python 小数相乘_python-铁
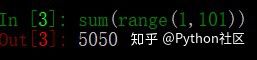
1、一行代码实现1--100之和
利用sum()函数求和
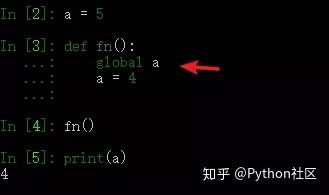
2、如何在一个函数内部修改全局变量
利用global在函数声明 修改全局变量
3、列出5个python标准库
os:提供了不少与操作系统相关联的函数
sys: 通常用于命令行参数
re: 正则匹配
math: 数学运算
datetime:处理日期时间
4、字典如何删除键和合并两个字典
del和update方法

5、谈下python的GIL
GIL 是python的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行python程序的时候会霸占python解释器(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
多进程中因为每个进程都能被系统分配资源,相当于每个进程有了一个python解释器,所以多进程可以实现多个进程的同时运行,缺点是进程系统资源开销大
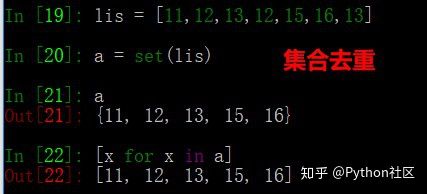
6、python实现列表去重的方法
先通过集合去重,在转列表
7、fun(*args,**kwargs)中的*args,**kwargs什么意思?


8、python2和python3的range(100)的区别
python2返回列表,python3返回迭代器,节约内存
9、一句话解释什么样的语言能够用装饰器?
函数可以作为参数传递的语言,可以使用装饰器
10、python内建数据类型有哪些
整型--int
布尔型--bool
字符串--str
列表--list
元组--tuple
字典--dict
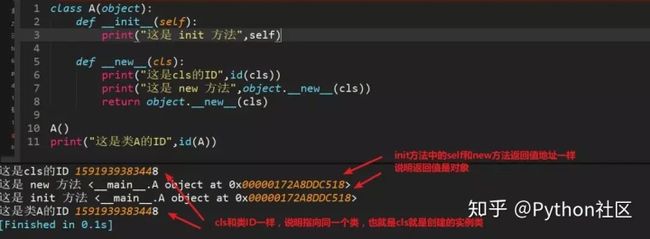
11、简述面向对象中__new__和__init__区别
__init__是初始化方法,创建对象后,就立刻被默认调用了,可接收参数,如图

1、__new__至少要有一个参数cls,代表当前类,此参数在实例化时由Python解释器自动识别
2、__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类(通过super(当前类名, cls))__new__出来的实例,或者直接是object的__new__出来的实例
3、__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值
4、如果__new__创建的是当前类的实例,会自动调用__init__函数,通过return语句里面调用的__new__函数的第一个参数是cls来保证是当前类实例,如果是其他类的类名,;那么实际创建返回的就是其他类的实例,其实就不会调用当前类的__init__函数,也不会调用其他类的__init__函数。
12、简述with方法打开处理文件帮我我们做了什么?
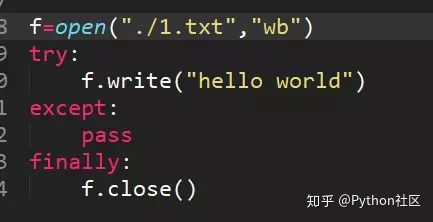
打开文件在进行读写的时候可能会出现一些异常状况,如果按照常规的f.open
写法,我们需要try,except,finally,做异常判断,并且文件最终不管遇到什么情况,都要执行finally f.close()关闭文件,with方法帮我们实现了finally中f.close
(当然还有其他自定义功能,有兴趣可以研究with方法源码)
13、列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25],并使用列表推导式提取出大于10的数,最终输出[16,25]
map()函数第一个参数是fun,第二个参数是一般是list,第三个参数可以写list,也可以不写,根据需求

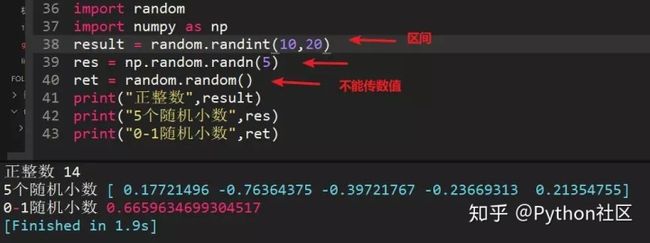
14、python中生成随机整数、随机小数、0--1之间小数方法
随机整数:random.randint(a,b),生成区间内的整数
随机小数:习惯用numpy库,利用np.random.randn(5)生成5个随机小数
0-1随机小数:random.random(),括号中不传参
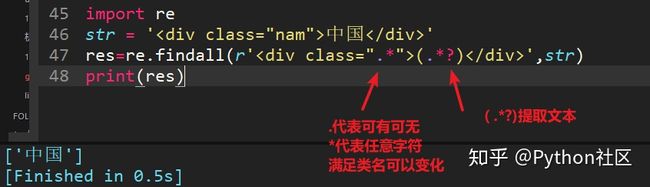
15、避免转义给字符串加哪个字母表示原始字符串?
r , 表示需要原始字符串,不转义特殊字符
16、
17、python中断言方法举例
assert()方法,断言成功,则程序继续执行,断言失败,则程序报错
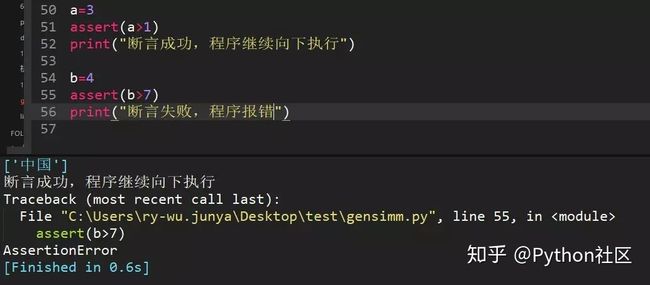
18、数据表student有id,name,score,city字段,其中name中的名字可有重复,需要消除重复行,请写sql语句
select distinct name from student
19、10个Linux常用命令
ls pwd cd touch rm mkdir tree cp mv cat more grep echo
20、python2和python3区别?列举5个
1、Python3 使用 print 必须要以小括号包裹打印内容,比如 print('hi')
Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比 如 print 'hi'
2、python2 range(1,10)返回列表,python3中返回迭代器,节约内存
3、python2中使用ascii编码,python中使用utf-8编码
4、python2中unicode表示字符串序列,str表示字节序列
python3中str表示字符串序列,byte表示字节序列
5、python2中为正常显示中文,引入coding声明,python3中不需要
6、python2中是raw_input()函数,python3中是input()函数
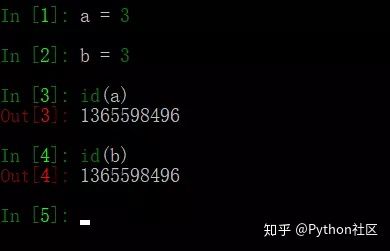
21、列出python中可变数据类型和不可变数据类型,并简述原理
不可变数据类型:数值型、字符串型string和元组tuple
不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象(一个地址),如下图用id()方法可以打印对象的id
可变数据类型:列表list和字典dict;
允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。

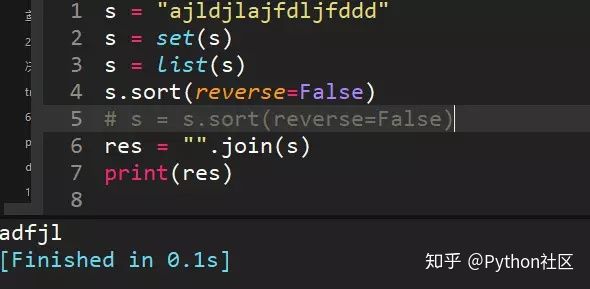
22、s = "ajldjlajfdljfddd",去重并从小到大排序输出"adfjl"
set去重,去重转成list,利用sort方法排序,reeverse=False是从小到大排
list是不 变数据类型,s.sort时候没有返回值,所以注释的代码写法不正确
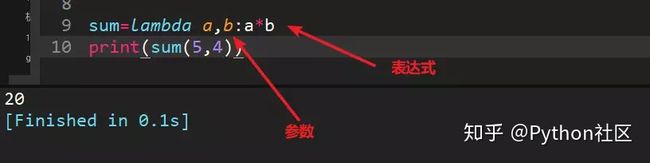
23、用lambda函数实现两个数相乘
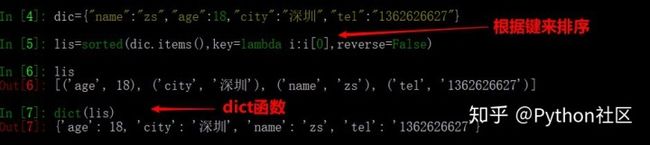
24、字典根据键从小到大排序
dic={"name":"zs","age":18,"city":"深圳","tel":"1362626627"}
25、利用collections库的Counter方法统计字符串每个单词出现的次数"kjalfj;ldsjafl;hdsllfdhg;lahfbl;hl;ahlf;h"

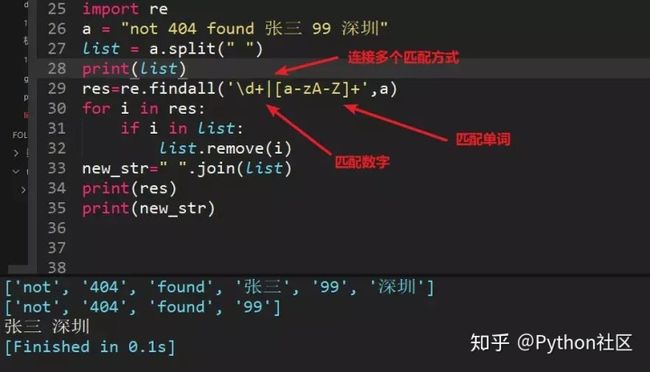
26、字符串a = "not 404 found 张三 99 深圳",每个词中间是空格,用正则过滤掉英文和数字,最终输出"张三 深圳"
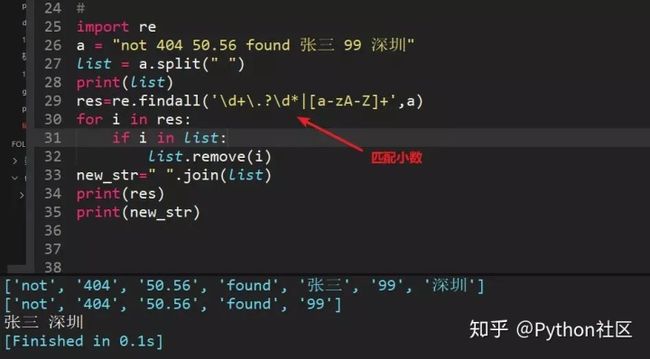
顺便贴上匹配小数的代码,虽然能匹配,但是健壮性有待进一步确认
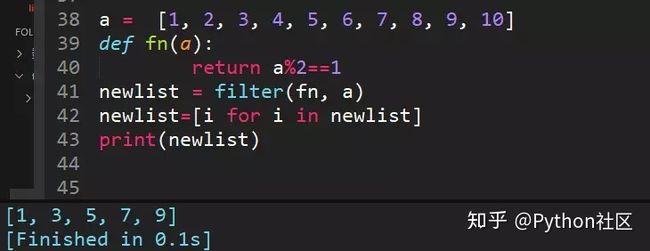
27、filter方法求出列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表
28、列表推导式求列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
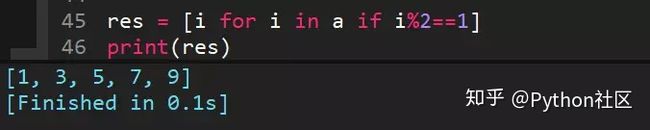
29、正则re.complie作用
re.compile是将正则表达式编译成一个对象,加快速度,并重复使用
30、a=(1,)b=(1),c=("1") 分别是什么类型的数据?

