week4 day2 包的基本使用(了解)和日志模块(重点)
week4 day2 包的基本使用(了解)和日志模块(重点)
-
- 一. 区分python文件两种用途
- 二. 包的基本使用(了解)
- 三. 日志模块
一. 区分python文件两种用途
python文件有两种使用途径。
- 当作执行文件运行
- 被当作模块导入执行
我们利用内置的__name__方法来使我们可以区分python文件的两种使用途径:
- 如果文件被直接执行,
__name__==__main__ - 如果文件被当作模块导入,
__name__==模块名
因此我们在文件中可以添加以下代码,如果该文件被执行,执行文件内代码,否则,当作模块导入。
if __name__ == '__main__':
执行对应代码块
二. 包的基本使用(了解)
模块可以是py文件,也可以是文件夹。导入py文件我们之前已经进行过探讨了,现在我们进行导入文件夹的探讨。当我们导入一个文件夹模块的时候,本质就是找文件夹要里面的__init__.py文件。
文件夹模块的设计者最初把所有功能放在一个py文件中,所有的使用者只需要在自己的执行文件中导入这个文件,然后直接加 . 调用对应的功能即可。随着功能越来越多,设计者需要分门别类存放功能(放在不同的文件里面),但是对于使用者来说,他们并不知道模块的内部如何发生变化,他们还是导入模块,加 . 调用功能。因此,设计者需要将自己的维护更新适配使用者原来的使用习惯,就需要整理分门别类存放的文件,将它们放到文件夹中。但同时还不能改变该模块的使用方法,因此需要在文件夹中添加__init__.py文件,把所有分散的功能整合到__init__.py文件里面。
原来只有一个aaa.py文件作为模块导入后的使用方法(方便与后面导包作比较):
run.py:
import aaa
aaa.f1()----->from f1
aaa.f2()----->from f2
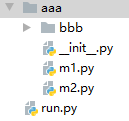
当py文件变成了包以后,文件路径是这样的时候,run.py是执行文件,我们想在run.py里面要到aaa的m1和m2的内容,就需要在__init__.py文件里面添加好m1和m2的模块。添加模块的方式有两种:
- 绝对导入:从包的文件夹作为起始目录开始导入
# =====================只扒一层皮,找aaa下面的m1里面的f1,找m2里面的f2=====================
# aaa的__init__.py:
from aaa.m1 import f1
from aaa.m2 import f2 # 将f1和f2扔到了aaa的名称空间中
# run.py:
导入方式一:
import aaa
调用方式一:
aaa.f1()----->from f1
aaa.f2()----->from f2
导入方式二:
from aaa import f1
from aaa import f2
调用方式二:
f1()----->from f1
f2()----->from f2
# =====================扒两层皮,找bbb下面的m3里面的f3=========================
# aaa的__init__.py:
from aaa.bbb.m3 import f3 # f3的爸爸是m3,m3的爸爸是bbb,bbb的爸爸是aaa,aaa就是包的文件夹,所以可以开始扔在aaa的__init__里面了
# run.py:
导入方式一:
import aaa
调用方式一:
aaa.f3()----->from f3
导入方式二:
from aaa import f3
调用方式二:
f3()----->from f3
- 相对导入(只能在包内使用,局限性比较大,了解即可)
__init__.py:
from .m1 import f1
from .m2 import f2
这样导入模块完成后,就可以和原来一样的调用功能。
run.py:
aaa.f1()----->from f1
aaa.f2()----->from f2
总结:
- 导包就是在导包下的__init__.py文件
- 包内部的导入应该使用相对导入,相对导入只能在包内使用,而且…取上一级不能出包
- 使用语句中的点代表的是访问属性 m.n.x----->向m要n,向n要x
而导入语句中的点代表的是路径分隔符 import a.b.c----->a/b/c 文件夹a下有个子文件夹b,b下有子文件或者子文件夹c。并且导入语句中的点左边必须是一个包