python3 爬取豆瓣电影数据
步骤目录
-
-
-
-
-
- 安装相关模块
- 分析网页结构与地址
- 拼接网页地址数组
- 处理请求头以及发起请求
- 解析html
- 将得到的数组合并写入一个txt文件
- 批量下载图片
- 对比普通下载和使用线程下载
-
-
-
-
这里是根据requests以及beautifulsoup4来完成对豆瓣电影top250数据的爬取
安装相关模块
requests处理请求、beautifulsoup4解析html、lxml beautifulsoup4的依赖库、fake-useragent模拟请求
pip install requests
pip install beautifulsoup4
pip install lxml
pip3 install fake-useragent
分析网页结构与地址
第一页地址:https://movie.douban.com/top250,先从网页结构来看
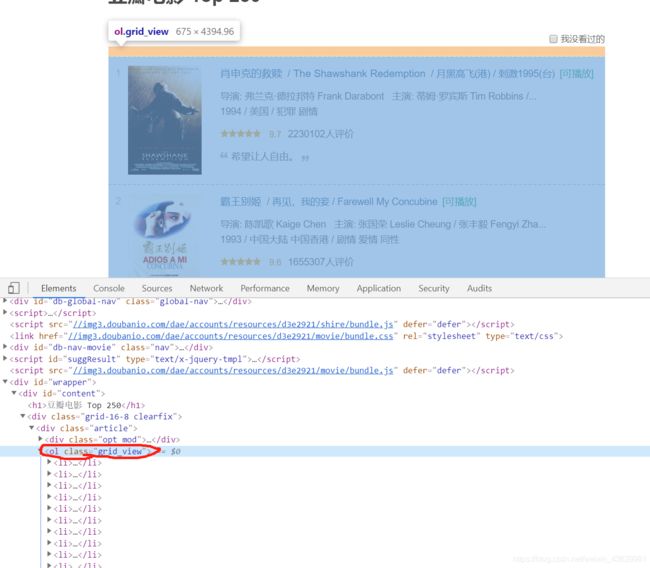
且在截图中搜索后发现grid_view仅有一个,可以以其为参照点去查找
网页地址中从第二页开始地址为https://movie.douban.com/top250?start=25&filter=,即从0开始每页25个,那么共10页
拼接网页地址数组
start_urls = ['https://movie.douban.com/top250']
for i in range(1,10):
start_urls.append(f'https://movie.douban.com/top250?start={25*i}&filter=')
print(start_urls)
输出如下:
['https://movie.douban.com/top250', 'https://movie.douban.com/top250?start=25&filter=', 'https://movie.douban.com/top250?start=50&filter=', 'https://movie.douban.com/top250?start=75&filter=', 'https://movie.douban.com/top250?start=100&filter=', 'https://movie.douban.com/top250?start=125&filter=', 'https://movie.douban.com/top250?start=150&filter=', 'https://movie.douban.com/top250?start=175&filter=', 'https://movie.douban.com/top250?start=200&filter=', 'https://movie.douban.com/top250?start=225&filter=']
处理请求头以及发起请求
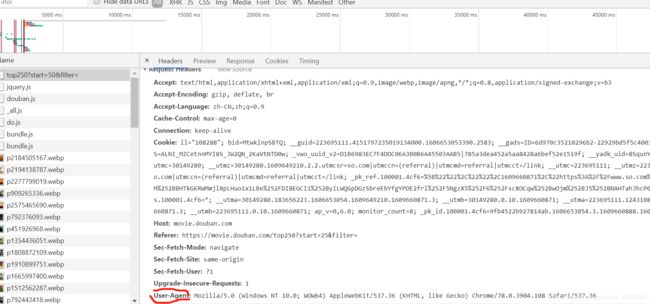
处理请求头或者说用户代理文本模仿浏览器访问
from fake_useragent import UserAgent
import requests
ua = UserAgent()
headers = {
'User-Agent': ua.chrome}
r = requests.get(url,headers=headers).content
或者直接将浏览器对应的User-Agent直接复制出来将ua.chrome替换
解析html
先找到包含内容最贴近的部分,如之前截图中的
soup = BeautifulSoup(r)
content = soup.find('ol',class_='grid_view')
print(content)
打印此处省略
- ...
def getData(url):
ua = UserAgent()
headers = {
'User-Agent': ua.chrome}
r = requests.get(url,headers=headers).content
# print(r)
soup = BeautifulSoup(r,features="lxml")
content = soup.find('ol',class_='grid_view') #最贴近的ol标签
liList = content.find_all('li')#找到单个的li标签数组
data = []
for item in liList:
d1 = {
}
img = item.find('img')
d1["img"] = img['src']
d1["title"] = img['alt']
info = item.find('div',class_='bd').find('p').get_text()
d1["info"] = re.sub(r'\s',"",re.sub(r'\xa0',"",info))
d1["rating_num"] = item.find('span',class_='rating_num').get_text()
data.append(d1)
# print(data)
return data
将得到的数组合并写入一个txt文件
文件写入时指定encoding解决中文乱码问题
json.dumps()为了避免中文乱码问题,因此在参数中加入ensure_ascii=False;
data = []
for i in range(0,10):
# start_urls.append(f'https://movie.douban.com/top250?start={25*i}&filter=')
st = f'https://movie.douban.com/top250?start={25*i}&filter='
data.extend(getData(st))
file = open(f"{downloadpath}/data.json",'w',encoding='utf-8')
file.write(json.dumps(data,ensure_ascii=False))
file.close()
批量下载图片
同样的解析方式,不过下载图片相对数据少了几个标签处理
def download_pic(url):
ua = UserAgent()
headers = {
'User-Agent': ua.chrome}
r = requests.get(url,headers=headers).content
# print(r)
soup = BeautifulSoup(r,features="lxml")
content = soup.find('ol',class_='grid_view') #最贴近的ol标签
images = content.find_all('img')
for img in images:
name = img['alt']
html = requests.get(img['src'],headers=headers)
with open(f'{downloadpath}/{name}.jpg','wb') as f:#wd 二进制格式写入文件
f.write(html.content)
print(f"{name}.jpg下载完成")
对比普通下载和使用线程下载
先普通下载:
start_urls = ['https://movie.douban.com/top250']
for i in range(1,10):
start_urls.append(f'https://movie.douban.com/top250?start={25*i}&filter=')
# 开始时间
start_time = time.time()
for url in start_urls:
download_pic(url)
# 结束时间
end_time = time.time()
print(f'下载执行时间:{end_time-start_time}')
输出结果:
下载执行时间:36.174914836883545
而使用线程之后的下载时间,代码如下:
from concurrent.futures import ThreadPoolExecutor,wait,ALL_COMPLETED
import time
start_time = time.time()
with ThreadPoolExecutor(max_workers=10) as executor:
tasks = []
for url in start_urls:
task = executor.submit(download_pic,url)
tasks.append(task)
wait(tasks,return_when=ALL_COMPLETED)
end_time = time.time()
print(f'下载执行时间:{end_time-start_time}')
输出结果如下:
下载执行时间:5.680005788803101