31、两个列表[1,5,7,9]和[2,2,6,8]合并为[1,2,2,3,6,7,8,9]
extend可以将另一个集合中的元素逐一添加到列表中,区别于append整体添加

32、用python删除文件和用linux命令删除文件方法
python:os.remove(文件名)
linux: rm 文件名
33、log日志中,我们需要用时间戳记录error,warning等的发生时间,请用datetime模块打印当前时间戳 “2018-04-01 11:38:54”
顺便把星期的代码也贴上了

34、数据库优化查询方法
外键、索引、联合查询、选择特定字段等等
35、请列出你会的任意一种统计图(条形图、折线图等)绘制的开源库,第三方也行
pyecharts、matplotlib
36、写一段自定义异常代码
自定义异常用raise抛出异常
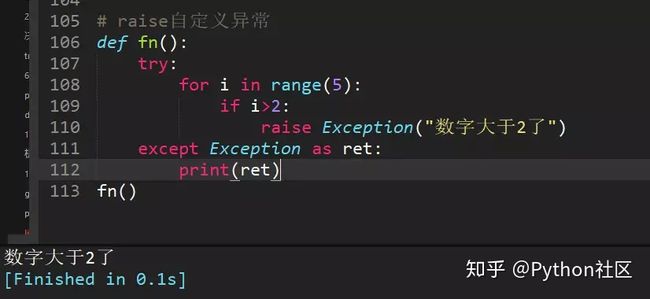
37、正则表达式匹配中,(.*)和(.*?)匹配区别?
(.*)是贪婪匹配,会把满足正则的尽可能多的往后匹配
(.*?)是非贪婪匹配,会把满足正则的尽可能少匹配

38、简述Django的orm
ORM,全拼Object-Relation Mapping,意为对象-关系映射
实现了数据模型与数据库的解耦,通过简单的配置就可以轻松更换数据库,而不需要修改代码只需要面向对象编程,orm操作本质上会根据对接的数据库引擎,翻译成对应的sql语句,所有使用Django开发的项目无需关心程序底层使用的是MySQL、Oracle、sqlite....,如果数据库迁移,只需要更换Django的数据库引擎即可

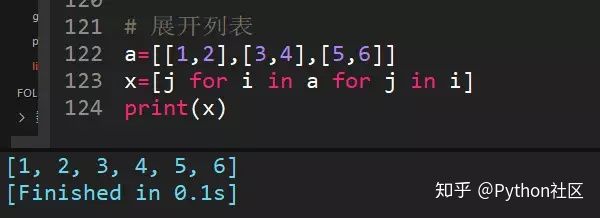
39、[[1,2],[3,4],[5,6]]一行代码展开该列表,得出[1,2,3,4,5,6]
列表推导式的骚操作
运行过程:for i in a ,每个i是【1,2】,【3,4】,【5,6】,for j in i,每个j就是1,2,3,4,5,6,合并后就是结果
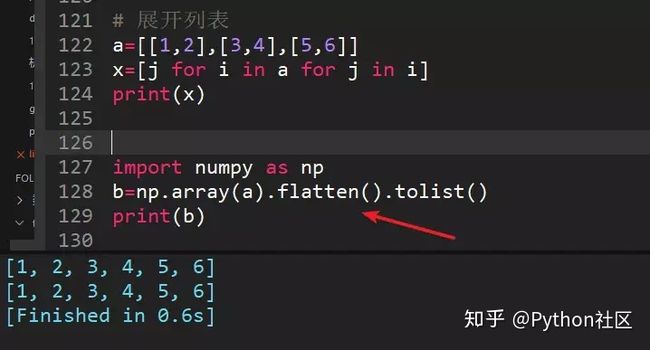
还有更骚的方法,将列表转成numpy矩阵,通过numpy的flatten()方法,代码永远是只有更骚,没有最骚
40、x="abc",y="def",z=["d","e","f"],分别求出x.join(y)和x.join(z)返回的结果
join()括号里面的是可迭代对象,x插入可迭代对象中间,形成字符串,结果一致,有没有突然感觉字符串的常见操作都不会玩了
顺便建议大家学下os.path.join()方法,拼接路径经常用到,也用到了join,和字符串操作中的join有什么区别,该问题大家可以查阅相关文档,后期会有答案

41、举例说明异常模块中try except else finally的相关意义
try..except..else没有捕获到异常,执行else语句
try..except..finally不管是否捕获到异常,都执行finally语句
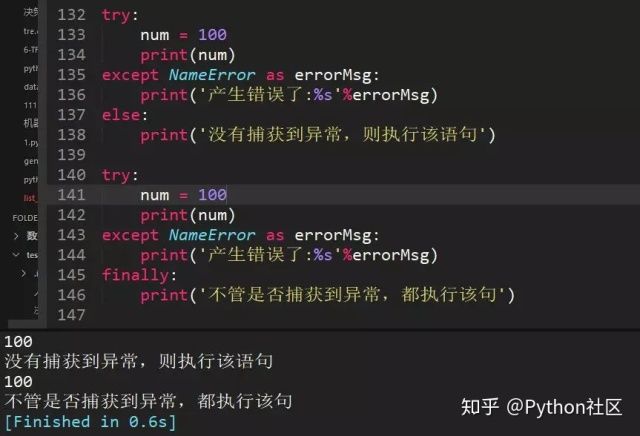
42、python中交换两个数值
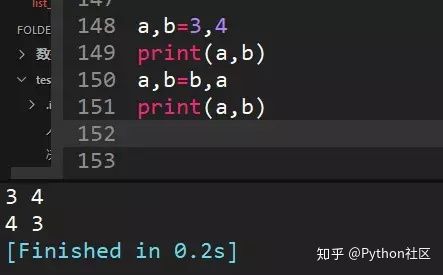
43、举例说明zip()函数用法
zip()函数在运算时,会以一个或多个序列(可迭代对象)做为参数,返回一个元组的列表。同时将这些序列中并排的元素配对。
zip()参数可以接受任何类型的序列,同时也可以有两个以上的参数;当传入参数的长度不同时,zip能自动以最短序列长度为准进行截取,获得元组。

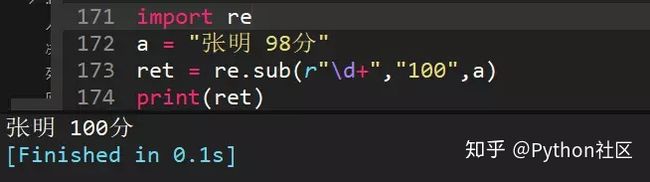
44、a="张明 98分",用re.sub,将98替换为100
45、写5条常用sql语句
show databases;
show tables;
desc 表名;
select * from 表名;
delete from 表名 where id=5;
update students set gender=0,hometown="北京" where id=5
46、a="hello"和b="你好"编码成bytes类型

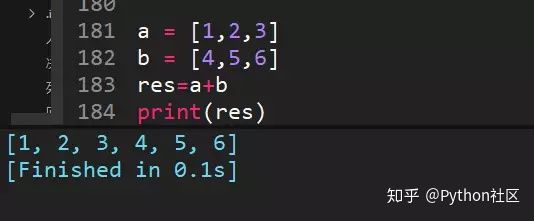
47、[1,2,3]+[4,5,6]的结果是多少?
两个列表相加,等价于extend
48、提高python运行效率的方法
1、使用生成器,因为可以节约大量内存
2、循环代码优化,避免过多重复代码的执行
3、核心模块用Cython PyPy等,提高效率
4、多进程、多线程、协程
5、多个if elif条件判断,可以把最有可能先发生的条件放到前面写,这样可以减少程序判断的次数,提高效率
49、简述mysql和redis区别
redis: 内存型非关系数据库,数据保存在内存中,速度快
mysql:关系型数据库,数据保存在磁盘中,检索的话,会有一定的Io操作,访问速度相对慢
50、遇到bug如何处理
1、细节上的错误,通过print()打印,能执行到print()说明一般上面的代码没有问题,分段检测程序是否有问题,如果是js的话可以alert或console.log
2、如果涉及一些第三方框架,会去查官方文档或者一些技术博客。
3、对于bug的管理与归类总结,一般测试将测试出的bug用teambin等bug管理工具进行记录,然后我们会一条一条进行修改,修改的过程也是理解业务逻辑和提高自己编程逻辑缜密性的方法,我也都会收藏做一些笔记记录。
4、导包问题、城市定位多音字造成的显示错误问题
51、正则匹配,匹配日期2018-03-20
url='https://sycm.taobao.com/bda/tradinganaly/overview/get_summary.json?dateRange=2018-03-20%7C2018-03-20&dateType=recent1&device=1&token=ff25b109b&_=1521595613462'
仍有同学问正则,其实匹配并不难,提取一段特征语句,用(.*?)匹配即可

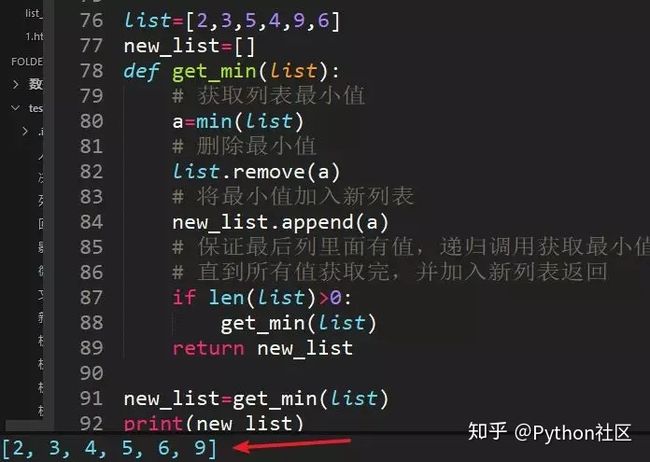
52、list=[2,3,5,4,9,6],从小到大排序,不许用sort,输出[2,3,4,5,6,9]
利用min()方法求出最小值,原列表删除最小值,新列表加入最小值,递归调用获取最小值的函数,反复操作
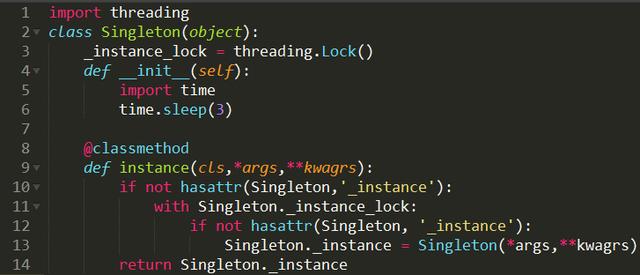
53、写一个单列模式
因为创建对象时__new__方法执行,并且必须return 返回实例化出来的对象所cls.__instance是否存在,不存在的话就创建对象,存在的话就返回该对象,来保证只有一个实例对象存在(单列),打印ID,值一样,说明对象同一个

