华为云“云上先锋”·AI主题赛(垃圾分类)-Top7复盘
文章目录
- 介绍
-
- 赛事介绍
- 数据分析
- 模型训练
- 玄学炼丹
介绍
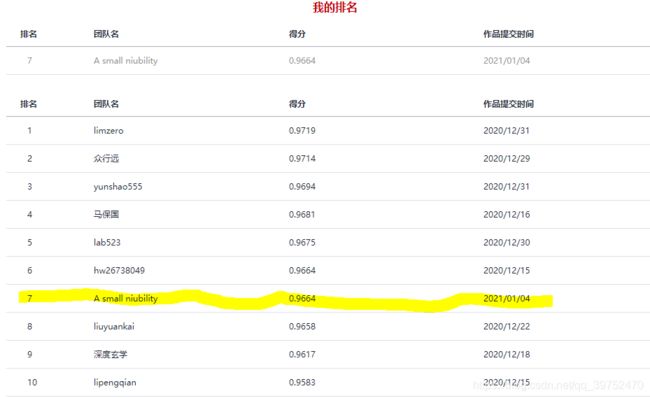
在2020.12-2021.1这段时间和师兄参加了华为云“云上先锋”·AI主题赛官网(垃圾分类),最后拿到了 第7名(7/1405) 的成绩,在最终榜单上分数为96.64.
赛事介绍
1.赛题描述
本赛题采用深圳市垃圾分类标准,赛题任务是对垃圾图片进行分类,即首先识别出垃圾图片中物品的类别(比如易拉罐、果皮等),然后查询垃圾分类规则,输出该垃圾图片中物品属于可回收物、厨余垃圾、有害垃圾和其他垃圾中的哪一种。
模型输出格式示例:
{
" result ": “可回收物/易拉罐”
}
2.数据说明
本次比赛提供的训练集中包含了43类生活中常见垃圾,参赛者可自行划分用于模型调优用的验证集和测试集。
datasets
|- train_data ( 训练集目录,包含垃圾图片和对应的标签文件(.txt))
|- garbage_classify_rule.json (垃圾分类规则字典,key值是id,value是“垃圾种类/具体物品名”。
例如训练数据标签文件img1.txt的内容是“img_1.jpg, 0”,表示img_1.jpg这张图中的垃圾是“其他垃圾/一次性快餐盒”。)
3.评分标准
如上文模型输出格式示例中,模型预测的物品类别是“易拉罐”,如果图片的真实类别是易拉罐,则这张图片预测正确,否则预测错误。评价指标的计算方式是:
识别准确率 = 识别正确的图片数 / 图片总数
识别准确率的数值即为最终的模型评分。
4.提交说明
参赛者需使用华为云一站式AI开发平台ModelArts来开发模型,将模型部署为在线服务或批量服务验证其正确性。确认模型无误后在ModelArts平台上将开发好的模型提交判分,最后在竞赛平台上提交作品、查看成绩。
模型规范
1、所提交的模型必须满足赛题说明中的模型输出格式
2、评分系统使用ModelArts批量服务加载选手提交的模型,对比赛评分专用的测试集图片(此部分图片不公开)进行批量预测,后台会根据预测结果自动计算识别准确率
3、不允许使用“测试时增强”策略和“模型融合”策略(如投票、stacking和blending)来提升模型的效果,只能使用端到端预测的单模型,每个赛事阶段结束后,都会要求入围选手提交代码和模型,由赛事组进行人工审核模型是否符合要求
4、ModelArts模型管理中的模型创建后,不会自动更新,如果您有了更好的模型需要提交,要重新导入模型,然后再重新发布模型、提交作品
5、排名靠前选手所提交的模型,会被择优发布到ModelArts AI市场
这个ModelArts系统挺一言难尽的,评判时间会很慢,一个多小时出结果,有时候还会评分失败。。
