【文末有惊喜!】Hive SQL血缘关系解析与应用


本文字数:7860字
预计阅读时间:20分钟
+
1 研究背景
随着企业信息化和业务的发展,数据资产日益庞大,数据仓库构建越来越复杂,在数仓构建的过程中,常遇到数据溯源困难,数据模型修改导致业务分析困难等难题,此类问题主要是由于数据血缘分析不足造成的,只有强化血缘关系,才能帮助企业更好的发挥数据价值。
SQL血缘关系是数据仓库模型构建的核心依赖。通过对SQL语句进行梳理与解析,得到各个业务层表之间依赖关系和属性依赖关系,并进行可视化展示,形成数据表和属性血缘层次关系图,充分展示了原始字段数据与数据模型的映射关系。拥有良好的SQL血缘关系系统,不仅有利于数据分析师对业务场景的梳理,还极大帮助对其数仓分层的构建,同时对企业数据质量控制方面起到很好的朔源作用,对构造数据链路图,监控数据变化起到很好的辅助作用。
市场存在一系列血缘关系解析工具,如Druids,但由于只支持对mysql语句的解析,且解析力度不够,不支持复杂的sql逻辑等问题,导致无法在企业中得到广泛使用。同样的hive自身的血缘解析往往在sql执行之后,才可得到解析结果,如果sql执行比较耗时,导致血缘关系无法快速展现,同时造成没有办法提前进行元数据安全和权限认证等问题,在企业真实应用中有一定的限制。
本文结合公司自身业务,研究Hive血缘关系解析源码,并进行优化,首先简化SQL语句剪枝和对包含CTE别名数据表的识别与剔除,降低SQL解析的复杂性,提高血缘解析性能;其次,提供元数据信息服务模块,既保证元信息的完整性,又提供安全的数据表权限认证,维护数据表的操作权限,保证操作的安全性;然后,将postExecuteHook前置,即在SQL执行物理优化前即可获得SQL 的血缘关系,极大提高了获取SQL血缘关系的效率,后续将对这些优化策略进行逐一展开。
+
2 相关技术介绍
2.1 SQL血缘关系介绍
在数据仓库构建的过程中,SQL血缘关系体现了各个数据表以及相关属性的依赖关系。SQL血缘关系即是对业务流程涉及到的模型表进行梳理,它包含了集群血缘关系、系统血缘关系、表级血缘关系和字段血缘关系,其指向数据的上游来源,向上游追根溯源。通过简单的SQL语句展现各个表之间的数据关系。
INSERT overwrite TABLE ads_shmm_wap_homepage_s3_nu_retention_1d_di PARTITION ( dt = $ { SYSTEM_BIZDATE }) SELECT a.source_first_id, a.source_second_id, a.source_third_id, b.vst_cookie FROM ( SELECT source_first_id, source_second_id, source_third_id, vst_cookie FROM ads_shmm_wap_homepage_s3_new_cookie_di WHERE dt = $ [ yyyyMMdd - 2 ] ) a JOIN ( SELECT vst_cookie FROM ads_shmm_wap_homepage_cookie_di WHERE dt = $ { SYSTEM_BIZDATE } ) b ON a.vst_cookie = b.vst_cookie; |
图2-1 业务SQL解析样例示意图
通过SQL血缘关系解析,得到的对应的血缘关系依赖图,如下图所示:
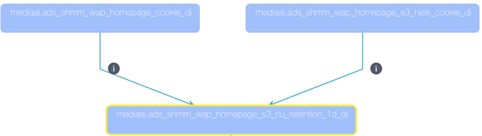
图2-2 数据表血缘关系依赖示意图
对应字段关系示意图如下所示:
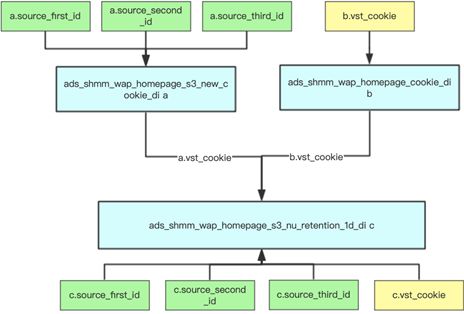
图2-2 数据表字段级别血缘关系依赖示意图
血缘关系一般是指表级和字段级,其能清晰展现数据加工处理逻辑脉络,快速定位数据异常字段影响范围,准确圈定最小范围数据回溯,降低了理解数据和解决数据问题的成本。同时数据血缘关系可与数据质量监控系统进行完美的整合,重要数据质量检测异常结果可通过数据血缘关系直接定位影响范围。
2.2 ANTLR技术介绍
Atlas是Apache开源的元数据治理方案。Hook执行中采集数据(如hivehook),发送Kafka,消费Kafka数据,生成Relation关系保存图数据库Titan,并提供REST接口查询功能,支持表血缘,列级支持不完善。
Durid虽在SQL解析中发挥很大的作用,但主要支持Mysql 语法,对Hive SQL仅仅是支持一些简单的操作。
Antlr作为一个强大的解释器,用来读取,处理,执行或翻译结构化文本或二进制文件。通过 Antlr可以构造出相应的词法分析器 (Lexer)、语法分析器 (Parser) 和树分析器 (TreeParser)。自动构建解析树的解析器,用于表示语法如何匹配输入的数据结构;自动生成树遍历器,遍历AST树的节点以执行特定于应用程序的代码。现通过ANTLR Works展示词法分析与语法分析的处理过程,举例如下:
insert into b SELECT c FROM a
经词法分析,识别字符串中单词,并对字符串进行分类,得到token集合,具体流程如下图所示:

图 2-3 SQL词法分析执行流程图
通过SQL词法分析,将SQL按照词法关键词进行匹配,并按照词性进行分组,最终组装成一个词法树,通过词法树,直观展示SQL中相关词所属的组,便于后续抽象语法树的形成。
词法分析之后,经语法分析得到对应抽象语法树,如下图所示:

图 2-4 SQL语法分析后AST抽象语法树
经过语法分析,初步将SQL分解成源表,目标表以及Query字段等组,已经初步形成SQL血缘脉络。
综上述词法分析与语法分析举例可知,词法分析将sql中涉及到所有词进行识别,并依据相关规则,需将所有的规则进行比对,并对字符串进行分组分类,初步得到词法分析树;语法分析,将Token集合简化,找出关键的TOK进行组装,更直观的反映出SQL的解析逻辑,tok_query,tok_select,tok_destination以及tok_tablename和tok_insert等,直观的反映出SQL中数据表的依赖关系。
查询语句和insert语句是Hive SQL的核心语句,由上述分析可得查询语句和insert语句语法结构相似,都具有相同的根节点TOK_QUERY,且都包括from数据源和tok_insert两部分,insert部分包含目的数据源、select和body等部分,简单归纳如下图所示。

图 2-5 通用的语法解析得到AST树形结构图
词法分析与语法分析之后,将遍历AST树,并进行语义分析。此外ANTLR提供了监听者模式和访问者模式。由于Visitor访问者模式是一种可以控制遍历方式的方式,并且可通过显示调用visit方法,完成对叶子节点的访问,使用者可选择性的主动遍历树,从而控制遍历的顺序,因此在血缘解析具有很好的灵活性,因此SQL血缘解析采用Visitor访问者模式完成对AST树的遍历。
2.3 Hive SQL解析流程介绍
通过以上对SQL解析关键过程的概述,现总结Hive SQL解析流程如下图所示:

图 2-6 Hive SQL解析流程图
由上图所示流程可知,HQL解析(生成AST语法树) => 语法分析(得到QueryBlock) => 生成逻辑执行计划(Operator) => 逻辑优化(LogicalOptimizer Operator) => 生成物理执行计划(TaskPlan) => 物理优化(Task Tree) => 构建执行计划(QueryPlan) => 执行引擎执行。
具体展开如下:
1、Hive根据Antlr定义的词法、语法规则完成词法、语法分析将HQL解析为AST Tree即抽象语法树;
2、深度遍历抽象语法树进行语义解析,得到相应的查询的基本组成单元Query Block;
AST Tree生成QueryBlock的过程是一个递归的过程,先序遍历AST Tree,遇到不同的Token节点,保存到相应的属性中,主要包含以下几个过程:
•TOK_QUERY =>创建QB对象,循环递归子节点
•TOK_FROM => 将表名语法部分保存到QB对象的aliasToTabs等属性中
• TOK_INSERT=> 循环递归子节点
•TOK_DESTINATION=> 将输出目标的语法部分保存在QBParseInfo对象的nameToDest属性中
• TOK_SELECT=> 分别将查询表达式的语法部分保存在destToSelExpr、destToAggregationExprs、destToDistinctFuncExprs三个属性中
• TOK_WHERE=> 将Where部分的语法保存在QBParseInfo对象的destToWhereExpr属性中
3、遍历Query Block,解析为操作树OperatorTree,生成逻辑执行计划;
4、逻辑优化器进行操作树变换,合并多余的ReduceSinkOperator,减少shuffle,即对应的列剪枝、分区剪枝以及join顺序优化等操作;
5、遍历Operator Tree,将操作树转变为对应的MapReduce任务,生成物理执行计划;
6、物理优化器进行MapReduce任务变换,针对最后生成DAG图进行优化,生成最终的执行计划。
7、逻辑计划执行;
通过以上对Hive SQL解析流程描述,血缘解析以此为基础进行展开。同时注意到传统Hive SQL解析流程相对比较繁琐,递归次数多,自定义函数无法识别,以及Hive Schema 不能支持企业级应用等问题,在血缘解析中进行调整与优化,充分支撑企业数仓级应用。
+
3 Hive SQL血缘关系解析
结合企业自身业务,对Hive SQL血缘关系解析流程进行了一下优化,具体流程如下图所示。
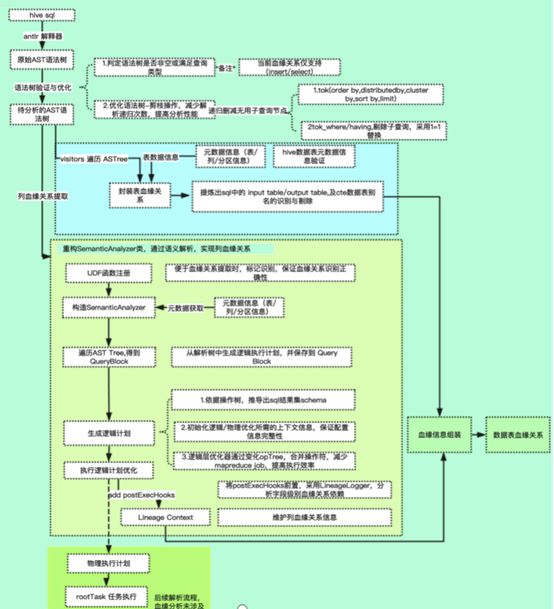
图3-1 Hive SQL血缘关系分析流程示意图
由上图所示,Hive SQL血缘关系解析主要包括表级别的血缘关系解析以及字段级别的血缘关系解析,并依赖元数据管理模块服务,完成了SQL血缘解析,先将从表级和字段级别分别对优化策略进行描述。
3.1 表级别血缘关系解析优化
表级别血缘解析是HIVE SQL解析的基础,通过SQL 快速定位到SQL语句中的源表和目标表以及相关条件,通过DAG图展示源表与目标表的关系。进一步直观展现数据表的流传。特别是在复杂的SQL 逻辑下,涉及到多张表部分数据的join、union等连接形式,通过DAG图展示给数据分析师或ETL数仓工程师,对企业数据仓库的构建以及数据监控起到重要支撑作用。
表级别血缘关系解析流程如下。
一、对Hive SQL进行词法分析和语法分析,获取对应的AST 原始的抽象语法树。
二、抽象语法树验证与优化;
1、语法树有效性验证,通过验证,辅助ETL工程师判定书写SQL的正确性;
2、AST语法树剪枝优化,减少遍历次数,提高语义解析的效率,具体主要做两方面的优化:
1)、针对token中涉及到的无效解析节点进行删除,如order by,distributedby,cluster by,sort by以及limit,代码如下:
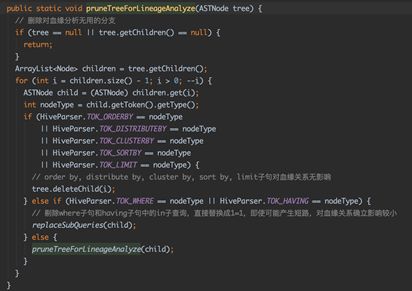
图3-2 语法树剪枝操作
2)、针对token_where/having的子查询,在保证SQL语法正确性以及语义完整性的前提下,采用1=1 等价策略进行等价替换,降低了血缘关系解析的复杂性;

