Slony-I 文摘
http://www.onlamp.com/pub/a/onlamp/2004/11/18/slony.html
我特别喜欢这篇文章,就进行了转载和翻译。
Introducing Slony
Slony is the Russian plural for elephant. It is also the name of the new replication project being developed by Jan Weick. The mascot for Slony, Slon, is a good variation of the usual Postgres elephant mascot, created by Jan.
Slony是俄罗斯语中对大象的复数描述。这也是由Jan Weick所开发的复制项目的名称。他所开发的Slony系统,其吉祥物--Slon,正是通常的PostgreSQL的吉祥物的变种。
Slony-I, the first iteration of the project, is an asynchronous replicator of a single master database to multiple replicas, which in turn may have cascaded replicas. It will include all features required to replicate large databases with a reasonable number of replicas. Jan has targeted Slony-I toward data centers and backup sites, implying that all nodes in the network are always available. 该项目的第一代迭代,Slony-I,是一种单master数据库到多复制节点异步复制的解决方案,复制节点之间可以进行级联复制。它也包括了复制大型数据库到若干复制节点的所有功能。Jan设定的目标是针对数据红心和备份站点,假定前提是在网络做中所有节点都可以通达。
The master is the primary database with which the applications interact. Replicas are replications, or copies of the primary database. Since the master database is always changing, data replication is the system that enables the updates of secondary, or replica, databases as the master database updates. In synchronous replication systems, the master and the replica are consistent exact copies. The client does not receive a commit until all replicas have the transaction in question. Asynchronous replication loosens that binding and allows the replica to copy transactions from the master, rolling forward, at its own pace. The server issues a commit to the master client based on the state of the master database transaction.
master阶段是主要的数据库,应用主要和它进行交互。复制节点完成复制任务,可以看作是对主数据库的拷贝。由于master节点数据库总是在发生变化,故数据复制就是能够在master节点数据库发生变化的时候,使复制节点也发生变化的体系。在同步复制系统中,master节点和复制节点是完全一致的,直到所有的复制节点都提交,master节点才会真正提交。而异步复制方式中双方的绑定不会这么紧,它允许复制节点从master节点拷贝数据,按照自己的实际运行速度进行前滚。服务器只是根据master数据库的事务状况进行提交。
Cascading replicas over a WAN minimizes bandwidth, enabling better scalability and also enables read-only (for example, reporting) applications to take advantage of replicas.
它提供了更好的灵活性,可以节约带宽,并且能够支持只读型应用从复制中获益。
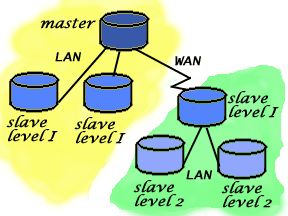
Assume you have a primary site, with a database server and a replica as backup server. Then you create a remote backup center with its own main server and its backup replica. The remote primary server is a direct replica, replicating from the master over the WAN, while the remote secondary server is a cascaded replica, replicating from the primary server via the LAN. This avoids transferring all of the transactions twice over the WAN. More importantly, this configuration enables you to have a remote backup with its own local failover already in place for cases such as a data center failure.
假设你有一个主节点,其中有一个数据库服务器,另外还有一个复制节点,运行一个备份数据库。然后你创建一个远端备份中心,带有自己的主服务器和备份复制节点。此远端的主服务器是跨越WAN对主服务器的复制,远端从服务器是一个级联复制节点,通过LAN实现对其主服务器的复制。这种方式避免了在WAN上传递所有的事务两次。更为重要的是,这种方式允许你对远端备份节点拥有自己的failover机制以应对数据中心的崩溃。
Slony's design goals differentiate it from other replication systems. The initial plan was to enable a few very important key features as a basis for implementing these design goals. An underlying theme to the design is to update only that which changes, enabling scalable replication for a reliable failover strategy.
Slony的设计目标与其他的复制系统不同。最初的计划是允许几个重要的核心功能来作为实现这些设计目标的基础。背后隐藏的想法是只改变那些变化的,允许一种灵活的可信赖的failover策略。
The design goals for Slony are: Slony的设计目标是:
-
The ability to install, configure, and create a replica and let it join and catch up with a running database.可以安装、配置、创建一个复制节点,让它来保持跟踪运行中的数据库内容。
This allows the replacement of both masters and replicas. This idea also enables cascading replicas, which in turn adds scalability, limitation of bandwidth, and proper handling of failover situations.
