在 class = “col search_reviewscore responsive_secondrow” 中,无评价为None


三、爬取信息并处理
1.游戏详情页面链接
提取a[‘href’] 保存到 jump_link 列表
link_text = soup.find_all("div", id="search_resultsRows")
for k in link_text:
b = k.find_all('a')
for j in b:
jump_link.append(j['href'])
2.好评率
提前好评率和评价数到 game_evaluation 列表。
u.span["data-tooltip-html"].split("
")[0] # 评价
例:多半好评
u.span["data-tooltip-html"].split("
")[-1]) # 好评率
例:276,144 篇用户的游戏评测中有 78% 为好评。
w = soup.find_all(class_="col search_reviewscore responsive_secondrow")
for u in w:
if u.span is not None: # 判断是否评价为None。
game_evaluation.append(
u.span["data-tooltip-html"].split("
")[0] + "," + u.span["data-tooltip-html"].split("
")[-1])
else:
game_evaluation.append("暂无评价!")
3.名字、价格
用strip去除多余空格,用split切割,提取其中的价格
global num 是游戏排名。
game_info 是列表,存储所有的信息。
price = z.find(class_="col search_price discounted responsive_secondrow").text.strip().split("¥")
print(price) # 切割后的打折price
print(price[2].strip()) # 需要保存的价格
结果为:
['', ' 116', ' 58']
58
global num
name_text = soup.find_all('div', class_="responsive_search_name_combined")
for z in name_text:
# 每个游戏的价格
name = z.find(class_="title").string.strip()
# 判断折扣是否为None,提取价格
if z.find(class_="col search_discount responsive_secondrow").string is None:
price = z.find(class_="col search_price discounted responsive_secondrow").text.strip().split("¥")
game_info.append([num + 1, name, price[2].strip(), game_evaluation[num], jump_link[num]])
else:
price = z.find(class_="col search_price responsive_secondrow").string.strip().split("¥")
game_info.append([num + 1, name, price[1], game_evaluation[num], jump_link[num]])
num = num + 1
四、信息保存
def save_data(game_info):
save_path = "E:/Steam.csv" # 保存路径
df = pd.DataFrame(game_info, columns=['排行榜', '游戏名字', '目前游戏价格¥', '游戏页面链接', '游戏评价'])
df.to_csv(save_path, index=0)
print("文件保存成功!")
五、主函数
一页有25个游戏,翻页链接直接在原链接后面加 &page= 第几页
想爬取多少页游戏,就把 range(1,11)的11改成多少页+1
if __name__ == "__main__":
Game_info = [] # 所有游戏信息
Turn_link = [] # 翻页链接
Jump_link = [] # 游戏详情页面链接
Game_evaluation = [] # 游戏好评率和评价
for i in range(1, 11):
Turn_link.append("https://store.steampowered.com/search/?filter=globaltopsellers&page=1&os=win" + str("&page=" + str(i)))
run(Game_info, Jump_link, Game_evaluation, get_text(Turn_link[i-1]))
save_data(Game_info)
六、全部代码
num 是排名;run 函数里要调用 BeautifulSoup 函数解析
import requests
import pandas as pd
from bs4 import BeautifulSoup
num = 0
def get_text(url):
try:
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/85.0.4183.102 Safari/537.36', 'Accept-Language': 'zh-CN '
}
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "爬取网站失败!"
def run(game_info, jump_link, game_evaluation, text):
soup = BeautifulSoup(text, "html.parser")
# 游戏评价
w = soup.find_all(class_="col search_reviewscore responsive_secondrow")
for u in w:
if u.span is not None:
game_evaluation.append(
u.span["data-tooltip-html"].split("
")[0] + "," + u.span["data-tooltip-html"].split("
")[-1])
else:
game_evaluation.append("暂无评价!")
# 游戏详情页面链接
link_text = soup.find_all("div", id="search_resultsRows")
for k in link_text:
b = k.find_all('a')
for j in b:
jump_link.append(j['href'])
# 名字和价格
global num
name_text = soup.find_all('div', class_="responsive_search_name_combined")
for z in name_text:
# 每个游戏的价格
name = z.find(class_="title").string.strip()
# 判断折扣是否为None,提取价格
if z.find(class_="col search_discount responsive_secondrow").string is None:
price = z.find(class_="col search_price discounted responsive_secondrow").text.strip().split("¥")
game_info.append([num + 1, name, price[2].strip(), game_evaluation[num], jump_link[num]])
else:
price = z.find(class_="col search_price responsive_secondrow").string.strip().split("¥")
game_info.append([num + 1, name, price[1], game_evaluation[num], jump_link[num]])
num = num + 1
def save_data(game_info):
save_path = "E:/Steam.csv"
df = pd.DataFrame(game_info, columns=['排行榜', '游戏名字', '目前游戏价格¥', '游戏评价', '游戏页面链接'])
df.to_csv(save_path, index=0)
print("文件保存成功!")
if __name__ == "__main__":
Game_info = [] # 游戏全部信息
Turn_link = [] # 翻页链接
Jump_link = [] # 游戏详情页面链接
Game_evaluation = [] # 游戏好评率和评价
for i in range(1, 11):
Turn_link.append("https://store.steampowered.com/search/?filter=globaltopsellers&page=1&os=win" + str("&page=" + str(i)))
run(Game_info, Jump_link, Game_evaluation, get_text(Turn_link[i-1]))
save_data(Game_info)
七、总结
以上就是今天要讲的内容,本文仅仅简单介绍了request 和 BeautifulSoup 的使用。突破点在于:有些页面信息的位置不同,能否找出判断条件
1.心情
初学爬虫,也是第一次写博客,对于优化和多线程目前没有太多了解,本文的代码可能有点繁琐,不过也能做到轻松爬取信息。O(∩_∩)O