Python基础学习(第二节 下)
这里写目录标题
- 1.布尔值的相关运算符
-
- (1)布尔值
- (2)比较运算符
- (3)逻辑运算符
- (4)同一运算符
- 2.字符串
-
- (1)字符串的基本特点
- (2)字符串的创建和len( )函数
- (3)转义字符
- (4)字符串拼接和复制
- (5)不换行打印和控制台读取字符串
- (6)字符串的提取和replace替换
- (7)字符串的切片slice、分割split( )和拼接join( )
- (8)字符串的驻留机制和字符串的比较
- (9)字符串常用方法汇总
-
- 1.字符串的常用查找方法
- 2.字符串大小写转化方法
- 3.字符串的格式排版方法
- 4.字符串的is判断方法
- (10)字符串的格式化
- (11)字符串的填充与对齐
- (12)数字的格式化
1.布尔值的相关运算符
(1)布尔值
布尔值是一个逻辑值,True表示真,False表示假。
Python3中把True和False定义为关键字,其本质是1和0,有时甚至可以和数字相加。
测试:
a = True
b = 33
print("a+b=", a + b)
测试结果:
![]()
(2)比较运算符
所有比较运算符返回1表示真,返回0表示假,这分别与特殊的变量True和False等价。
以下实例中假设变量a=15,b=30:
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于:比较对象的值是否相等 | False |
| != | 不等于:比较两个对象是否不相等 | True |
| > | 大于:比较a是否大于b | False |
| < | 小于:比较a是否小于b | True |
| >= | 大于等于:比较a是否大于等于b | False |
| <= | 小于等于:比较a是否小于等于b | True |
测试:
a,b,c=15,30,30.0
print("a和b是否相等?",a==b)
print("a是否大于b?",a>b)
print("a和b是否不相等?",a!=b)
print("a是否小于b?",a<b)
print("c是否大于等于b?",c>=b)
print("b是否大于等于c?",b<=c)
print("b是否大于等于c?",b==c)
测试结果:

从测试结果可以看出:比较运算符只是比较两个变量对应对象中的value值的大小,与value值的类型无关。
上面举了一个整型和浮点型进行比较的例子,下面再看整型和布尔型比较的例子。**
测试:
print("如果value的数值类型发生变化,但是数值一样,比较结果是否会报错?")
d,e,f=True,1,False
print("d是否等于e?",d==e)
print("d是否大于等于e?",d>=e)
print("d是否小于等于e?",d<=e)
print("d是不等于e?",d!=e)
print("f是否大于等于e?",f>=e)
测试结果:

(3)逻辑运算符
| 运算符 | 格式 | 说明 |
|---|---|---|
| or | x or y | x 为true,则不计算y值,直接返回true;x为false,则计算并返回y值 |
| and | x and y | x为true,则计算并返回y值;x为false,则不计算y值,直接返回false |
| not | not x | x 为true,则返回false;x为false,则返回true |
测试:
a, b, c = 9, 12, 13
print("逻辑and:")
print("真和真返回:", (a < b) and (a < c))
print("真和假返回:", (a < b) and (a > c))
print("假和真返回:", (a > b) and (a < c))
print("假和假返回:", (a > b) and (a > c))
print("逻辑or:")
print("真和真返回:", (a < b) or (a < c))
print("真和假返回:", (a < b) or (a > c))
print("假和真返回:", (a > b) or (a < c))
print("假和假返回:", (a > b) or (a > c))
测试结果:

在使用逻辑运算符 or 和 and 时,如果符号左侧是真或者假,计算机是否会计算右侧?
测试:
print("逻辑and,如果符号左侧为假,是否计算右侧?",False and (10//0))
print("逻辑and,如果符号左侧为真,是否计算右侧?",True and (10//0))

print("逻辑or,如果符号左侧为真,是否计算右侧?",True or (10//0))
print("逻辑or,如果符号左侧为假,是否计算右侧?",False or (10//0))
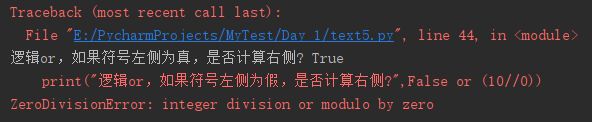
从测试结果可以看出:计算机在进行逻辑运算时,其计算过程和人脑的思考过程还是有差别的,虽然结果是一致的。
逻辑运算符 and :只要有一个为假即为假。如果符号左侧为假,则不计算判断符号右侧的真假,直接返回False;如果符号左侧为真,则计算判断符号右侧的真假,如果是真返回True,如果是假返回False。
逻辑运算符 or :只要有一个为真即为真。如果符号左侧为真,则不计算判断符号右侧的真假,直接返回True;如果符号左侧为假,则计算判断符号右侧的真假,如果是真返回True,如果是假返回False。
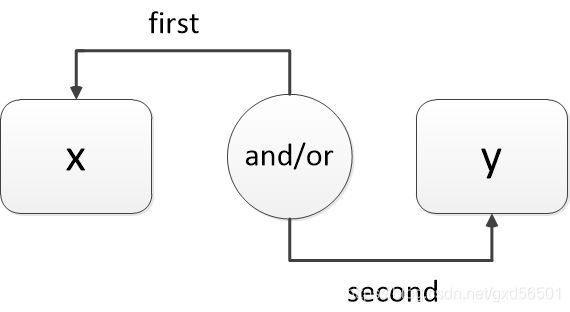
注意:逻辑运算符and和or,如果first步骤满足条件,那么就不会执行second步骤,会出现短路现象,即使y有错误系统也不会报错。
(4)同一运算符
| 运算符 | 说明 |
|---|---|
| is | 判断两个标识符是否引用同一对象 |
| not is | 判断两个标识符是否引用不同对象 |
这里之所以说的是标识符而不是变量,是因为标识符包括变量、常量、函数、包、模块和语句等,其概念范围更大,应用范围更广。
测试:
a = b = 1
print("a和b是否是同一对象?",a is b)
print("id(a)的地址为:", id(a))
print("id(b)的地址为:", id(b))
print("id(a)的数据类型为:", type(a))
print("id(b)的数据类型为:", type(b))
a, b = 1, 2
print("a和b是否是同一对象?",a is b)
print("id(a)的地址为:", id(a))
print("id(b)的地址为:", id(b))
print("id(a)的数据类型为:", type(a))
print("id(b)的数据类型为:", type(b))
print("a和b是否是同一对象?",a is b)
a, b = 1, 1.0
print(a is b)
print("id(a)的地址为:", id(a))
print("id(b)的地址为:", id(b))
print("id(a)的数据类型为:", type(a))
print("id(b)的数据类型为:", type(b))
a, b = 1, 1.0
print("a和b是否是不是同一对象?",a is not b)
print(a is not b)
print("id(a)的地址为:", id(a))
print("id(b)的地址为:", id(b))
print("id(a)的数据类型为:", type(a))
print("id(b)的数据类型为:", type(b))
