大数据导论复习笔记
文章目录
-
- 大数据导论
-
- 第1章 大数据概述
-
- 数据类型、数据组织形式、数据的使用
-
- 数据类型
- 数据组织形式
- 数据的使用
- 大数据的概念(4V)
- 科学研究四种范式
- 第2章 大数据与云计算、物联网、人工智能
-
- 云计算概念、云计算服务模式和类型
-
- 五个特征
- 四个部署模型
- 服务模式
- 大数据系统与云安全、云安全及其关键技术
- 物联网概念、物联网三要素、物联网层次架构
- 大数据与云计算、物联网的关系
- 人工智能概念、人工智能关键技术
- 大数据与人工智能的关系
- 第3章 大数据技术
-
- 大数据技术的不同层面及其功能
- 传统的数据采集与大数据采集的区别
- 互联网爬虫基本架构、爬取策略
- ETL概念
- 数据清洗的主要内容
- 大数据时代的数据存储和管理技术
- 数据挖掘和机器学习算法、深度学习概念和应用领域
- 大数据处理分析技术类型及解决的主要问题
- 数据可视化概念
- 数据安全技术
- 第4、5、6章 大数据应用、大数据安全、大数据思维
-
- 推荐系统、推荐方法、推荐系统
- 大数据应用领域
- 大数据安全与传统数据安全的不同
- 大数据思维方式
- 第9章 Hadoop、HDFS、MapReduce、Hive、Spark简介
-
- Hadoop的特性、项目结构
- HDFS相关概念、体系结构、数据存取策略、数据错误与恢复
-
- 相关概念
- HDFS体系结构
- 数据存取策略
- 数据错误与恢复
- HDFS如何减轻名称节点的负担
- MapReduce相较于传统并行计算框架的优势
- MapReduce体系结构、应用程序执行过程
-
- 体系结构
- MapReduce应用程序执行过程
- 数据仓库概念、 Hive特点
- Hive与Hadoop生态系统中其他组件的关系
- Spark特点、Spark基本概念
- Spark与Hadoop的对比、Spark RDD
-
- Spark RDD
大数据导论
第1章 大数据概述
数据类型、数据组织形式、数据的使用
数据类型
| 类型 | 含义 | 本质 | 举例 | 技术 |
|---|---|---|---|---|
| 结构化数据 | 直接可以用传统关系数据库存储和管理的数据 | 先有结构,后有管理 | 数字、符号、表格 | SQL |
| 非结构化数据 | 无法用传统关系数据库存储和管理的数据 | 难以发现同一的结构 | 语音、图像、文本 | NoSQL,NewSQL,云技术 |
| 半结构化数据 | 经过转换用传统关系数据库存储和管理的数据 | 先有数据,后有结构 | HTML、XML | RDF、OWL |
数据组织形式
计算机系统中的数据组织形式主要有两种,即文件和数据库。
-
文件:计算机系统中的很多数据都是以文件形式存在的,比如一个WORD文件、一个文本文件、一个网页文件、一个图片文件等等。
-
数据库:计算机系统中另一种非常重要的数据组织形式就是数据库,数据库已经成为计算机软件开发的基础和核心。
数据的使用
-
数据清洗
-
数据管理
-
数据分析
-
信息化浪潮、信息科技为大数据时代提供技术支撑
- 存储设备容量不断增加
- CPU处理能力大幅提升
- 网络带宽不断增加
大数据的概念(4V)

科学研究四种范式
-
实验
-
理论
-
计算
-
数据
第2章 大数据与云计算、物联网、人工智能
