音视频基础1:H264、H265、MPEG-4、VP8、VP9编码基础知识
这里写自定义目录标题
- 个人认知,程序员职业发展出路
- 编码器发展史
- 编码原理
- H264
- H265
个人认知,程序员职业发展出路
随着5G时代的到来,音视频成功走上风口,程序员如何发展,其实不管是入门级选手还是30岁,35岁中年危机的IT开发者,异或是更年长的IT开发者,都会有自己的职业发展路线。总结来说,目前大部分人的职业路线,职业出路,或者说职业遇到瓶颈以后解决方案可以总结为一下几种,程序员是天天解决问题,天天给各种问题解决方案的人,对于自己的职业当然也得给出最好的解决方案:
出路1: 转行;最简单粗暴的,从写代码的工作变换到开个杂货铺,开个烧烤摊,或者考个公务员事业单位。完全走上一个新的领域新的行业,但是这也是一种出路,没有对错,只有适合还是不适合。
出路2: 继续深入专业领域;这个就有点厉害了,当然也是有难度的,在自身的领域达到专家级别,对自己的领域有比其他人更多更深的研究和见解,这个时候,你的年纪其实是你的优势,随着技术的进一步深入,进一步积累,你会更值钱。但是你的成绩从不及格提升到及格是很容易的,从60份到80分也是比较容易的,提升到90分也可以做到,但是当你要做到从95分到96分的提升就很艰难了,需要很多的耐心、思考,等等,人和人之间的差距也许就是那0.1分,这就是为什么很多人做不到纵向深入的原因。
出路3: 相关领域转行,比如管理岗,技术管理岗,销售管理岗。都是以技术为基础继续向相关领域拓展。技术深入属于纵向拓展,相关岗位转岗就属于横向拓展了。
目前大部分的人都会有这3种考虑,觉得绞尽脑汁也就这3种选择和出路了,但是在我看来还有一种,追随风口。
出路4,追随互联网技术风口。
现在的互联网技术更新速度非常的快,阿里有一句话非常牛逼,就算是一头猪到了风口也可以飞上天。现在互联网技术发展这块,风口技术每年都有,有的技术可以维持三到五年的风口期,这段时间进行野蛮式增长、爆发,之后就进入一个相对理性、成熟、稳定增长和变化的环节了,这就趋于稳定了。
我看来的出路就是,用敏锐的触觉去发现每一次的风口技术,去抓风口技术,用最快的速度去学习风口技术,赶上这一波红利,做一个当下技术红牛没问题吧,甚至成功创业也不是不可能。
说的有点热血了,总结一句就是说,还有一个出路,需要你有快速反应能力,快速学习知识,学习技术,整合资源,学习当下最有发展前景,即将爆发的技术。
比如5G相关的产业。
也许你只需要学好0-1或者0-10,0-60就可以了,不必那么深入,因为走的就是快速路线,快枪讲究的就是速度。
说的太多有点跑题了,回归正题,音视频,移动音视频,随着5G的到来,音视频必然会带上风口,我个人认为在这个上风口之前具备一定的音视频开发技术,到了风口收割一波红利,没得说,美滋滋。但是音视频开发门槛较高,国内资源较少,这也是难点。
但是,难点也是卖点,烂大街的东西当然便宜了。
闲话就说这么多,今天主要总结一下几种编解码器的基础知识,他们的背景知识。
---------------------------------------------------------先洗这么点,明天继续更。2021-1-4.
编码器发展史
Android中创建编码器
MediaCodec.createEncoderByType("video/av"); //创建H264编码器
MediaCodec.createEncoderByType("video/hevc"); //创建H265编码器

