三十四、Hive常用的函数
本文主要介绍Hive中常用的函数,总体来说分为两部分,分别是Hive自带的函数和自定义的函数。关注专栏《破茧成蝶——大数据篇》,查看更多相关的内容~
目录
一、Hive自带的函数
1.1 CASE WHEN函数
1.2 NVL函数
1.3 行转列与列转行
1.3.1 行转列
1.3.2 列转行
1.4 窗口函数
1.5 rank函数
二、自定义函数
2.1 需求说明
2.2 代码实现
2.3 测试
一、Hive自带的函数
首先我们来看下Hive中内置了哪些函数,在命令行通过以下命令查看Hive内置的函数:
show functions;会列出很多内置的函数,这里就不截图了。对于某个内置的函数,我们可以使用如下命令查看它的用法,以sum函数为例:
desc function sum;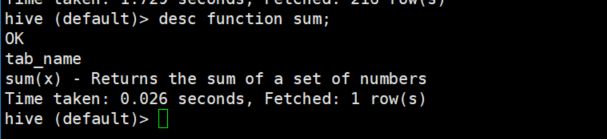
使用如下命令查看对应函数的详细用法,还是以sum函数为例:
desc function extended sum;
下面来具体看几个比较实用却略微有点复杂的内置函数。
1.1 CASE WHEN函数
还是以咱们之前的people表为例吧,现在需要将女性的性别字段以“女”显示,男性的性别字段以“男”显示。数据如下:

实现方式为:
select p.id, p.name, case when p.sex = 'f' then '女' when p.sex = 'm' then '男' else '非人类' end sex from people p;
1.2 NVL函数
NVL函数的作用是给值为NULL的数据赋值,它的格式是NVL( value,new_value)。它的功能是如果value为NULL,则NVL函数返回new_value的值,否则返回value的值,如果两个参数都为NULL ,则返回NULL。来看下例:
select t.name, nvl(t2.fav, '无') from people t left join favorite t2 on t.name = t2.name;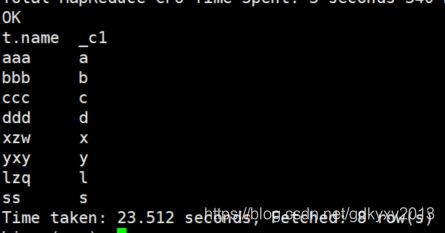
1.3 行转列与列转行
行转列与列转行可以说是在数据分析中很常用的操作了,下表是相关的函数,可以参考我的另外一篇文章:《Hive中的explode()函数和collect_set()函数》。
| 函数名称 | 说明 |
|---|---|
| CONCAT(col1, col2, ...) | 返回输入字符串连接后的结果,支持多个输入字符串。 |
| CONCAT_WS(separator, str1, str2,...) | 它是一个特殊形式的CONCAT()。第一个参数指定剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间。 |
| COLLECT_SET(col) | 函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。 |
| EXPLODE(col) | 将Hive一列中复杂的array或者map结构拆分成多行。 |
| LATERAL VIEW | LATERAL VIEW udtf(expression) tableAlias AS columnAlias。和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。 |
这样看,比较抽象,我们可以用几个例子来看一下到底是怎么应用的。
1.3.1 行转列
1、构造数据:名称、部门、职位。如下所示:

2、创建Hive表并加载数据
create table dept_info(
name string,
dept string,
pos string)
row format delimited fields terminated by ",";
load data local inpath "/root/files/emp.txt" into table dept_info;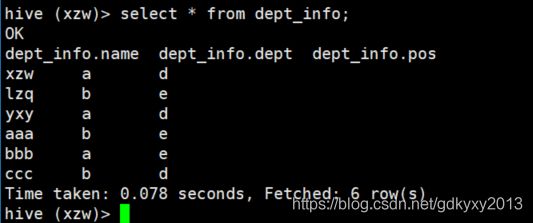
3、将部门和职位相同的人放到一行
select
t.dp,
concat_ws('|', collect_set(t.name)) name
from
(select
name,
concat(dept, ",", pos) dp
from
dept_info) t
group by
t.dp;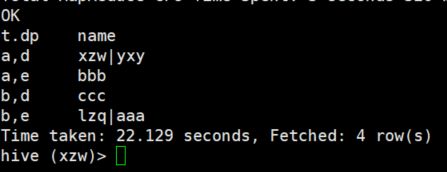
1.3.2 列转行
1、构造数据:数据一共两列,分别是姓名以及擅长的编程语言。如下所示:
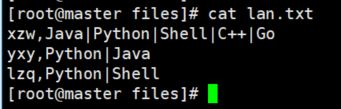
2、建表并导入语句
create table dept_lan(
name string,
lan array)
row format delimited fields terminated by ","
collection items terminated by "|";
load data local inpath "/root/files/lan.txt" into table dept_lan;

3、将编程语言的数据展开
select
name,
lan,
lan_name
from
dept_lan lateral view explode(lan) tmp as lan_name;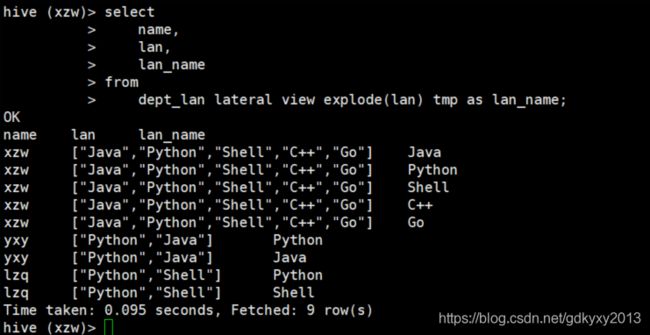
1.4 窗口函数
窗口函数相关函数说明如下:
| 函数名称 | 说明 |
|---|---|
| OVER() | 指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化。 |
| CURRENT ROW | 当前行 |
| n PRECEDING | 往前n行数据 |
| n FOLLOWING | 往后n行数据 |
| UNBOUNDED | 起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点。 |
| LAG(col,n,default_val) | 往前第n行数据 |
| LEAD(col,n, default_val) | 往后第n行数据 |
| NTILE(n) | 把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。 |
窗口函数在Hive中是比较重要的函数,用途也非常广泛,下面我们根据几个例子来看下窗口函数具体是怎么应用的。
1、首先还是先构造一部分测试数据吧,数据分为三列,分别是姓名、日期以及消费金额,数据为某超市的消费数据,如下所示。
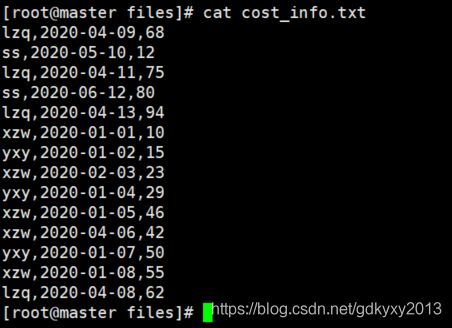
2、创建Hive表并导入数据
--创建表
create table cost_info(
name string,
rq string,
cost int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
--加载数据
load data local inpath "/root/files/cost_info.txt" into table cost_info;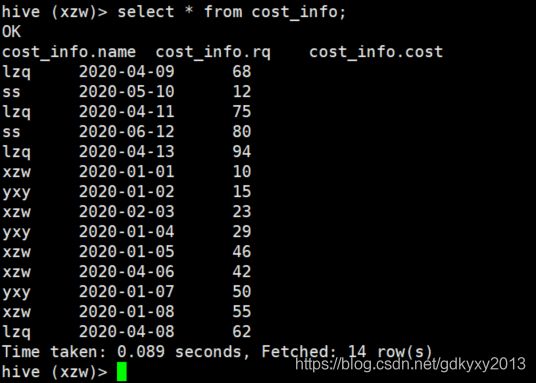
3、查询2020年1月份购买过的顾客及总人数
select name,count(*) over()
from cost_info
where substring(rq,1,7) = '2020-01'
group by name;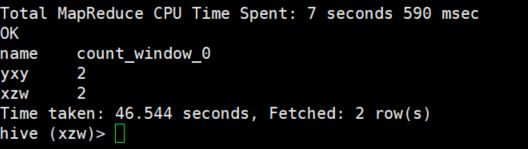
4、查询消费者的购买明细以及每月的购买总额
select name,rq,cost,sum(cost) over(partition by substring(rq,1,7)) from cost_info;
5、查询消费者购买明细以及按照下述要求的金额累加
select name,rq,cost,
--所有行相加
sum(cost) over() as col1,
--按name分组,组内数据相加
sum(cost) over(partition by name) as col2,
--按name分组,组内数据按照日期依次累加
sum(cost) over(partition by name order by rq) as col3,
--效果同col3
sum(cost) over(partition by name order by rq rows between UNBOUNDED PRECEDING and current row ) as col4,
--当前行和前面一行求和
sum(cost) over(partition by name order by rq rows between 1 PRECEDING and current row) as col5,
--当前行和前边一行及后面一行求和
sum(cost) over(partition by name order by rq rows between 1 PRECEDING AND 1 FOLLOWING ) as col6,
--当前行及后面所有行累加
sum(cost) over(partition by name order by rq rows between current row and UNBOUNDED FOLLOWING ) as col7
from cost_info;
6、查询消费者前一次和前两次的消费金额,如果没有消费,默认0元。
select name,rq,cost,
lag(cost,1,'0') over (partition by name order by rq) as c1, lag(cost,2,'0') over (partition by name order by rq) as c2
from cost_info;
7、按照时间排序,查询前50%的时间信息
select * from (
select name,rq,cost, ntile(2) over(order by rq) px
from cost_info
) t
where px = 1;
1.5 rank函数
函数说明如下:
| 函数名称 | 说明 |
|---|---|
| rank() | 排序相同时会重复,总数不会变。 |
| dense_rank() | 排序相同时会重复,总数会减少。 |
| row_number() | 会根据顺序进行计算。 |
我们通过一个例子来看一下rank()函数的具体应用。
1、构造数据:数据分为三列,分别是姓名、编程语言以及编程语言的期望值。如下所示:

2、创建Hive表并导入数据
create table dept_exp(
name string,
lan string,
exp int)
row format delimited fields terminated by ",";
load data local inpath '/root/files/bc.txt' into table dept_exp;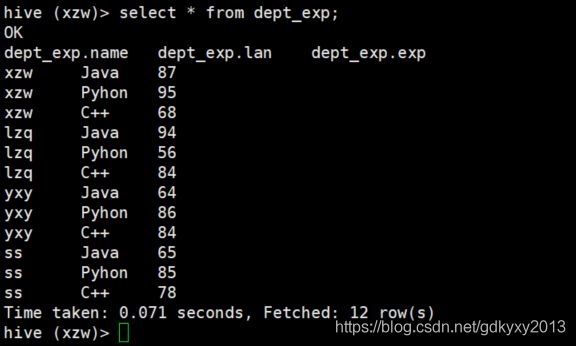
3、计算每一门编程语言的期望值排名
select name,
lan,
exp,
rank() over(partition by lan order by exp desc) r,
dense_rank() over(partition by lan order by exp desc) dr,
row_number() over(partition by lan order by exp desc) rn
from dept_exp;
二、自定义函数
当Hive提供的内置函数无法满足业务处理需要时,就可以考虑使用用户自定义函数(UDF:user-defined function)。这里以一个例子为例来说明怎样通过代码的方式自定义函数。
2.1 需求说明
现在需要实现以下功能:将传进来的字符串转换为小写。
2.2 代码实现
1、首先需要新建一个maven项目,并配置相应的pom.xml文件,如下:
org.apache.hive
hive-exec
1.2.1
2、编码实现相应的功能,这里需要注意的是,代码中需要有evaluate()方法,Hive自定义函数调用的是这个方法。
package com.xzw.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* @author: xzw
* @create_date: 2020/12/20 11:05
* @desc: 将字符串转换为小写
* @modifier:
* @modified_date:
* @desc:
*/
public class Lower extends UDF {
/**
* 执行计算的方法
* @param orig 原始字符串
* @return 返回转换为小写的字符串
*/
public String evaluate(String orig) {
if (null == orig)
return null;
return orig.toLowerCase();
}
public static void main(String[] args) {
}
}
3、打包上传。具体的打包方式可以参考咱们之前在《九、Hadoop核心组件之MapReduce》中介绍的。
2.3 测试
测试自定义的UDF函数,我们分两种情况来说明。
1、如果jar包上传的目录为Hive安装目录的lib下,此处我们的路径为:/opt/modules/hive/lib。此时进入hive命令行执行如下操作:
(1)创建临时函数与上传的jar包进行关联
create temporary function hive_lower as "com.xzw.hive.Lower";(2)使用自定义的UDF函数
select lan, hive_lower(lan) from dept_exp;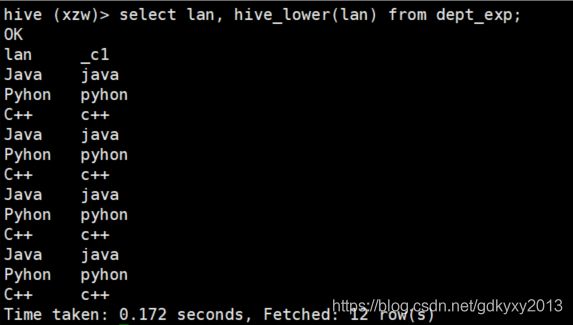
2、如果jar包并没有上传到Hive安装目录的lib下,那么在执行上述两步操作之前,需要先将jar添加到hive的classpath,命令如下:
add jar /root/files/hive-lower.jar;
至此,本文就讲解完了,你们在这个过程中遇到了什么问题,欢迎留言,让我看看你们遇到了什么问题~