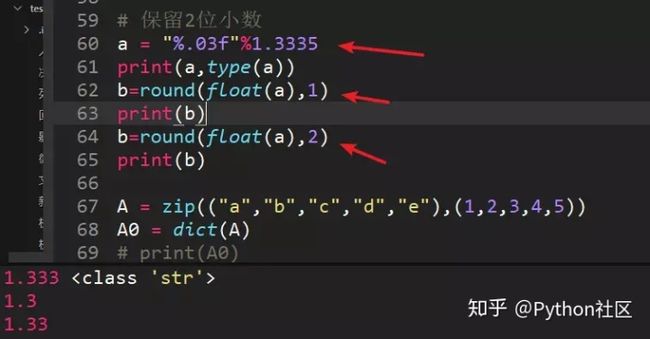
54、保留两位小数
题目本身只有a="%.03f"%1.3335,让计算a的结果,为了扩充保留小数的思路,提供round方法(数值,保留位数)
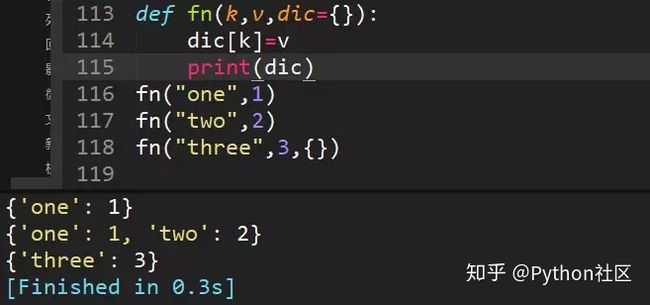
55、求三个方法打印结果
fn("one",1)直接将键值对传给字典;
fn("two",2)因为字典在内存中是可变数据类型,所以指向同一个地址,传了新的额参数后,会相当于给字典增加键值对
fn("three",3,{})因为传了一个新字典,所以不再是原先默认参数的字典
56、列出常见的状态码和意义
200 OK
请求正常处理完毕
204 No Content
请求成功处理,没有实体的主体返回
206 Partial Content
GET范围请求已成功处理
301 Moved Permanently
永久重定向,资源已永久分配新URI
302 Found
临时重定向,资源已临时分配新URI
303 See Other
临时重定向,期望使用GET定向获取
304 Not Modified
发送的附带条件请求未满足
307 Temporary Redirect
临时重定向,POST不会变成GET
400 Bad Request
请求报文语法错误或参数错误
401 Unauthorized
需要通过HTTP认证,或认证失败
403 Forbidden
请求资源被拒绝
404 Not Found
无法找到请求资源(服务器无理由拒绝)
500 Internal Server Error
服务器故障或Web应用故障
503 Service Unavailable
服务器超负载或停机维护
57、分别从前端、后端、数据库阐述web项目的性能优化
该题目网上有很多方法,我不想截图网上的长串文字,看的头疼,按我自己的理解说几点
前端优化:
1、减少http请求、例如制作精灵图
2、html和CSS放在页面上部,javascript放在页面下面,因为js加载比HTML和Css加载慢,所以要优先加载html和css,以防页面显示不全,性能差,也影响用户体验差
后端优化:
1、缓存存储读写次数高,变化少的数据,比如网站首页的信息、商品的信息等。应用程序读取数据时,一般是先从缓存中读取,如果读取不到或数据已失效,再访问磁盘数据库,并将数据再次写入缓存。
2、异步方式,如果有耗时操作,可以采用异步,比如celery
3、代码优化,避免循环和判断次数太多,如果多个if else判断,优先判断最有可能先发生的情况
数据库优化:
1、如有条件,数据可以存放于redis,读取速度快
2、建立索引、外键等
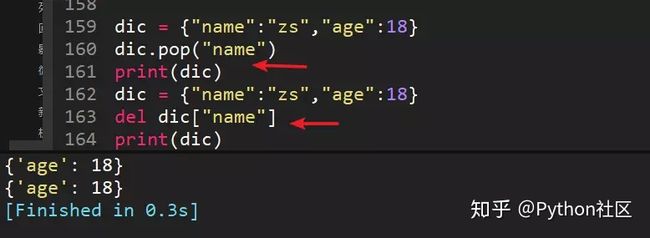
58、使用pop和del删除字典中的"name"字段,dic={"name":"zs","age":18}
59、列出常见MYSQL数据存储引擎
InnoDB:支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交(commit)和回滚(rollback)。
MyISAM:插入数据快,空间和内存使用比较低。如果表主要是用于插入新记录和读出记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发性要求比 较低,也可以使用。
MEMORY:所有的数据都在内存中,数据的处理速度快,但是安全性不高。如果需要很快的读写速度,对数据的安全性要求较低,可以选择MEMOEY。它对表的大小有要求,不能建立太大的表。所以,这类数据库只使用在相对较小的数据库表。
60、计算代码运行结果,zip函数历史文章已经说了,得出[("a",1),("b",2),("c",3),("d",4),("e",5)]
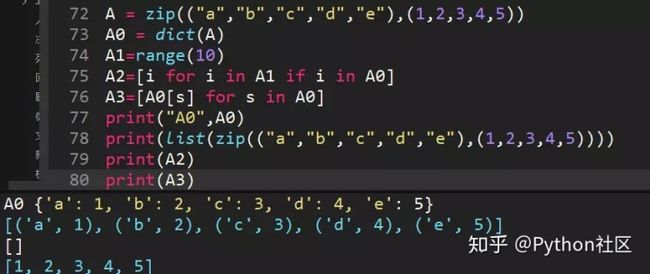
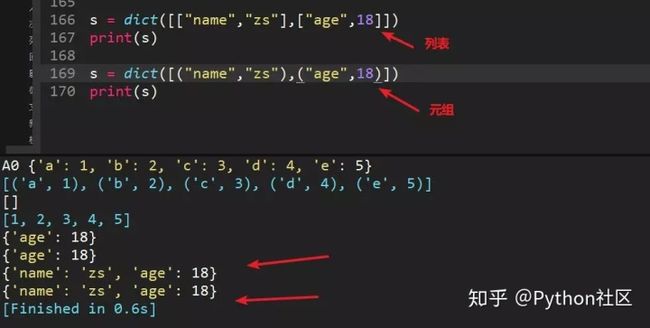
dict()创建字典新方法
61、简述同源策略
同源策略需要同时满足以下三点要求:
1)协议相同
2)域名相同
3)端口相同
http:http://www.test.com与https:http://www.test.com 不同源——协议不同
http:http://www.test.com与http:http://www.admin.com 不同源——域名不同
http:http://www.test.com与http:http://www.test.com:8081 不同源——端口不同
只要不满足其中任意一个要求,就不符合同源策略,就会出现“跨域”
62、简述cookie和session的区别
1,session 在服务器端,cookie 在客户端(浏览器)
2、session 的运行依赖 session id,而 session id 是存在 cookie 中的,也就是说,如果浏览器禁用了 cookie ,同时 session 也会失效,存储Session时,键与Cookie中的sessionid相同,值是开发人员设置的键值对信息,进行了base64编码,过期时间由开发人员设置
3、cookie安全性比session差
63、简述多线程、多进程
进程:
1、操作系统进行资源分配和调度的基本单位,多个进程之间相互独立
2、稳定性好,如果一个进程崩溃,不影响其他进程,但是进程消耗资源大,开启的进程数量有限制
线程:
1、CPU进行资源分配和调度的基本单位,线程是进程的一部分,是比进程更小的能独立运行的基本单位,一个进程下的多个线程可以共享该进程的所有资源
2、如果IO操作密集,则可以多线程运行效率高,缺点是如果一个线程崩溃,都会造成进程的崩溃
应用:
IO密集的用多线程,在用户输入,sleep 时候,可以切换到其他线程执行,减少等待的时间
CPU密集的用多进程,因为假如IO操作少,用多线程的话,因为线程共享一个全局解释器锁,当前运行的线程会霸占GIL,其他线程没有GIL,就不能充分利用多核CPU的优势
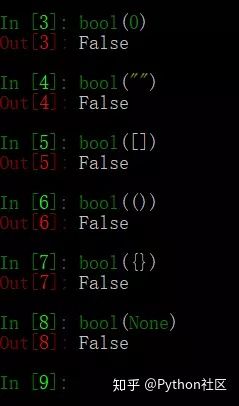
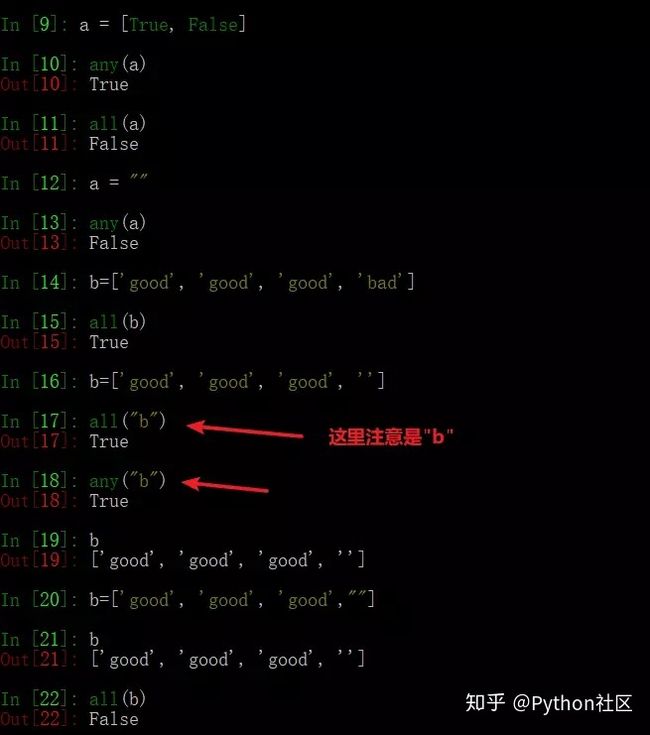
64、简述any()和all()方法
any():只要迭代器中有一个元素为真就为真
all():迭代器中所有的判断项返回都是真,结果才为真
python中什么元素为假?
答案:(0,空字符串,空列表、空字典、空元组、None, False)
测试all()和any()方法
65、IOError、AttributeError、ImportError、IndentationError、IndexError、KeyError、SyntaxError、NameError分别代表什么异常
IOError:输入输出异常
AttributeError:试图访问一个对象没有的属性
ImportError:无法引入模块或包,基本是路径问题
IndentationError:语法错误,代码没有正确的对齐
IndexError:下标索引超出序列边界
KeyError:试图访问你字典里不存在的键
SyntaxError:Python代码逻辑语法出错,不能执行
NameError:使用一个还未赋予对象的变量
66、python中copy和deepcopy区别
1、复制不可变数据类型,不管copy还是deepcopy,都是同一个地址当浅复制的值是不可变对象(数值,字符串,元组)时和=“赋值”的情况一样,对象的id值与浅复制原来的值相同。
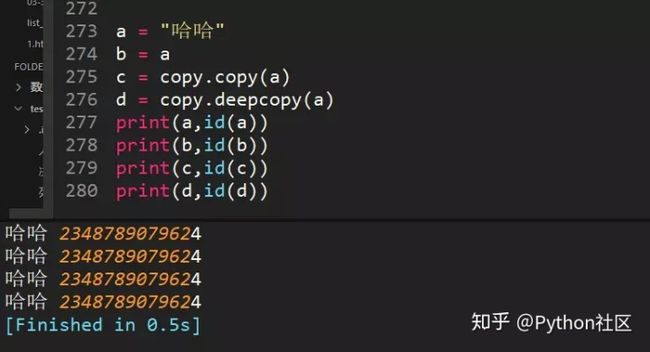
2、复制的值是可变对象(列表和字典)
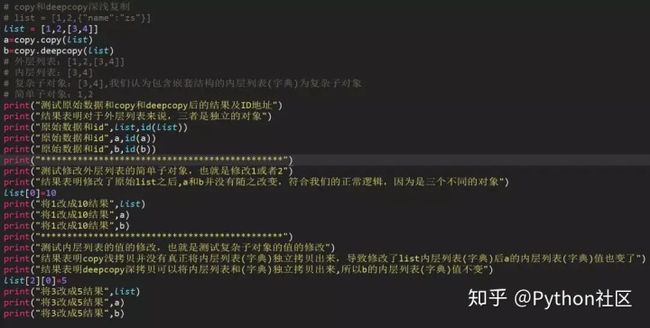
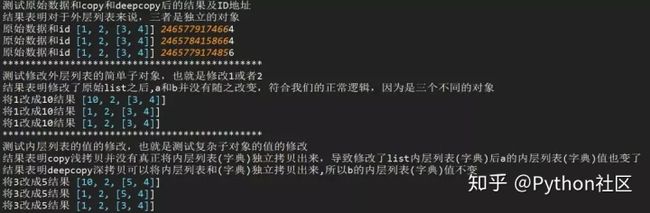
浅拷贝copy有两种情况:
第一种情况:复制的 对象中无 复杂 子对象,原来值的改变并不会影响浅复制的值,同时浅复制的值改变也并不会影响原来的值。原来值的id值与浅复制原来的值不同。
第二种情况:复制的对象中有 复杂 子对象 (例如列表中的一个子元素是一个列表), 改变原来的值 中的复杂子对象的值 ,会影响浅复制的值。
深拷贝deepcopy:完全复制独立,包括内层列表和字典
67、列出几种魔法方法并简要介绍用途
__init__:对象初始化方法
__new__:创建对象时候执行的方法,单列模式会用到
__str__:当使用print输出对象的时候,只要自己定义了__str__(self)方法,那么就会打印从在这个方法中return的数据
__del__:删除对象执行的方法
68、C:Usersry-wu.junyaDesktop>python 1.py 22 33命令行启动程序并传参,print(sys.argv)会输出什么数据?
文件名和参数构成的列表