-
Allowing any node to take over for any other node that fails. 允许任何一个节点接替其它的失败节点。
In the case of a failure of a replica that provides data to other replicas, the other replicas can continue to replicate from another replica or directly from the master.
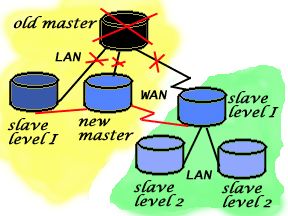
In the case where a master node fails, a replica can receive a promotion to become a master. Any other replicas can then replicate from the new master. Because Slony-I is asynchronous, the different replicas may be ahead of or behind each other. When a replica becomes a master, it synchronizes itself with the state of the most recent other replica.
当一个master节点失败的时候,一个复制节点可以接受一个提升从而变成master。任何其他的复制节点都可以从这个新master节点来复制。因为Slony-I是异步的,不同的复制节点可能相互之间有的新有的旧。当一个复制节点成为了master节点,它就会找到那个最新的复制节点来同步自己。
In other replication solutions, this roll forward of the new master is not possible. In those solutions, when promoting a replica to master, any other replicas that exist must rebuild from scratch in order to synchronize with the new master correctly. A failover of a 1TB database leaves the new master with no failover of its own for quite a while.
在其他的复制解决方案中,这种前滚方式是不可能的。在那些方案中,如果提升一个复制节点成为master节点,任何其他的复制节点必须从头开始重建以保持和新的master节点正确地同步。一个1TB的数据库的failover会使得其master节点等待有一段时间无法进行应对新的failover事件。
The Slony design handles the case where multiple replicas may be at different synchronization times with the master and are able to resynchronize when a new master arises. For example, different replicas could logically be in the future, compared to the new master. There is a way to detect and correct this. If there weren't, you would have to dump and restore the other replicas from the new master to synchronize again.
Slony的实际使得其可以处理多个复制节点位于与master节点间不同的同步阶段的场景,当一个新的master产生的时候,也可以再次同步。例如,在逻辑上,与新的master节点相比,不同的复制节点可以处于未来时间段。这是有办法检测和修正的。如果没有,你就不得不使用 dump 和 restore 的方式来和新的master节点间建立同步了。
It's possible to roll forward the new master, if necessary, from other replicas because of the packaging and saving of the replication transactions. Replication data is packaged into blocks of transactions and sent to each replica. Each replica knows what blocks it has consumed. Each replica can also pass those blocks along to other servers--this is the mechanism of cascading replicas. A new master may be on transaction block 17 relative to the old master, when another replica is on transaction block 20 relative to the old master. Switching to the new master causes the other replicas to send blocks 18, 19, and 20 to the new master.
如果有必要,把新的master节点前滚也是可能的,那是因为对复制事务的打包后保存能够发挥作用。复制数据被包装为事务块,然后送达各个复制节点。每一个复制节点都知道它自己消耗了哪些事务块。每一个复制节点也能把这些事务快传送给其他的服务器--这就是复制节点级联的机制。一个新的master节点可能处于相对于旧master节点的第17个事务块上,而另一个复制节点处于相对于旧master节点的第20个事务块上。切换到新的master节点会使得其他的复制节点传送第18,19,20个事务块给新的master节点。
Jan, said, "This feature took me a while to develop, even in theory."
Jan曾经说,这个功能我花了颇多的时间去开发,包括在理论设想阶段也是如此。
-
Backup and point-in-time capability with a twist. 备份以及快速按时间点恢复的能力。
It is possible, with some scripting, to maintain a delayed replica as a backup that might, for example, be two hours behind the master. This is done by storing and delaying the application of the transaction blocks. With this technique, it is possible to do a point-in-time recovery anytime within the last two hours on this replica. The time it takes to recover only depends on the time to which you choose to recover. Choosing "45 minutes ago" would take about one hour and 15 minutes, for example, independent of database size. 借助于一些脚本,可以实现保持一个延迟的备份,例如,这个备份比master延迟两个小时。这是通过存储和推迟transaction block来实现的。通过这种方式,可以在复制节点上实现两个小时以内的、任意时间点的 point-in-time恢复。恢复所需花费的时间仅仅是依赖于你想要恢复到那个时间点。选择恢复到45分钟前大概可能需要花费一个小时又15分钟左右,这和数据库大小基本无关。
-
Hot PostgreSQL installation and configuration. PostgreSQL热安装与配置
For failover, it must be possible to put a new master into place and reconfigure the system to allow the reassignment of any replica to the master or to cascade from another replica. All of this must be possible without taking down the system.所谓failover,必须是能够投入新的master节点,或配置使得可以重新把任何一个复制节点变成master节点,或者任何节点都可以从其他复制节点开始级联。所有这些在执行的时候,必须是不能关闭整个系统。
This means that it must be possible to add and synchronize a new replica without disrupting the master. When the new replica is in place, the master switch can happen. 这意味着必须可以在不导致master节点崩溃的情况下加入新的复制节点并进行同步化。然后新的复制节点到位,master节点的切换就可以开始了。
This is particularly useful when the new replica is a different PostgreSQL version than the previous one. If you create an 8.0 replica from your 7.4 master, it now is possible to promote the 8.0 to master as a hot upgrade to the new version.