云计算概念、云计算服务模式和类型
五个特征
-
宽带接入
-
弹性架构
-
可测量服务
-
按需自服务
-
虚拟化的资源池
四个部署模型
-
公有云
-
私有云
-
混合云
-
社区云
服务模式
IaaS(Infrastructure as a Service):基础设施级服务。消费者通过因特网可以从完善的计算机基础设施获得服务。
IaaS通过网络向用户提供计算机(物理机和虚拟机)、存储空间、网络连接、负载均衡和防火墙等基本计算资源;用户在此基础上部署和运行各种软件,包括操作系统和应用程序。例如,通过亚马逊的AWS,用户可以按需定制所要的虚拟主机和块存储等,在线配置和管理这些资源。
PaaS(Platform as a Service):平台级服务。PaaS实际上是指将软件研发的平台作为一种服务,以SaaS的模式提交给用户。因此,PaaS也是SaaS模式的一种应用。但是,PaaS的出现可以加快SaaS的发展,尤其是加快SaaS应用的开发速度。
平台通常包括操作系统、编程语言的运行环境、数据库和 Web服务器,用户在此平台上部署和运行自己的应用。用户不能管理和控制底层的基础设施,只能控制自己部署的应用。目前常见的PaaS提供商有CloudFoundry、谷歌的GAE等。
SaaS(Software as a Service):软件级服务。它是一种通过因特网提供软件的模式,用户无需购买软件,而是向提供商租用基于Web的软件,来管理企业经营活动,例如邮件服务、数据处理服务、财务管理服务等
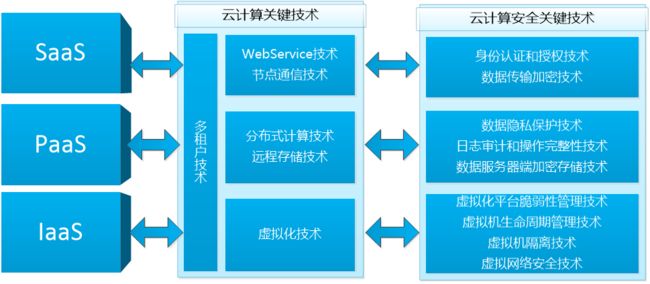
大数据系统与云安全、云安全及其关键技术
-
认证授权问题
-
访问控制问题
-
操作审计问题
-
敏感数据保护问题
-
认证授权问题
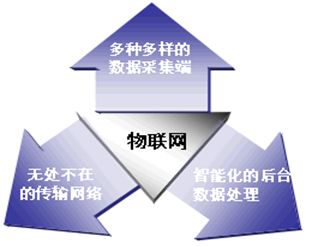
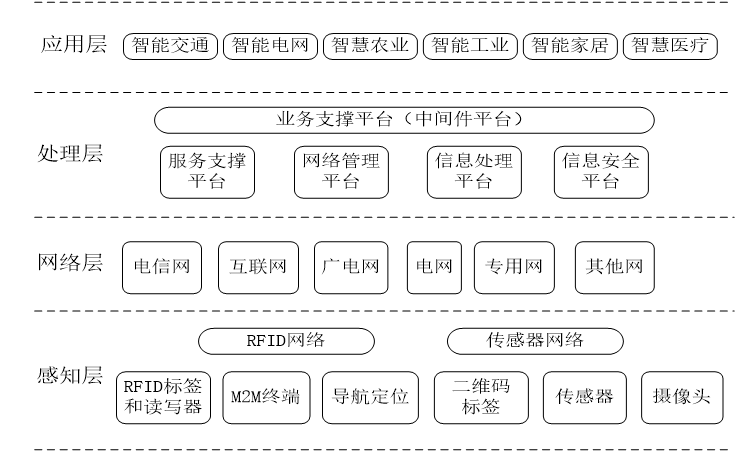
物联网概念、物联网三要素、物联网层次架构
大数据与云计算、物联网的关系

人工智能概念、人工智能关键技术
人工智能(Artificial Intelligence),英文缩写为AI,是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。
关键技术:机器学习、专家系统、知识图谱、计算机视觉、自然语言处理、生物特征识别、人机交互、VR/AR、模式识别
大数据与人工智能的关系
- 人工智能需要数据来建立其智能,特别是机器学习
- 大数据技术为人工智能提供了强大的存储能力和计算能力
第3章 大数据技术
大数据技术的不同层面及其功能

传统的数据采集与大数据采集的区别

互联网爬虫基本架构、爬取策略
- 将这些URL放入待抓取URL队列;
- 读取URL,Download对应页面;
- 解析页面,嗅探新的URL去重加入队列;
- Goto step 3
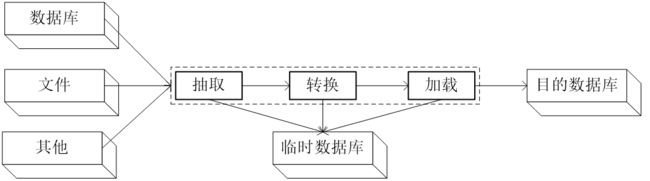
ETL概念
ETL(Extract、Transform、load)
ETL是数据获取的重要手段,需要知道具体格式
数据清洗的主要内容

大数据时代的数据存储和管理技术
- 分布式文件系统
- NewSQL和NoSQL数据库
数据挖掘和机器学习算法、深度学习概念和应用领域
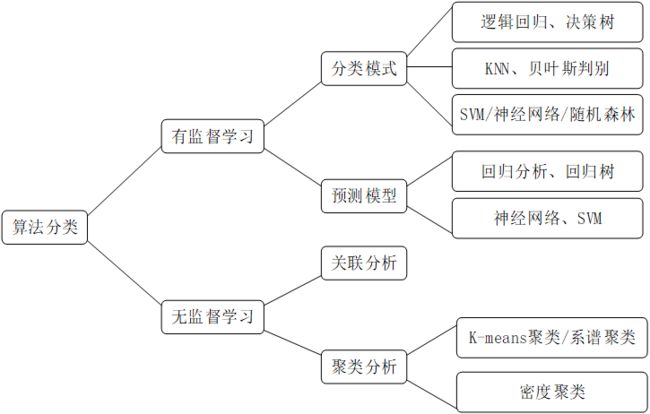