图3-3 语法树剪枝操作-替换策略
通过以上两种剪枝操作,既可以减少SQL语句的复杂性,又可以降低AST语法树的层级,进一步减少了遍历AST树递归次数,降低血缘分析的复杂性,提高了语句解析效率;
三、遍历AST获取上游表名(TOK_TAB)和下游表名(TOK_TABREF),在SQL语句中存在大部分SQL语句片段即CTE。由于其在血缘关系解析中不起关键作用,且对SQL解析带来很大困扰,因此血缘关系解析需对cte类型进行识别,并进行替换与删除,具体代码如下。
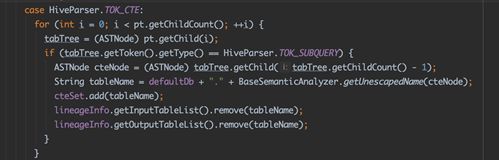
图3-4 SQL中CTE数据表别名的识别
以上是hiveSQL对表级别的血缘关系梳理。通过表血缘关系梳理,直观地展示出了ETL业务中各层数据表的流转,便于ETL工程师或数据分析师清楚的看到一张表的上下游,更方便地查找表关系,对ETL数据仓库的构建起到很好的辅助作用。
3.2 字段级别血缘关系解析优化
字段级别的血缘关系梳理是Hive解析中具有重要环节,并支撑血缘关系DAG的核心作用。
1、有利于数据分析师回溯数据问题。数据表由ods层流转到did层后,通过对比结果差异很大,需要人工核对分析指标纬度信息,如数据指标来源,经过哪些清洗条件或逻辑,进而找出相应的处理问题;
2、有利于报表分析问题的排查。基础表由于字段类型的改变或精度的改变,需要评估对数仓的影响,通过血缘可以快速定位原始字段和目标字段的数据,便于分析师及时调整处理策略。
3、有利于数据质控阶段监控数据质量变化。如数据表的字段的空值率,重复率以及是否满足数据逻辑率等方面快速监控ods数据质量问题,并及时反馈给应用层,进行数据问题的排查。在数据风控环节,某一个手机设备访问率呈现指数型增加,并不断刷去金币,以达到套现目的。针对此问题通过字段血缘可以快速企业业务场景,反馈给后台应用研发,达到快速对问题排查的能力。
字段级别血缘解析贯穿到HIVE SQL语义解析之后,结合企业数仓应用的需求,如需支持UDF自定义函数解析,丰富Hive元数据信息,Hive 数据表等权限认证,支持Hook监听策略等需求进行改进,具体改进方式如下:
一、注册UDF自定义函数,便于血缘关系提取时,标记识别特殊函数,保证血缘关系解析的准确性,代码注册如下;