测试结果:

注意:同一运算符is和比较运算符= =是有区别的:
1.比较运算符==比较的是两个对象中的value值的大小,同一运算符is比较的是两个对象的地址是否相同;
2.比较运算符==实际是默认调用对象的_eq_()方法;
3.同一运算符is比比较运算符==效率要高,在进行变量和None比较运算时,应该使用is。
总结:比较value用==,比较id用is。
测试:
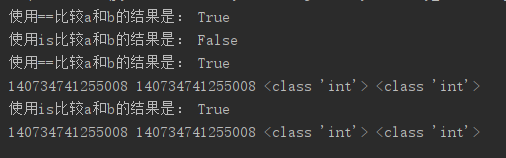
a, b = 1, 1.0
print("使用==比较a和b的结果是:", a == b)
print("使用is比较a和b的结果是:", a is b)
a=b=2
print("使用==比较a和b的结果是:",a==b)
print(id(a),id(b),type(a),type(b))
print("使用is比较a和b的结果是:", a is b)
print(id(a),id(b),type(a),type(b))
测试结果:
2.字符串
(1)字符串的基本特点
字符串的本质是字符序列。其特点是:
1.在Python中字符串是不可变的,无法对原字符串做任何修改;
2.在Python中没有字符这个概念,一个字符也是字符串,长度为1;
3.在Python3中直接使用Unicode码(16位),其可以表示世界上任何书面语言。(Python3版之前,使用的是ASC2码(8位))
可以使用内置函数:
ord( )把字符转化为对应的Unicode码;
chr( )把十进制数字转化为对应字符。
测试:
a = ord("我")
print("使用ord()把\"我\"转换为Unicode码:", a, id(a), type(a))
b = ord('a')
print("使用ord()把'a'转换为Unicode码:", b, id(b), type(b))
a = chr(100)
print("使用chr()把100转换为字符串:", a, id(a), type(a))
b = chr(0)
print("使用chr()把0转换为字符串:", b, id(b), type(b))
print(ord("老"), ord("高"), ord("学"), ord("P"), ord("y"))
print(chr(32769), chr(39640), chr(23398), chr(80), chr(121))
# b=chr(-100)
# print("使用chr()把-100转换为字符串:",b,id(b),type(b))
# b=chr(10000000)
# print("使用chr()把10000000转换为字符串:",b,id(b),type(b))
测试结果:
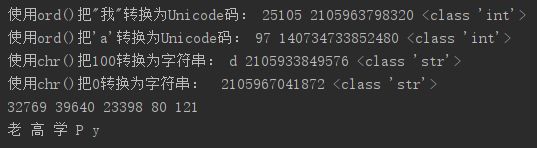
从测试结果可以发现,在使用内置函数ord()和chr()时需要注意以下几点:
1.ord( )函数在使用后,返回的是整型数据,chr( )函数在使用后,返回的是字符串型的数据;
2.ord( )和chr( )函数返回的结果是相互对应的,也就是说ord( )函数返回的数据可以在chr( )中使用,同理chr( )函数返回的数据也可以在ord( )中使用;
3.ord( )和chr( )函数内的数据都是有限定的:ord( )内的字符串只能是单个字符,无论是英文还是中文,字符串的长度只能是1;chr( )函数内的整数必须大于0,在Pycharm内测试的范围为0*110000。以上两种情况如果出现会报错,如下图所示。
b=chr(-100)
print("使用chr()把-100转换为字符串:",b,id(b),type(b))
b=chr(10000000)
print("使用chr()把10000000转换为字符串:",b,id(b),type(b))


注意::
这里需要说明一下,chr( )和ord( )函数和之前讲的int( )、float( )、str( )函数是有区别的。
int( )和float( )可以将任意大小的整数形式字符串转化为整型和浮点型的数据,而ord( )只能将单个字符串转化为对应的ASCII码或Unicode码,该码的数据类型为整型。
str( )是将整数、浮点数、布尔值、列表、元组、字典等数据转化为字符串,而chr( )是将一定范围内的整数转化为ASCII码或Unicode码对应的单个字符。
测试:
a=chr(101)
print("chr(101):",a)
print(a,id(a),type(a))
b=str(101)
print("str(101):",b)
print(b,id(b),type(b))
c=int("101")
print(c,id(c),type(c))
d=float("101")
print(d,id(d),type(d))
f=ord("W")
print(f,id(f),type(f))
测试结果:
chr(101): e
e 2108867175344 <class 'str'>
str(101): 101
101 2108867372680 <class 'str'>
101 140735234940864 <class 'int'>
101.0 2108887930272 <class 'float'>
87 140735234940416 <class 'int'>
(2)字符串的创建和len( )函数
我们可以使用双引号或单引号对字符串进行创建。如果使用双引号创建的字符串内,也存在双引号,可以使用\"xxx\"格式,或者将双引号替换成单引号,以便计算机识别,防止报错。
我们可以使用三个连续的双引号或者单引号对多行字符串进行创建。
Python中允许空字符串的存在,其长度为0。
len( )内置函数的作用是测量字符串的长度。len( )内的参数只能是字符串、列表、字典、元组等。如果测量字符串的长度,字符串只能是一个。
注意:
创建多行字符串时,无论三个连续的引号内输入的是什么,计算机都会原样输出,也就说不存在语法和执行命令的问题,仅仅是字符串而已。
测试:
a="老高学Python"
print("字符串a的长度为:",len(a),a)
a=""
print("字符串a的长度为:",len(a))
resume="""name=gao age=17 experence=none int(10.334)"""
print(id(resume),type(resume))
print(resume)
测试结果:
字符串a的长度为: 9 老高学Python
字符串a的长度为: 0
2951552105712 <class 'str'>
name="gao" age=17 experence=none int(10.334)
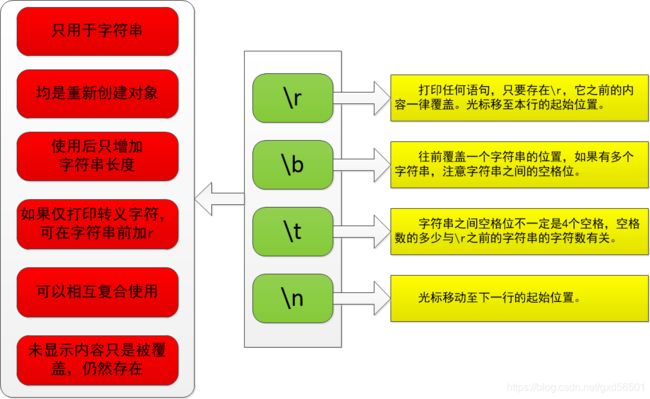
(3)转义字符
可以使用+特殊字符的形式来实现某些难以用字符表示的字符。
| 转义字符 | 说明 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \’ | 单引号 |
| \" | 双引号 |
| \b | 退格(Backspace) |
| \n | 换行 |
| \t | 横线制表符 |
| \r | 回车 |
\t和\n的测试:
print(r"转义字符换行符\n和制表符\t的使用:")
a = "明\t苍\n月\t茫\n出\t云\n天\t海\n山\t间\n,\t。"
print(a)
测试结果:
转义字符换行符\n和制表符\t的使用:
明 苍
月 茫
出 云
天 海
山 间
, 。
\r的测试:
print("测试使用\r后id、value、type、length是否一致")
a = "abcdefgh"
print("原有的a的相关信息:", "id=", id(a), "type=", type(a), "length=", len(a))
b = "\nabc\rdefgh"
print("原有的b的相关信息:", "id=", id(b), "type=", type(b), "length=", len(b))
print("判断a和b是否是同一对象?", a is b)
print("a和b的大小是否相等?", a == b)
print("打印a为:", a)
print("打印b为:", b)
测试结果:
测试使用\r后id、value、type、length是否一致
原有的a的相关信息: id= 2663455707056 type= <class 'str'> length= 8
原有的b的相关信息: id= 2663455789104 type= <class 'str'> length= 9
判断a和b是否是同一对象? False
a和b的大小是否相等? False
打印a为: abcdefgh
defgh
从结果可以发现:一个字符串如果加上转义字符,相当于重新创建了一个对象,而且转义字符也占一个字符位,会增加一个字符串的长度。如果加上\r就是将字符串的光标移动至该行的起始位置,\r之前的内容被覆盖但没有被删除,因为从打印的结果看,输出的字符串长度只在原有字符串长度的基础上增加了转义字符的占位。
测试 “print(“打印b为:”, b) ”这个语句时发现,打印结果为:defgh,而"打印b为:"这句话没被打印,不知道是什么原因,最后发现还是\r的原因,这个转义字符会把其之前的内容全部覆盖,这里我说的是全部,无论它前面输出的是什么,一律覆盖。随后我在此代码的基础上进行了改动,如下所示::
b = "\nabc\rdefgh"
print("打印b为:", b)
打印b为:
defgh
在字符串内增加了\n换行符,\r就只能覆盖本行的内容,上一行的"打印b为:"这句话就显示了。
\t的测试:
print("\t12345678")
print(0,"\t12345678")
print("01","\t12345678")
print("012","\t12345678")
print("-----------------------")
print("\t12345678")
print("1\t12345678")
print("12\t12345678")
print("123\t12345678")
print("1234\t12345678")
print("12345\t12345678")
print("123456\t12345678")
print("1234567\t12345678")
print("12345678\t12345678")
print("-----------------------")
print("123456789123456789")
print("姓名","\t\t年龄","\t出生年月","\t\t出生地")
print("苏东坡","\t\t24","\t\t1990.07","\t\t无锡")
print("李白","\t\t33","\t\t1960.07","\t\t哈尔滨")
print("杜甫","\t\t109","\t1999.03","\t\t齐齐哈尔")
print("肉孜.买买提","\t2","\t\t2009.12","\t\t乌鲁木齐")
print("-----------------------")
print("1234","\t1234")
print("1","\t1234")
print("12","\t1234")
print("123456","\t1234")
print("1234567","\t1234")
print("12345678","\t1234")
print("1234567891","\t1234")
print("12345678910","\t1234")
print("-----------------------")
print("1234","\t1234")
print("高","\t1234")
print("高高","\t1234")
print("高高高","\t1234")
print("高高高高","\t1234")
print("高高高高高","\t1234")
a="高"
print("字符串的长度为:",len(a))
print("UTF-8编码长度为:",len(a.encode()))
print("GBK编码长度为:",len(a.encode("GBK")))
测试结果:
12345678
0 12345678
01 12345678
012 12345678
-----------------------
12345678
1 12345678
12 12345678
123 12345678
1234 12345678
12345 12345678
123456 12345678
1234567 12345678
12345678 12345678
-----------------------
123456789123456789
姓名 年龄 出生年月 出生地
苏东坡 24 1990.07 无锡
李白 33 1960.07 哈尔滨
杜甫 109 1999.03 齐齐哈尔
肉孜.买买提 2 2009.12 乌鲁木齐
-----------------------
1234 1234
1 1234
12 1234
123456 1234
1234567 1234
12345678 1234
1234567891 1234
12345678910 1234
-----------------------
1234 1234
高 1234
高高 1234
高高高 1234
高高高高 1234
高高高高高 1234
字符串的长度为: 1
UTF-8编码长度为: 3
GBK编码长度为: 2
从上面测试的结果可以看出:如果使用\t时,\t代表的空格数可以通过用户设置改变,测试用的是4个空格。需要注意的是:如果\t前面的字符串与其后的字符串之间的空格数不是固定不变的,也就是说你使用\t时,不一定就是4个空格,如果制表符前面没有字符串,便是4个空格,如果有1个字符,则会有3个空格,2个字符则会有2个空格,以此类推。从运算的角度分析,如果制表符前面的字符串的个数能被4整除,则有4个空格,divmod(len(a)/4)=(商,余数),if余数=0,空格数=4;if4>余数>0的整数(4的整数余数只有1、2、3),则空格数=4-余数。
如果是汉字,则一个汉字占两个空格。
print("高\t1234")
print("高高\t1234")
print("高高高\t1234")
print("高高高高\t1234")
print("高高高高高\t1234")
高 1234
高高 1234
高高高 1234
高高高高 1234
高高高高高 1234
这么排版看着更清楚点。
print("测试汉字在一个字符串内,和不在一个字符串内的间隔区别")
print("高高\t1234\t1111")
print("1234高高\t1111")
print("高高\t高34\t1111")
测试汉字在一个字符串内,和不在一个字符串内的间隔区别
高高 1234 1111
1234高高 1111
高高 高34 1111
这里有个梗一直没弄明白,在以后的学习中慢慢理解吧:len()的长度,字符所占的字节,字符占的空格数,这三个东西很让人纠结!!!