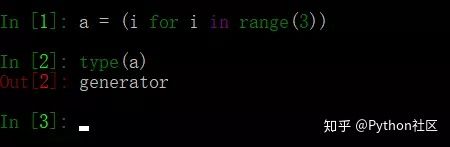
69、请将[i for i in range(3)]改成生成器
生成器是特殊的迭代器,
1、列表表达式的【】改为()即可变成生成器
2、函数在返回值得时候出现yield就变成生成器,而不是函数了;
中括号换成小括号即可,有没有惊呆了
70、a = " hehheh ",去除收尾空格

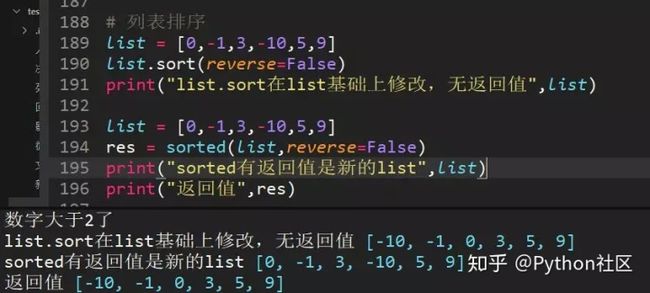
71、举例sort和sorted对列表排序,list=[0,-1,3,-10,5,9]
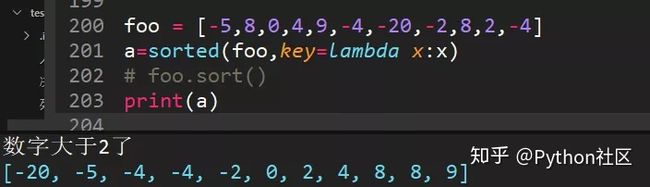
72、对list排序foo = [-5,8,0,4,9,-4,-20,-2,8,2,-4],使用lambda函数从小到大排序
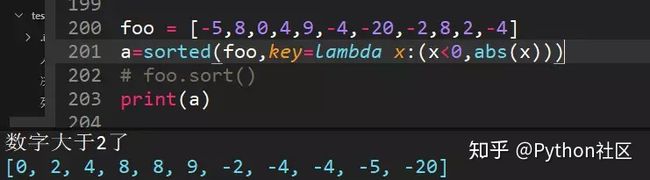
73、使用lambda函数对list排序foo = [-5,8,0,4,9,-4,-20,-2,8,2,-4],输出结果为
[0,2,4,8,8,9,-2,-4,-4,-5,-20],正数从小到大,负数从大到小
(传两个条件,x<0和abs(x))
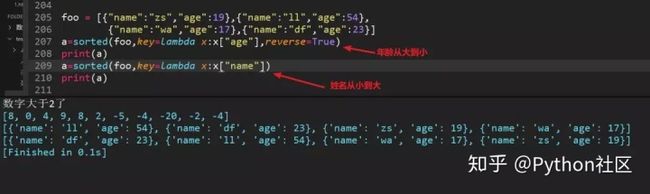
74、列表嵌套字典的排序,分别根据年龄和姓名排序
foo = [{"name":"zs","age":19},{"name":"ll","age":54},
{"name":"wa","age":17},{"name":"df","age":23}]
75、列表嵌套元组,分别按字母和数字排序
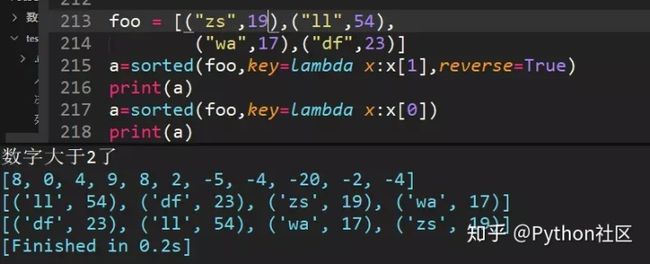
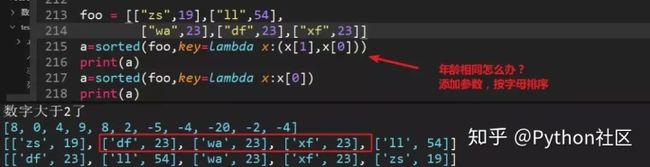
76、列表嵌套列表排序,年龄数字相同怎么办?
77、根据键对字典排序(方法一,zip函数)
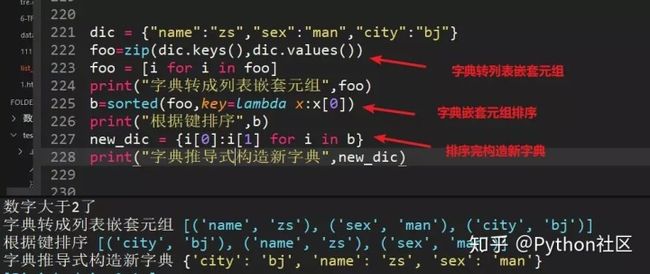
78、根据键对字典排序(方法二,不用zip)
有没有发现dic.items和zip(dic.keys(),dic.values())都是为了构造列表嵌套字典的结构,方便后面用sorted()构造排序规则

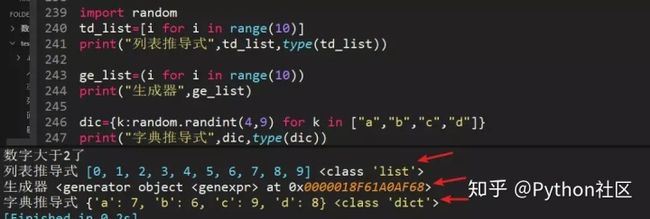
79、列表推导式、字典推导式、生成器
80、最后出一道检验题目,根据字符串长度排序,看排序是否灵活运用

81、举例说明SQL注入和解决办法
当以字符串格式化书写方式的时候,如果用户输入的有;+SQL语句,后面的SQL语句会执行,比如例子中的SQL注入会删除数据库demo

解决方式:通过传参数方式解决SQL注入

82、s="info:xiaoZhang 33 shandong",用正则切分字符串输出['info', 'xiaoZhang', '33', 'shandong']
|表示或,根据冒号或者空格切分

83、正则匹配以http://163.com结尾的邮箱
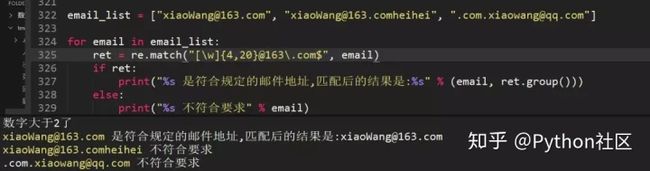
84、递归求和
85、python字典和json字符串相互转化方法
json.dumps()字典转json字符串,json.loads()json转字典

86、MyISAM 与 InnoDB 区别:
1、InnoDB 支持事务,MyISAM 不支持,这一点是非常之重要。事务是一种高
级的处理方式,如在一些列增删改中只要哪个出错还可以回滚还原,而 MyISAM
就不可以了;
2、MyISAM 适合查询以及插入为主的应用,InnoDB 适合频繁修改以及涉及到
安全性较高的应用;
3、InnoDB 支持外键,MyISAM 不支持;
4、对于自增长的字段,InnoDB 中必须包含只有该字段的索引,但是在 MyISAM
表中可以和其他字段一起建立联合索引;
5、清空整个表时,InnoDB 是一行一行的删除,效率非常慢。MyISAM 则会重
建表;
87、统计字符串中某字符出现次数
88、字符串转化大小写
89、用两种方法去空格
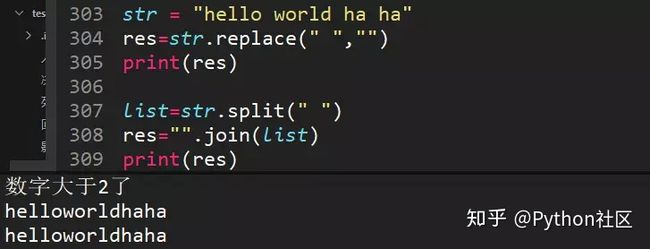
90、正则匹配不是以4和7结尾的手机号
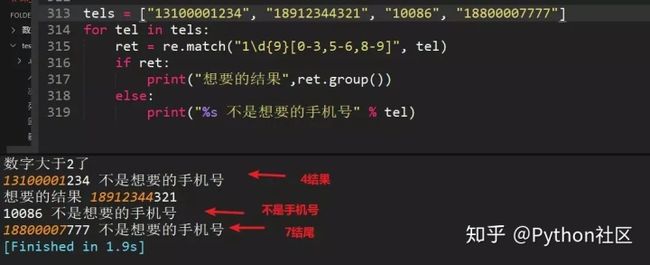
91、简述python引用计数机制
python垃圾回收主要以引用计数为主,标记-清除和分代清除为辅的机制,其中标记-清除和分代回收主要是为了处理循环引用的难题。引用计数算法
当有1个变量保存了对象的引用时,此对象的引用计数就会加1
当使用del删除变量指向的对象时,如果对象的引用计数不为1,比如3,那么此时只会让这个引用计数减1,即变为2,当再次调用del时,变为1,如果再调用1次del,此时会真的把对象进行删除
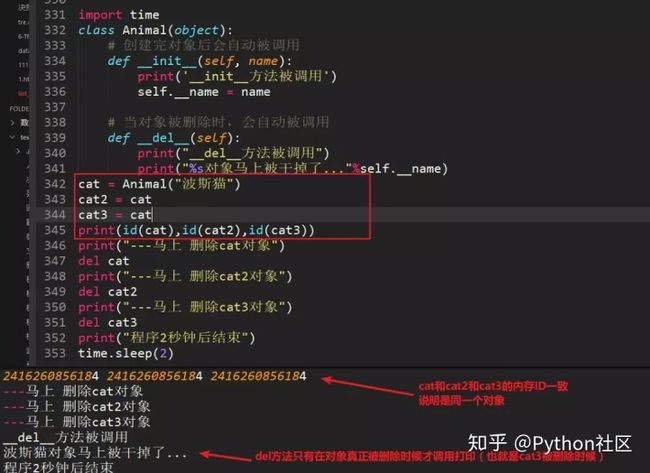
92、int("1.4"),int(1.4)输出结果?
int("1.4")报错,int(1.4)输出1
93、列举3条以上PEP8编码规范
1、顶级定义之间空两行,比如函数或者类定义。
2、方法定义、类定义与第一个方法之间,都应该空一行
3、三引号进行注释
4、使用Pycharm、Eclipse一般使用4个空格来缩进代码
94、正则表达式匹配第一个URL
findall结果无需加group(),search需要加group()提取
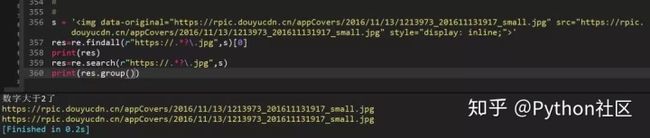
95、正则匹配中文

