『目标检测』YOLO V5(3):使用教程
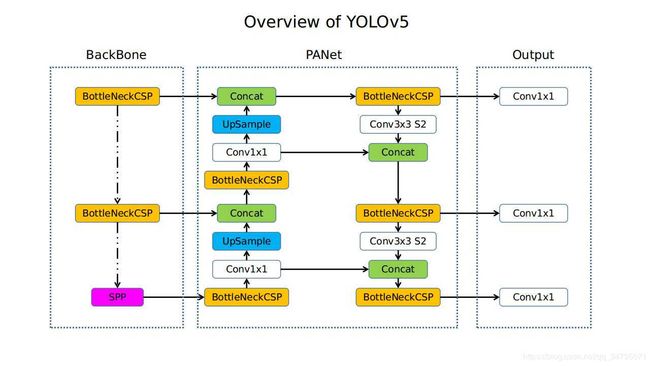
系列文章目录
- YOLO V5(1):学习笔记
- YOLO V5(2):代码解析
YOLO V5 使用教程
- 系列文章目录
- 一、安装环境依赖
-
- 1.1 克隆项目
- 1.2 安装必要的环境依赖
- 二、下载预训练模型
-
- 2.1 执行脚本下载预训练模型
- 2.2 直接下载预训练模型,然后保存到 `/yolov5/weights` 目录下即可
- 三、下载标注的数据集
-
- 3.1 执行脚本下载
- 3.2 如果下载比较慢,也可以通过 url 链接直接下载 coco128.zip
- 四、训练下载的 coco128 数据集
-
- 4.1 创建训练数据集的配置文件 Dataset.yaml
- 4.2 创建标签(Labels)
- 4.3 组织文件结构
- 4.4 选择一个模型训练
- 4.5 开始训练
-
- 4.5.1 训练命令
- 4.5.2 训练常见错误1
- 4.5.3 训练常见错误2
- 4.5.4 训练常见错误3
- 4.6 使用 tensorboard 可视化结果
- 4.7 测试
- 五、训练自己的数据集
-
- 5.1 准备数据集
- 5.2 修改数据和模型配置文件
-
- 5.2.1 修改数据配置文件
- 5.2.2 修改模型配置文件
- 5.3 训练自己的数据集
-
- 5.3.1 使用 `yolovs.pt` 预训练模型进行训练
- 参考连接
一、安装环境依赖
1.1 克隆项目
git clone https://github.com/ultralytics/yolov5 # clone repo
1.2 安装必要的环境依赖
官方给出的要求是:python>=3.7、PyTorch>=1.5,安装依赖:
cd yolov5
pip install -U -r requirements.txt
requirements.txt
二、下载预训练模型
2.1 执行脚本下载预训练模型
/yolov5/weights/download_weights.sh 脚本定义下载预训练模型
2.2 直接下载预训练模型,然后保存到 /yolov5/weights 目录下即可
直接在 google driver 中下载即可 https://drive.google.com/drive/folders/1Drs_Aiu7xx6S-ix95f9kNsA6ueKRpN2J
三、下载标注的数据集
3.1 执行脚本下载
python3 -c "
from yolov5.utils.google_utils import gdrive_download;
gdrive_download('1n_oKgR81BJtqk75b00eAjdv03qVCQn2f','coco128.zip')
" # download dataset
执行上面的代码,会下载:coco128.zip 数据集,该数据是 COCO train2017 数据的一部分,只取了 coco 数据集中的 128 张标注的图片,coco128.zip 下载完后解压到 /yolov5 目录下即可,解压后的 coco128 文件结构如下:
coco128
|-- LICENSE
|-- README.txt # 相关说明
|-- annotations # 空目录
|-- images # 128 张 jpg 图片
|-- labels # 128 张标注的 txt 文件
3.2 如果下载比较慢,也可以通过 url 链接直接下载 coco128.zip
直接在 google driver 中下载即可
https://drive.google.com/uc?export=download&id=1n_oKgR81BJtqk75b00eAjdv03qVCQn2f
Note: utils/google_utils.py 脚本是下载预训练模型和标注的训练数据集
四、训练下载的 coco128 数据集
4.1 创建训练数据集的配置文件 Dataset.yaml
上面下载好 coco128.zip 小型数据集之后,这些数据集可以用于训练和验证,models/yolov5l.yaml。
coco128.yaml 中定义了:
- 训练图片的路径(或训练图片列表的
.txt文件) - 与验证集相同的图片
- 目标的类别数
- 类名列表
4.2 创建标签(Labels)
将标签导出为 darknet 格式,每个标注图像有一个 *.txt 文件(如果图像中没有对象,则不需要 *.txt 文件),*.txt 文件格式如下:
- 每行一个对象
- 每行都是:
class x_center y_center width height格式 - 框的坐标格式必须采用
归一化格式的 xywh(从0到1),如果框以像素为单位,则将x_center和width除以图像宽度,将y_center和height除以图像的高度 - 类别是从索引 0 开始的
示例图像和标签:
dataset/images/train2017/000000109622.jpg # image