https://baijiahao.baidu.com/s?id=1664825991403275797&wfr=spider&for=pc(这篇文章写的很好)
https://www.jianshu.com/p/7dd4a545e030
https://blog.csdn.net/weixin_34062469/article/details/93608232
上面的网址后面可以自己测试下。
\b的测试:
print("十年生死两茫茫",",不思量","自难忘")
print(r"加上退格符\b后为:")
print("十年生死两茫茫\b",",不思量",",自难忘")
print("十年生死两茫茫\b","\b,不思量",",自难忘")
print("十年生死两茫",",不思量",",自难忘")
测试结果:
十年生死两茫茫 ,不思量 自难忘
加上退格符\b后为:
十年生死两茫 ,不思量 ,自难忘
十年生死两茫,不思量 ,自难忘
十年生死两茫 ,不思量 ,自难忘
在这个测试中发现一个问题:第三个和第四个语句虽然结果一样,但是并没有对齐,退格符\b覆盖的是什么呢?
print("123456","1234","123")
print("123456","1234",",123")
print("123456","1234",",123")
print("123456\b","\b1234",",123")
print("123456\b","\b1234",",\b123")
print("123456\b","\b1234","\b,123")
123456 1234 123
123456 1234 ,123
123456 1234 ,123
123451234 ,123
123451234 123
123451234,123
使用数字测试时,如果不适用\b,两个字符串之间存在一个空格位,如果两个字符串如同这样:“xxxx\b”,"\bxxx",打印时第一个\b退回一个x,第二个\b仅退回一个空格。这和起初认为的和使用全角字符没有关系,全角的逗号只是占了两个位置,不是导致两个打印结果未对其的原因。
本来想使用len()函数测量两个语句的长度:
print("十年生死两茫茫\b",",不思量",",自难忘")
print("十年生死两茫茫\b","\b,不思量",",自难忘")
但是len()函数无法测量多个字符串的长度,只能测量单个字符串的长度,所以又想用字符串的拼接功能,但是拼接之后,多个字符串变成了一个单独的字符串,字符串之间没有空格位分隔。
综上所述,打印多个字符串时,字符串之间存在空格位,使用退回符\b时要注意。与制表符\t和回车符\r相比,它们就不存在这个空格的问题。
在不断实验的过程中,还是有收获的,能更加深刻的理解之前所学的内容,再简单的语句也要自己亲手敲一遍。
(4)字符串拼接和复制
可以使用符号"+"将多个字符串拼接起来。需要注意的是:符号"+"左右两边必须都是字符串,才能实现拼接,如果数据类型不同,则会出现报错。也可以将符号"+"略掉,使用空格隔开,直接将字符串放到一起实现拼接。
在上面的测试中已经提到,字符串的拼接是将多个字符串拼接为一个独立的字符串,字符串之间没有空格位。
测试:
a="123456"+"1234"+"123"
print(a)
b="123456"+"1234"+",123"
print(b)
c="123456"+"1234"+",\b123"
print(c)
print(len(a),len(b),len(c))
测试结果:
1234561234123
1234561234,123
1234561234123
13 14 15
可以使用乘号“*”来实现字符串的复制,在第二节上的运算符使用介绍里已经提到。
(5)不换行打印和控制台读取字符串
在调用print()函数时,一个print()函数在执行完毕时会自动打印一个换行符\n,这是默认的,但是在有些情况,我们不希望其换行,那么我们就可以使用参数end=“字符串”,来实现末尾添加任意内容,从另一个角度讲,用end参数实现了print()函数末尾换行符\n的替换。
测试:
print("-----------------------",end=" ")
print("112233345",end="\t")
print("aabbcc",end="Peach blossoms begin to bloom in the temple.")