大数据处理分析技术类型及解决的主要问题
| 大数据计算模式 | 解决问题 | 代表产品 |
|---|---|---|
| 批处理计算 | 针对大规模数据的批量处理 | MapReduce、Spark等 |
| 流计算 | 针对流数据的实时计算 | Storm、S4、Flume、Streams、Puma、DStream、Super Mario、银河流数据处理平台等 |
| 图计算 | 针对大规模图结构数据的处理 | Pregel、GraphX、Giraph、PowerGraph、Hama、GoldenOrb等 |
| 查询分析计算 | 大规模数据的存储管理和查询分析 | Dremel、Hive、Cassandra、Impala等 |
数据可视化概念
数据可视化是指将大型数据集中的数据以图形图像形式表示,并利用数据分析和开发工具发现其中未知信息的处理过程
数据安全技术
- 身份认证技术
- 防火墙技术
- 访问控制技术
- 入侵检测技术
- 加密技术
第4、5、6章 大数据应用、大数据安全、大数据思维
推荐系统、推荐方法、推荐系统
推荐系统是自动联系用户和物品的一种工具,和搜索引擎相比,推荐系统通过研究用户的兴趣偏好,进行个性化计算。推荐系统可发现用户的兴趣点,帮助用户从海量信息中去发掘自己潜在的需求。
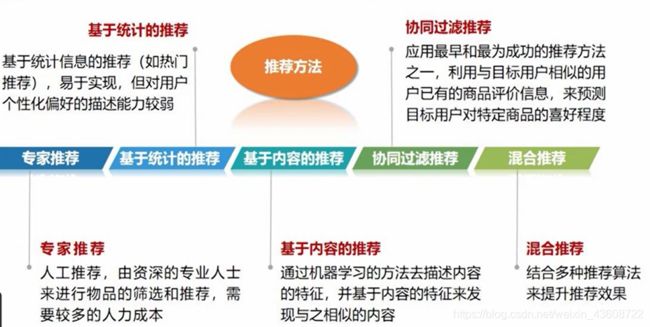
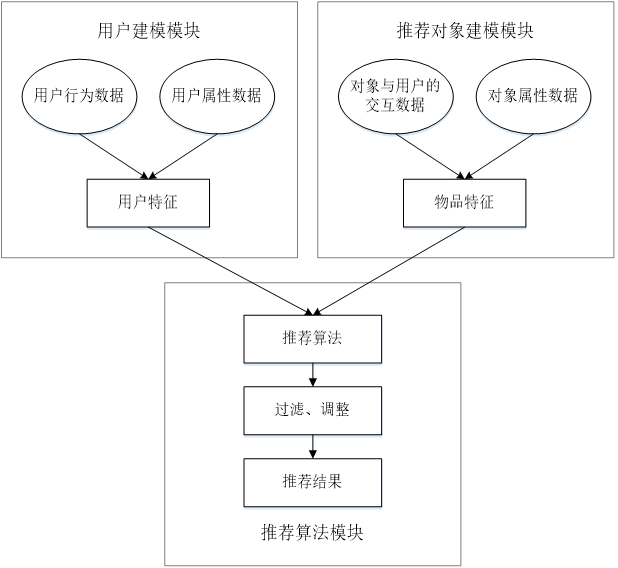
大数据应用领域
- 互联网领域
- 生物医学领域
- 物流领域
- 城市管理领域
- 金融领域
- 汽车领域
- 零售领域
- 餐饮领域
- 电信领域
- 能源领域
- 体育和娱乐领域
- 安全领域
- 政府领域
大数据安全与传统数据安全的不同
- 大数据成为网络攻击的显著目标
- 大数据加大隐私泄露风险
- 大数据技术被应用到攻击手段中
- 大数据成为高级可持续攻击(APT)的载体
大数据思维方式
- 全样而非抽样
- 效率而非精确
- 相关而非因果
- 以数据为中心
- 我为人人,人人为我
第9章 Hadoop、HDFS、MapReduce、Hive、Spark简介
Hadoop的特性、项目结构
特性:
- 高可靠性
- 高效性
- 高可扩展性
- 高容错性
- 成本低
- 运行在Linux平台上
- 支持多种编程语言
项目结构:
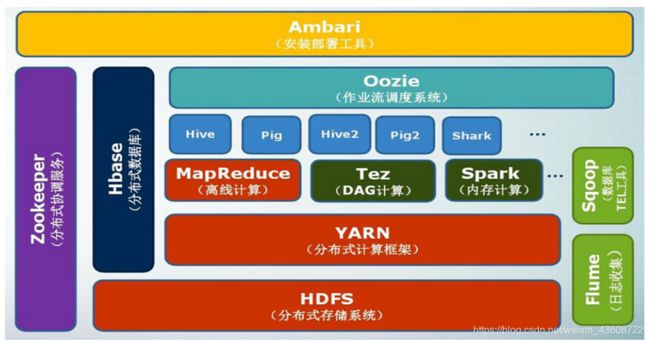
| 组件 | 功能 |
|---|---|
| HDFS | 分布式文件系统 |
| MapReduce | 分布式并行编程模型 |
| YARN | 资源管理和调度器 |
| Tez | 运行在YARN之上的下一代Hadoop查询处理框架,它会将很多的mr任务分析优化后构建一个有向无环图,保证最高的工作效率 |
| Hive | Hadoop上的数据仓库 |
| HBase | Hadoop上的非关系型的分布式数据库 |
| Pig | 一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin |
| Sqoop | 用于在Hadoop与传统数据库之间进行数据传递 |
| Oozie | Hadoop上的工作流管理系统 |
| Zookeeper | 提供分布式协调一致性服务 |
| Storm | 流计算框架 |