96、简述乐观锁和悲观锁
悲观锁, 就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制,乐观锁适用于多读的应用类型,这样可以提高吞吐量
97、r、r+、rb、rb+文件打开模式区别
模式较多,比较下背背记记即可

98、Linux命令重定向 > 和 >>
Linux 允许将命令执行结果 重定向到一个 文件
将本应显示在终端上的内容 输出/追加 到指定文件中
> 表示输出,会覆盖文件原有的内容
>> 表示追加,会将内容追加到已有文件的末尾
用法示例:
将 echo 输出的信息保存到 1.txt 里echo Hello Python > 1.txt
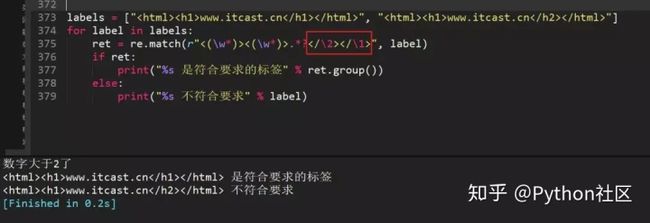
将 tree 输出的信息追加到 1.txt 文件的末尾tree >> 1.txt99、正则表达式匹配出http://www.itcast.cn
前面的<>和后面的<>是对应的,可以用此方法
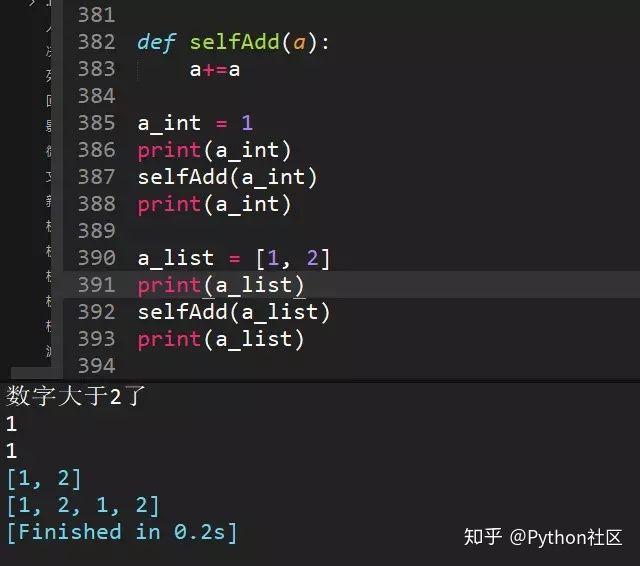
100、python传参数是传值还是传址?
Python中函数参数是引用传递(注意不是值传递)。对于不可变类型(数值型、字符串、元组),因变量不能修改,所以运算不会影响到变量自身;而对于可变类型(列表字典)来说,函数体运算可能会更改传入的参数变量。
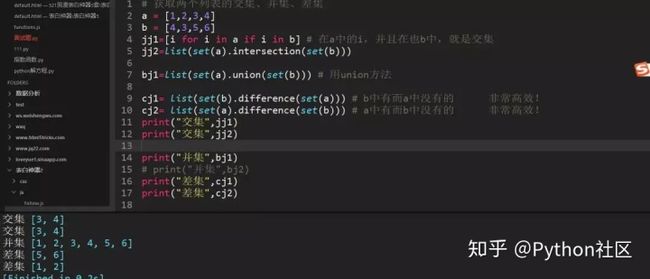
101、求两个列表的交集、差集、并集
102、生成0-100的随机数
random.random()生成0-1之间的随机小数,所以乘以100

103、lambda匿名函数好处
精简代码,lambda省去了定义函数,map省去了写for循环过程

104、常见的网络传输协议
UDP、TCP、FTP、HTTP、SMTP等等
105、单引号、双引号、三引号用法
1、单引号和双引号没有什么区别,不过单引号不用按shift,打字稍微快一点。表示字符串的时候,单引号里面可以用双引号,而不用转义字符,反之亦然。
'She said:"Yes." ' or "She said: 'Yes.' "2、但是如果直接用单引号扩住单引号,则需要转义,像这样:
' She said:'Yes.' '3、三引号可以直接书写多行,通常用于大段,大篇幅的字符串
"""
hello
world
"""106、python垃圾回收机制
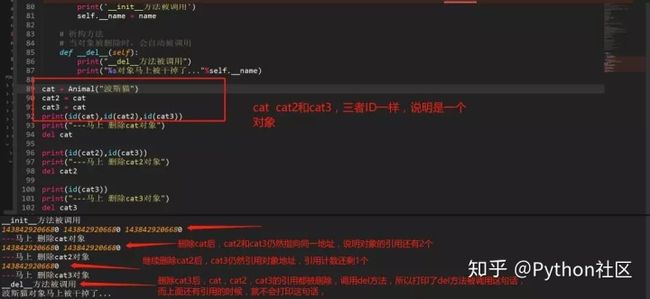
python垃圾回收主要以引用计数为主,标记-清除和分代清除为辅的机制,其中标记-清除和分代回收主要是为了处理循环引用的难题。
引用计数算法
当有1个变量保存了对象的引用时,此对象的引用计数就会加1
当使用del删除变量指向的对象时,如果对象的引用计数不为1,比如3,那么此时只会让这个引用计数减1,即变为2,当再次调用del时,变为1,如果再调用1次del,此时会真的把对象进行删除
107、HTTP请求中get和post区别
1、GET请求是通过URL直接请求数据,数据信息可以在URL中直接看到,比如浏览器访问;而POST请求是放在请求头中的,我们是无法直接看到的;
2、GET提交有数据大小的限制,一般是不超过1024个字节,而这种说法也不完全准确,HTTP协议并没有设定URL字节长度的上限,而是浏览器做了些处理,所以长度依据浏览器的不同有所不同;POST请求在HTTP协议中也没有做说明,一般来说是没有设置限制的,但是实际上浏览器也有默认值。总体来说,少量的数据使用GET,大量的数据使用POST。
3、GET请求因为数据参数是暴露在URL中的,所以安全性比较低,比如密码是不能暴露的,就不能使用GET请求;POST请求中,请求参数信息是放在请求头的,所以安全性较高,可以使用。在实际中,涉及到登录操作的时候,尽量使用HTTPS请求,安全性更好。
108、python中读取Excel文件的方法
应用数据分析库pandas
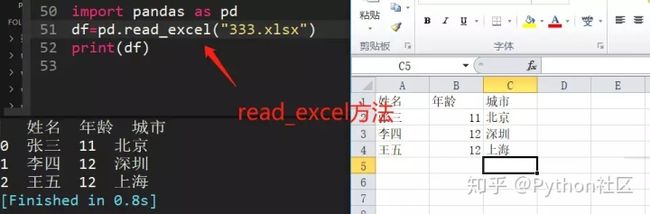
109、简述多线程、多进程
进程:
1、操作系统进行资源分配和调度的基本单位,多个进程之间相互独立
2、稳定性好,如果一个进程崩溃,不影响其他进程,但是进程消耗资源大,开启的进程数量有限制
线程:
1、CPU进行资源分配和调度的基本单位,线程是进程的一部分,是比进程更小的能独立运行的基本单位,一个进程下的多个线程可以共享该进程的所有资源
2、如果IO操作密集,则可以多线程运行效率高,缺点是如果一个线程崩溃,都会造成进程的崩溃
应用:
IO密集的用多线程,在用户输入,sleep 时候,可以切换到其他线程执行,减少等待的时间
CPU密集的用多进程,因为假如IO操作少,用多线程的话,因为线程共享一个全局解释器锁,当前运行的线程会霸占GIL,其他线程没有GIL,就不能充分利用多核CPU的优势
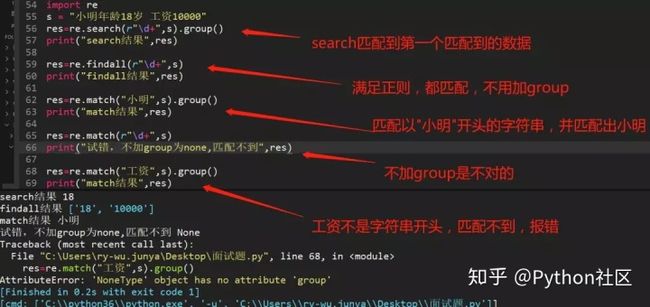
110、python正则中search和match
Q1、Python中的列表和元组有什么区别?
Q2、Python的主要功能是什么?
- Python是一种解释型语言。与C语言等语言不同,Python不需要在运行之前进行编译。Python是动态语言,当您声明变量或类似变量时,您不需要声明变量的类型。
- Python适合面向对象的编程,因为它允许类的定义以及组合和继承。Python没有访问说明(如C ++的public,private)。在Python中,函数是第一类对象。它们可以分配给变量。类也是第一类对象编写Python代码很快,但运行比较慢。
- Python允许基于C的扩展,例如numpy函数库。Python可用于许多领域。Web应用程序开发,自动化,数学建模,大数据应用程序等等。它也经常被用作“胶水”代码。
Q3、Python是通用编程语言吗?
Python能够编写脚本,但从一般意义上讲,它被认为是一种通用编程语言。
Q4、Python是如何解释语言的?
Python在运行之前不需要对程序进行解释。因此,Python是一种解释型语言。
Q5、什么是pep?
PEP代表Python Enhancement Proposal。它是一组规则,指定如何格式化Python代码以获得最大可读性。
Q6、如何在Python中管理内存?
- python中的内存管理由Python私有堆空间管理。所有Python对象和数据结构都位于私有堆中。程序员无权访问此私有堆。python解释器负责处理这个问题。
- Python对象的堆空间分配由Python的内存管理器完成。核心API提供了一些程序员编写代码的工具。Python还有一个内置的垃圾收集器,它可以回收所有未使用的内存,并使其可用于堆空间。
Q7、Python中的命名空间是什么?
命名空间是一个命名系统,用于确保名称是唯一性,以避免命名冲突。
Q8、什么是PYTHONPATH?
它是导入模块时使用的环境变量。每当导入模块时,也会查找PYTHONPATH以检查各个目录中是否存在导入的模块。解释器使用它来确定要加载的模块。
Q9、什么是python模块?Python中有哪些常用的内置模块?
Python模块是包含Python代码的.py文件。此代码可以是函数类或变量。一些常用的内置模块包括:sys、math、random、data time、JSON。、
Q10、Python中的局部变量和全局变量是什么?
- 全局变量:在函数外或全局空间中声明的变量称为全局变量。这些变量可以由程序中的任何函数访问。
- 局部变量:在函数内声明的任何变量都称为局部变量。此变量存在于局部空间中,而不是全局空间中。
Q11、python是否区分大小写?
是。Python是一种区分大小写的语言。
另附上一份各好友收集的Python资料,进群可自行下载!
Q12、什么是Python中的类型转换?
类型转换是指将一种数据类型转换为另一种数据类型。
- int() - 将任何数据类型转换为整数类型
- float() - 将任何数据类型转换为float类型
- ord() - 将字符转换为整数
- hex() - 将整数转换为十六进制
- oct() - 将整数转换为八进制
- tuple() - 此函数用于转换为元组。
- set() - 此函数在转换为set后返回类型。
- list() - 此函数用于将任何数据类型转换为列表类型。
- dict() - 此函数用于将顺序元组(键,值)转换为字典。
- str() - 用于将整数转换为字符串。
- complex(real,imag) - 此函数将实数转换为复数(实数,图像)数。
Q13、如何在Windows上安装Python并设置路径变量?
要在Windows上安装Python,请按照以下步骤操作:从以下链接安装python:https://http://www.python.org/downloads/下载之后,将其安装在您的PC上。在命令提示符下使用以下命令查找PC上安装PYTHON的位置:cmd python。
然后转到高级系统设置并添加新变量并将其命名为PYTHON_NAME并粘贴复制的路径。查找路径变量,选择其值并选择“编辑”。
如果值不存在,请在值的末尾添加分号,然后键入%PYTHON_HOME%
Q14、python中是否需要缩进?
缩进是Python必需的。它指定了一个代码块。循环,类,函数等中的所有代码都在缩进块中指定。通常使用四个空格字符来完成。
如果您的代码没有必要缩进,它将无法准确执行并且也会抛出错误。
Q15、Python数组和列表有什么区别?
Python中的数组和列表具有相同的存储数据方式。但是,数组只能包含单个数据类型元素,而列表可以包含任何数据类型元素。
Q16、Python中的函数是什么?
函数是一个代码块,只有在被调用时才会执行。要在Python中定义函数,需要使用def关键字。
Q17、什么是init?
init是Python中的方法或者结构。在创建类的新对象/实例时,将自动调用此方法来分配内存。所有类都有init方法。
Q18、什么是lambda函数?
lambda函数也叫匿名函数,该函数可以包含任意数量的参数,但只能有一个执行操作的语句。
Q19、Python中的self是什么?
self是类的实例或对象。在Python中,self包含在第一个参数中。
但是,Java中的情况并非如此,它是可选的。它有助于区分具有局部变量的类的方法和属性。init方法中的self变量引用新创建的对象,而在其他方法中,它引用其方法被调用的对象。
Q20、区分break,continue和pass?
Q21、[:: - 1}表示什么?
[:: - 1]用于反转数组或序列的顺序。
Q22、如何在Python中随机化列表中的元素?
可以使用shuffle函数进行随机列表元素。
Q23、什么是python迭代器?
迭代器是可以遍历或迭代的对象。
Q24、如何在Python中生成随机数?
random模块是用于生成随机数的标准模块。该方法定义为:
random.random()方法返回[0,1]范围内的浮点数。 该函数生成随机浮点数。随机类使用的方法是隐藏实例的绑定方法。可以使用Random的实例来显示创建不同线程实例的多线程程序。
其中使用的其他随机生成器是:randrange(a,b):它选择一个整数并定义[a,b]之间的范围。它通过从指定范围中随机选择元素来返回元素。它不构建范围对象
uniform(a,b):它选择一个在[a,b)范围内定义的浮点数normalvariate(mean,sdev):它用于正态分布,其中mean是平均值,sdev是用于标准偏差的sigma。
使用和实例化的Random类创建一个独立的多个随机数生成器。
Q25、range&xrange有什么区别?
在大多数情况下,xrange和range在功能方面完全相同。
它们都提供了一种生成整数列表的方法,唯一的区别是range返回一个Python列表对象,x range返回一个xrange对象。这就表示xrange实际上在运行时并不是生成静态列表。
它使用称为yielding的特殊技术根据需要创建值。该技术与一种称为生成器的对象一起使用。因此如果你有一个非常巨大的列表,那么就要考虑xrange。
Python的趋势现在是越来越火了!需求的岗位也是越来越多了!那么面试官哪些奇怪刁钻的面试题确实令人头疼,面试前最好做好充分的准备,那样才能有最大的几率入聘进自己心仪的岗位,今天总结了一些大企业百分之九十都会碰到的问题,希望能帮到大家入职!