print("-----------------------")
测试结果:
----------------------- 112233345 aabbccPeach blossoms begin to bloom in the temple.-----------------------
从测试结果可以发现,end参数可以实现对print()函数进行同一行的拼接,而且end="字符串"中的字符串可以是任意的字符串。
我们可以使用input( )函数从控制台读取键盘输入的数据,返回一个字符串类型的数据。
测试:
print("-----------------------")
print(input("谁在敲门?"),end="——主人说。\t")
print(input("你能给我开门吗?"),end="——陌生人说。\t")
print("-----------------------")
测试结果:
-----------------------
谁在敲门?是我
是我——主人说。 你能给我开门吗?不能
不能——陌生人说。 -----------------------
从测试结果可以发现,input( )函数会被执行后才能执行下一个命令,所以上面的例子中end参数会在input( )函数执行后才执行。
测试:
print("-----------------------")
a=input("输入一个内容:")
print(a,id(a),type(a))
a=input("输入一个内容:")
print(a,id(a),type(a))
a=input("输入一个内容:")
print(a,id(a),type(a))
a=input("输入一个内容:")
print(a,id(a),type(a))
a=input("输入一个内容:")
print(a,id(a),type(a))
a=input("输入一个内容:")
print(a,id(a),type(a))
输入一个内容:-10989
-10989 1948483872168 <class 'str'>
输入一个内容:False
False 1948483872224 <class 'str'>
输入一个内容:44459e-4
44459e-4 1948504412016 <class 'str'>
输入一个内容:33,,896
33,,896 1948484666960 <class 'str'>
输入一个内容:3//5*3**4
3//5*3**4 1948504412016 <class 'str'>
输入一个内容:附近溜达
从测试的结果可以发现,input函数输入的内容无论是什么类型的数据,都会返回为字符串,并且不进行计算。
(6)字符串的提取和replace替换
字符串的本质就是字符序列,每个字符都有自己的索引编号,也叫偏移量。我们可以在字符串标识符后面添加[ ],[ ]内添加索引编号(偏移量),就可以提取该位置的单个字符。
在Python中,可以实现正向或逆向搜索字符:
正向搜索:从最左侧第一个字符开始计算,起始索引编号或偏移量为0,第二个为1,以此类推,直到len(str)-1为止。
逆向搜索:从最右侧第一个字符开始计算,起始索引号或偏移量为-1,第二个为-2,以此类推,直到-len(str)为止。
a="丝桐合为琴,中有太古声。"
print(a[0],a[1],a[2],a[3],a[4],a[5],a[6]\
,a[7],a[8],a[9],a[10],a[11])
print(a[-len(a)])
print(a[0],id(a[0]),type(a[0]))
print(a[1],id(a[1]),type(a[1]))
print(a[11],id(a[11]),type(a[11]))
丝 桐 合 为 琴 , 中 有 太 古 声 。
丝
丝 2020137329168 <class 'str'>
桐 2020137329168 <class 'str'>
。 2020137329168 <class 'str'>
字符串是“不可变的”,但是有时我们想修改字符串的数据内容,可以使用replace( )函数来实现,其格式为:标识符.replace( “原字符串内某序列”,“替换的内容” )。
测试:
a="丝桐合为琴,中有太古声。"
print(a[0],a[1],a[2],a[3],a[4],a[5],a[6]\
,a[7],a[8],a[9],a[10],a[11])
print(a[-len(a)])
print(a[0],id(a[0]),type(a[0]))
print(a[1],id(a[1]),type(a[1]))
print(a[11],id(a[11]),type(a[11]))
print(a[11])
print(id(a))
print("-----------------------")
print(a.replace("。","&&&"))
print(id(a),id(a.replace("。","&&&")))
print(id(a) is id(id(a.replace("。","&&&"))))
测试结果:
丝 桐 合 为 琴 , 中 有 太 古 声 。
丝
丝 1983723859760 <class 'str'>
桐 1983723859760 <class 'str'>
。 1983723859760 <class 'str'>
。
1983723865984
-----------------------
丝桐合为琴,中有太古声&&&
1983723865984 1983723865776
False
从测试结果可以发现,使用replace( )函数时,原字符串的地址并没有改变,内容也没改变,replace( )函数只是重新创建了一个做了内容替换的新对象,自然原来的和修改的字符串的ID不同。
这里有个问题待解决,就是为什么字符串内的字符序列的ID地址和字符串本身的ID地址不一样呢?
(7)字符串的切片slice、分割split( )和拼接join( )
切片slice操作可以让我们快速提取字符串,其格式为:
标识符[ 起始偏移量:终止偏移量:步长 ]
标识符[ start:end:step ]
测试:
print("-----------------------")
a="古声淡无味,不称今人情。"
print(a[0:len(a)-1:1])
print(a[0:len(a)-1])
print(a[1:len(a)-1:2])
print(a[1:len(a)-1:2])
print(a[:5])
print(a[:])
print(a[::2])
print(a[:2])
print("-----------------------")
测试结果:
-----------------------
古声淡无味,不称今人情
古声淡无味,不称今人情
声无,称人
声无,称人
古声淡无味
古声淡无味,不称今人情。
古淡味不今情
古声
-----------------------
测试:
print("-----------------------")
a="前月只此月,后月亦此月"
print(len(a))
print(a[-1:-11:-1])
print(a[-11:-1:1])
print(a[-11:100:1])
print("-----------------------")
测试结果:
-----------------------
11
月此亦月后,月此只月
前月只此月,后月亦此
前月只此月,后月亦此月
-----------------------
这里需要注意的是:
1.slice是"包头不包尾",意思是start和end只包括开始,不包括结尾,上面的例子中第一个和第二个语句没有句号就是因为这个原因;
2.使用[:]时是表示选取字符串的所有内容,这里就没有"包头不包尾"的问题;
3.在slice操作时,[ ]括号内的start、end和step必须是索引编号(偏移量),不能是字符串形式"xxx",否则报错,如代码所示。
4.步长step取正数时是从左到右提取字符,取负数时是从右到左提取字符,如果不显示参数步长,默认为1。
5.步长的正负一定要与start和end的索引序列方向一致,比如说,a[0:9],偏移量是向右移动的,那么步长取值必须是从左到右,也就是正的,系统才不会报错。
测试:
print(a[:"不"])
测试结果:
print(a[:"不"])
TypeError: slice indices must be integers or None or have an __index__ method
这里有个问题待解决,估计在后期学习中会得到答案。一个字符串内包含汉字和英文数字,汉字的索引序列的id始终是一样的,而数字和英文的索引序列的id,除非是相同的数字或字母,那么它们的id是不同的,这是什么原因?而且只有汉字的id和整个字符串的id一致,其它的数字和英文都和原字符串的id不一样?