| Flume | 一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统 |
| Ambari | Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控 |
| Kafka | 一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据 |
| Spark | 类似于Hadoop MapReduce的通用并行框架 |
HDFS相关概念、体系结构、数据存取策略、数据错误与恢复
相关概念
-
块
HDFS默认一个块128MB,一个文件被分成多个块,以块作为存储单位。
- 支持大规模文件存储
- 简化系统设计
- 适合数据备份
-
NameNode和DataNode
NameNode DataNode 存储元数据 存储文件内容 元数据保存在内存中 文件内容保存在磁盘 保存文件,block,datanode之间的映射关系 维护了block id和datanode本地文件的映射关系 -
NameNode
-
在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间,保存了两个核心的数据结构,即FsImage和EditLog
-
名称节点记录了每个文件中各个块所在的数据节点的位置信息

-
-
FsImage文件
- FsImage文件包含文件系统中所有目录和文件inode的序列化形式。
- FsImage文件没有记录块存储在哪个数据节点。而是由名称节点把这些 映射保留在内存中
-
SecondaryNameNode
第二名称节点是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。SecondaryNameNode一般是单独运行在一台机器上
-
数据节点(DataNode)
- 数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据
客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发
送自己所存储的块的列表
- 每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中
-
HDFS体系结构
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点(NameNode)和若干个数据节点(DataNode)。名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。集群中的数据节点一般是一个节点运行一个数据节点进程,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作。每个数据节点的数据实际上是保存在本地Linux文件系统中的

数据存取策略
- 数据存放
- 第一个副本:放置在上传文件的数据节点;如果是集群外提交,则随机挑选一台磁盘不太满、CPU不太忙的节点
- 第二个副本:放置在与第一个副本不同的机架的节点上
- 第三个副本:与第一个副本相同机架的其他节点上
- 更多副本:随机节点

- 数据读取
- HDFS提供了一个API可以确定一个数据节点所属的机架ID,客户端也可以调用API获取自己所属的机架ID