互联网协议定义(分别有4层、5层及7层协议的说法,以下从上层向下层介绍)?
a) 四层协议:应用层、传输层、网络层、网络接口层
a) 五层协议:
应用层:用户使用的应用程序都归属于应用层,作用为规定应用程序的数据格式。
传输层:网络层帮我们找到主机,但是区分应用层的应用就是靠端口,所以传输层就是建立端口到端口的通信。(端口范围0-65535,0-1023为系统占用端口)
网络层:区分不同的广播域或者子网(否则发送一条数据全世界都会受到,是灾难)。
数据链路层:定义电信号的分组方式。
物理层:基于电器特性发送高低点电压(电信号),高电压对应数字1,低电压对应数字0。
C)七层协议:(应用层、表示层、会话层)、传输层、网络层、(数据链路层、物理层)
传输层基于tcp协议的三次握手和四次挥手?
答:传输层有两种数据传输协议,分别为TCP协议和UDP协议,其中TCP协议为可靠传输,数据包没有长度设置,理论可以无限长,而UDP协议为不可靠传输,报头一共就8个字节。Tcp的三次握手和四次挥手定义为:建立连接时三次握手完成建立连接,然后传输数据,断开连接时是四次挥手。所以tcp传输数据是安全的。
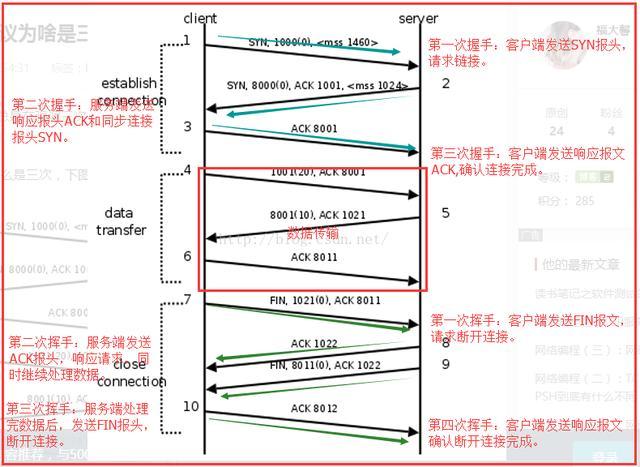
为什么连接的时候是三次握手,关闭的时候却是四次挥手?

什么是socket?
socket是在应用层和传输层之间的一个抽象层,它把TCP/IP层复杂的操作抽象为几个简单的接口供应用层调用以实现进程在网络中通信。
什么是多路复用和多路复用要解决的问题?

并发与并行的区别?
并发不是并行,但看起来像是同时运行的,单个cpu和多道技术就可以实现并发;并行也属于并发,指的是同时运行,只有具备多个cpu才能实现并行。
进程、线程、协程的定义?

进程、线程、协程的区别?

进程同步锁概念介绍
进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件或者打印终端是可以的。共享带来了竞争,竞争的结果就是混乱。解决办法就是加锁处理。加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,没错,速度是慢了,但牺牲了速度却保证了数据安全。
生产者消费者模型?
程序中有两类角色:一类负责生产数据(生产者),一类负责处理数据(消费者);引入生产者消费者模型为了解决的问题是:平衡生产者与消费者之间的工作能力,从而提高程序整体处理数据的速度;如何实现:生产者<-->队列<——>消费者;生产者消费者模型实现类程序的解耦和。
进程与线程的关系?
进程如一个车间,线程如车间内的一条流水线;创建进程需要申请特别的内存空间(车间),各进程间是竞争关系,所以创建进程的开销大;而多个线程属于同一个进程(车间),线程间共享进程中的资源,属于合作关系,所以创建线程开销小。所以,进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是cpu上的执行单位。
什么是协程?

数据库分类
关系型数据库:如sqllite,db2,oracle,access,sql server,MySQL,注意:sql语句通用,需要有表结构;非关系型:mongodb,redis,memcache,非关系型数据库是key-value存储的,没有表结构。
MyISAM和InnoDB搜索引擎的特点

char 和varchar字符串类型的区别?

foreign key外键关联(一对多)实例。
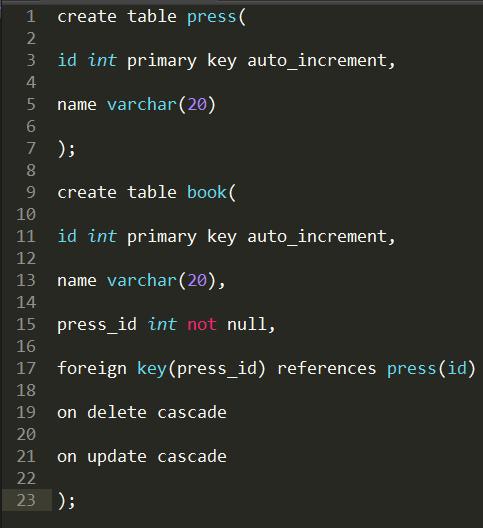
mysql索引相关介绍。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。建立索引会占用磁盘空间的索引文件。
联合索引命中规则是:最左匹配规则,如下联合索引(姓名,年龄,性别):


MySQL在以下操作场景下会使用索引
1) 快速查找符合where条件的记录
2) 快速确定候选集。若where条件使用了多个索引字段,则MySQL会优先使用能使候选记录集规模最小的那个索引,以便尽快淘汰不符合条件的记录。
3) 如果表中存在几个字段构成的联合索引,则查找记录时,这个联合索引的最左前缀匹配字段也会被自动作为索引来加速查找。
例如,若为某表创建了3个字段(c1, c2, c3)构成的联合索引,则(c1), (c1, c2), (c1, c2, c3)均会作为索引,(c2, c3)就不会被作为索引,而(c1, c3)其实只利用到c1索引。
4) 多表做join操作时会使用索引(如果参与join的字段在这些表中均建立了索引的话)。
5) 若某字段已建立索引,求该字段的min()或max()时,MySQL会使用索引。
6) 对建立了索引的字段做sort或group操作时,MySQL会使用索引。
redis如何做持久化?

django的http请求流程
http协议与https协议的区别?
HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。
HTTPS:是以安全为目标的HTTP通道,简单讲是HTTP的安全版,即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL,作用有:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
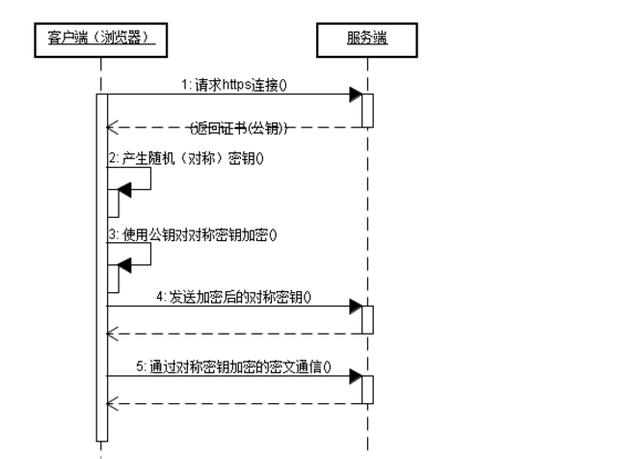
websocket协议?