测试:
a="我jjkk12我取我的jjkk221"
print(id(a))
print(id(a[0]),0)
print(id(a[1]),1)
print(id(a[2]),2)
print(id(a[3]),3)
print(id(a[4]),4)
print(id(a[5]),5)
print(id(a[6]),6)
print(id(a[7]),7)
print(id(a[8]),8)
print(id(a[9]),9)
print(id(a[10]),10)
print(id(a[11]),11)
print(id(a[12]),12)
print(id(a[13]),13)
print(id(a[14]),14)
print(id(a[15]),15)
print(id(a[16]),16)
print(id(a[17]),17)
测试结果:
1679901704648
1679904759856 0
1679904868648 1
1679904868648 2
1679901890968 3
1679901890968 4
1679901734088 5
1679905460496 6
1679904759856 7
1679904759856 8
1679904759856 9
1679904759856 10
1679904868648 11
1679904868648 12
1679901890968 13
1679901890968 14
1679905460496 15
1679905460496 16
1679901734088 17
split( )可以基于指定分隔符将字符串分割成多个子字符串,并存储到列表中,如果不指定分隔符,则默认使用空白字符(换行符\n空格和制表符\t)。
测试:
a="to be or not to be"
print(a.split())
print(a.split("o"))
print(a.split("t"))
print(a.split("b"))
测试结果:
['to', 'be', 'or', 'not', 'to', 'be']
['t', ' be ', 'r n', 't t', ' be']
['', 'o be or no', ' ', 'o be']
['to ', 'e or not to ', 'e']
如果split( )括号内的分隔符在字符串内不存在,那么会将字符串整体放入列表中。
测试:
a="to be or not to be"
print(a.split("1"))
['to be or not to be']
如果split( )括号内的分隔符为int、float、bool,那么系统会报错,因为分隔符只能为str类型或者什么都没有None。
测试:
a="to be or not to be"
print(a.split(1.1))
print(a.split(1.1))
TypeError: must be str or None, not float
join( )函数通常和列表一起使用,用来将列表内的字符串拼接在一起,其格式为:“字符串”.join(列表标识符)。join( )也可以与单独的字符串组合使用,实现单独字符串内每个索引序列与其它字符串的拼接效果。
测试:
a="to be or not to be"
b="@@"
print(b.join(a))
测试结果:
t@@o@@ @@b@@e@@ @@o@@r@@ @@n@@o@@t@@ @@t@@o@@ @@b@@e
测试:
li_a=["醉里","挑灯看剑",",","梦回吹","角连","营","。"]
print("\n".join(li_a))
print(" 1221 ".join(li_a))
print("\b".join(li_a))
测试结果:
醉里
挑灯看剑
,
梦回吹
角连
营
。
醉里 1221 挑灯看剑 1221 , 1221 梦回吹 1221 角连 1221 营 1221 。
醉挑灯看梦回角。
这里需要注意的是:到目前为止,字符串的拼接学到了两种方法,一种是使用拼接符“+”,另一种就是join( )函数,两种方法都能实现字符串的拼接,但是如果涉及大量运算,考虑性能效率时,尽量使用join( )函数,因为“+”拼接符使用一次就会重新创建一次对象,而join( )函数在拼接前,就会计算好所有字符串的长度,并逐一拷贝,仅新建一次对象。
测试:
li_a=["醉里","挑灯看剑",",","梦回吹","角连","营","。"]
print("\n".join(li_a))
print(" 1221 ".join(li_a))
print("\b".join(li_a))
测试结果:
醉里
挑灯看剑
,
梦回吹
角连
营
。
醉里 1221 挑灯看剑 1221 , 1221 梦回吹 1221 角连 1221 营 1221 。
醉挑灯看梦回角。
对照视频操作拼接符“+”和 join( ) 函数在性能效率方面的差异:
测试:
import time
time_01=time.time()
a="我"
for i in range(1000000):
a+="txt"
time_02=time.time()
time_03=time_02-time_01
print(time_03)
time_04=time.time()
li=[]
for i in range(1000000):
li.append("txt")
a="".join(li)
time_05=time.time()
time_06=time_05-time_04
print(time_06)
测试结果:
2.49920654296875
0.16201353073120117
从测试结果看,两个拼接方法在使用效率方面差距还是很大的。但是在编写上面代码时,虽然补习了for循环、range( )函数和append( )函数的使用方法,但是始终没弄明白for和range一起使用时,变量调取和运算的机理,特别是老师在写这个语句:a+="txt",很是纳闷,这个变量 a 和 i 是怎么迭代的?为什么变量 a 不用在for之前进行定义?在后面代码中使用 join( )拼接时,又发现a="".join(li)为什么不在循环语句内,因为没有打印具体结果,所以不清楚这里是最后进行拼接还是在循环内拼接?
(8)字符串的驻留机制和字符串的比较
字符串的驻留是指在内存中只保存一份相同且不可变字符串的方法。对于符合标识符规则(字母、数字、下划线)的字符串会启用驻留机制。
测试:
str1="aa"
str2="bb"
str3=str1+str2
print(str3 is "aabb")
print(str3 == "aabb")
print("aabb" in str3)
测试结果:
False
True
True
字符串的比较指的就是之前学过的is和==,即比较两个变量是否是同一对象,两个变量的值是否相等。
https://www.cnblogs.com/jiyongjia/p/9539024.html
上面的网址总结了字符串的运算和占位符,感觉总结的不错,在后面学习过程中可以参考。
(9)字符串常用方法汇总
1.字符串的常用查找方法
| 函数 | 说明 |
|---|---|
| len(“字符串”) | 测试字符串的长度 |
| str.startswith(“字符串”) | 判断是否为指定字符串开头,结果为True/False |
| str.endswith(“字符串”) | 判断是否为指定字符串结尾,结果为True/False |
| str.find(“字符串”) | 从左到右查找第一次出现某字符为止,结果为某字符 |
| str.rfind("字符串“) | 从右到左查找第一次出现某字符为止,结果为某字符 |
| str.count(“字符串”) | 指定字符串出现的次数 |
| str.isalnum(“无参数”) | 判断字符串是否全是字母或数字或数字和字母,结果为True/False |
| str.strip(“字符串”) | 去除字符串首尾的指定信息 |
| str.lstrip(“字符串”) | 去除字符串首部指定信息 |
| str.lstrip(“字符串”) | 去除字符串尾部指定信息 |
测试:
str1="皑如山上雪,皎若云间月。\n\
aabb22289\n\
闻君有两意,故来相决绝。\n\
DDFIJG87F\
今日斗酒会,明旦沟水头。\n\
NNBVO62jfk\
愿得一心人,白头不相离。\n\
fjklaj21314"
print(len(str1))
print(str1.startswith("皑如上山"))
print(str1.startswith("皑如山上"))
print(str1.endswith("冰箱里"))
print(str1.endswith("不相离"))
print(str1.find("水"))
print(str1.rfind("水"))
print(str1.rfind("314"))
print(str1.find("水头。"))
print(str1.isalnum())
a="99weigong"
print(a.isalnum())
print(a.strip("9"))
b="###高#####"
print(b.strip("#"))
print(b.lstrip("#"))
print(b.rstrip("#"))
print("---------------------------")
c="** %%\ntianpeizi\n%% *****"
print(c.strip(" "))
print("---------------------------")
c="** %%tianpeizi\n %% *****"
print(c.strip(" "))
print("---------------------------")
print(c.strip("%"))
print("---------------------------")
print(c.strip("*"))
print("---------------------------")
测试结果:
93
False
True
False
False
54
54
90
54
False
True
weigong
高
高#####
###高
---------------------------
** %%
tianpeizi
%% *****
---------------------------
** %%tianpeizi
%% *****
---------------------------
** %%tianpeizi
%% *****
---------------------------
%%tianpeizi
%%
---------------------------
isalnum=is+alpha+number
2.字符串大小写转化方法
| 函数 | 说明 |
|---|---|
| str.capitalize() | 产生新的字符串,首字母大写 |
| str.title() | 产生新的字符串,每个单词的首字母大写 |
| str.upper() | 产生新的字符串,所有字符转化为大写 |
| str.lower() | 产生新的字符串,所有字符转化为小写 |
| str.swapcase | 产生新的字符串,所有字符大小写转化 |
测试:
str="whenever you need me, I'll be here。"
print(str.isalnum())
print(str.capitalize())
print(str.upper())
print(str.lower())
print(str.swapcase())
测试结果:
False
Whenever you need me, i'll be here。
WHENEVER YOU NEED ME, I'LL BE HERE。
whenever you need me, i'll be here。
WHENEVER YOU NEED ME, i'LL BE HERE。
3.字符串的格式排版方法
| 函数 | 说明 |
|---|---|
| str.center() | 居中对齐 |
| str.ljust() | 左对齐 |
| str.rjust() | 右对齐 |
测试:
str="ruin"
print(str.center(11,"%"))
print(str.ljust(5,"#"))
print(str.rjust(8,"("))
print(str.rjust(8,"0"))
测试结果:
%%%%ruin%%%
ruin#
((((ruin
0000ruin
4.字符串的is判断方法
| 函数 | 说明 |
|---|---|
| str.isalnum() | 是否为字母或数字 |
| str.isalpha() | 检测字符串是否由字母(包括汉字)组成 |
| str.isdigit() | 检测字符串是否由数字组成 |
| str.isspace() | 检测字符串是否为空白符 |
| str.isupper() | 检测字符串是否为大写字母 |
| str.islower() | 检测字符串是否为小写字母 |
测试:
a="3.144,214"
print(a.isdigit())
a="3.144214"
print(a.isdigit())
a="33341"
print(a.isdigit())
print(a.isspace())
a="\t\nfjlkd"
print(a.isspace())
a="\t\n"
print(a.isspace())
a="ABCDefg"
print(a.isupper())
print(a.islower())
a="12356721"
print(a.isupper())
a="关关雎鸠"
print(a.isalpha())
a="关关雎鸠fjkd"
print(a.isalpha())
a="关关雎鸠fjkd12"
print(a.isalpha())
测试结果:
False
False
True
False
False
True
False
False
False
True
True
False
(10)字符串的格式化
字符串的格式化就是将指定字符串替换为指定格式,在Python中使用str.format( )函数对指定位置的字符串进行格式化,也就是说将指定位置的字符串用{}表示,然后用format()函数进行替换,这就是所谓的格式化。
测试:
a="我叫:{0},我今年:{1}岁了"
a.format("老高",18)
print(a)
a="我叫{name},我今年{age}岁了"
a.format(name="老高",age=18)
print(a)