图3-5 udf函数注册
二、重构SemanticAnalyzer,重写SQL解析主要逻辑。SemanticAnalyzer类作为 hive SQL 解析的核心工具类,用于遍历AST树,并将其转化为Query Block。然而血缘关系解析时,需要元数据管理模块获取数据表的基本信息如表信息以及字段信息,以及数据表验证,表与字段信息的填充,因此为方便对血缘关系的梳理,特重构SemanticAnalyzer 类并继承BaseSemanticAnalyzer类型,完善对列字段血缘关系的提取;
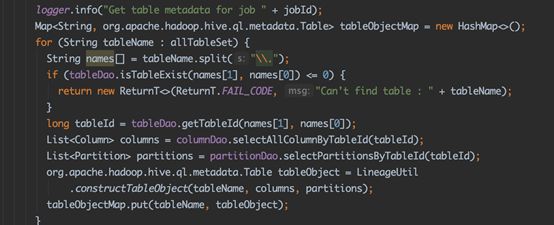
图3-6 数据表元数据信息获取
三、逻辑计划生成和逻辑计划优化,此过程主要依据操作树,推到出结果集schema,并初始化逻辑计划和物理计划依赖的配置信息,保证血缘关系分析的基础配置信息的完整性,同时对操作树进行优化,合并操作符,减少mapreduce job的stage 数量,提高血缘关系解析的执行效率;
四、Hive 血缘解析会涉及到getMetaData()方法对元数据信息的提取来完善解析,血缘解析中采用公司自研的hive元数据管理模块,替代默认的元数据模块,提供更完整的元数据信息。
元数据管理模块hive架构中主要组成部分,然而hive自身的元数据存在一定的局限性,如数据表的生命周期控制,数据表的权限控制等模块的缺乏,导致数据管理模块并没有发挥其核心价值,通过对企业相关的元管理模块梳理与参考,发现缺少对应血缘关系的支持,导致元数据模块相对比较薄弱,并且对元数据模块的应用需要模糊,仅仅提供元信息的保存,并没有在企业级应用中发挥重要作用。
为了能够在血缘解析中对元数据管理模块的支撑,形成元数据与血缘关系做到有机的结合。采用自主研发的元数据信息服务,不仅提供完整的Hive Schema信息,而且维护完整的数据表权限认证,同时,保证了SQL执行时数据的安全性。
血缘关系解析中,采用单独封装getTableSpec方法实现了元数据信息的切换,通过其方法获取相关hive表Schema,分区信息以及表权限信息。

图3-7 切换自研的元数据信息服务,保证数据表操作的安全性
Hooks 是一种事件和消息机制,可以将事件绑定在内部 Hive 的执行流程中,用于k监听Hive的各种事件,如表创建,更新等操作,通过对postExecHook 的配置与调用,可以hive 列级别血缘管理封装到LineageContext中。
五、添加postExecHook,执行LineageLogger获得LineageContext. 在血缘关系解析中,将此步骤前置到执行逻辑计划之后,由LineageLogger类调用执行SQL逻辑计划,获取到字段级别的血缘信息封装到Lineage Context中。
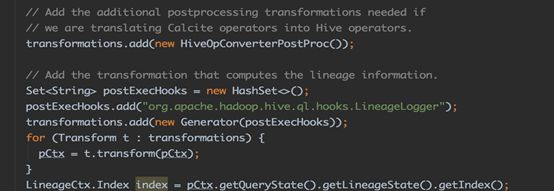
图3-8 Hook函数使用
六、读取LineageContext信息,组装数据表与字段血缘关系信息。通过对AST树进行血缘解析之后,具体的字段血缘信息存储LineageContext中,通过得LineageContext的索引对象,便可获取列字段血缘关系,通过LineageContext.index信息,将源头和目标用向量连接起来,形成列字段边信息,同时将各个边的节点连接起来,形成列的有向五环图。具体代码如下:

图3-9 血缘关系信息“边”与“节点”信息封装
七、结合具体应用,将表级别和字段级别的血缘关系信息进行组装得到表血缘关系。并存储在元数据管理模块中,便于更好的追溯表结构信息。
血缘关系整合之后,存入数据表中,具体展开如下所示:

图3-10 血缘关系存储结构图
应用层展示Hive SQL血缘关系如下:
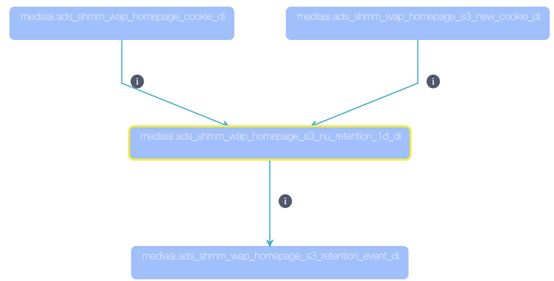
图3-11 血缘依赖关系展示图
+
4 血缘关系总结与展望
本文主要介绍Hive SQL血缘关系解析流程的整体介绍,针对固有的SQL 解析进行优化,最后得到表级别的血缘关系信息以及字段级别的血缘关系信息,并针对此两部分血缘信息进行组装,然后得到整体的血缘信息,并在元数据管理模块中进行可视化展示。
通过对Hive SQL血缘关系工具开发,并成功应用到企业内部数据资产管理哦平台中。通过其在企业数据仓库中的应用,充分满足企业业务需求,给数据组同事带来很大的遍历。
通过对SQL血缘关系构建,具有一下核心意义:
第一,形成完成数据流向DAG图,便于数据问题溯源,便于对数据问题的排查;
第二,将血缘关系融入到hive元数据管理模块,在SQL执行中,充分将元数据权限控制应用到血缘解析中,保证数据的完整性和安全性;
第三,通过血缘关系,在数据质量监控方面带来极大的便利。通过企业监控平台,针对数据完整性,数据字段空值率,重复率以及不满足逻辑率等问题进行快速感知,并及时进行处理,辅助对问题的及时排查,保证企业业务正常顺利的执行。
当前企业资产管理平台支持数据组同事根据输入的业务sql,完成了相关sql的血缘关系梳理和入库,并可视化展现在元数据管理模块中,唯一不足的是目前血缘关系展现主要展示数据表之间的关系,字段级别的血缘目前只是存储在血缘关系表中。
通过血缘关系梳理,做到企业数据可溯源,挖掘企业数据价值,同时对数据质量得到很好的评估。
本期赠书
《Java多线程与大数据处理实战》
李建平 著

《Java多线程与大数据处理实战》对 Java 的多线程及主流大数据中间件对数据的处理进行了较为详细的讲解。本书主要讲了 Java 的线程创建方法和线程的生命周期,方便我们管理多线程的线程组和线程池,设置线程的优先级,设置守护线程,学习多线程的并发、同步和异步操作,了解 Java 的多线程并发处理工具(如信号量、多线程计数器)等内容。
活动参与方式:留言点赞数前三名的同学各获赠书一本
获奖公布时间及位置:12月10日头条推送文末
特别提醒:兑奖截止至12月17日,请参与读者及时兑奖~




加入搜狐技术作者天团
千元稿费等你来!
???? 戳这里!
也许你还想看
(▼点击文章标题或封面查看)
【周年福利Round4】史诗级java低时延调优案例一
2020-08-27

全面详细的java线程池解密,看我就够了!
2020-09-03

【文末有惊喜!】Spring Boot核心原理实现及核心注解类
2020-07-23

ELK日常使用基础篇
2020-06-18

Java多线程并发读写锁ReadWriteLock实现原理剖析
2020-02-20