为什么会有这么多种编码器?看看他们的发展史的。
ITU-T这个组织是专门做音视频的组织,还有一个组织ISO,这个组织是专门做各种标准规范的。
ITU-T是最先研发了音视频通话的,最先研究出了H261,后来发布H262,H263,指导后来的H视频编解码器,这是ITU-T的H26x系列。
两个组织互相竞争,
ISO也研发了MPEG-1、MPEG-2、MPEG-3、MPEG-4,对应H26x系列。
两个组织竞争了相近20年,两个组织两个标准,最后再1998年双方合作,在第一版H264的基础上双方进行共同研发,发布了后来的更成熟的H264,作为后来的结晶,这一结晶在ITU-T组织中依然称为H264,但是在ISO组织中称为MPEG4-avc,这只是在不同组织中的称呼名字。
但是在实际代码中创建的时候,都是传入,首先是video表示一个视频标签,然后传入ISO组织的名称“avc”表示H264编解码器,H265就是“video/hevc”。
随着社会的进步,技术的发展,生活中使用的显示器,越来越大,视频画面也变大,广泛的出现了4K、8K视频,这对于H264来说已经存在明显不足了,所以两个组织又一起合作研发了H265.
H265编解码技术在ITU-T组织中称为H265,在ISO组织中称为HEVC。
H265在H264的基础上研发的,可以达到更高压缩的同时实现画面更清晰。
H264可以实现把4M的数组压缩到80k-90k,
同样的画质和同样的码率,H.265比H2.64 占用的存储空间要少理论50%;

封装格式
mp4、flv、rmvb、avi等称为封装格式。
封装格式内部包含视频轨(H264、H265编码器编码之后的后缀是h264、h265的视频编码文件)、音频轨(后缀是.aac .mp3的音频编码文件)、字幕轨以及视频宽高等编解码信息。
编解码格式
H264、H265、VP8、VP9等称为编码格式。
其他参与者,其他编解码器
Google后来推出了VP8、VP9的编解码器,VP8,VP9分别和H264、H265做对应竞争。
Microsoft推出了VC-1。
国产自主标准:AVS/AVS+/AVS2,只是仅仅用于机顶盒,广播电视,其他领域并没有用到。但是现在的广播电视也已经废弃了AVS标准了用了其他更优良的标准。
视频的组成
可以通过FFmpeg命令把视频文件进行拆分,把一个mp4封装格式的视频文件可以抽取其中的h264视频流文件,也可以抽取其中的aac音频流文件。
视频编码文件、音频编码文件、编解码信息包括视频宽高等共同组成了封装视频文件。
编码原理
视频是如何进行编码的呢

H261在音视频领域的地位相当于冯诺依曼计算机模型对计算机领域的影响。


编码的本质就是压缩,而且是有损压缩,损失掉人耳可以听的音波频率范围之外的频率的声音。图像编码也是有损编码。
图像编码首先是将画面打乱划分称为宏块,经过心愿编码器划分宏块。
在H.264中的宏块大小是固定的16x16,在H.265中宏块的大小是可变的,最小8x8最大64x64。

对于这样一个渐变色的色块,记录哪些信息可以保存这个渐变色块呢?
首先是宽高;
其次,是起止点颜色,终止点颜色;
最后,一条颜色渐变的变化趋势方向。
这样,有这3个数据就可以还原出这张渐变图了,也就是可以唯一确定这张渐变图了。
比起来存储这张图片里的所有像素点的像素值,存储的数据就小的多了。
图片编码思路

摄像头采集到的原始视频数据是YUV格式的视频数据,然后这个YUV的数据传输给信源编码器,信源编码器的作用就是将视频的每一帧打乱成宏块,

划分好宏块后,计算宏块的像素值,计算一副图像中每个宏块的像素值,

计算宏块像素值的时候,也类似于上面的存储一张渐变图的方式,存储横向宽的第一排像素值,存储第一列的纵向颜色值,然后再记录一个预测方向,这个宏块的显示内容基本上就可以确定了。
这样,虽然不会完全把这张图片的内容保存下来,但是基本上可以把这张图片的绝大多数的内容还原出来。这也就是为什么说是有损压缩了。
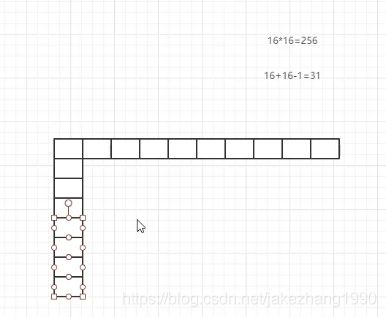
原本,完全保存一张图片,比如宽高都是16像素的图片,完整保存需要16X16个int值也就是256字节,但是经过这样横向保存16字节纵向保存16字节然后保存一个预测方向,基本上只需要16+16-1=31个字节就可以保存这张图片了。