print("---------------------------1")
print("我叫{0},今年{1}".format("老高",22))
print("---------------------------2")
a="我叫{0},今年{1}岁。"
print(a.format("老高",22))
print("---------------------------3")
a="我叫{},今年{}岁。"
print(a.format("老高",22))
print("---------------------------4")
a="我爱吃{0},不爱吃{1},非常讨厌吃{1}"
print(a.format("苹果","萝卜"))
a="我爱吃{1},不爱吃{1},非常讨厌吃{0}"
print(a.format("苹果","萝卜"))
print("---------------------------5")
a="我爱吃{fruit},不爱吃{vegetable},非常讨厌吃{vegetable}"
print(a.format(fruit="苹果",vegetable="萝卜"))
测试结果:
我叫:{
0},我今年:{
1}岁了
我叫{
name},我今年{
age}岁了
---------------------------1
我叫老高,今年22
---------------------------2
我叫老高,今年22岁。
---------------------------3
我叫老高,今年22岁。
---------------------------4
我爱吃苹果,不爱吃萝卜,非常讨厌吃萝卜
我爱吃萝卜,不爱吃萝卜,非常讨厌吃苹果
---------------------------5
我爱吃苹果,不爱吃萝卜,非常讨厌吃萝卜
从测试结果可以发现,起初按照所学资料在Pycharm里进行测试,发现打印输出的结果不对,a="我叫:{0},我今年:{1}岁了" ----a.format("老高",18) ----print(a)
后来发现我在打印时,其实打印的是a="我叫:{0},我今年:{1}岁了",而不是格式化后的a,所以,在Pycharm中如果只写a.format("老高",18),解析器不会直接执行,而在print( )函数内才会执行a.format("老高",18)语句。
format( )函数是与花括号{ }一起使用的,{ }是表示可替代字符串的位置,花括号内的参数有三种形式:1.空。如果{ }参数是空的,那么表示format( )内替换的内容按照顺序依次替换;2.索引号。{ }参数是索引号,那么format( )内替换的内容也是一次顺序的索引号与之对应;3.变量名。
第一种情况:
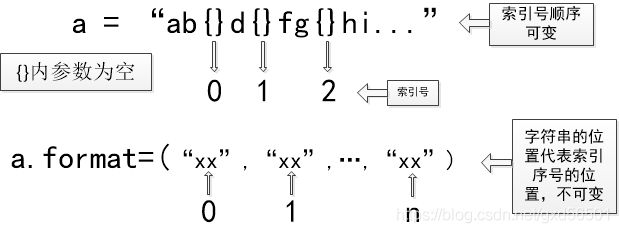
第二种情况:
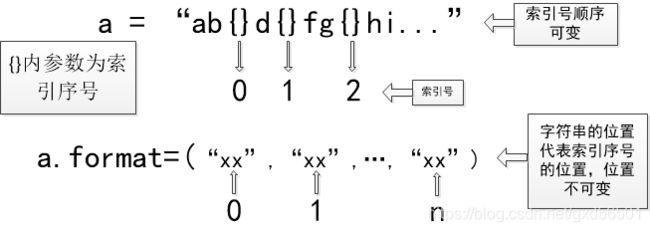
第三种情况:

比较三种方法,用赋值语句对字符串进行格式化更加灵活方便。
(11)字符串的填充与对齐
填充物:可以填充任意字符。
对齐符:^、<、>分别表示居中、左对齐、右对齐。
占位数:指字符串和填充物总共占的位数。
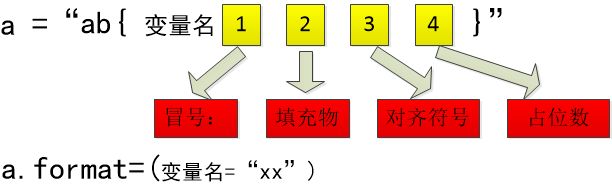
变量名可以省略,如上面所说的第一种情况,但是format()内字符串的索引顺序,必须与格式化的顺序一致,即与{ }占位顺序一致。
测试:
print("---------------------------1")
a="我喜欢{str1:&^9}运动,我不喜欢{str2: <11}运动,我的朋友王亮喜欢{str3:+>12}"
print(a.format(str1="跑步",str2="游泳",str3="健美"))
print("---------------------------2")
a="我喜欢{:&^9}运动,我不喜欢{: <11}运动,我的朋友王亮喜欢{:+>12}"
print(a.format("跑步","游泳","健美"))
print("---------------------------3")
a="我们都是{:+<8},我们应该爱护{:*^8},如果我们不保护{:0^6},我们终将被{:!>12}destroy"
print(a.format("动物","地球","环境","自己"))
print("---------------------------4")
a="我们都是{0:+<8},我们应该爱护{3:*^8},如果我们不保护{3:0^6},我们终将被{1:!>12}destroy"
print(a.format("动物","地球","环境","自己"))
测试结果:
---------------------------1
我喜欢&&&跑步&&&&运动,我不喜欢游泳 运动,我的朋友王亮喜欢++++++++++健美
---------------------------2
我喜欢&&&跑步&&&&运动,我不喜欢游泳 运动,我的朋友王亮喜欢++++++++++健美
---------------------------3
我们都是动物++++++,我们应该爱护***地球***,如果我们不保护00环境00,我们终将被!!!!!!!!!!自己destroy
---------------------------4
我们都是动物++++++,我们应该爱护***自己***,如果我们不保护00自己00,我们终将被!!!!!!!!!!地球destroy
(12)数字的格式化
| 函数 | 说明 |
|---|---|
| {:.2f} | 表示小数点后保留两位小数。 |
| {:.0f} | 表示小数点后没有小数,包括小数点也没有。 |
| {:+.2f} | 表示带符号(“+”与数字的正负无关,仅代表保留数字的正负符号)输出小数,且保留小数点后两位。 |
| {:d} | 表示以十进制形式输出,但是如果format()内的数为小数,则不能以整数形式输出,通常用与对齐填充命令组合使用。 |
| {:b} | 表示以二进制形式输出。 |
| {:#b} | 表示开头带“0b”标识输出二进制数。 |
| {} | 表示以八进制形式输出。 |
| {:#o} | 表示开头带“0o”标识输出八进制数。 |
| {:x} | 表示以十六进制形式输出。 |
| {:#x} | 表示开头带“0x”标识输出十六进制数。 |
| {:e} | 表示以科学计数法形式输出。 |
| {:%} | 表示以百分比形式输出。 |
| {:,} | 表示以逗号分隔数字格式。(必须千位以上才能显示逗号) |
测试:
print("---------填充、对齐与数字格式化的符合使用-------")
print("{:x}".format(1000))
print("{:%<20x}".format(1000))
print("{:%<20b}".format(1000))
print("{:%<20d}".format(1000))
print("{:%<20o}".format(1000))
print("{:%<20f}".format(1000))
print("{:%<20.2f}".format(1000))
"""format也可以实现进制的转化,将其它进制的数转化为指定进制类型"""
测试结果:
---------填充、对齐与数字格式化的符合使用-------
3e8
3e8%%%%%%%%%%%%%%%%%
1111101000%%%%%%%%%%
1000%%%%%%%%%%%%%%%%
1750%%%%%%%%%%%%%%%%
1000.000000%%%%%%%%%
1000.00%%%%%%%%%%%%%
需要注意:
1.以上的数字化格式类型都可以和填充对齐混合使用;
2.format( )函数可以实现数据进制类型的转化,但是前提是你必须让计算机识别format( )内数字的类型,这种转化是不同进制间的直接转化,与之前学过(第二节上的标题3)的0b/0o/0x+整数的转化有明显区别,之前这种形式只是转化为十进制,不能实现不同进制的直接转化。
测试:
print("---------进制间的转化-------")
print("{:x}".format(0o1000))
print("{:o}".format(0b1000))
print("{:b}".format(0x1000))
print(0o1000)
print(0x512)
测试结果:
---------进制间的转化-------
200
10
1000000000000
512
1298