dataset/labels/train2017/000000109622.txt # label
例如:000000000009.txt 标签文件,表示 000000000009.jpg 图片中标注了 8 个目标:
45 0.479492 0.688771 0.955609 0.5955
45 0.736516 0.247188 0.498875 0.476417
50 0.637063 0.732938 0.494125 0.510583
45 0.339438 0.418896 0.678875 0.7815
49 0.646836 0.132552 0.118047 0.096937
49 0.773148 0.129802 0.090734 0.097229
49 0.668297 0.226906 0.131281 0.146896
49 0.642859 0.079219 0.148063 0.148062
4.3 组织文件结构
根据下图整理自己的训练集和验证集图片及标签。
注意:/coco128 目录应该和 yolov5 目录同级,同时确保 coco128/labels 和 coco128/images 两个目录同级!
4.4 选择一个模型训练
上面已经修改了自定义数据集的配置文件,同时组织好了数据。下面就可以选择一个模型进行训练了。
从 ./models 目录下选择一个模型的配置文件,这里我们选择 yolov5s.yaml,这是一个最小最快的模型。关于其他模型之间的比较下面介绍。选择好模型之后,如果你使用的不是 coco 数据集进行训练,而是自定义的数据集,此时只需要修改 *.yaml 配置文件中的 nc: 80 参数和数据的类别列表
yolov5s.yaml 配置文件中主要定义了:
- 参数(parameters):类别等
- anchor
- YOLOv5 backbone
- YOLOv5 head
4.5 开始训练
4.5.1 训练命令
运行下面的命令训练 coco128.ymal,训练 5 epochs。可以有两种训练方式,如下参数:
--cfg yolov5s.yaml --weights '':从头开始训练--cfg yolov5s.yaml --weights yolov5s.pt:从预训练的模型加载开始训练
YOLOv5 在 coco128 上训练 5 epochs 的命令:
python train.py --img 640 --batch 16 --epochs 5 --data ./data/coco128.yaml --cfg ./models/yolov5s.yaml --weights ''
4.5.2 训练常见错误1
1、执行训练命令报错:RuntimeError: Model replicas must have an equal number of parameters.,错误显示,模型的副本必须有相同的参数
2、解决方式:
这个可能是由于Pytorch的版本问题导致的错误,我的 torch 版本为15.0,把版本降为 1.4.0 即可(参考):
pip install torch==1.4.0+cu100 torchvision==0.5.0+cu100 -f https://download.pytorch.org/whl/torch_stable.html
4.5.3 训练常见错误2
1、执行训练命令报错:ModuleNotFoundError: No module named 'yaml'
2、解决方式:
这是由于没有安装 yaml 库包错误,虽然导入是:import yaml,但是安装的名字却不是 yaml,下面是正确安装 yaml:
pip install PyYAML
4.5.4 训练常见错误3
1、执行训练命令报错:AttributeError: 'DistributedDataParallel' object has no attribute 'model'
2、错误解决方式:
这个是由于--device的默认值为 '',此时默认会使用多GPU进行训练,但是多GPU训练时就会出现上面这个问题,这可能时一个bug(参考),解决方式就是使用单GPU,把训练命令改成如下:
python train.py --img 640 --batch 16 --epochs 5 --data ./data/coco128.yaml --cfg ./models/yolov5s.yaml --weights '' --device 0
4.6 使用 tensorboard 可视化结果
在 yolov5 目录下,使用:
tensorboard --logdir=runs
4.7 测试
测试的更多可选参数:
--weights:预训练模型路径,默认值weights/yolov5s.pt--data:数据集的配置文件,默认为data/coco.yaml--batch-size:默认值32--img-size:推理大小(pixels),默认640--conf-thres:目标置信度阈值,默认0.001--iou-thres:NMS 的 IOU 阈值,默认0.65--save-json:把结果保存为 cocoapi-compatible 的json文件--task:默认val,可选其他值:val, test, study--device:cuda设备,例如:0 或 0,1,2,3 或 cpu,默认''--half:半精度的FP16推理--single-cls:将其视为单类别,布尔值--augment:增强推理,布尔值--verbose:显示类别的mAP,布尔值
测试命令示例:
python test.py --weights yolov5s.pt --data ./data/coco.yaml --img 640
五、训练自己的数据集
数据准备有两种方式:
- 一种是直接指定训练集和测试集图片的路径
(本文使用的这种方法) - 另外一种是给出训练和测试集图片的 txt 文件
5.1 准备数据集
yolov5 中的数据集的标签都是保存为 YOLO 格式的 txt 文件的,关于:
- 怎么标注数据集
- VOC数据和YOLO数据格式时是什么样的
- 怎么把VOC格式数据转化为YOLO格式数据
- 以及VOC格式和YOLO格式相互转化计算过程
请参考:这篇 博客,这里不再赘述!!!
数据集标注好之后,存放如下目录格式:
hat_hair_beard
├── images
│ ├── train2017 # 训练集图片,这里我只列举几张示例
│ │ ├── 000050.jpg
│ │ ├── 000051.jpg
│ │ └── 000052.jpg
│ └── val2017 # 验证集图片
│ ├── 001800.jpg
│ ├── 001801.jpg
│ └── 001802.jpg
└── labels
├── train2017 # 训练集的标签文件
│ ├── 000050.txt
│ ├── 000051.txt
│ └── 000052.txt
└── val2017 # 验证集的标签文件
├── 001800.txt
├── 001801.txt
└── 001802.txt
- had_hair_beard:存放数据的目录,该目录位于
yolov5目录下 - images:目录下存放的是图片,包含训练集和验证集图片
- labels:目录下存放的是标签文件,包含训练集和验证集图片对应的标签文件
按照上面的结构组织好 数据的目录结构,然后就可以修改一些训练相关的文件了!
5.2 修改数据和模型配置文件
5.2.1 修改数据配置文件
原先的配置文件为:./data/coco128.yaml
我们把该文件拷贝一份(这是我个人的习惯,你也可以不改,直接在 coco128.yaml 文件中进修改)
然后在 hat_hair_beard.yaml 中需要修改 3 处内容:
1、训练集和验证集图片的路径
train: /home/shl/shl/yolov5/hat_hair_beard/images/train2017
val: /home/shl/shl/yolov5/hat_hair_beard/images/val2017
Note: 最好用绝对路径,我在使用相对路径的时候报错,说路径存在
2、修改类别数 nc
nc=7 # 我数据集一共分7个类别
3、修改类别列表,把类别修改为自己的类别
names: ['hard_hat', 'other', 'regular', 'long_hair', 'braid', 'bald', 'beard']
5.2.2 修改模型配置文件
上面 数据的准备 和 配置文件的修改 全部准备好之后,就可以 开始训练了!!!
5.3 训练自己的数据集
5.3.1 使用 yolovs.pt 预训练模型进行训练
训练命令:
python train.py --img 640 --batch 16 --epochs 300
--data ./data/hat_hair_beard.yaml \
--cfg ./models/hat_hair_beard_yolov5s.yaml \
--weights ./weights/yolov5s.pt
--device 1
训练结束后,会生成两个预训练的模型:
best.pt:保存的是中间一共比较好模型last.pt:训练结束后保存的最后模型
注意:
当使用 --device 参数设置多GPU进行训练时,可能会报错:RuntimeError: Model replicas must have an equal number of parameters. 具体错误如下,会报错的命令:
--device 1:指定单个GPU不会报错--device 1,2,3:当使用两个以上的GPU会报错
官方的issues解决方式:把torch的版本更新为torch1.4,而我的torch 为 1.5 版本
参考连接
- https://blog.csdn.net/weixin_41010198/article/details/106785253
- https://blog.csdn.net/weixin_41153216/article/details/106924348