H264有8个预测方向+1个平均值,一共9个预测。


可以看出,其他条件不变的情况下,宏块越大,视频文件越小。
所有宏块都处理完,就可以拼接成一张图,就是由宏块的拼接成的一张图片了。

然后,就是划分子块:
H265对比较平坦的图像使用16X16的大小的宏块,但是为了更高的压缩率,还可以在16X16的宏块上划分出更小的子块,子块的大小可以是8X16,16X8,8X8,4X8,8X4,4X4,非常的灵活。
子块就是在16X16的标准宏块内进一步划分出更小的宏块。

这样再经过帧内压缩,可以得到更高效的数据。

可以看到H264压缩后的像素颗粒更少了。更大成都的压缩了。
宏块划分好后,就可以对H265编码器缓冲中的所有图片进行分组了。
下一步就是:帧分组:
对于视频数据主要有两类数据冗余,一类是时间上的数据冗余,一类是空间上的数据冗余。其中时间上的数据冗余是最大的,先说说视频数据时间冗余问题。
为什么说时间上的冗余是最大的呢?假设摄像机每秒抓取30帧,这30帧的数据大部分情况下都是相关的,也有可能不止30帧的数据,可能几十上百帧的数据都是关联特别密切的。
对于这些关联特别密切的帧,其实只需要保存一帧的数据,其他帧都可以通过这一帧在按某种规则预测出来,所以说视频数据在时间上的冗余是最多的。
为了达到相关帧通过预测的方法来压缩数据,就需要将视频帧进行分组。那么如何判定某些帧关系密切,可以划分为一组呢?
举个例子,打台球为例:


H265编码器会按顺序,每次取出两幅相邻帧进行宏块比较,计算两帧的相似度,如下:


可以使用VideoEye分析视频的每一帧以及各种数据。

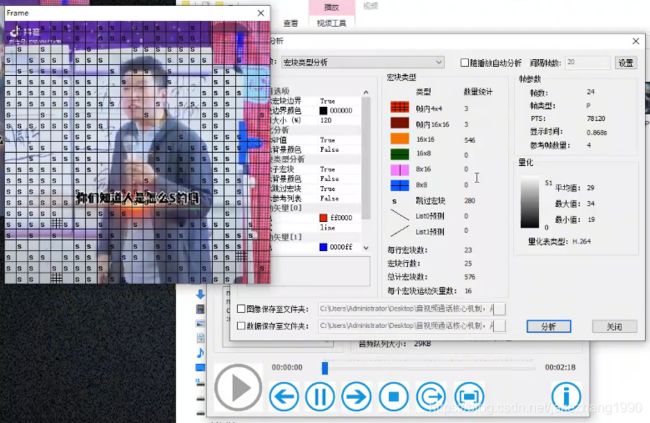
为什么宏块越小压缩程度越低,如果是4x4宏块,减掉的原本图像的内容就越少,和原本内容相同数据就越多,宏块越大,和原图相同数据肯定就越少了。大宏块压缩肯定会丢失更多的画面细节数据,小宏块压缩,就能够保存更多的图像细节数据,图像肯定更清晰。
像微信中的发送视频,如果不是发送的原图,微信肯定进行了压缩,它压缩时牺牲视频宽高和帧率来达到的压缩,和现在视频逐帧从YUV原始数据编码压缩时不同的。
H264
H265是基于H264的,H265是在H264的基础上发展起来的。
什么是H264:
定义: 对摄像头采集的每一帧视频需要进行编码,由于视频中存在空间和时间的冗余,需要用算法来取出这些冗余。H264是专门去除这些冗余的算法,我们把这种算法称为H264编码。
H264是新一代的编码标准,以高压缩高质量和支持多种网络的流媒体传输著称。
应用 大多数看到的视频,如rmvb, avi, mp4, flv 大豆是由H264进行编码,当然也会有不同的其他编码器,如mpeg4, vp9等这些比较冷门的编码器进行编码。
无论是H264 mpeg4 vp9 都是基于宏块的方式进行编码,原理都是一样的,只不过实现的算法不一致罢了。
H265
相对于H264,总结来说,在增加视频压缩率的同时,视频画面质量反而增加了,更高清了。
H264 H265 对比