数据分析
这次也是属于图像分类的一种,但是官方要求不能使用多模型融合和TTA,只能看单模型的泛化能力,所以要在单模型上挖掘出最大潜能。图像训练集总共包含43类,2.1W张,这个比赛在2019年已经有过类似的了,当时是40类,为了增强泛化,我们把上一届比赛某获奖方案中自行添加的4K数据也加了进来。后续结果证明,因为这个附加数据已经经过筛选,加入后会带来0.2左右的提升。
下面是做一个数据可视化分析:
类别说明:
{
“0”: “其他垃圾/一次性快餐盒”,
“1”: “其他垃圾/污损塑料”,
“2”: “其他垃圾/烟蒂”,
“3”: “其他垃圾/牙签”,
“4”: “其他垃圾/破碎花盆及碟碗”,
“5”: “其他垃圾/竹筷”,
“6”: “厨余垃圾/剩饭剩菜”,
“7”: “厨余垃圾/大骨头”,
“8”: “厨余垃圾/水果果皮”,
“9”: “厨余垃圾/水果果肉”,
“10”: “厨余垃圾/茶叶渣”,
“11”: “厨余垃圾/菜叶菜根”,
“12”: “厨余垃圾/蛋壳”,
“13”: “厨余垃圾/鱼骨”,
“14”: “可回收物/充电宝”,
“15”: “可回收物/包”,
“16”: “可回收物/化妆品瓶”,
“17”: “可回收物/塑料玩具”,
“18”: “可回收物/塑料碗盆”,
“19”: “可回收物/塑料衣架”,
“20”: “可回收物/快递纸袋”,
“21”: “可回收物/插头电线”,
“22”: “可回收物/旧衣服”,
“23”: “可回收物/易拉罐”,
“24”: “可回收物/枕头”,
“25”: “可回收物/毛绒玩具”,
“26”: “可回收物/洗发水瓶”,
“27”: “可回收物/玻璃杯”,
“28”: “可回收物/皮鞋”,
“29”: “可回收物/砧板”,
“30”: “可回收物/纸板箱”,
“31”: “可回收物/调料瓶”,
“32”: “可回收物/酒瓶”,
“33”: “可回收物/金属食品罐”,
“34”: “可回收物/锅”,
“35”: “可回收物/食用油桶”,
“36”: “可回收物/饮料瓶”,
“37”: “有害垃圾/干电池”,
“38”: “有害垃圾/软膏”,
“39”: “有害垃圾/过期药物”,
“40”: “可回收物/毛巾”,
“41”: “可回收物/饮料盒”,
“42”: “可回收物/纸袋”
}
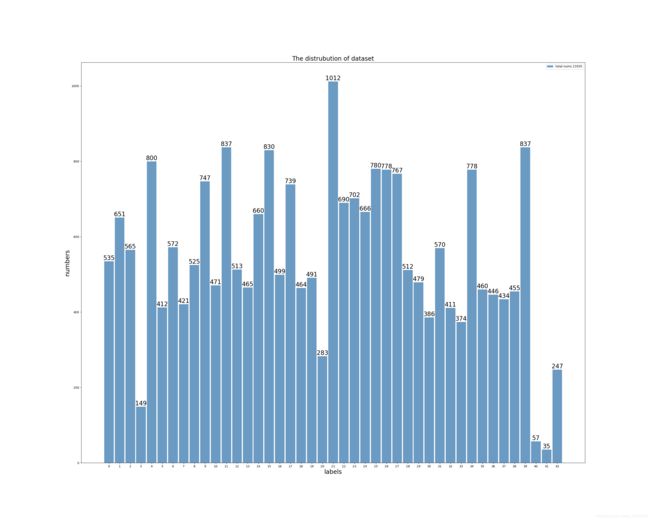
上图可以看到类别还是不太平衡的,后续结果表明,虽然类似于3,20,40,41,42的数据较少,但在这些类别上的正确率还不错,没有表现出很恶劣的情况。我们在训练时把数据划分为9-1格式,90%train,10%val,最后也尝试过全部数据进行训练,但是结果一直不太好,还没能超越9-1划分最高分。