单列模式
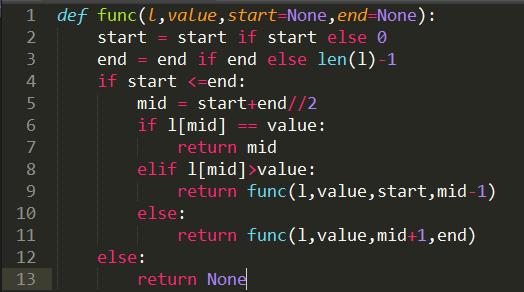
递归实现二分查找实例
冒泡排序

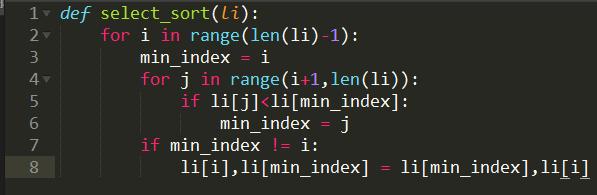
选择排序
栈是一种后进先出的数据结构,堆栈也是采用这种结构管理内存,调用过程中当最初的结果依赖于后面的计算处理,那么后面的部分虽然后开始处理,却先结束。当后续处理太多并且又依赖更后面的处理......(比如递归),便会一直压栈,当空间全部用完,就会造成“堆栈溢出”。
在Python中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。
简述cpython的内存管理机制

列举你知道的python魔法方法及用途
+ View Code
代码出现以下异常的原因
1
2
3
4
5
6
7
IndexError:索引异常,如列表索引取值时,索引不存在会抛此异常
AttributeError:属性异常,如实例化对象获取没有的属性就会抛出此异常
AssertionError:断言语句失败抛出的异常
NotImplementedError:尚未实现的方法时抛出的异常
StopIteration:迭代器没有更多值的时候。
TypeError:传入对象与要求不符
IndentationError:缩进错误

简述以下内置函数的用法:reduce map any all
+ View Code
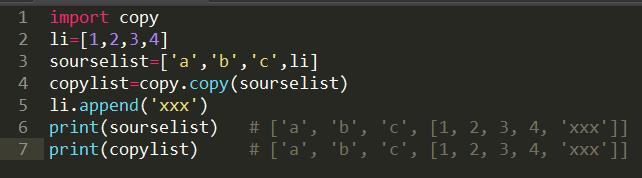
copy和deepcopy的区别是什么?
python中,变量的存储采用了引用语义的方式,即变量存储不是值本身,而是值的内存地址,对于复杂的数据结构,如列表字典等,
变量存储的是数据结构中每个值的存储地址。
使用copy.copy(obj)对对象obj进行浅拷贝,它复制了对象,但是对象中的元素依然使用的是原始引用,所以只要原始引用不发生改
变,原始引用对应的数值发生变化后,也会影响到浅拷贝后的对象。如下实例:
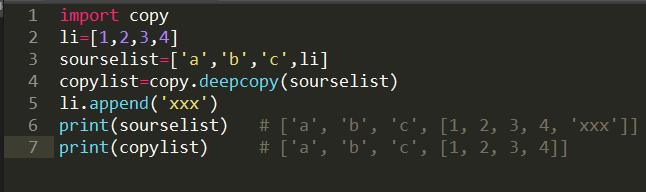
使用copy.deepcopy(obj)对对象深拷贝,深拷贝会完全复制原变量相关的所有数据,在内存中重新开辟一块空间,不管数据结构
多么复杂,只要遇到可能发生改变的数据类型,就重新开辟一块内存空间把内容复制下来,直到最后一层,不再有复杂的数据类型,就
保持其原引用。在这个过程中我们对这两个变量中的一个进行任意修改都不会影响其他变量。如下实例:
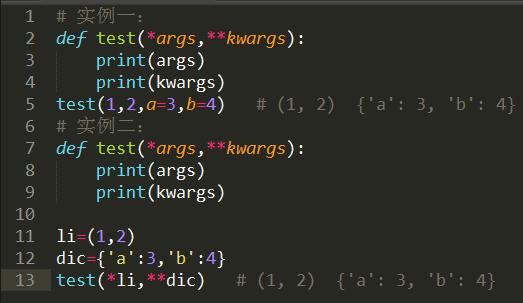
代码中经常遇到的*args和**kwargs的含义及用法
*arg代表任意个位置参数,**kwargs代表任意个关键字参数,使用顺序为def 函数名(位置参数,*args,默认参数,**kwargs),即*arg一定在**kwargs之前。使用见如下实例:
列举一下你知道的HTTP Header及其功能
Accept:
浏览器端可以接受的媒体类型,通配符 * 代表任意类型
Accept-Encoding:
浏览器申明自己接收的编码方法,例如: Accept-Encoding: zh-CN,zh;q=0.8
Accept-Language:
浏览器申明自己接收的语言,
Connection:
如Connection: keep-alive 当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,
如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。
Referer:
当浏览器向web服务器发送请求的时候,一般会带上Referer,告诉服务器我是从哪个页面链接过来的,服务器籍此可以获得一些信息用于处理。
User-Agent:
告诉HTTP服务器, 客户端使用的操作系统和浏览器的名称和版本.
Cookie:
Cookie是用来存储一些用户信息以便让服务器辨别用户身份的(大多数需要登录的网站上面会比较常见),比如cookie会存储一些用户的用户名和密码,
当用户登录后就会在客户端产生一个cookie来存储相关信息,这样浏览器通过读取cookie的信息去服务器上验证并通过后会判定你是合法用户,从而允许查看相应网页。
简述cookie和session的区别和联系
1.cookie是保存在浏览器端的键值对,而session是保存的服务器端的键值对,但是依赖cookie。
2.以登录为例,cookie为通过登录成功后,设置明文的键值对,并将键值对发送客户端存,明文信息可能存在泄漏,不安全。
session则是生成随机字符串sessionID,发给用户,并写到浏览器的cookie中,同时服务器自己也会保存一份。
3.在登录验证时,cookie:根据浏览器发送请求时附带的cookie的键值对进行判断,如果存在,则验证通过;
session:在请求用户的cookie中获取随机字符串,根据随机字符串在session中获取其对应的值进行验证
简述什么是浏览器的同源策略
同源指的是一个请求路径中的请求协议、ip及端口和另一个请求路径中的请求协议、ip及端口保持一致。同源策略是浏览器的一个安全功能,
不同源的客户端脚本在没有明确授权的情况下,不能读写对方资源。
简述python上下文管理器原理,并用上下文管理器简单实现将”hello world”,写入文件的功能。


简述一致性哈希原理和他要解决的问题
pass
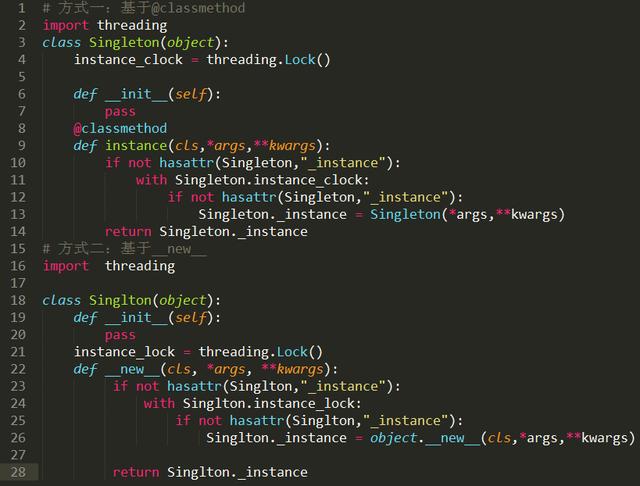
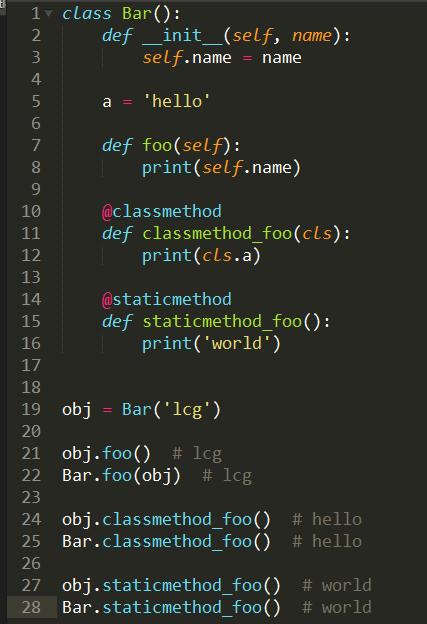
Python中@staticmethod和@classmethod的区别。
在类中总共有三种方法:普通方法(需要参数,使用时默认将类的实例对象传进去,类调用的时候需要传递实例对象),@staticmethod装饰的静态方法与普通函数相同(实例和类均可调用,没有默认的参数传递进去),@classmethod装饰的类方法(需要参数,使用时将调用的类传进去,或者实例对象调用时是将实例对应的类传进去。实例:
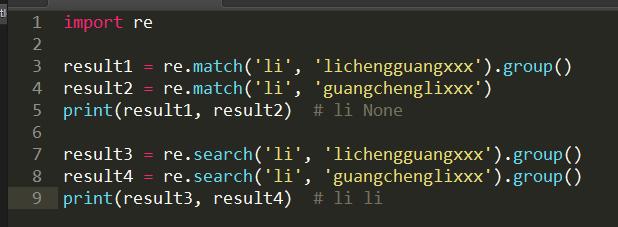
Python里面search()和match()的区别。
首先match()和search()都是只匹配一个结果,但是match()是从字符串开始处进行匹配,匹配成功返回,没有返回None而search()则是从头开始,在整个字符串内匹配。
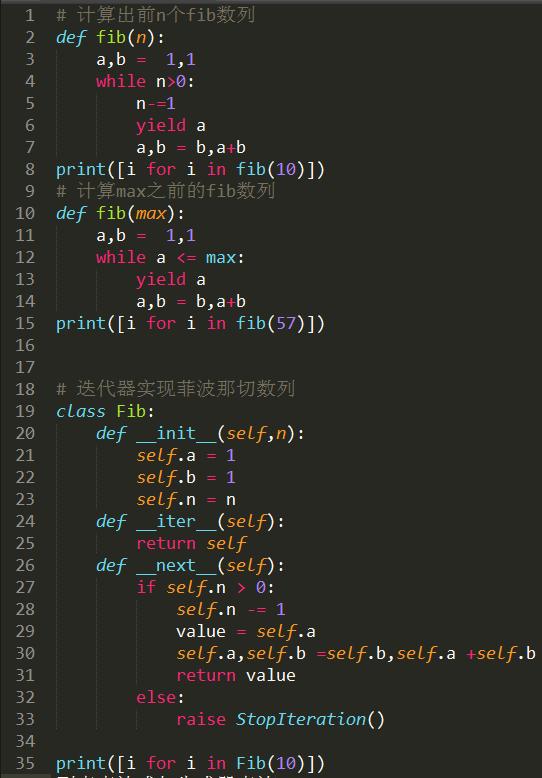
简述迭代器和生成器以及他们之间的区别?
迭代器就是用于迭代操作的的对象,遵从迭代协议(内部实现了__iter__()和__next__()方法,可以像列表(可迭代对象,只有__iter__()方法)一样迭代获取其中的值,与列表不同的是,构建迭代器的时候,不像列表一样一次性把数据加到内存,而是以一种延迟计算的方式返回元素,即调用next方法时候返回此值。
生成器本质上也是一个迭代器,自己实现了可迭代协议,与生成器不同的是生成器的实现方式不同,可以通过生成器表达式和生成器函数两种方式实现,代码更简洁。生成器和迭代器都是惰性可迭代对象,只能遍历一次,数据取完抛出Stopiteration异常
菲波那切数列
列表表达式与生成器表达式的区别
列表表达式生成是一个列表属于可迭代对象,数据一次性生成,占用内存;生成器表达式结果为一个生成器,具有生成器的特性数据,延迟计算,一次只生成一个结果,只能遍历一遍,取完抛异常,节省内存。
注意:range()属于可迭代对象,不是迭代器或生成器,但是是属于惰性可迭代对象,数据是延迟加载,娶一个生成一个,可以重复遍历获取。