在H265的压缩算法中,在像素趋于一致的地方,就采用64X64的宏块大小,在画面复杂的地方采用4X4这样的小宏块,也就是说,细节的地方H265表现更好。就是因为宏块比较小,更能够还原对应的数据,画面更清晰。
H264里有8+1个预测方向,但是在H265里面有35个预测方向。
H265块划分结构
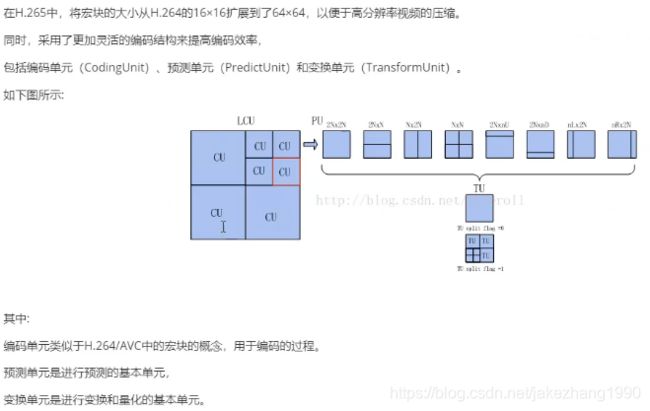

H265中的编码过程
首先宏块会划分成64X64的大小,如果宏块内像素变化比较大,就会将该64X64的宏块继续往小划分,比如划分成4个子块,会遍历每一个子块,这个时候就会形成一个树,一个四叉树,每个子块是32X32的,对每个子块再进行进一步像素计算,如果子块内颜色趋于一致那就不再继续划分,如果子块内像素变化较大,那就继续划分,最小可以划分成4X4的大小,也就是极限情况下会出现一个64叉树。
YUV数据经过信源编码器会打乱成很多个宏块;
然后会再经过视频符合编码器;
视频符合编码器主要做的就是方向预测以及基本参考数据保存,总结来说就是结构化数据;
然后再经过传输缓冲器,会先缓存B帧数据。
捕获到的第一帧是I帧,I帧内部存储了所有了宏块数据。
第二帧和第一帧相差不大,也就是说第一帧中的宏块,第二帧中还是存在很多的,这些相同的宏块就不需要再重新进行编码了。
这样看来,视频播放的本质,就是宏块的运动,由于宏块的运动,导致用户看到的视频画面发生了改变。
那么,在第二帧就不需要保存所有的宏块了,只需要保存运动矢量+残差数据 就可以了。这就是 P帧。
B帧 不仅要参考I帧还要参考P帧才能确定自己的运动矢量,B帧里面只保存运动矢量,不需要保存宏块数据。
所以,I帧最大,P帧次之,B帧最小;
如果一个视频文件中I帧越多,视频文件肯定越大。
与I帧相似程度极高,达到95%以上编码成B帧;相似程度70%以上编码成P帧。如何编码不需要程序员来实现,已经由x264这个工具实现了。
所以,首先会生成一个I帧,保存所有宏块的数据,进行编码;然后第二帧生成B帧,把B帧与I帧对比,相同宏块去掉替换成运动矢量,第三帧B帧;再然后第四帧,信源编码器认为应该生成P帧,视频符合编码器会取出P帧里和I帧相同的宏块,再把对应的宏块转成运动矢量,
P帧,B帧都会和I帧做对比,去掉相同宏块,替换成运动矢量,再进行保存。
所以,码流中,首先输出I帧,然后并不是输出B帧,而是把B帧存在了传输缓冲器中,生成P帧以后把P帧输出到码流,这个时候才开始输出B帧,并不是直接从传输缓冲器直接输出B帧,而是从传输缓冲器中缓冲的B帧交给新源编码器、然后再交给视频符合编码器,或者直接从传输缓冲器交给视频符合编码器,把B帧与I帧比较,去掉重复宏块,生成B帧的运动矢量,把B帧输出到码流。
是这样的顺序。