- 当客户端读取数据时,从名称节点获得数据块不同副本的存放位置列表,列表中包含了副本所在的数据节点,可以调用API来确定客户端和这些数据节点所属的机架ID,当发现某个数据块副本对应的机架ID和客户端对应的机架ID相同时,就优先选择该 副本读取数据,如果没有发现,就随机选择一个副本读取数据
数据错误与恢复
-
名称节点出错
HDFS设置了备份机制,把这些核心文件同步复制到备份服务器SecondaryNameNode上。当名称节点出错时,就可以根据备份服务器SecondaryNameNode中的FsImage和Editlog数据进行恢复。
-
数据节点出错
-
每个数据节点会定期向名称节点发送“心跳”信息,向名称节点报告自己的状态
-
当数据节点发生故障,或者网络发生断网时,名称节点就无法收到来自一些数据节点的心跳信息,这时,这些数据节点就会被标记为“宕机”,节点上面的所有数据都会被标记为“不可读”,名称节点不会再给它们发送任何I/O请求
-
这时,有可能出现一种情形,即由于一些数据节点的不可用,会导致一些数据块的副本数量小于冗余因子
-
名称节点会定期检查这种情况,一旦发现某个数据块的副本数量小于冗余因子,就会启动数据冗余复制,为它生成新的副本
-
HDFS和其它分布式文件系统的最大区别就是可以调整冗余数据的位置
-
-
数据出错
-
网络传输和磁盘错误等因素,都会造成数据错误
-
客户端在读取到数据后,会采用md5和sha1对数据块进行校验,以确定读取到正确的数据
-
在文件被创建时,客户端就会对每一个文件块进行信息摘录,并把这些信息写入到同一个径的隐藏文件里面
-
当客户端读取文件的时候,会先读取该信息文件,然后,利用该信息文件对每个读取的数
-
据块进行校验,如果校验出错,客户端就会请求到另外一个数据节点读取该文件块,并且向名称节点报告这个文件块有错误,名称节点会定期检查并且重新复制这个块
-
HDFS如何减轻名称节点的负担
在客户端需要访问一个文件时,名称节点并不参与数据的传输,而是只将数据节点位置发给客户端,因此实现了一个文件的数据能够在不同的数据节点上实现并发访问,大大提高了数据访问速度并减轻了中心服务器的负担,方便了数据管理。
MapReduce相较于传统并行计算框架的优势
| 传统并行计算框架 | MapReduce | |
|---|---|---|
| 集群架构/容错性 | 共享式(共享内存/共享存储),容错性差 | 非共享式,容错性好 |
| 硬件/价格/扩展性 | 刀片服务器、高速网、SAN,价格贵,扩展性差 | 普通PC机,便宜,扩展性好 |
| 编程/学习难度 | what-how,难 | what,简单 |
| 适用场景 | 实时、细粒度计算、计算密集型 | 批处理、非实时、数据密集型 |
MapReduce体系结构、应用程序执行过程
体系结构
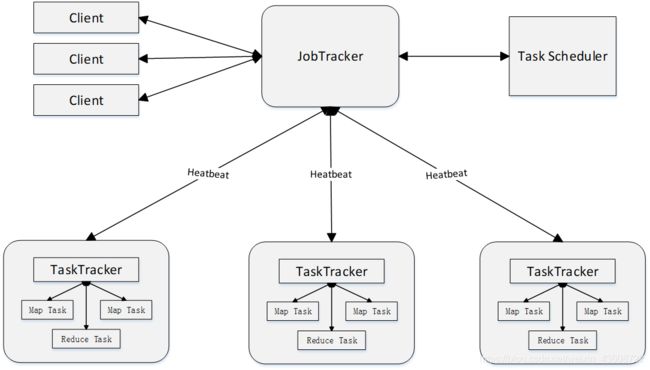
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task
-
Client
- 用户编写的MapReduce程序通过Client提交到JobTracker端
- 用户可通过Client提供的一些接口查看作业运行状态
-
JobTracker
-
JobTracker负责资源监控和作业调度
-
JobTracker 监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相
应的任务转移到其他节点
-
JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler,可插拔,可自定义),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源
-
TaskTracker
-
TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的
运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相
应的操作(如启动新任务、杀死任务等)
-
TaskTracker 使用”slot(槽)”等量划分本节点上的资源量(CPU、内存等)。
-
一个Task 获取到一个slot 后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为Map slot 和 Reduce slot 两种,分别供MapTask 和Reduce Task 使用
-
-
Task
Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动
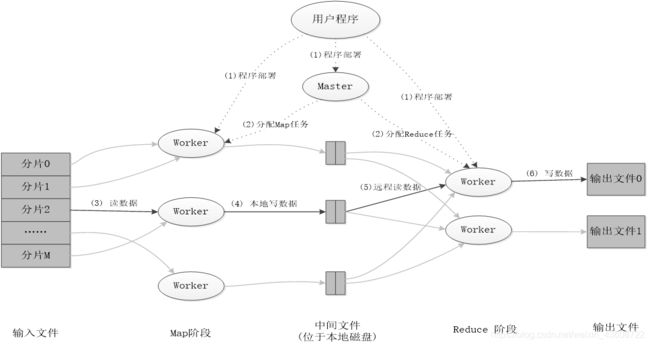
MapReduce应用程序执行过程
数据仓库概念、 Hive特点
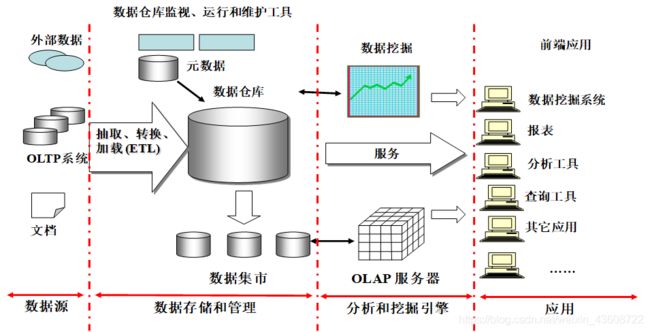
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。
-
Hive是一个构建于Hadoop顶层的数据仓库工具
-
支持大规模数据存储、分析,具有良好的可扩展性
-
某种程度上可以看作是用户编程接口,本身不存储和处理数据
-
依赖分布式文件系统HDFS存储数据
-
依赖分布式并行计算模型MapReduce处理数据
-
定义了简单的类似SQL 的查询语言——HiveQL
-
用户可以通过编写的HiveQL语句运行MapReduce任务
-
可以很容易把原来构建在关系数据库上的数据仓库应用程序移植到Hadoop平台上
-
是一个可以提供有效、合理、直观组织和使用数据的分析工具
Hive具有的特点非常适用于数据仓库
- 采用批处理方式处理海量数据
- Hive需要把HiveQL语句转换成MapReduce任务进行运行
- 数据仓库存储的是静态数据,对静态数据的分析适合采用批处理方式,不需要快速响应给出结果,而且数据本身也不会频繁变化
- 提供适合数据仓库操作的工具
- Hive本身提供了一系列对数据进行提取、转换、加载(ETL)的工具,可以存储、查询和分析存储在Hadoop中的大规模数据
- 这些工具能够很好地满足数据仓库各种应用场景
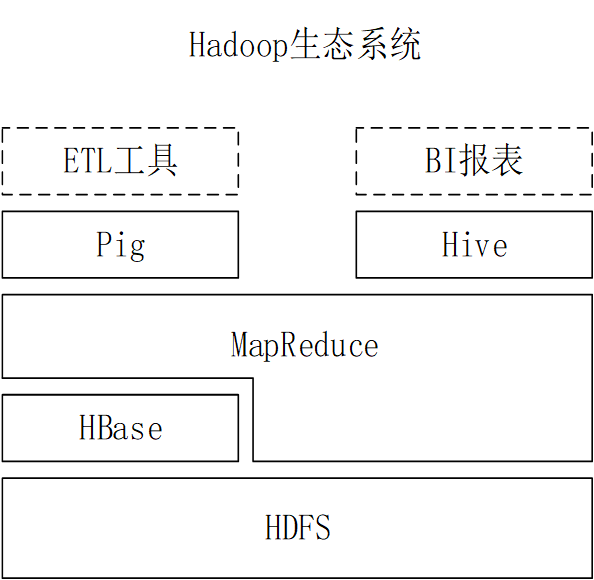
Hive与Hadoop生态系统中其他组件的关系
-
Hive依赖于HDFS存储数据
-
Hive依赖于MapReduce 处理数据
-
在某些场景下Pig可以作为Hive的替代工具
-
HBase 提供数据的实时访问
Spark特点、Spark基本概念
-
运行速度快:使用DAG执行引擎以支持循环数据流与内存计算
-
容易使用:支持使用Scala、Java、Python和R语言进行编程,可以通过Spark Shell进行交互式编程