做数据增强的时候,发现很多垃圾图片都是对称的,还有轻微的旋转角度,所以也没有加入过多的数据增强。


最终选择的训练数据增强操作如下:
self.transforms = T.Compose([
T.Resize((int(input_size / 0.934), int(input_size / 0.934))),
T.RandomCrop((input_size,input_size)),
T.RandomRotation(10),
T.RandomHorizontalFlip(),
T.ToTensor(),
normalize
])
验证和测试都是只加入了中心裁剪:
self.transforms = T.Compose([
T.Resize((int(input_size / 0.934), int(input_size / 0.934))),
T.CenterCrop((input_size,input_size)),
T.ToTensor(),
normalize
])
这里的 input_size / 0.934 是针对 tf_efficientnet_b5_ns 模型456输入的cropt_pct,对应普通的224输入就是 input_size/0.875 。
模型训练
1.网络选择
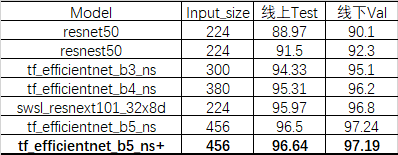
最开始用resnet50跑了一个baseline,提交后再换不同模型,这些操作都比较无脑,就是加大分辨率大模型了,因为之前ACCV细粒度分类比赛第2名使用了efficientnet的ns模型,这次延续了上次的做法,改为timm库中的tf_efficientnet_bx_ns 系列,这个在imagent上的Top1准确率表现很不错
2.训练过程
我们在单卡2080TI上训练,优化器选择了SGD,初始 lr=0.001,使用ReduceLROnPlateau进行衰减,这里是对val_loss进行判断,如果2个epoch都没有减少,则学习率衰减0.1倍,因为val_acc震荡太多在20epoch左右,使用val_loss会更好一点。
optimizer = optim.SGD((model.parameters()), lr=0.001, momentum=0.9, weight_decay=0.0004)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=2, verbose=False)
损失函数开始选择 CrossEntropyLoss ,后面改为LabelSmoothingLoss,smoothing=0.1,会涨点0.25.
后面改为b6/b7系列发现效果会变差,b5是最优的选择,也试了swsl_resnext101系列,发现效果不怎么好,但是可能也是我们炼丹不够好。