所以,码流中,I帧之后一定是P帧。只有P帧输出之后,才能输出B帧。
视频流是一串流,可以通过十六进制分析工具分析264文件,或者用抓包工具,可以看到里面就是一串流数据,那在这一串流数据中怎么找到I帧,B帧,P帧呢?
这个时候H264设计了一个分隔符,0x0000 0001。


一个视频的帧数,就可以通过记录有多少分隔符,就可以知道有多少帧数据。
问题又来了,如果只知道分隔符,是知道了帧与帧之间的分隔,知道了一帧的数据,但是并不知道它是什么帧,所以264在设计的时候,在分隔符之后又增加了两位来表示帧类型,比如0x 0000 0001 65表示I帧。
那把I帧和P帧拿到之后能够解码出画面呢?
答案是不能。因为还需要解码参数。
解码参数就是sps,pps里面存储的信息。
码流中是按照I帧,P帧,B帧。。。。这样的顺序传输过来的,但是实际上画面是I帧,B帧,B帧,P帧,这样的顺序。所以,解码时候,首先解码I帧渲染出画面,然后解码P帧,但是P帧的画面并不能立刻播放出来,而是需要去解码B帧,B帧画面出来之后才播放P帧画面出来。这是怎么保证这个顺序的呢?码流中有一个pts参数,这是一个按照帧播放顺序递增的数据。
也就是说I帧传输过来,解析出来,就播放了,然后P帧传输过来也给它解析出来了,但是得让P帧等一等,按视频顺序播放了B帧之后再把P帧播放出来。
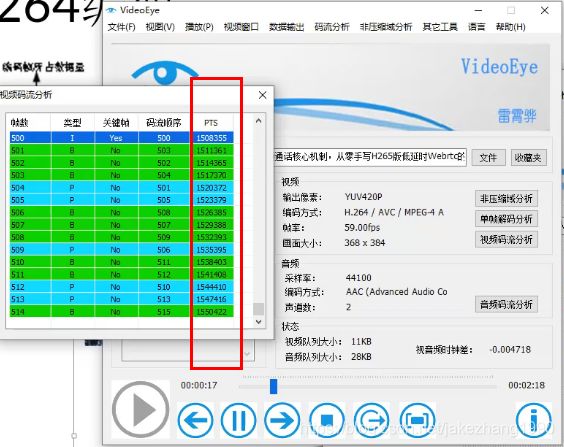
新的问题来了,首先生成了I帧,然后相似程度极高的第二帧画面,第三帧画面。。。相似程度都在95%以上,都生成了B帧,直到相似程度低于95%生成P帧。问题是,B帧是什么时候输出到H264码流中的?
生成了B帧不会立刻输出到码流中,因为B帧非常小,会缓存在传输缓冲器中,直到有P帧生成传输到码流之后才会从传输缓冲区拿出所有缓存的B帧,传输到码流。
视频倒放特效是怎么实现的呢?
其实就是,首先按照正序解码出来,然后倒序重新进行编码,编码出新的文件,编码比较耗时,所以选择了倒序播放会需要等待一小会儿。
I帧保存了所有宏块的数据。
所以,文件的大小和宏块大小有关系,也和I帧数量有关系。
短视频、电影中I帧是比较少的;
直播中I帧是相对比较多的;
但是直播中I帧变多就会导致视频流变大,直播中对尽可能的低带宽小数据量传输也是迫切的,所以,增多I帧以后还是需要优化,怎么优化,降低帧率,普通视频的帧率在30帧左右,但是直播的帧率一般在10-15帧。这样就保证了直播的流畅性又保证了直播视频秒开。
GOP
两个I帧之间的帧就是GOP。两个I帧之间的序列,在一个图像序列中只有一个I帧。
所有的视频文件的第一帧永远是I帧。不可能是P帧也不可能是B帧。
变换了场景之后,肯定会产生一个I帧。
短视频的GOP一般都比较大,在200-800之间,但是直播的GOP都比较小。

可以通过雷霄华的分析工具进行分析运动矢量:

