二、TensorFlow2.x 基于图像的分类
本文使用tf.keras对服装、运动鞋图像进行分类,训练一个神经网络模型。tf.keras是TensorFlow中用来构建和训练模型的高级API。详细内容会在下面实际操作中展开介绍,一起来看看吧。关注专栏《一起来学TensorFlow2.x》,解锁更多相关内容~
目录
一、数据集准备
1.1 数据描述与加载
1.2 查看数据
二、数据预处理
2.1 查看某图像
2.2 归一化处理
三、构建模型
3.1 设置模型的层
3.1.1 tf.keras.layers.Flatten层
3.1.2 keras.layers.Dense层
3.2 编译模型
3.2.1 keras.losses.SparseCategoricalCrossentropy类
3.2.2 model.compile()方法
四、训练模型
4.1 训练模型
4.1.1 model.fit()方法
4.2 评估准确率
4.2.1 model.evaluate()方法
4.3 预测
4.3.1 tf.keras.layers.Softmax()层
4.3.2 tf.keras.Sequential()类
4.3.3 predict()预测方法
4.3.4 绘图查看并验证预测结果
五、使用模型
一、数据集准备
1.1 数据描述与加载
这里我们使用Fashion MNIST数据集,该数据集包含10个类别的70000个灰度图像,这些图像以低分辨率(28x28像素)展示了单件衣物。Fashion MNIST数据集相对较小,非常方便代码的测试和调试。其中Fashion MNIST数据集的GitHub地址请戳这里,衣物的部分灰度图像如下所示:

我们首先需要做的是加载Fashion MNIST数据集:
1、测试之前需要首先导入需要的库,如下所示:
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt2、加载数据集
# 1.1 数据描述与加载
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()数据集会返回四个NumPy数组,train_images和train_labels数组是训练集图像和训练集标签,即模型用于学习的数据。test_images和test_labels数组是测试集的图像和测试集的标签,会被用来对模型进行测试。
1.2 查看数据
1、首先我们来查看一下数据的格式,通过以下代码打印出数据的shape:
print(train_images.shape, len(train_labels), test_images.shape, len(test_images))
通过上图发现训练集中有60000个图像,每个图像由28x28的像素表示,对应的训练集中有60000个标签。测试集中有10000个图像,每个图像都由28x28个像素表示,对应的测试集包含10000个图像标签。
2、通过以下代码我们打印训练集的第一个图像以及训练集的标签进行查看:
print(train_images[0], '\n', train_labels)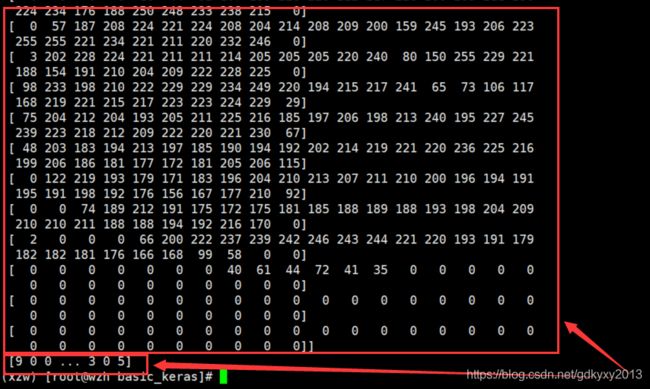
通过上图可以发现图像是28x28的NumPy数组,像素值介于0到255之间。标签是整数数组,介于0到9之间。下表给出了这些标签对应于图像所代表的服装类:
| 标签 | 类 |
|---|---|
| 0 | T恤/上衣 |
| 1 | 裤子 |
| 2 | 套头衫 |
| 3 | 连衣裙 |
| 4 | 外套 |
| 5 | 凉鞋 |
| 6 | 衬衫 |
| 7 | 运动鞋 |
| 8 | 包 |
| 9 | 短靴 |
每个图像都会被映射到一个标签。由于数据集不包含类名称,于是下方我们定义了类名称,以供稍后绘制图像时使用:
# 类别名称
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
二、数据预处理
2.1 查看某图像
在构建模型、训练网络之前,必须对数据进行预处理。我们可以使用matplotlib库查看某个图像:
# 查看某个图像,发现像素值处于0-255之间
plt.figure()
plt.imshow(train_images[0])
plt.grid(False)
plt.show()
2.2 归一化处理
因为图像的像素值都是处于0-255之间,所以我们需要对其进行归一化处理,然后将其送到神经网络模型中。因此,我们需要将这些值除以255。
train_images, test_images = train_images / 255, test_images / 255为了验证归一化之后的数据是否正确,我们显示其中的25个图像进行查看:
# 显示一部分数据查看数据格式是否正确
plt.figure(figsize=(10, 10))
for i in range(25):
plt.subplot(5, 5, i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()其中,plt.subplot()指的是在当前图像上添加一个子图,上面代码中的意思是当前图像分为五行五列,当前位置是i+1。plt.xticks()是获取或设置x轴的当前刻度位置和标签。plt.yticks()是获取或设置y轴的当前刻度位置和标签。plt.grid(False)表示显示网格线,1=True=默认显示;0=False=不显示,此处设置的为不显示。plt.imshow()用于实现热图绘制。plt.xlabel()用于设置x轴的标签。

这图像看不大清楚,没办法,CentOS的图形界面毕竟不是本地的系统,有部分还是能看出来的,大家将就着看吧,我真的尽力了,此处手动捂脸哭三次。
三、构建模型
构建神经网络需要先配置模型的层,然后再编译模型。
3.1 设置模型的层
神经网络的基本组成部分是层,层会从向其传送的数据中提取表示形式。大多数深度学习都包括将简单的层链接在一起。大多数层(如 tf.keras.layers.Dense)都具有在训练期间才会学习的参数。通过下面的代码设置模型的层:
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10)
])3.1.1 tf.keras.layers.Flatten层
tf.keras.layers.Flatten层的作用是将输入的inputs展平,简单来说就是变形,它不会影响batch的大小。如果输入的形状是没有特征轴的,例如:(batch, )。则经过tf.keras.layers.Flatten层展平后会增加一个维度,即输出的形状是(batch, 1)。其源码如下所示:
@keras_export('keras.layers.Flatten')
class Flatten(Layer):
def __init__(self, data_format=None, **kwargs):
super(Flatten, self).__init__(**kwargs)
self.data_format = conv_utils.normalize_data_format(data_format)
self.input_spec = InputSpec(min_ndim=1)
self._channels_first = self.data_format == 'channels_first'
def call(self, inputs):
if self._channels_first:
rank = inputs.shape.rank
if rank and rank > 1:
# Switch to channels-last format.
permutation = [0]
permutation.extend(range(2, rank))
permutation.append(1)
inputs = array_ops.transpose(inputs, perm=permutation)
if context.executing_eagerly():
# Full static shape is guaranteed to be available.
# Performance: Using `constant_op` is much faster than passing a list.
flattened_shape = constant_op.constant([inputs.shape[0], -1])
return gen_array_ops.reshape(inputs, flattened_shape)
else:
input_shape = inputs.shape
rank = input_shape.rank
if rank == 1:
return array_ops.expand_dims_v2(inputs, axis=1)
else:
batch_dim = tensor_shape.dimension_value(input_shape[0])
non_batch_dims = input_shape[1:]
# Reshape in a way that preserves as much shape info as possible.
if non_batch_dims.is_fully_defined():
last_dim = int(functools.reduce(operator.mul, non_batch_dims))
flattened_shape = constant_op.constant([-1, last_dim])
elif batch_dim is not None:
flattened_shape = constant_op.constant([int(batch_dim), -1])
else:
flattened_shape = [array_ops.shape_v2(inputs)[0], -1]
return array_ops.reshape(inputs, flattened_shape)
def compute_output_shape(self, input_shape):
input_shape = tensor_shape.TensorShape(input_shape).as_list()
if not input_shape:
output_shape = tensor_shape.TensorShape([1])
else:
output_shape = [input_shape[0]]
if np.all(input_shape[1:]):
output_shape += [np.prod(input_shape[1:], dtype=int)]
else:
output_shape += [None]
return tensor_shape.TensorShape(output_shape)
def get_config(self):
config = super(Flatten, self).get_config()
config.update({'data_format': self.data_format})
return config所以,此处keras.layers.Flatten(input_shape=(28, 28))是将图像格式从二维数组(28x28像素)转换成一维数组(28x28=784像素)。将该层视为图像中未堆叠的像素行并将其排列起来,该层没有要学习的参数,它只会重新格式化数据。
3.1.2 keras.layers.Dense层
keras.layers.Dense层是神经网络中的连接层,其源码如下:
@keras_export('keras.layers.Dense')
class Dense(Layer):
def __init__(self,
units,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs):
super(Dense, self).__init__(
activity_regularizer=activity_regularizer, **kwargs)
self.units = int(units) if not isinstance(units, int) else units
self.activation = activations.get(activation)
self.use_bias = use_bias
self.kernel_initializer = initializers.get(kernel_initializer)
self.bias_initializer = initializers.get(bias_initializer)
self.kernel_regularizer = regularizers.get(kernel_regularizer)
self.bias_regularizer = regularizers.get(bias_regularizer)
self.kernel_constraint = constraints.get(kernel_constraint)
self.bias_constraint = constraints.get(bias_constraint)
self.input_spec = InputSpec(min_ndim=2)
self.supports_masking = True
def build(self, input_shape):
dtype = dtypes.as_dtype(self.dtype or K.floatx())
if not (dtype.is_floating or dtype.is_complex):
raise TypeError('Unable to build `Dense` layer with non-floating point '
'dtype %s' % (dtype,))
input_shape = tensor_shape.TensorShape(input_shape)
last_dim = tensor_shape.dimension_value(input_shape[-1])
if last_dim is None:
raise ValueError('The last dimension of the inputs to `Dense` '
'should be defined. Found `None`.')
self.input_spec = InputSpec(min_ndim=2, axes={-1: last_dim})
self.kernel = self.add_weight(
'kernel',
shape=[last_dim, self.units],
initializer=self.kernel_initializer,
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint,
dtype=self.dtype,
trainable=True)
if self.use_bias:
self.bias = self.add_weight(
'bias',
shape=[self.units,],
initializer=self.bias_initializer,
regularizer=self.bias_regularizer,
constraint=self.bias_constraint,
dtype=self.dtype,
trainable=True)
else:
self.bias = None
self.built = True
def call(self, inputs):
return core_ops.dense(
inputs,
self.kernel,
self.bias,
self.activation,
dtype=self._compute_dtype_object)
def compute_output_shape(self, input_shape):
input_shape = tensor_shape.TensorShape(input_shape)
input_shape = input_shape.with_rank_at_least(2)
if tensor_shape.dimension_value(input_shape[-1]) is None:
raise ValueError(
'The innermost dimension of input_shape must be defined, but saw: %s'
% input_shape)
return input_shape[:-1].concatenate(self.units)
def get_config(self):
config = super(Dense, self).get_config()
config.update({
'units':
self.units,
'activation':
activations.serialize(self.activation),
'use_bias':
self.use_bias,
'kernel_initializer':
initializers.serialize(self.kernel_initializer),
'bias_initializer':
initializers.serialize(self.bias_initializer),
'kernel_regularizer':
regularizers.serialize(self.kernel_regularizer),
'bias_regularizer':
regularizers.serialize(self.bias_regularizer),
'activity_regularizer':
regularizers.serialize(self.activity_regularizer),
'kernel_constraint':
constraints.serialize(self.kernel_constraint),
'bias_constraint':
constraints.serialize(self.bias_constraint)
})
return config其输入参数解释如下:
1、units:输出空间的维数,正整数。
2、activation: 要使用的激活函数,如果为None则表示不适用任何激活函数。
3、use_bias: 布尔值,层是否使用偏差矢量。
4、kernel_initializer: 初始化内核权重矩阵。
5、bias_initializer: 初始化偏差向量。
6、kernel_regularizer: 正则化函数应用于内核权重矩阵。
7、bias_regularizer: 正则化函数应用于偏差向量。
8、activity_regularizer: 正则化函数应用于层的输出。
9、kernel_constraint: 约束函数应用于内核权重矩阵。
10、bias_constraint: 约束函数应用于偏差向量。
所以,此处模型设置层中keras.layers.Dense(128, activation='relu')表示展平像素后,Dense层有128个节点(或神经元),keras.layers.Dense(10)表示返回一个长度为10的logits数组。每个节点都包含一个得分,用来表示当前图像属于10个类中的哪一类。
3.2 编译模型
在准备对模型进行训练之前,还需要再对其进行一些设置,例如:损失函数、优化器、指标等等。其中,损失函数用于测量模型在训练期间的准确率。优化器决定模型如何根据其看到的数据和自身的损失函数进行更新。指标用于监控训练和测试步骤,下面的代码中使用了准确率作为指标,即被正确分类的图像比率。
model.compile(optimizer='adam',
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])3.2.1 keras.losses.SparseCategoricalCrossentropy类
keras.losses.SparseCategoricalCrossentropy类主要的作用是用于计算计算标签和预测之间的交叉熵损失。当有两个或多个标签类别时,可以使用此交叉熵损失函数,标签需要以整数形式提供。 如果使用独热编码提供标签,需要使用CategoricalCrossentropy损失。其源码如下:
@keras_export('keras.losses.SparseCategoricalCrossentropy')
class SparseCategoricalCrossentropy(LossFunctionWrapper):
def __init__(self,
from_logits=False,
reduction=losses_utils.ReductionV2.AUTO,
name='sparse_categorical_crossentropy'):
super(SparseCategoricalCrossentropy, self).__init__(
sparse_categorical_crossentropy,
name=name,
reduction=reduction,
from_logits=from_logits)其默认参数解释如下:
1、from_logits参数用来指定预测值y_pred是否是对数张量。默认情况下,假设y_pred是一个概率值。使用from_logits=True可能在数值上更稳定。
2、reduction参数用来指定适用于损失的“tf.keras.losses.Reduction”类型,默认值是“AUTO”。“AUTO”表示reduction参数将由使用情况决定,在大多数情况下,该默认值均为“SUM_OVER_BATCH_SIZE”。
3、name参数用来指定操作的可选名称,默认是“sparse_categorical_crossentropy”。
上面指定的sparse_categorical_crossentropy方法是用于计算稀疏的分类交叉熵损失,其具体实现过程如下所示:
@keras_export('keras.metrics.sparse_categorical_crossentropy',
'keras.losses.sparse_categorical_crossentropy')
@dispatch.add_dispatch_support
def sparse_categorical_crossentropy(y_true, y_pred, from_logits=False, axis=-1):
y_pred = ops.convert_to_tensor_v2_with_dispatch(y_pred)
y_true = math_ops.cast(y_true, y_pred.dtype)
return K.sparse_categorical_crossentropy(
y_true, y_pred, from_logits=from_logits, axis=axis)3.2.2 model.compile()方法
model.compile()方法用于配置训练的模型,其实现方法如下所示:
def compile(self,
optimizer='rmsprop',
loss=None,
metrics=None,
loss_weights=None,
weighted_metrics=None,
run_eagerly=None,
steps_per_execution=None,
**kwargs):
base_layer.keras_api_gauge.get_cell('compile').set(True)
with self.distribute_strategy.scope():
if 'experimental_steps_per_execution' in kwargs:
logging.warn('The argument `steps_per_execution` is no longer '
'experimental. Pass `steps_per_execution` instead of '
'`experimental_steps_per_execution`.')
if not steps_per_execution:
steps_per_execution = kwargs.pop('experimental_steps_per_execution')
self._validate_compile(optimizer, metrics, **kwargs)
self._run_eagerly = run_eagerly
self.optimizer = self._get_optimizer(optimizer)
self.compiled_loss = compile_utils.LossesContainer(
loss, loss_weights, output_names=self.output_names)
self.compiled_metrics = compile_utils.MetricsContainer(
metrics, weighted_metrics, output_names=self.output_names)
self._configure_steps_per_execution(steps_per_execution or 1)
# Initializes attrs that are reset each time `compile` is called.
self._reset_compile_cache()
self._is_compiled = True
self.loss = loss or {} # Backwards compat.model.compile()方法的相关参数释义如下:
1、optimizer:字符串(优化程序的名称)或优化程序实例。在tf.keras.optimizers中可以发现主要有以下几种类型:
from tensorflow.python.keras.optimizer_v2.adadelta import Adadelta
from tensorflow.python.keras.optimizer_v2.adagrad import Adagrad
from tensorflow.python.keras.optimizer_v2.adam import Adam
from tensorflow.python.keras.optimizer_v2.adamax import Adamax
from tensorflow.python.keras.optimizer_v2.ftrl import Ftrl
from tensorflow.python.keras.optimizer_v2.gradient_descent import SGD
from tensorflow.python.keras.optimizer_v2.nadam import Nadam
from tensorflow.python.keras.optimizer_v2.optimizer_v2 import OptimizerV2 as Optimizer
from tensorflow.python.keras.optimizer_v2.rmsprop import RMSprop
from tensorflow.python.keras.optimizers import deserialize
from tensorflow.python.keras.optimizers import get
from tensorflow.python.keras.optimizers import serialize2、loss:字符串(目标函数的名称),目标函数或“tf.keras.losses.Loss”实例。在tf.keras.losses中可以发现主要有以下几种类型:
from tensorflow.python.keras.losses import BinaryCrossentropy
from tensorflow.python.keras.losses import CategoricalCrossentropy
from tensorflow.python.keras.losses import CategoricalHinge
from tensorflow.python.keras.losses import CosineSimilarity
from tensorflow.python.keras.losses import Hinge
from tensorflow.python.keras.losses import Huber
from tensorflow.python.keras.losses import KLDivergence
from tensorflow.python.keras.losses import LogCosh
from tensorflow.python.keras.losses import Loss
from tensorflow.python.keras.losses import MeanAbsoluteError
from tensorflow.python.keras.losses import MeanAbsolutePercentageError
from tensorflow.python.keras.losses import MeanSquaredError
from tensorflow.python.keras.losses import MeanSquaredLogarithmicError
from tensorflow.python.keras.losses import Poisson
from tensorflow.python.keras.losses import SparseCategoricalCrossentropy
from tensorflow.python.keras.losses import SquaredHinge
from tensorflow.python.keras.losses import binary_crossentropy
from tensorflow.python.keras.losses import categorical_crossentropy
from tensorflow.python.keras.losses import categorical_hinge
from tensorflow.python.keras.losses import cosine_similarity
from tensorflow.python.keras.losses import deserialize
from tensorflow.python.keras.losses import get
from tensorflow.python.keras.losses import hinge
from tensorflow.python.keras.losses import huber
from tensorflow.python.keras.losses import kl_divergence
from tensorflow.python.keras.losses import kl_divergence as KLD
from tensorflow.python.keras.losses import kl_divergence as kld
from tensorflow.python.keras.losses import kl_divergence as kullback_leibler_divergence
from tensorflow.python.keras.losses import log_cosh
from tensorflow.python.keras.losses import log_cosh as logcosh
from tensorflow.python.keras.losses import mean_absolute_error
from tensorflow.python.keras.losses import mean_absolute_error as MAE
from tensorflow.python.keras.losses import mean_absolute_error as mae
from tensorflow.python.keras.losses import mean_absolute_percentage_error
from tensorflow.python.keras.losses import mean_absolute_percentage_error as MAPE
from tensorflow.python.keras.losses import mean_absolute_percentage_error as mape
from tensorflow.python.keras.losses import mean_squared_error
from tensorflow.python.keras.losses import mean_squared_error as MSE
from tensorflow.python.keras.losses import mean_squared_error as mse
from tensorflow.python.keras.losses import mean_squared_logarithmic_error
from tensorflow.python.keras.losses import mean_squared_logarithmic_error as MSLE
from tensorflow.python.keras.losses import mean_squared_logarithmic_error as msle
from tensorflow.python.keras.losses import poisson
from tensorflow.python.keras.losses import serialize
from tensorflow.python.keras.losses import sparse_categorical_crossentropy
from tensorflow.python.keras.losses import squared_hinge
from tensorflow.python.ops.losses.loss_reduction import ReductionV2 as Reduction3、metrics:模型在训练和测试期间要评估的指标列表。每个都可以是字符串(内置函数的名称),函数或“tf.keras.metrics.Metric”实例。在tf.keras.metrics中可以发现主要有以下几种类型:
from tensorflow.python.keras.metrics import AUC
from tensorflow.python.keras.metrics import Accuracy
from tensorflow.python.keras.metrics import BinaryAccuracy
from tensorflow.python.keras.metrics import BinaryCrossentropy
from tensorflow.python.keras.metrics import CategoricalAccuracy
from tensorflow.python.keras.metrics import CategoricalCrossentropy
from tensorflow.python.keras.metrics import CategoricalHinge
from tensorflow.python.keras.metrics import CosineSimilarity
from tensorflow.python.keras.metrics import FalseNegatives
from tensorflow.python.keras.metrics import FalsePositives
from tensorflow.python.keras.metrics import Hinge
from tensorflow.python.keras.metrics import KLDivergence
from tensorflow.python.keras.metrics import LogCoshError
from tensorflow.python.keras.metrics import Mean
from tensorflow.python.keras.metrics import MeanAbsoluteError
from tensorflow.python.keras.metrics import MeanAbsolutePercentageError
from tensorflow.python.keras.metrics import MeanIoU
from tensorflow.python.keras.metrics import MeanRelativeError
from tensorflow.python.keras.metrics import MeanSquaredError
from tensorflow.python.keras.metrics import MeanSquaredLogarithmicError
from tensorflow.python.keras.metrics import MeanTensor
from tensorflow.python.keras.metrics import Metric
from tensorflow.python.keras.metrics import Poisson
from tensorflow.python.keras.metrics import Precision
from tensorflow.python.keras.metrics import PrecisionAtRecall
from tensorflow.python.keras.metrics import Recall
from tensorflow.python.keras.metrics import RecallAtPrecision
from tensorflow.python.keras.metrics import RootMeanSquaredError
from tensorflow.python.keras.metrics import SensitivityAtSpecificity
from tensorflow.python.keras.metrics import SparseCategoricalAccuracy
from tensorflow.python.keras.metrics import SparseCategoricalCrossentropy
from tensorflow.python.keras.metrics import SparseTopKCategoricalAccuracy
from tensorflow.python.keras.metrics import SpecificityAtSensitivity
from tensorflow.python.keras.metrics import SquaredHinge
from tensorflow.python.keras.metrics import Sum
from tensorflow.python.keras.metrics import TopKCategoricalAccuracy
from tensorflow.python.keras.metrics import TrueNegatives
from tensorflow.python.keras.metrics import TruePositives
from tensorflow.python.keras.metrics import binary_accuracy
from tensorflow.python.keras.metrics import categorical_accuracy
from tensorflow.python.keras.metrics import deserialize
from tensorflow.python.keras.metrics import get
from tensorflow.python.keras.metrics import serialize
from tensorflow.python.keras.metrics import sparse_categorical_accuracy
from tensorflow.python.keras.metrics import sparse_top_k_categorical_accuracy
from tensorflow.python.keras.metrics import top_k_categorical_accuracy
4、loss_weights:可选的列表或字典,用于指定标量系数(Python浮点数)以加权不同模型输出的损耗贡献。然后,模型最小化的损失值将是所有单个损失的“加权总和”,并由“loss_weights”系数加权。如果是列表,则期望与模型的输出具有1:1的映射。 如果是字典,则期望将输出名称(字符串)映射到标量系数。
5、weighted_metrics:在训练和测试期间要通过sample_weight或class_weight来评估和加权指标列表。
6、run_eagerly:布尔类型,默认是False。如果为True,则该模型的逻辑不会包装在tf.function中。建议将其设置为“None”,除非模型无法在“tf.function”中运行。
7、steps_per_execution:整型,默认是1。它是每次“tf.function”调用期间要运行的批次数。在单个“ tf.function”调用中运行多个批处理可以大大提高TPU或具有较大Python开销的小型模型的性能。每次执行最多只能运行一个完整的epoch。如果传递的数字大于epoch的大小,则执行epoch的大小。
四、训练模型
训练神经网络模型需要执行以下几个步骤:
1、首先将训练数据(train_images和train_labels)发送给模型。
2、模型学习将图像和标签关联起来。
3、模型对测试集(test_images)进行预测。
4、验证预测是否与test_labels中的标签相匹配。
4.1 训练模型
使用如下方法训练模型:
model.fit(train_images, train_labels, epochs=10)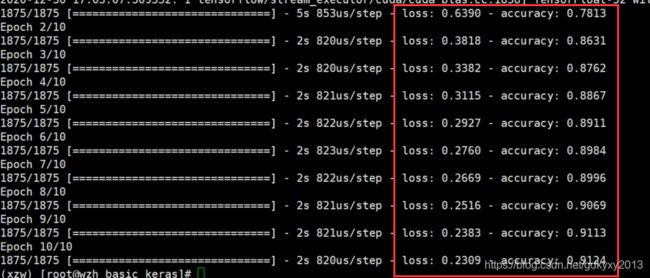
在模型训练期间,会显示损失和准确率指标,如上图所示。
4.1.1 model.fit()方法
model.fit()方法的用途是使用一个固定的epochs训练模型。其实现过程如下:
def fit(self,
x=None,
y=None,
batch_size=None,
epochs=1,
verbose=1,
callbacks=None,
validation_split=0.,
validation_data=None,
shuffle=True,
class_weight=None,
sample_weight=None,
initial_epoch=0,
steps_per_epoch=None,
validation_steps=None,
validation_batch_size=None,
validation_freq=1,
max_queue_size=10,
workers=1,
use_multiprocessing=False):
base_layer.keras_api_gauge.get_cell('fit').set(True)
# Legacy graph support is contained in `training_v1.Model`.
version_utils.disallow_legacy_graph('Model', 'fit')
self._assert_compile_was_called()
self._check_call_args('fit')
_disallow_inside_tf_function('fit')
if validation_split:
# Create the validation data using the training data. Only supported for
# `Tensor` and `NumPy` input.
(x, y, sample_weight), validation_data = (
data_adapter.train_validation_split(
(x, y, sample_weight), validation_split=validation_split))
if validation_data:
val_x, val_y, val_sample_weight = (
data_adapter.unpack_x_y_sample_weight(validation_data))
with self.distribute_strategy.scope(), \
training_utils.RespectCompiledTrainableState(self):
# Creates a `tf.data.Dataset` and handles batch and epoch iteration.
data_handler = data_adapter.DataHandler(
x=x,
y=y,
sample_weight=sample_weight,
batch_size=batch_size,
steps_per_epoch=steps_per_epoch,
initial_epoch=initial_epoch,
epochs=epochs,
shuffle=shuffle,
class_weight=class_weight,
max_queue_size=max_queue_size,
workers=workers,
use_multiprocessing=use_multiprocessing,
model=self,
steps_per_execution=self._steps_per_execution)
# Container that configures and calls `tf.keras.Callback`s.
if not isinstance(callbacks, callbacks_module.CallbackList):
callbacks = callbacks_module.CallbackList(
callbacks,
add_history=True,
add_progbar=verbose != 0,
model=self,
verbose=verbose,
epochs=epochs,
steps=data_handler.inferred_steps)
self.stop_training = False
self.train_function = self.make_train_function()
self._train_counter.assign(0)
callbacks.on_train_begin()
training_logs = None
# Handle fault-tolerance for multi-worker.
# TODO(omalleyt): Fix the ordering issues that mean this has to
# happen after `callbacks.on_train_begin`.
data_handler._initial_epoch = ( # pylint: disable=protected-access
self._maybe_load_initial_epoch_from_ckpt(initial_epoch))
logs = None
for epoch, iterator in data_handler.enumerate_epochs():
self.reset_metrics()
callbacks.on_epoch_begin(epoch)
with data_handler.catch_stop_iteration():
for step in data_handler.steps():
with trace.Trace(
'train',
epoch_num=epoch,
step_num=step,
batch_size=batch_size,
_r=1):
callbacks.on_train_batch_begin(step)
tmp_logs = self.train_function(iterator)
if data_handler.should_sync:
context.async_wait()
logs = tmp_logs # No error, now safe to assign to logs.
end_step = step + data_handler.step_increment
callbacks.on_train_batch_end(end_step, logs)
if self.stop_training:
break
if logs is None:
raise ValueError('Expect x to be a non-empty array or dataset.')
epoch_logs = copy.copy(logs)
# Run validation.
if validation_data and self._should_eval(epoch, validation_freq):
# Create data_handler for evaluation and cache it.
if getattr(self, '_eval_data_handler', None) is None:
self._fit_frame = tf_inspect.currentframe()
self._eval_data_handler = data_adapter.DataHandler(
x=val_x,
y=val_y,
sample_weight=val_sample_weight,
batch_size=validation_batch_size or batch_size,
steps_per_epoch=validation_steps,
initial_epoch=0,
epochs=1,
max_queue_size=max_queue_size,
workers=workers,
use_multiprocessing=use_multiprocessing,
model=self,
steps_per_execution=self._steps_per_execution)
val_logs = self.evaluate(
x=val_x,
y=val_y,
sample_weight=val_sample_weight,
batch_size=validation_batch_size or batch_size,
steps=validation_steps,
callbacks=callbacks,
max_queue_size=max_queue_size,
workers=workers,
use_multiprocessing=use_multiprocessing,
return_dict=True)
val_logs = {'val_' + name: val for name, val in val_logs.items()}
epoch_logs.update(val_logs)
callbacks.on_epoch_end(epoch, epoch_logs)
training_logs = epoch_logs
if self.stop_training:
break
# If eval data_hanlder exists, delete it after all epochs are done.
if getattr(self, '_eval_data_handler', None) is not None:
del self._eval_data_handler
del self._fit_frame
callbacks.on_train_end(logs=training_logs)
return self.history下面是model.fit()方法中参数的解释:
1、x:输入数据。
2、y:目标数据。
3、batch_size:整型或者是“None”,表示每个梯度更新的样本数。如果未指定,“batch_size”将默认为32。如果数据采用数据集、生成器或keras.utils.Sequence实例的形式,则不要指定“batch_size”。
4、epochs:整型,训练模型所需要的时期数。
5、verbose:0、1或2,详细模式。0表示什么都没有,1表示有进度条,2表示每个时期一行。值得注意的是,进度条在登录到文件时不是特别有用,因此当不交互式运行时建议使用verbose=2。
6、callbacks:keras.callbacks.Callback实例列表,在训练期间要应用的回调列表。通过tf.keras.callbacks我们可以发现主要有以下几种类型。
from tensorflow.python.keras.callbacks import BaseLogger
from tensorflow.python.keras.callbacks import CSVLogger
from tensorflow.python.keras.callbacks import Callback
from tensorflow.python.keras.callbacks import CallbackList
from tensorflow.python.keras.callbacks import EarlyStopping
from tensorflow.python.keras.callbacks import History
from tensorflow.python.keras.callbacks import LambdaCallback
from tensorflow.python.keras.callbacks import LearningRateScheduler
from tensorflow.python.keras.callbacks import ModelCheckpoint
from tensorflow.python.keras.callbacks import ProgbarLogger
from tensorflow.python.keras.callbacks import ReduceLROnPlateau
from tensorflow.python.keras.callbacks import RemoteMonitor
from tensorflow.python.keras.callbacks import TensorBoard
from tensorflow.python.keras.callbacks import TerminateOnNaN7、validation_split:0到1之间的浮点类型,训练数据的分数用作验证数据。模型将分开训练数据的这一部分,不对其进行训练,并且将在每个时期结束时评估此数据的损失和任何模型度量。
8、validation_data:在每个时期结束时用于评估损失的数据和任何模型指标。该模型将不会根据此数据进行训练。 因此,使用“validation_split”或“validation_data”提供的数据的验证丢失不受诸如噪声和丢失之类的正则化层的影响。
9、shuffle:布尔类型,是否在每个epoch之前将训练数据洗牌。当x是生成器时,将忽略该参数。
10、class_weight:可选的字典映射类索引(整数)到权重(浮动)值,用于加权损失函数(仅在训练期间)。
11、sample_weight:训练样本的可选Numpy权重数组,用于加权损失函数(仅在训练过程中)。
12、initial_epoch:整型,开始训练的epoch(用于恢复以前的训练运行)。
13、steps_per_epoch:整型或“None”,声明一个epoch完成并开始下一个epoch之前的总步数。当使用TensorFlow数据张量等输入张量进行训练时,默认值None等于数据集中的样本数除以批次大小;如果无法确定,则默认为1。如果x是tf.data数据集,并且steps_per_epoch为None,则该epoch将运行直到输入数据集用尽。传递无限重复的数据集时,必须指定steps_per_epoch参数。数组输入不支持此参数。
14、validation_steps:此参数仅在提供“validation_data”并且是“tf.data”数据集的情况下才使用。它代表在每个时期结束执行验证时,在停止之前要绘制的步骤总数。如果“validation_steps”为“None”,则验证将一直进行到“validation_data”数据集用尽。如果是无限重复的数据集,它将陷入无限循环。如果指定了“validation_steps”,并且仅消耗了一部分数据集,则评估将在每个时期从数据集的开头开始,这样可以确保每次都使用相同的验证样本。
15、validation_batch_size:整型或“None”,代表每个验证batch的样品数量。
16、validation_freq:仅在提供验证数据时才使用的参数。整型或“collections_abc.Container”实例,例如:列表、元组等等。如果是整数,请指定在执行新的验证运行之前要运行多少个训练时期,例如validation_freq = 2表示每2个周期运行一次验证。如果是容器,请指定要在其上运行验证的时期,例如“validation_freq = [1、2、10]”会在第1个,第2个和第10个时期的末尾运行验证。
17、max_queue_size:整型。仅用于生成器或keras.utils.Sequence输入,代表生成器队列的最大大小。如果未指定,max_queue_size默认为10。
18、workers:整型。仅用于生成器或keras.utils.Sequence输入。代表使用基于进程的线程时,要启动的最大进程数。如果未指定,workers默认为1。如果为0,将在主线程上执行生成器。
19、use_multiprocessing:布尔类型。仅用于生成器或keras.utils.Sequence输入。如果为True,则使用基于进程的线程。如果未指定,则use_multiprocessing将默认为False。
4.2 评估准确率
模型训练好之后,我们接下来使用测试数据集对训练好的模型进行准确率的评估。使用如下代码进行测试:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print("Test_Loss:", test_loss)
print("Test_Accuracy:", test_acc)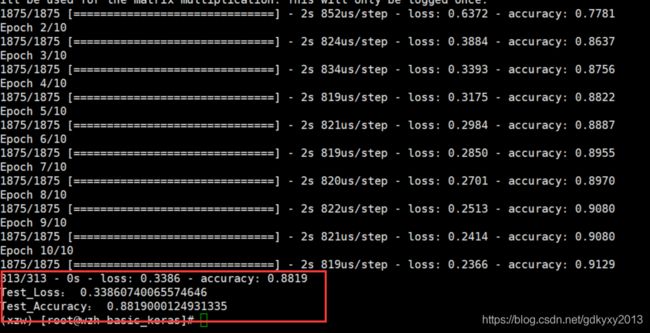
通过上图可以发现,模型在测试数据集上的准确率略低于训练数据集。训练准确率和测试准确率之间的差距代表过拟合。过拟合是指机器学习模型在新的、以前未曾见过的输入上的表现不如在训练数据上的表现。过拟合的模型会“记住”训练数据集中的噪声和细节,从而对模型在新数据上的表现产生负面影响。对于过拟合的内容,我们会在后面进行讲解。
4.2.1 model.evaluate()方法
model.evaluate()方法的作用是返回测试模式下模型的损失值和指标值。其实现过程如下所示:
def evaluate(self,
x=None,
y=None,
batch_size=None,
verbose=1,
sample_weight=None,
steps=None,
callbacks=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False,
return_dict=False):
base_layer.keras_api_gauge.get_cell('evaluate').set(True)
version_utils.disallow_legacy_graph('Model', 'evaluate')
self._assert_compile_was_called()
self._check_call_args('evaluate')
_disallow_inside_tf_function('evaluate')
with self.distribute_strategy.scope():
# Use cached evaluation data only when it's called in `Model.fit`
if (getattr(self, '_fit_frame', None) is not None
and tf_inspect.currentframe().f_back is self._fit_frame
and getattr(self, '_eval_data_handler', None) is not None):
data_handler = self._eval_data_handler
else:
# Creates a `tf.data.Dataset` and handles batch and epoch iteration.
data_handler = data_adapter.DataHandler(
x=x,
y=y,
sample_weight=sample_weight,
batch_size=batch_size,
steps_per_epoch=steps,
initial_epoch=0,
epochs=1,
max_queue_size=max_queue_size,
workers=workers,
use_multiprocessing=use_multiprocessing,
model=self,
steps_per_execution=self._steps_per_execution)
# Container that configures and calls `tf.keras.Callback`s.
if not isinstance(callbacks, callbacks_module.CallbackList):
callbacks = callbacks_module.CallbackList(
callbacks,
add_history=True,
add_progbar=verbose != 0,
model=self,
verbose=verbose,
epochs=1,
steps=data_handler.inferred_steps)
logs = {}
self.test_function = self.make_test_function()
self._test_counter.assign(0)
callbacks.on_test_begin()
for _, iterator in data_handler.enumerate_epochs(): # Single epoch.
self.reset_metrics()
with data_handler.catch_stop_iteration():
for step in data_handler.steps():
with trace.Trace('test', step_num=step, _r=1):
callbacks.on_test_batch_begin(step)
tmp_logs = self.test_function(iterator)
if data_handler.should_sync:
context.async_wait()
logs = tmp_logs # No error, now safe to assign to logs.
end_step = step + data_handler.step_increment
callbacks.on_test_batch_end(end_step, logs)
logs = tf_utils.to_numpy_or_python_type(logs)
callbacks.on_test_end(logs=logs)
if return_dict:
return logs
else:
results = []
for name in self.metrics_names:
if name in logs:
results.append(logs[name])
for key in sorted(logs.keys()):
if key not in self.metrics_names:
results.append(logs[key])
if len(results) == 1:
return results[0]
return results下面我们对该方法的参数进行一下说明:
1、x:输入数据。
2、y:目标数据。
3、batch_size:整型或者是“None”,表示每个梯度更新的样本数。如果未指定,“batch_size”将默认为32。如果数据采用数据集、生成器或keras.utils.Sequence实例的形式,则不要指定“batch_size”。
4、verbose:0或者1,详细模式。0表示什么都没有,1表示有进度条。
5、sample_weight:测试样本的可选Numpy权重数组,用于加权损失函数。
6、steps:整型或者是“None”,宣布评估回合之前完成的步骤总数。
7、callbacks:keras.callbacks.Callback实例列表。评估期间要应用的回调列表。
8、max_queue_size:整型。仅用于生成器或keras.utils.Sequence输入。表示生成器队列的最大大小。如果未指定,max_queue_size将默认为10。
9、workers:整型。仅用于生成器或keras.utils.Sequence输入。使用基于进程的线程时,要启动的最大进程数。如果未指定,workers将默认为1。如果为0,将在主线程上执行生成器。
10、use_multiprocessing:布尔类型。仅用于生成器或keras.utils.Sequence输入。如果为True,则使用基于进程的线程。如果未指定,则use_multiprocessing将默认为False。这里需要注意的是,由于此实现依赖于多处理,因此不应将不可拾取的参数传递给生成器,因为它们无法轻易传递给子进程。
11、return_dict:如果为True,则将损失和度量结果作为dict返回,每个键都是度量的名称。如果为False,则将它们作为列表返回。
4.3 预测
在评估完准确率之后,我们可以使用该模型进行预测,因为模型具有线性输出,即logits。所以我们可以添加一个softmax层,将logits转换成更容易理解的概率数据。预测过程如下:
probability_model = tf.keras.Sequential([model, tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
print('预测结果:', predictions[0])
print('预测标签:', np.argmax(predictions[0]))
print('实际标签:', test_labels[0])上面代码中,predictions预测了测试集中每个图像的标签,这里我们只打印出了第一个的预测结果以及与真实值的对比,如下图所示:

预测结果是一个包含10个数字的数组,它们分别代表了模型对10种不同服装中每种服装的“置信度”。我们可以通过选择置信度值最大的那个作为预测的最终分类结果,通过上图可以发现9是置信度最大的标签,通过与真实值对比发现:对于第一个测试数据的预测是准确的。
4.3.1 tf.keras.layers.Softmax()层
tf.keras.layers.Softmax()层主要实现的就是Softmax激活函数,这个比较简单,其实现过程如下:
@keras_export('keras.layers.Softmax')
class Softmax(Layer):
def __init__(self, axis=-1, **kwargs):
super(Softmax, self).__init__(**kwargs)
self.supports_masking = True
self.axis = axis
def call(self, inputs, mask=None):
if mask is not None:
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -1e.9 for masked positions.
adder = (1.0 - math_ops.cast(mask, inputs.dtype)) * (
_large_compatible_negative(inputs.dtype))
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
inputs += adder
if isinstance(self.axis, (tuple, list)):
if len(self.axis) > 1:
return math_ops.exp(inputs - math_ops.reduce_logsumexp(
inputs, axis=self.axis, keepdims=True))
else:
return K.softmax(inputs, axis=self.axis[0])
return K.softmax(inputs, axis=self.axis)
def get_config(self):
config = {'axis': self.axis}
base_config = super(Softmax, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
@tf_utils.shape_type_conversion
def compute_output_shape(self, input_shape):
return input_shape4.3.2 tf.keras.Sequential()类
tf.keras.Sequential()类的作用是“Sequential”将线性的图层堆栈分组为“tf.keras.Model”,“Sequential”在此模型上提供训练和推理功能。其源码如下:
class Sequential(functional.Functional):
@trackable.no_automatic_dependency_tracking
def __init__(self, layers=None, name=None):
super(functional.Functional, self).__init__( # pylint: disable=bad-super-call
name=name, autocast=False)
base_layer.keras_api_gauge.get_cell('Sequential').set(True)
self.supports_masking = True
self._compute_output_and_mask_jointly = True
self._auto_track_sub_layers = False
self._inferred_input_shape = None
self._has_explicit_input_shape = False
self._input_dtype = None
self._layer_call_argspecs = {}
self._created_nodes = set()
self._graph_initialized = False
self._use_legacy_deferred_behavior = False
# Add to the model any layers passed to the constructor.
if layers:
if not isinstance(layers, (list, tuple)):
layers = [layers]
for layer in layers:
self.add(layer)
@property
def layers(self):
layers = super(Sequential, self).layers
if layers and isinstance(layers[0], input_layer.InputLayer):
return layers[1:]
return layers[:]
@trackable.no_automatic_dependency_tracking
def add(self, layer):
if hasattr(layer, '_keras_history'):
origin_layer = layer._keras_history[0]
if isinstance(origin_layer, input_layer.InputLayer):
layer = origin_layer
if not isinstance(layer, base_layer.Layer):
raise TypeError('The added layer must be '
'an instance of class Layer. '
'Found: ' + str(layer))
tf_utils.assert_no_legacy_layers([layer])
if not self._is_layer_name_unique(layer):
raise ValueError('All layers added to a Sequential model '
'should have unique names. Name "%s" is already the name'
' of a layer in this model. Update the `name` argument '
'to pass a unique name.' % (layer.name,))
self.built = False
set_inputs = False
if not self._layers:
if isinstance(layer, input_layer.InputLayer):
# Case where the user passes an Input or InputLayer layer via `add`.
set_inputs = True
else:
batch_shape, dtype = training_utils.get_input_shape_and_dtype(layer)
if batch_shape:
# Instantiate an input layer.
x = input_layer.Input(
batch_shape=batch_shape, dtype=dtype, name=layer.name + '_input')
# This will build the current layer
# and create the node connecting the current layer
# to the input layer we just created.
layer(x)
set_inputs = True
if set_inputs:
outputs = nest.flatten(layer._inbound_nodes[-1].outputs)
if len(outputs) != 1:
raise ValueError(SINGLE_LAYER_OUTPUT_ERROR_MSG)
self.outputs = outputs
self.inputs = layer_utils.get_source_inputs(self.outputs[0])
self.built = True
self._has_explicit_input_shape = True
elif self.outputs:
output_tensor = layer(self.outputs[0])
if len(nest.flatten(output_tensor)) != 1:
raise ValueError(SINGLE_LAYER_OUTPUT_ERROR_MSG)
self.outputs = [output_tensor]
self.built = True
if set_inputs or self._graph_initialized:
self._init_graph_network(self.inputs, self.outputs)
self._graph_initialized = True
else:
self._layers.append(layer)
self._handle_deferred_layer_dependencies([layer])
self._layer_call_argspecs[layer] = tf_inspect.getfullargspec(layer.call)
@trackable.no_automatic_dependency_tracking
def pop(self):
if not self.layers:
raise TypeError('There are no layers in the model.')
layer = self._layers.pop()
self._layer_call_argspecs.pop(layer)
if not self.layers:
self.outputs = None
self.inputs = None
self.built = False
self._inferred_input_shape = None
self._has_explicit_input_shape = False
self._graph_initialized = False
elif self._graph_initialized:
self.layers[-1]._outbound_nodes = []
self.outputs = [self.layers[-1].output]
self._init_graph_network(self.inputs, self.outputs)
self.built = True
@trackable.no_automatic_dependency_tracking
def _build_graph_network_for_inferred_shape(self,
input_shape,
input_dtype=None):
if input_shape is None or not self.layers:
return
if not tf2.enabled() or not ops.executing_eagerly_outside_functions():
# This behavior is disabled in V1 or when eager execution is disabled.
return
if (not self._has_explicit_input_shape and
not self._use_legacy_deferred_behavior):
# Determine whether the input shape is novel, i.e. whether the model
# should be rebuilt.
input_shape = tuple(input_shape)
if self._inferred_input_shape is None:
new_shape = input_shape
else:
new_shape = relax_input_shape(self._inferred_input_shape, input_shape)
if (new_shape is not None and new_shape != self._inferred_input_shape):
# A novel shape has been received: we need to rebuild the model.
# In case we are inside a graph function, we step out of it.
with ops.init_scope():
inputs = input_layer.Input(
batch_shape=new_shape,
dtype=input_dtype,
name=self.layers[0].name + '_input')
layer_input = inputs
created_nodes = set()
for layer in self.layers:
clear_previously_created_nodes(layer, self._created_nodes)
try:
# Create Functional API connection by calling the current layer
layer_output = layer(layer_input)
except: # pylint:disable=bare-except
self._use_legacy_deferred_behavior = True
return
if len(nest.flatten(layer_output)) != 1:
raise ValueError(SINGLE_LAYER_OUTPUT_ERROR_MSG)
# Keep track of nodes just created above
track_nodes_created_by_last_call(layer, created_nodes)
layer_input = layer_output
outputs = layer_output
self._created_nodes = created_nodes
try:
self._init_graph_network(inputs, outputs)
self._graph_initialized = True
except: # pylint:disable=bare-except
self._use_legacy_deferred_behavior = True
self._inferred_input_shape = new_shape
@generic_utils.default
def build(self, input_shape=None):
if self._graph_initialized:
self._init_graph_network(self.inputs, self.outputs)
else:
if input_shape is None:
raise ValueError('You must provide an `input_shape` argument.')
self._build_graph_network_for_inferred_shape(input_shape)
if not self.built:
input_shape = tuple(input_shape)
self._build_input_shape = input_shape
super(Sequential, self).build(input_shape)
self.built = True
def call(self, inputs, training=None, mask=None): # pylint: disable=redefined-outer-name
# If applicable, update the static input shape of the model.
if not self._has_explicit_input_shape:
if not tensor_util.is_tensor(inputs) and not isinstance(
inputs, np_arrays.ndarray):
# This is a Sequential with mutiple inputs. This is technically an
# invalid use case of Sequential, but we tolerate it for backwards
# compatibility.
self._use_legacy_deferred_behavior = True
self._build_input_shape = nest.map_structure(_get_shape_tuple, inputs)
if tf2.enabled():
logging.warning('Layers in a Sequential model should only have a '
'single input tensor, but we receive a %s input: %s'
'\nConsider rewriting this model with the Functional '
'API.' % (type(inputs), inputs))
else:
self._build_graph_network_for_inferred_shape(inputs.shape, inputs.dtype)
if self._graph_initialized:
if not self.built:
self._init_graph_network(self.inputs, self.outputs)
return super(Sequential, self).call(inputs, training=training, mask=mask)
outputs = inputs # handle the corner case where self.layers is empty
for layer in self.layers:
# During each iteration, `inputs` are the inputs to `layer`, and `outputs`
# are the outputs of `layer` applied to `inputs`. At the end of each
# iteration `inputs` is set to `outputs` to prepare for the next layer.
kwargs = {}
argspec = self._layer_call_argspecs[layer].args
if 'mask' in argspec:
kwargs['mask'] = mask
if 'training' in argspec:
kwargs['training'] = training
outputs = layer(inputs, **kwargs)
if len(nest.flatten(outputs)) != 1:
raise ValueError(SINGLE_LAYER_OUTPUT_ERROR_MSG)
# `outputs` will be the inputs to the next layer.
inputs = outputs
mask = getattr(outputs, '_keras_mask', None)
return outputs
def compute_output_shape(self, input_shape):
shape = input_shape
for layer in self.layers:
shape = layer.compute_output_shape(shape)
return shape
def compute_mask(self, inputs, mask):
# TODO(omalleyt): b/123540974 This function is not really safe to call
# by itself because it will duplicate any updates and losses in graph
# mode by `call`ing the Layers again.
outputs = self.call(inputs, mask=mask)
return getattr(outputs, '_keras_mask', None)
def predict_proba(self, x, batch_size=32, verbose=0):
warnings.warn('`model.predict_proba()` is deprecated and '
'will be removed after 2021-01-01. '
'Please use `model.predict()` instead.')
preds = self.predict(x, batch_size, verbose)
if preds.min() < 0. or preds.max() > 1.:
logging.warning('Network returning invalid probability values. '
'The last layer might not normalize predictions '
'into probabilities '
'(like softmax or sigmoid would).')
return preds
def predict_classes(self, x, batch_size=32, verbose=0):
warnings.warn('`model.predict_classes()` is deprecated and '
'will be removed after 2021-01-01. '
'Please use instead:'
'* `np.argmax(model.predict(x), axis=-1)`, '
' if your model does multi-class classification '
' (e.g. if it uses a `softmax` last-layer activation).'
'* `(model.predict(x) > 0.5).astype("int32")`, '
' if your model does binary classification '
' (e.g. if it uses a `sigmoid` last-layer activation).')
proba = self.predict(x, batch_size=batch_size, verbose=verbose)
if proba.shape[-1] > 1:
return proba.argmax(axis=-1)
else:
return (proba > 0.5).astype('int32')
def get_config(self):
layer_configs = []
for layer in super(Sequential, self).layers:
# `super().layers` include the InputLayer if available (it is filtered out
# of `self.layers`). Note that `self._layers` is managed by the
# tracking infrastructure and should not be used.
layer_configs.append(generic_utils.serialize_keras_object(layer))
config = {
'name': self.name,
'layers': copy.deepcopy(layer_configs)
}
if not self._is_graph_network and self._build_input_shape is not None:
config['build_input_shape'] = self._build_input_shape
return config
@classmethod
def from_config(cls, config, custom_objects=None):
if 'name' in config:
name = config['name']
build_input_shape = config.get('build_input_shape')
layer_configs = config['layers']
else:
name = None
build_input_shape = None
layer_configs = config
model = cls(name=name)
for layer_config in layer_configs:
layer = layer_module.deserialize(layer_config,
custom_objects=custom_objects)
model.add(layer)
if (not model.inputs and build_input_shape and
isinstance(build_input_shape, (tuple, list))):
model.build(build_input_shape)
return model
@property
def input_spec(self):
if hasattr(self, '_manual_input_spec'):
return self._manual_input_spec
if self.layers and hasattr(self.layers[0], 'input_spec'):
return self.layers[0].input_spec
return None
@input_spec.setter
def input_spec(self, value):
self._manual_input_spec = value
@property
def _trackable_saved_model_saver(self):
return model_serialization.SequentialSavedModelSaver(self)
def _is_layer_name_unique(self, layer):
for ref_layer in self.layers:
if layer.name == ref_layer.name and ref_layer is not layer:
return False
return True
def _assert_weights_created(self):
if self._graph_initialized:
return
# When the graph has not been initialized, use the Model's implementation to
# to check if the weights has been created.
super(functional.Functional, self)._assert_weights_created() # pylint: disable=bad-super-call
其输入参数解释如下:1、layers:要添加到模型的可选层列表。2、name:模型的可选名称。
4.3.3 predict()预测方法
predict()方法主要是生成输入样本的输出预测。其源码如下:
def predict(self,
x,
batch_size=None,
verbose=0,
steps=None,
callbacks=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False):
base_layer.keras_api_gauge.get_cell('predict').set(True)
version_utils.disallow_legacy_graph('Model', 'predict')
self._check_call_args('predict')
_disallow_inside_tf_function('predict')
outputs = None
with self.distribute_strategy.scope():
# Creates a `tf.data.Dataset` and handles batch and epoch iteration.
dataset_types = (dataset_ops.DatasetV1, dataset_ops.DatasetV2)
if (self._in_multi_worker_mode() or _is_tpu_multi_host(
self.distribute_strategy)) and isinstance(x, dataset_types):
try:
options = dataset_ops.Options()
data_option = AutoShardPolicy.DATA
options.experimental_distribute.auto_shard_policy = data_option
x = x.with_options(options)
except ValueError:
warnings.warn('Using Model.predict with '
'MultiWorkerDistributionStrategy or TPUStrategy and '
'AutoShardPolicy.FILE might lead to out-of-order result'
'. Consider setting it to AutoShardPolicy.DATA.')
data_handler = data_adapter.DataHandler(
x=x,
batch_size=batch_size,
steps_per_epoch=steps,
initial_epoch=0,
epochs=1,
max_queue_size=max_queue_size,
workers=workers,
use_multiprocessing=use_multiprocessing,
model=self,
steps_per_execution=self._steps_per_execution)
# Container that configures and calls `tf.keras.Callback`s.
if not isinstance(callbacks, callbacks_module.CallbackList):
callbacks = callbacks_module.CallbackList(
callbacks,
add_history=True,
add_progbar=verbose != 0,
model=self,
verbose=verbose,
epochs=1,
steps=data_handler.inferred_steps)
self.predict_function = self.make_predict_function()
self._predict_counter.assign(0)
callbacks.on_predict_begin()
batch_outputs = None
for _, iterator in data_handler.enumerate_epochs(): # Single epoch.