什么是装饰器?请用装饰器实现singleton。
装饰器的本质是一个闭包函数,实现的功能是在不修改原函数及调用方式的情况下对原函数进行功能扩展的,是开放封闭原则的典型代表。

装饰器单例:
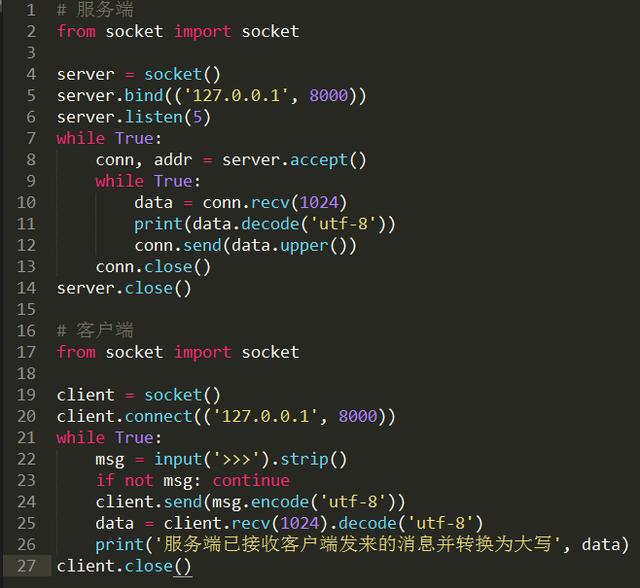
写一个简单的python sockect编程
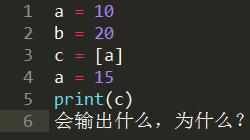
有这样一段代码:
如何下代码(python2.x):

结果一样,但是占用系统资源不一样,range与xrange均属于可迭代对象,通过循环迭代可以取出其中的值,但是xrange属于惰性可迭代对象,虽然不是迭代器,没有next方法,但是有迭代器一样的性质,不会一次性将数据加载到内存,而是通过延迟加载的方式生成数据,取一个生成一个,节省内存资源,与python3中的range相同。
有这样一个url
url:footbar/homework/2009-10-20/xiaoming,其中2009-10-20和xiaoming为变量,请用正则表达式捕获这个url,要求尽量精准.
1
'^footbar/homework/(?P
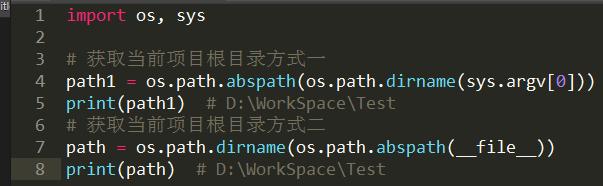
当前项目根目录
现有两个元组(('a'),('b')),(('c'),('d')),请使用python中匿名函数生成列表[{'a':'c'},{'b':'d'}]

django里Queryset的get和filter方法的区别?
get获得是一个对象,filter得到是一个对象列表,即使只有一个满足条件
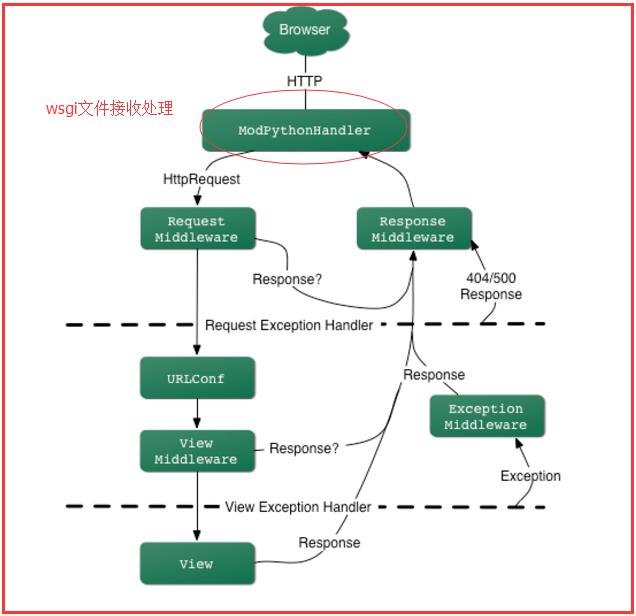
简述django对http请求的执行流程。
一个 HTTP 请求,首先被转化成一个 HttpRequest 对象,然后该对象被传递给 Request 中间件处理,如果该中间件返回了Response,则直接传递给 Response 中间件做收尾处理。否则的话 Request 中间件将访问 URL 配置,确定哪个 view 来处理,在确定了哪个 view 要执行,但是还没有执行该 view 的时候,系统会把 request 传递给 View 中间件处理器进行处理,如果该中间件返回了Response,那么该Response 直接被传递给 Response 中间件进行后续处理,否则将执行确定的 View 函数处理并返回 Response,在这个过程中如果引发了异常并抛出,会被 Exception 中间件处理器进行处理。
简述django下的(内建的)的缓存机制
缓存是将一些常用的数据保存内存或者memcache中,在一定的时间内有人来访问这些数据时,则不再去执行数据库及渲染等操作,而是直接从内存或memcache的缓存中去取得数据,然后返回给用户.django提供了6中内存缓存机制,分别为:
开发调试缓存(为开发调试使用,实际上不使用任何操作);
内存缓存(将缓存内容缓存到内存中);
文件缓存(将缓存内容写到文件 );
数据库缓存(将缓存内容存到数据库);
memcache缓存(包含两种模块,python-memcached或pylibmc.)。
以上缓存均提供了三种粒度的应用。
django中model的slugfeild类型字段有什么用途?
只包含字母、数字、下划线和连接符,通常用于urls
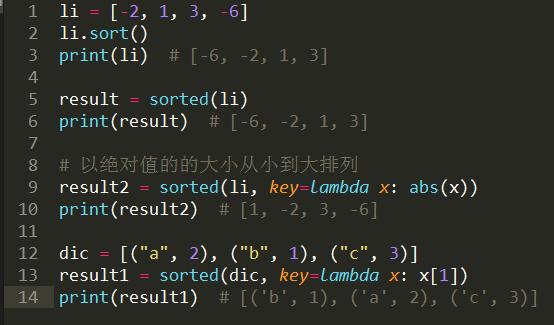
列表的sort方法和sorted的区别是什么?
list=[-2,1,3,-6],如何实现以绝对值的大小从小到大将list的内容进行排序。
sort 与 sorted 区别:
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
Python中变量的作用域(变量的查找顺序)
python中的作用域分4种情况:
(1)L:local,局部作用域,即函数中定义的变量;
(2)E:enclosing,嵌套的父级函数的局部作用域,即包含此函数的上级函数的局部作用域,但不是全局的;
(3)G:globa,全局变量,就是模块级别定义的变量;
(4)B:built-in,系统固定模块里面的变量,比如int, bytearray等。
搜索变量的优先级顺序依次是:局部作用域>外层作用域>当前模块中的全局>python内置作用域,也就是LEGB。
sql注入:在sql语句中,如果存在'--'字符,则执行sql语句时会注释掉--字符后面的内容。凡有SQL注入漏洞的程序,
都是因为程序要接受来自客户端用户输入的变量或URL传递的参数,并且这个变量或参数是组成SQL语句的一部分。放置方式有:
1、使用预编译绑定变量的SQL语句 如execute()
2.严格加密处理用户的机密信息
3.不要随意开启生产环境中Webserver的错误显示
4.使用正则表达式过滤传入的参数
5.字符串过滤
6.检查是否包函非法字符
解释python脚本程序的"__name__"变量及其作用
每一个python程序脚本在运行的时候,都有一个__name__属性,如果程序是作为模块被引入的,则其__name__属性值则自动被设置为模块名,如果脚本程序独立运行,则其__name__属性则自动被设置为__main__,利用__name__属性即可控制python程序的运行方式。
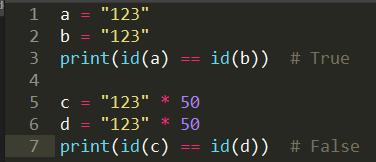
解释python字符串驻留机制。
Python支持字符串驻留机制,即:对于短字符串,将其赋值给多个不同的对象时,内存中只有一个副本,多个对象共享该副本。这一点不适用于长字符串,即长字符串不遵守驻留机制,下面的代码演示了短字符串和长字符串在这方面的区别。
解释下HTTP常见响应状态码

python是如何进行内存管理的
1
python采用的是基于值的内存管理方式,如果为不同变量赋值相同值,则在内存中只有一份该值,多个变量指向同一块内存地址
mysql中随着数据量的增大,查询速度会越来越慢,请给出简易的优化方案。
1.合理的添加索引(mysql默认只会btree类型索引);
mysql常见的索引:
普通索引INDEX:加速查找
唯一索引:
-主键索引PRIMARY KEY:加速查找+约束(不为空、不能重复)
-唯一索引UNIQUE:加速查找+约束(不能重复)
联合索引:
-PRIMARY KEY(id,name):联合主键索引
-UNIQUE(id,name):联合唯一索引
-INDEX(id,name):联合普通索引
2、避免使用select *
3、创建表时尽量用char代替varchar
4、表的字段顺序,固定长度的优先
5、组合索引代替多个单列索引
6、使用连接(join)代替子查询
7、使用explain优化神器
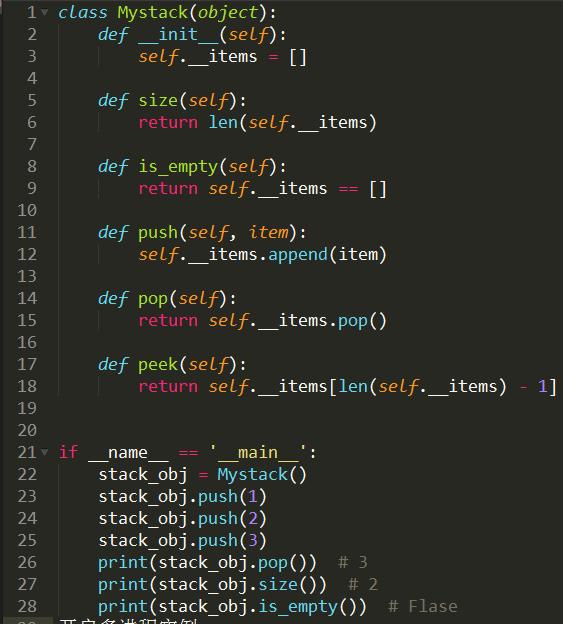
python自定义栈实例
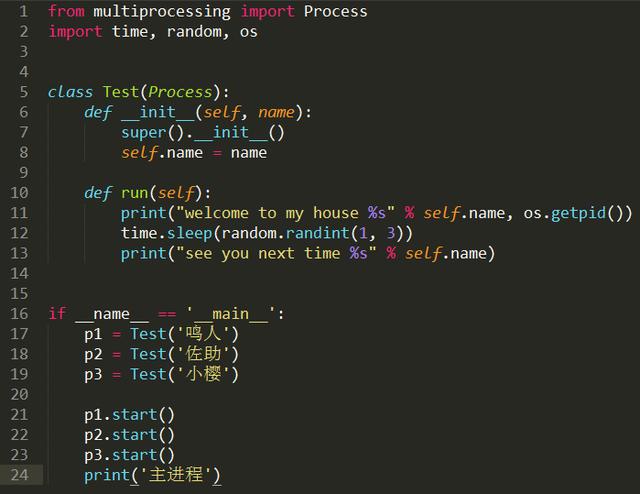
开启多进程实例
方式2