在训练 tf_efficientnet_b5_ns 时,使用了混合精度Apex训练,batchsize=12,20-40个epoch之间出最好结果。
from timm.models import create_model
model = create_model(
'tf_efficientnet_b5_ns',
pretrained=True,
num_classes=43,
drop_rate=0.1,
drop_connect_rate=None, # DEPRECATED, use drop_path
drop_path_rate=None,
drop_block_rate=None,
global_pool=None,
bn_tf=False,
bn_momentum=None,
bn_eps=None,
checkpoint_path=None)
我们发现加大模型,加大分辨率最多在b5上达到了96.5的结果,后面试了很多方法也没有提升:
(1)全部数据训练后,没啥提升;
(2)还使用了破坏-重建学习DCL网络,没提升;
(3)NIPS2020汤凯华新提出的De-confound TDE(训练时需要De-confound Training,说人话就是classifier需要使用multi-head normalized classifier),没啥提升;
(4)也试了随机SWA方法,波动大,效果也不行;
(5)试了超参数搜索,设置初始学习率和drop_rate两个参数,发现还是lr=0.001,drop_rate=0.1效果最好;
(6)分层学习率,特征提取部分学习率0.001,全连接层为0.01,效果也一般。
玄学炼丹
比赛结束前一天,试了最后一个trick,在96.5最好结果的预训练模型上训练全部数据,冻结特征提取层,仅跑全连接层,提交了第3个epoch的结果,因为它看着val_loss最低,val_acc还可以,然后结果出来96.64,炼丹大法最后一天终于有了可见的效果。
从第8到了第7,之前开始做的时候一路顺风一直到第4(96.5),然后就是温水煮青蛙,再上不去了,慢慢掉下来,最后又挣扎了一下。

最后是我们最好模型的val结果混淆矩阵分析:
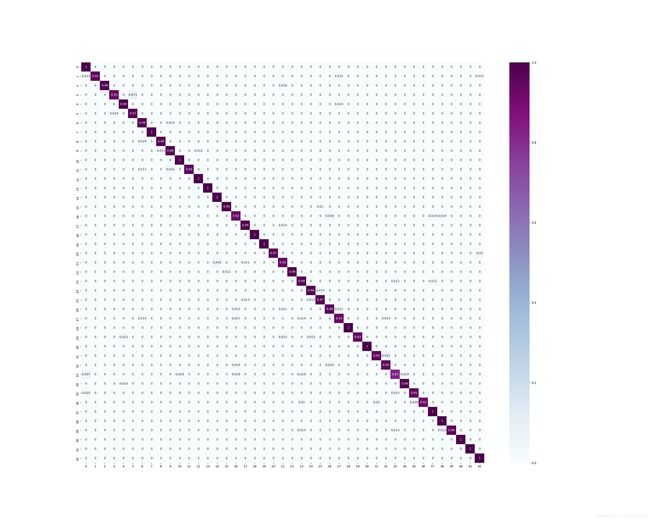 这个中间数字是对应类别的分类正确概率。
这个中间数字是对应类别的分类正确概率。
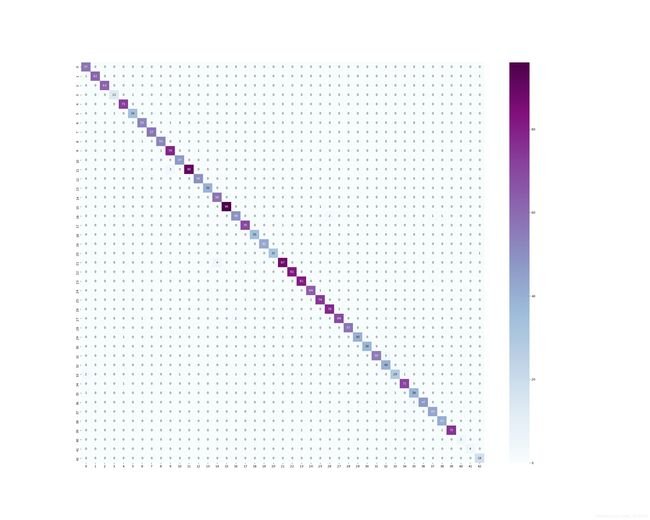 上面是对应类别的分类正确数量。
上面是对应类别的分类正确数量。
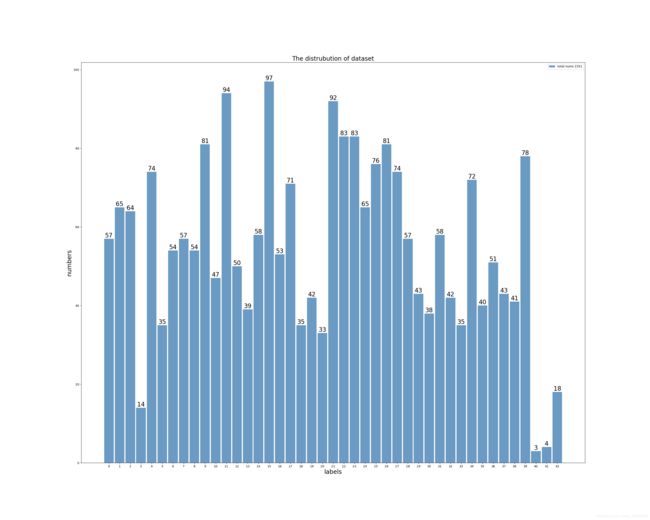 上面是val数据的类别分布。
上面是val数据的类别分布。
具体代码见github:
完整code
期待更多大佬方案。