with data_handler.catch_stop_iteration():
for step in data_handler.steps():
callbacks.on_predict_batch_begin(step)
tmp_batch_outputs = self.predict_function(iterator)
if data_handler.should_sync:
context.async_wait()
batch_outputs = tmp_batch_outputs # No error, now safe to assign.
if outputs is None:
outputs = nest.map_structure(lambda batch_output: [batch_output],
batch_outputs)
else:
nest.map_structure_up_to(
batch_outputs,
lambda output, batch_output: output.append(batch_output),
outputs, batch_outputs)
end_step = step + data_handler.step_increment
callbacks.on_predict_batch_end(end_step, {'outputs': batch_outputs})
if batch_outputs is None:
raise ValueError('Expect x to be a non-empty array or dataset.')
callbacks.on_predict_end()
all_outputs = nest.map_structure_up_to(batch_outputs, concat, outputs)
return tf_utils.to_numpy_or_python_type(all_outputs)predict()方法的参数释义如下:
1、x:输入样本。
2、batch_size:整型或者是None。每个批次的样本数,如果没有指定,默认是32
3、verbose:详细模式,0或者是1。
4、steps:宣布预测回合完成之前的步骤总数(样本批次)。
5、callbacks:keras.callbacks.Callback实例列表。
6、max_queue_size:整型。仅用于生成器或“keras.utils.Sequence”输入。生成器队列的最大大小。如果未指定,将默认为10。
7、workers:整型。仅用于生成器或“keras.utils.Sequence”输入。使用基于进程的线程时,要启动的最大进程数。如果未指定,将默认为1。如果为0,将在主线程上执行生成器。
8、use_multiprocessing:布尔类型。仅用于生成器或“keras.utils.Sequence”输入。如果为True,则使用基于进程的线程。如果未指定,则将默认为False。
4.3.4 绘图查看并验证预测结果
对于上述的预测,也可以通过如下绘图的方式查看模型对类的预测。
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array, true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100 * np.max(predictions_array),
class_names[true_label]), color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array, true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')其中上述方法中的plt.bar()是指绘制柱状图。我们来看几个示例:
1、查看第0个图像、预测结果和预测数组。正确的预测标签为蓝色,错误的预测标签为红色,数字表示预测标签的百分比。
i = 0
plt.figure(figsize=(6, 3))
plt.subplot(1, 2, 1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1, 2, 2)
plot_value_array(i, predictions[i], test_labels)
plt.show()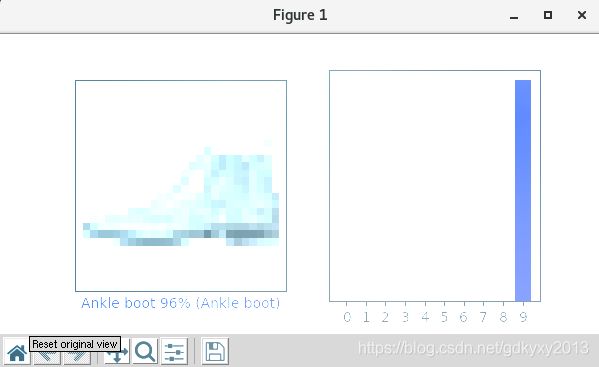
2、查看第20个图像、预测结果和预测数组。
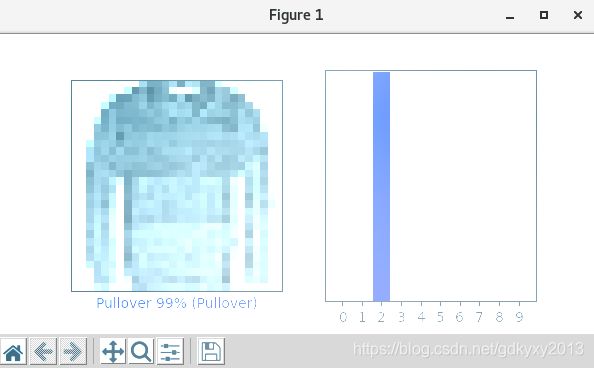
3、虽然模型的准确率很高,但是也会有出错的时候,毕竟准确率不是百分之百。我们可以多绘制几张图像,看看是什么结果。
num_rows = 5
num_cols = 3
num_images = num_rows * num_cols
plt.figure(figsize=(2 * 2 * num_cols, 2 * num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2 * num_cols, 2 * i + 1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2 * num_cols, 2 * i + 2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()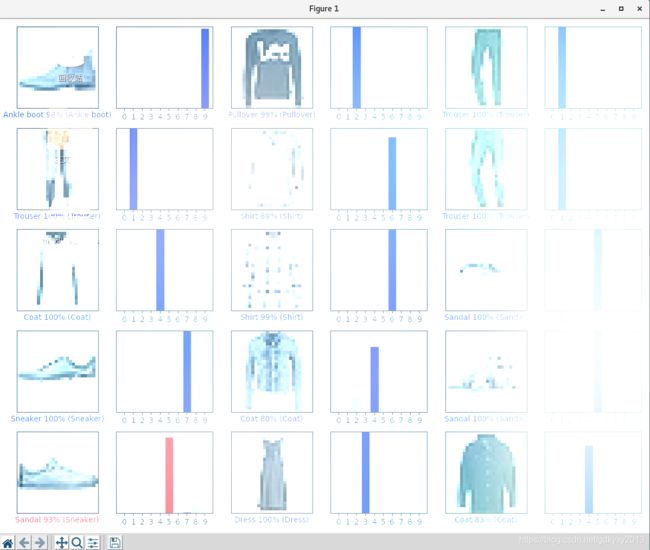
五、使用模型
模型训练、验证完成之后就是正式投入使用的阶段了,开始使用咱们的模型对新的图像进行预测。tf.keras模型经过了优化,可同时对一个批或一组样本进行预测。因此,即便只使用一个图像进行预测,也需要将其添加到列表中。预测代码如下:
# 五、使用模型
img = test_images[1]
print(img.shape)
# tf.keras模型经过了优化,可同时对一个批或一组样本进行预测。因此,即便只使用一个图像,也需要将其添加到列表中。
img = (np.expand_dims(img, 0))
print(img.shape)
# 预测图像的正确标签
predictions_single = probability_model.predict(img)
print(np.argmax(predictions_single[0]))
# 画图
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
plt.show()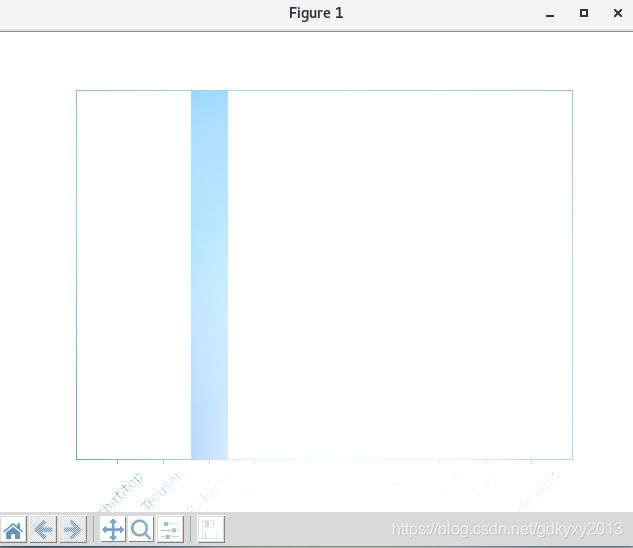
而且控制台也输出了最终的预测标签:

好了,本文内容有点多了,大家可以慢慢看,到此本文已经接近尾声了,相关代码也已经传到了我的GitHub上,可以点击这里进行查看。你们在这个过程中遇到了什么问题,欢迎留言,让我看看你们都遇到了什么问题~