如果新加入的复制节点是一个不同的PostgreSQL版本,那么这是很有用的功能。如果从7.4版本的master节点你创建了一个8.0版本的复制节点,今后把8.0版本节点提升为master节点的方式来完成一个"热变更"是可行的。
-
Schema changes. 反映Schema变化
Schema changes require special consideration. The bundling of the replication transactions must be able to join all of the pertinent schema changes together, whether or not they took place in the same transaction. Identifying these change sets is very difficult. Schema的变更值得特殊考虑。复制事务必须能够把所有的Schema变更合并到一起,无论其是否在同一个事务里完成的。标记出这些变更集合是很困难的。
In order to address this issue, Slony-I has a way to execute SQL scripts in a controlled fashion. This means that it is even more important to bundle and save your schema changes in scripts. Tracking your schema changes in scripts is a key DBA procedure for keeping your system in order and your database recreatable.
为了解决这个问题,Slony-I有一个在可控方式下执行SQL脚本的方式。这意味着把你的scheam变更保存在脚本中并打包是异常重要的。在脚本中跟中你的模式变更是一个核心的DBA过程,由此而保持你的系统有序,数据库可以再创建。
The first part of Slony-I also does not address any of the user interface features required to set up and configure the system. After the core engine of Slony-I becomes available, development of the configuration and maintenance interface can begin. There may be multiple interfaces available, depending on who develops the user interface and how.在此我并没有提及任何与用户界面相关的功能,当Slony-I的核心引擎得以实现之后,对配置文件以及维护所用的界面的开发可以开始了。可以有多个界面,这要看是谁以及如何开发用户界面。
Jan points out that "replication will never be something where you type SETUP and all of a sudden your existing enterprise system will nicely replicate in a disaster recovery scenario." Designing how to set up your replication is a complex problem. Jan指出复制永远不肯能是那种你输入了SETUP然后突然之间你的系统就可以在危机保护场景里很完美地执行复制了的东西。设计如何完成你的复制,是一个复杂的挑战。
The user interface(s) will be important to clarify and simplify the configuration and maintenance of your replication system. Some of the issues to address include the configuration of which tables to replicate, the requirement of primary keys, and the handling of sequence and trigger coordination. 对于理清和简化对你的复制系统的配置而言,用户界面将是很重要的。这包括配置那些表需要被复制,对主键的需要,以及对序列和触发器的处理。
The Slony-I release does not address the issues of multi-master, synchronous replication or sporadically synchronizable nodes (the "sales person on the road" scenario). However, Jan is considering these issues in the architecture of the system so that future Slony releases may implement some of them. It is critical to design future features into the system; analysis of existing replication systems has shown that it is next to impossible to add fundamental features to an existing replication system. Slony-I 没有触及多master问题,同步复制或者零星的同步节点(例如在路上的销售员场景)。但是Jan正在架构中考虑这些问题,因此也许未来的发布中会实现一部分。设计时考虑到未来的功能是很重要的;对既存复制系统的分析表明追加基础性的功能到一个已经存在的复制系统中是几乎不可能的。
The primary question to ask regarding the requirements for a failover system is how much down time can you afford. Is five minutes acceptable? Is one hour? Must the failover be read/write, or is it acceptable to have a read-only temporary failover? The second question you must ask is whether you are willing to invest in the hardware required to support multiple copies of your database. A clear cost/benefit analysis is necessary, especially for large databases. 考察一个failover系统时应当问的一个主要问题是,你能承受多久的系统不在线时间。是5分钟,还是1个小时?是后备机必须可写可读,还是说可以临时保持只读?第二个问题是你要问自己是否愿意投入硬件来保证对数据库的多份拷贝。一个清晰的投入产出分析是必要的,特别是对大型数据库而言。