-
通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件
-
运行模式多样:可运行于独立的集群模式中,可运行于Hadoop中,并且可以访问HDFS、HBase、Hive等多种数据源
Spark与Hadoop的对比、Spark RDD
Hadoop存在如下一些缺点:
-
表达能力有限
-
磁盘IO开销大
-
延迟高
-
任务之间的衔接涉及IO开销
-
在前一个任务执行完成之前,其他任务就无法开始,难以胜任复杂、多阶段的计算任务
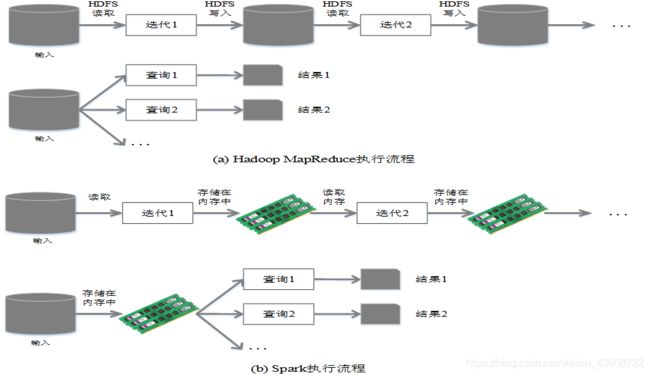
相比于Hadoop MapReduce,Spark主要具有如下优点:
-
Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多 种数据集操作类型,编程模型比Hadoop MapReduce更灵活
-
Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高
-
Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制
| MapReduce | Spark |
|---|---|
| 数据存储结构:磁盘HDFS文件系统的split | 使用内存构建弹性分布式数据集RDD 对数据进行运算和cache |
| 编程范式:Map + Reduce | DAG: Transformation + Action |
| 计算中间结果落到磁盘,IO代价大 | 计算中间结果在内存中维护 存取速度比磁盘高几个数量级 |
| Task以进程的方式维护,需要数秒时间才能启动任务 | Task以线程的方式维护 对于小数据集读取能够达到亚秒级的延迟 |
Spark RDD
RDD提供了一个抽象的数据架构,我们不必 担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,避免中间数据存储
RDD典型的执行过程如下:
-
RDD读入外部数据源进行创建
-
RDD经过一系列的转换(Transformation)操作,每一次都会产生不同的RDD,供给下一个转换操作使用
-
最后一个RDD经过“动作”操作进行转换,并输出到外部数据源
RDD特性
-
高效的容错性
现有容错机制:数据复制或者记录日志
RDD:血缘关系、重新计算丢失分区、无需回滚系统、重算过程在不同
节点之间并行、只记录粗粒度的操作
-
中间结果持久化到内存,数据在内存中的多个RDD操作之间进行传递,避免 了不必要的读写磁盘开销
担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,避免中间数据存储
RDD典型的执行过程如下:
-
RDD读入外部数据源进行创建
-
RDD经过一系列的转换(Transformation)操作,每一次都会产生不同的RDD,供给下一个转换操作使用
-
最后一个RDD经过“动作”操作进行转换,并输出到外部数据源
RDD特性
-
高效的容错性
现有容错机制:数据复制或者记录日志
RDD:血缘关系、重新计算丢失分区、无需回滚系统、重算过程在不同
节点之间并行、只记录粗粒度的操作
-
中间结果持久化到内存,数据在内存中的多个RDD操作之间进行传递,避免 了不必要的读写磁盘开销